Meta AI
Meta AI é o assistente de IA da Meta integrado ao Facebook, Instagram, WhatsApp e Messenger. Saiba como funciona, suas capacidades e seu papel no monitoramento ...
13 min de leitura
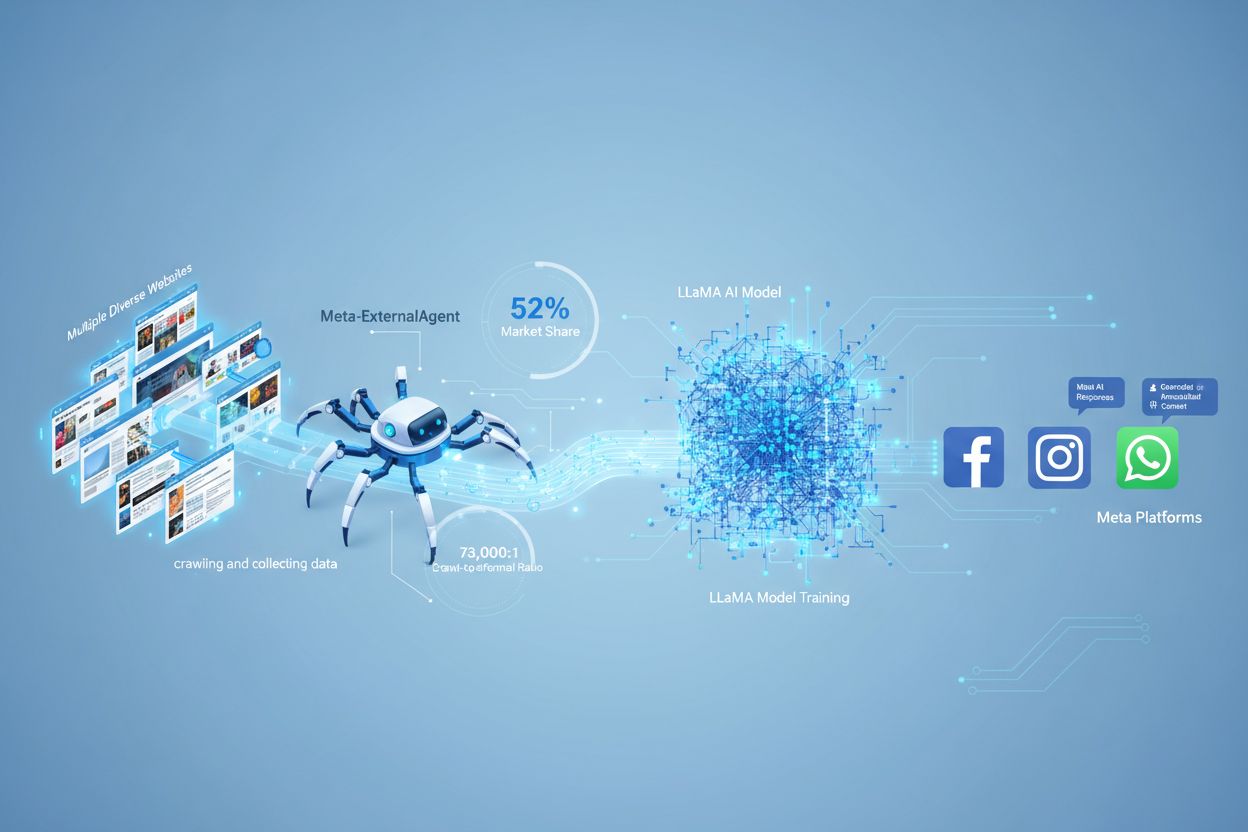
Meta-ExternalAgent é o bot rastreador da web da Meta lançado em julho de 2024 para coletar conteúdo publicamente disponível para treinar modelos de IA como o LLaMA. Ele se identifica com a string User-Agent meta-externalagent/1.1 e controla se o conteúdo aparece em respostas da Meta AI no Facebook, Instagram e WhatsApp. Os editores podem bloqueá-lo via robots.txt ou configurações no servidor, embora a conformidade seja voluntária e não tenha força legal.
Meta-ExternalAgent é o bot rastreador da web da Meta lançado em julho de 2024 para coletar conteúdo publicamente disponível para treinar modelos de IA como o LLaMA. Ele se identifica com a string User-Agent meta-externalagent/1.1 e controla se o conteúdo aparece em respostas da Meta AI no Facebook, Instagram e WhatsApp. Os editores podem bloqueá-lo via robots.txt ou configurações no servidor, embora a conformidade seja voluntária e não tenha força legal.
