
Gráfico
Saiba o que são gráficos, seus tipos e como transformam dados brutos em insights acionáveis. Guia essencial sobre formatos de visualização de dados para análise...
9 min de leitura
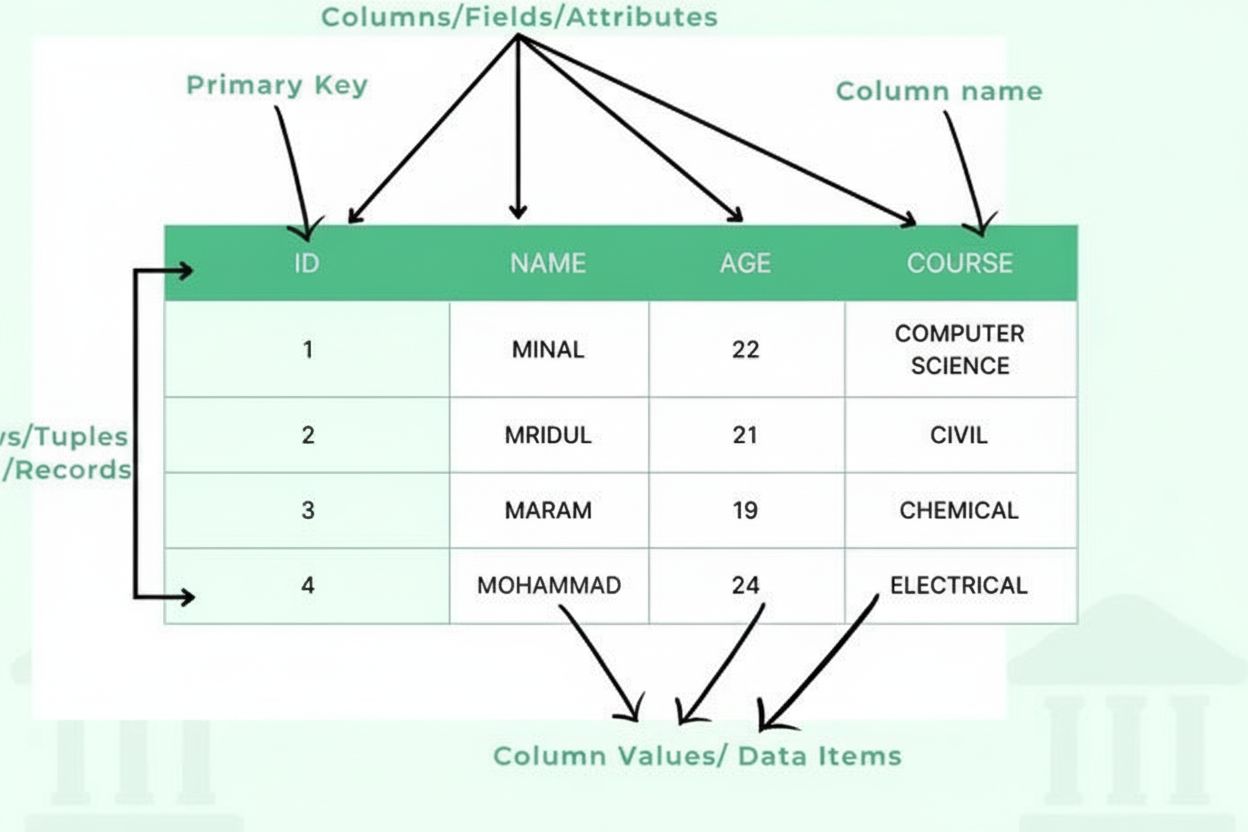
Uma tabela é um método estruturado de organização de dados que dispõe informações em um formato de grade bidimensional composta por linhas horizontais e colunas verticais, possibilitando armazenamento, recuperação e análise eficiente dos dados. As tabelas formam o bloco fundamental de bancos de dados relacionais, planilhas eletrônicas e sistemas de apresentação de dados, permitindo que os usuários localizem e comparem rapidamente informações relacionadas em várias dimensões.