Meta-ExternalAgent é um rastreador da web operado pela Meta Platforms, lançado em julho de 2024 para coletar dados para o treinamento de modelos de inteligência artificial. Identificado pela string User-Agent meta-externalagent/1.1, esse rastreador é diferente do antigo facebookexternalhit da Meta, que era usado principalmente para prévias de links e recursos de compartilhamento em redes sociais. O Meta-ExternalAgent representa uma mudança significativa na maneira como a Meta reúne dados de treinamento para suas iniciativas de IA, incluindo os modelos de linguagem LLaMA e o chatbot Meta AI integrado ao Facebook, Instagram e WhatsApp. Diferente dos rastreadores anteriores da Meta, este agente opera com transparência mínima e foi implantado sem anúncio público formal.

O Meta-ExternalAgent funciona como um bot automatizado que rastreia sistematicamente sites na internet para extrair textos e conteúdos para fins de treinamento de modelos de IA. O rastreador opera enviando solicitações HTTP para servidores web, identificando-se por meio de seu cabeçalho User-Agent exclusivo e baixando o conteúdo das páginas para processamento. Uma vez coletado, o conteúdo é analisado e tokenizado pelos sistemas da Meta, sendo convertido em dados de treinamento que ajudam a aprimorar as capacidades de seus grandes modelos de linguagem. O rastreador respeita o arquivo robots.txt de forma voluntária, sendo esse um sistema de honra e não uma exigência legal. Segundo dados da Cloudflare, o Meta-ExternalAgent representa aproximadamente 52% de todo o tráfego de rastreadores de IA na internet, tornando-o uma das operações de coleta de dados mais agressivas da indústria de IA. O rastreador opera continuamente, com alguns editores relatando frequências de rastreamento que sugerem que a Meta prioriza uma cobertura abrangente do conteúdo da web em vez de uma coleta seletiva e direcionada.
| Nome do Rastreador | String User-Agent | Propósito Principal | Data de Lançamento | Uso dos Dados |
|---|---|---|---|---|
| Meta-ExternalAgent | meta-externalagent/1.1 | Treinamento de modelos de IA (LLaMA, Meta AI) | Julho 2024 | Dados de treinamento para IA generativa |
| facebookexternalhit | facebookexternalhit/1.1 | Prévia de links e compartilhamento social | ~2010 | Metadados Open Graph, miniaturas |
| Facebot | facebot/1.0 | Verificação de conteúdo de apps do Facebook | ~2015 | Validação de conteúdo para apps móveis |
| Applebot | Applebot/0.1 | Siri da Apple e indexação de busca | ~2015 | Indexação de busca e assistente de voz |
| Googlebot | Googlebot/2.1 | Indexação do Google Search | ~1998 | Construção de índice para buscadores |
O Meta-ExternalAgent representa uma preocupação crítica para criadores de conteúdo e editores porque opera em escala sem precedentes e oferece pouca visibilidade sobre como o conteúdo está sendo utilizado. Segundo pesquisa da Cloudflare, o Meta-ExternalAgent responde por 52% de todo o tráfego de rastreadores de IA, superando amplamente concorrentes como o GPTBot da OpenAI e os rastreadores de IA do Google. Esse domínio significa que a Meta coleta mais dados de treinamento do que qualquer outra empresa de IA, mas os editores não recebem compensação ou atribuição quando seu conteúdo é utilizado para treinar os modelos de IA da Meta. A razão de 73.000:1 entre rastreamento e indicação demonstra que a Meta extrai enormes quantidades de conteúdo enquanto envia praticamente nenhum tráfego de volta aos sites de origem—um desequilíbrio fundamental na troca de valor. Apesar dessas preocupações, apenas 2% dos sites bloqueiam ativamente o Meta-ExternalAgent, em comparação com 25% que bloqueiam o GPTBot, sugerindo que muitos editores desconhecem a presença do rastreador ou suas implicações. Com a Meta investindo US$ 40 bilhões em infraestrutura de IA, o compromisso da empresa com a coleta agressiva de dados tende a se intensificar, tornando essencial que os editores entendam e gerenciem ativamente sua relação com esse rastreador.
Os editores podem controlar o acesso do Meta-ExternalAgent por meio do arquivo robots.txt, mas é importante entender que esse mecanismo funciona de maneira voluntária e não tem força legal. Para bloquear o Meta-ExternalAgent, adicione a seguinte diretiva ao seu arquivo robots.txt:
User-agent: meta-externalagent
Disallow: /
Alternativamente, se você quiser permitir o rastreador, mas restringi-lo a diretórios específicos, pode usar:
User-agent: meta-externalagent
Disallow: /private/
Disallow: /admin/
Allow: /public/
No entanto, alguns editores relataram que o Meta-ExternalAgent continua rastreando seus sites mesmo após a implementação de bloqueios no robots.txt, sugerindo que a Meta pode não seguir essas diretivas de maneira consistente. Para proteção mais abrangente, os editores podem implementar bloqueio por cabeçalho HTTP ou usar regras em redes de distribuição de conteúdo (CDN) para identificar e rejeitar solicitações do Meta-ExternalAgent com base na string User-Agent. Além disso, é possível monitorar os logs do servidor em busca da string User-Agent meta-externalagent/1.1 para verificar se o rastreador está acessando seu conteúdo. Ferramentas como AmICited.com ajudam editores a acompanhar se seu conteúdo está sendo citado ou referenciado em respostas da Meta AI, oferecendo visibilidade sobre como seu trabalho está sendo utilizado pelos sistemas de IA da Meta.

Quando usuários interagem com chatbots da Meta AI no Facebook, Instagram ou WhatsApp, as respostas geradas são baseadas, em parte, no conteúdo coletado pelo Meta-ExternalAgent. No entanto, as respostas da Meta AI geralmente não incluem citações visíveis ou atribuição aos sites de origem, o que significa que os usuários podem não saber quais conteúdos de quais editores contribuíram para a resposta recebida. Essa falta de transparência cria um desafio significativo para criadores de conteúdo que desejam entender o valor que seu trabalho fornece aos sistemas de IA da Meta. Diferente de alguns concorrentes que incluem citações em respostas geradas por IA, a abordagem da Meta prioriza a experiência do usuário em detrimento da atribuição ao editor. A ausência de citações visíveis também dificulta que os editores acompanhem com que frequência seu conteúdo influencia respostas da Meta AI, tornando difícil mensurar o impacto comercial do uso do conteúdo para treinamento de IA. Essa lacuna de visibilidade é uma das principais razões para o aumento da importância de soluções de monitoramento para editores que desejam entender seu papel no ecossistema de IA.
Os editores podem verificar a atividade do Meta-ExternalAgent por meio da análise de logs do servidor, que revelam endereços IP do rastreador, padrões de requisição e frequência de acesso ao conteúdo. Ao examinar os logs de acesso, é possível identificar solicitações com a string User-Agent meta-externalagent/1.1 e determinar quais páginas são rastreadas com maior frequência. Ferramentas avançadas de monitoramento podem acompanhar padrões de rastreamento ao longo do tempo, revelando se a Meta está priorizando certos tipos de conteúdo ou seções do site. Também é importante monitorar o uso de banda, já que rastreamento agressivo do Meta-ExternalAgent pode consumir recursos significativos do servidor, especialmente em sites com grandes acervos de conteúdo. Além disso, editores podem utilizar ferramentas como AmICited.com para monitorar se seu conteúdo aparece em respostas da Meta AI e acompanhar padrões de citação nas plataformas da Meta. A configuração de alertas para atividades incomuns de rastreamento pode ajudar a detectar mudanças no comportamento de coleta de dados da Meta e responder proativamente. Auditorias regulares nos logs do servidor devem fazer parte da estratégia de gestão de rastreadores de IA de qualquer editor, garantindo consciência sobre como seu conteúdo está sendo acessado e utilizado.
O status legal do Meta-ExternalAgent permanece contestado, com processos em andamento movidos por criadores de conteúdo, artistas e editores que questionam o direito da Meta de usar seu trabalho para treinamento de IA sem consentimento explícito ou compensação. Enquanto a Meta argumenta que o rastreamento da web se enquadra no conceito de uso justo, críticos afirmam que a escala e o caráter comercial da coleta de dados, combinados à ausência de atribuição, constituem infração de direitos autorais. O arquivo robots.txt, embora amplamente respeitado como padrão da indústria, não tem força legal, o que significa que a Meta não é obrigada a seguir as diretivas de bloqueio. Diversas jurisdições estão desenvolvendo regulações sobre coleta de dados para treinamento de IA, com o AI Act da União Europeia e propostas em outras regiões potencialmente impondo requisitos mais rigorosos a empresas como a Meta. Do ponto de vista ético, a questão fundamental é se criadores de conteúdo devem ter direito a controlar como seu trabalho é utilizado para treinamento comercial de IA e se o sistema atual compensa adequadamente os criadores pelo valor que fornecem. Os editores devem manter-se informados sobre a evolução das legislações e considerar consultar assessoria jurídica sobre seus direitos e obrigações em relação ao acesso de rastreadores de IA. O equilíbrio entre permitir a inovação em IA e proteger os direitos dos criadores ainda não está resolvido, tornando esse um campo de desenvolvimento jurídico e regulatório ativo.
O cenário de gestão de rastreadores de IA está evoluindo rapidamente à medida que editores, reguladores e empresas de IA negociam os termos de coleta e uso de dados. O lançamento agressivo do Meta-ExternalAgent indica que grandes empresas de tecnologia veem o conteúdo da web como material essencial para o treinamento de sistemas de IA competitivos, e essa tendência tende a se acelerar à medida que as capacidades de IA se tornam cada vez mais centrais para as estratégias de negócios. Desenvolvimentos futuros podem incluir proteções legais mais robustas para criadores, estruturas obrigatórias de licenciamento para dados de treinamento de IA e padrões técnicos que facilitem o controle e a monetização do uso do conteúdo dos editores em sistemas de IA. O surgimento de ferramentas como o AmICited.com reflete a crescente demanda por transparência e responsabilidade em como sistemas de IA utilizam conteúdo publicado, sugerindo que monitoramento e verificação se tornarão práticas padrão para criadores de conteúdo. À medida que a indústria de IA amadurece, podemos esperar negociações mais sofisticadas entre criadores de conteúdo e empresas de IA, potencialmente levando a novos modelos de negócios que remunerem de forma justa os editores por suas contribuições ao treinamento de IA.
Meta-ExternalAgent é o rastreador dedicado ao treinamento de IA da Meta lançado em julho de 2024, identificado pela string User-Agent meta-externalagent/1.1. Ele se diferencia do facebookexternalhit, que gera prévias de links para compartilhamento social. O Meta-ExternalAgent coleta especificamente conteúdo para treinar modelos LLaMA e a Meta AI, enquanto o facebookexternalhit é utilizado para funções sociais desde cerca de 2010.
Você pode bloquear o Meta-ExternalAgent adicionando diretivas ao seu arquivo robots.txt. Adicione 'User-agent: meta-externalagent' seguido de 'Disallow: /' para bloqueá-lo completamente. Para proteção mais abrangente, implemente bloqueio a nível de servidor usando .htaccess (Apache) ou regras de configuração Nginx. No entanto, o robots.txt é voluntário e não tem força legal, então alguns editores relatam rastreamento contínuo apesar do bloqueio.
Não, bloquear o Meta-ExternalAgent não afeta as prévias de links do Facebook. O rastreador facebookexternalhit é responsável pelas prévias de links e recursos de compartilhamento social. Você pode bloquear o meta-externalagent e ainda permitir que o facebookexternalhit continue gerando prévias atraentes quando seu conteúdo é compartilhado nas plataformas da Meta.
O Meta-ExternalAgent possui uma razão de rastreamento para indicação de aproximadamente 73.000:1, o que significa que a Meta extrai conteúdo em escala enorme enquanto envia praticamente nenhum tráfego de volta aos sites de origem. Isso representa um desequilíbrio fundamental em comparação com mecanismos de busca tradicionais, que rastreiam conteúdo em troca de direcionar tráfego de referência.
O robots.txt é um sistema de honra e não tem força legal. Embora muitos rastreadores respeitem as diretivas do robots.txt, alguns editores relataram que o Meta-ExternalAgent continua rastreando seus sites apesar de bloqueios explícitos no robots.txt. Para proteção garantida, implemente bloqueio a nível de servidor usando cabeçalhos HTTP, regras de CDN ou configurações de firewall.
Verifique os logs de acesso do seu servidor para solicitações com a string User-Agent 'meta-externalagent/1.1'. Você também pode usar ferramentas de monitoramento como AmICited.com para acompanhar se seu conteúdo aparece em respostas da Meta AI. Ferramentas como Dark Visitors e Cloudflare Analytics fornecem insights adicionais sobre a atividade de rastreadores de IA em seu site.
Segundo dados da Cloudflare, o Meta-ExternalAgent responde por aproximadamente 52% de todo o tráfego de rastreadores de IA na internet, tornando-se a operação de coleta de dados de IA mais agressiva. Isso supera amplamente concorrentes como o GPTBot da OpenAI e os rastreadores de IA do Google, indicando a posição dominante da Meta na coleta de conteúdo da web para treinamento de IA.
A decisão depende das prioridades do seu negócio. Se o tráfego da Meta AI é valioso para seu público, talvez queira permitir. No entanto, considere que a Meta não oferece compensação ou atribuição pelo conteúdo usado no treinamento de IA. Muitos editores implementam estratégias de bloqueio seletivo que impedem o treinamento de IA, mas preservam a funcionalidade de prévias de links para compartilhamento social.
Acompanhe como seu conteúdo aparece nas respostas da Meta AI no Facebook, Instagram e WhatsApp. Tenha visibilidade sobre citações de IA e entenda a presença da sua marca em respostas geradas por IA.
Meta AI é o assistente de IA da Meta integrado ao Facebook, Instagram, WhatsApp e Messenger. Saiba como funciona, suas capacidades e seu papel no monitoramento ...

Descubra como a otimização de IA da Meta transforma a publicidade no Facebook e Instagram com automação baseada em IA, lances em tempo real e segmentação inteli...

Aprenda a implementar as meta tags noai e noimageai para controlar o acesso de crawlers de IA ao conteúdo do seu site. Guia completo sobre cabeçalhos de control...
Consentimento de Cookies
Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.