Uma tabela é um método estruturado de organização de dados que dispõe informações em um formato de grade bidimensional composta por linhas horizontais e colunas verticais, possibilitando armazenamento, recuperação e análise eficiente dos dados. As tabelas formam o bloco fundamental de bancos de dados relacionais, planilhas eletrônicas e sistemas de apresentação de dados, permitindo que os usuários localizem e comparem rapidamente informações relacionadas em várias dimensões.
Uma tabela é uma estrutura de dados fundamental que organiza informações em um formato de grade bidimensional composta por linhas horizontais e colunas verticais. Em sua forma mais básica, uma tabela representa um conjunto de dados relacionados organizados de maneira estruturada, onde cada interseção de linha e coluna contém um único item de dado ou célula. Tabelas servem como a base de bancos de dados relacionais, planilhas eletrônicas, data warehouses e praticamente todo sistema que necessita de armazenamento e recuperação organizados de informações. O poder das tabelas reside em sua capacidade de permitir uma rápida varredura visual, comparação lógica de dados em múltiplas dimensões e acesso programático a informações específicas por meio de linguagens de consulta padronizadas. Seja em análises de negócios, pesquisas científicas ou plataformas de monitoramento de IA, as tabelas oferecem um formato universalmente compreendido para apresentar dados estruturados que podem ser facilmente interpretados por humanos e máquinas.
O conceito de organizar informações em linhas e colunas antecede a computação moderna em séculos. Civilizações antigas utilizavam formatos tabulares para registrar inventários, transações financeiras e observações astronômicas. Entretanto, a formalização das estruturas de tabela na computação surgiu com o desenvolvimento da teoria de bancos de dados relacionais por Edgar F. Codd em 1970, que revolucionou a forma como os dados poderiam ser armazenados e consultados. O modelo relacional estabeleceu que os dados deveriam ser organizados em tabelas com relações claramente definidas, mudando fundamentalmente os princípios do design de bancos de dados. Durante as décadas de 1980 e 1990, aplicativos de planilhas como Lotus 1-2-3 e Microsoft Excel democratizaram o uso de tabelas, tornando a organização tabular de dados acessível a usuários não técnicos. Atualmente, aproximadamente 97% das organizações utilizam aplicativos de planilhas para gestão e análise de dados, demonstrando a importância duradoura da organização de dados baseada em tabelas. A evolução continua com desenvolvimentos modernos em bancos de dados colunares, sistemas NoSQL e data lakes, que desafiam abordagens tradicionais orientadas a linhas, mas ainda mantêm estruturas fundamentais semelhantes a tabelas para organizar informações.
Uma tabela é composta por vários componentes estruturais essenciais que trabalham juntos para criar uma estrutura de dados organizada. Colunas (também chamadas de campos ou atributos) são dispostas verticalmente e representam categorias de informação, como “Nome do Cliente”, “Endereço de E-mail” ou “Data da Compra”. Cada coluna possui um tipo de dado definido que especifica que tipo de informação pode conter — inteiros, strings de texto, datas, decimais ou estruturas mais complexas. Linhas (também chamadas de registros ou tuplas) são dispostas horizontalmente e representam entradas ou entidades individuais, sendo que cada linha contém um registro completo. A interseção entre uma linha e uma coluna cria uma célula ou item de dado, que armazena uma única informação. Cabeçalhos de coluna identificam cada coluna e aparecem no topo da tabela, fornecendo contexto para os dados abaixo. Chaves primárias são colunas especiais que identificam exclusivamente cada linha, garantindo que não existam registros duplicados. Chaves estrangeiras estabelecem relações entre tabelas ao referenciar chaves primárias de outras tabelas. Essa organização hierárquica permite que bancos de dados mantenham a integridade dos dados, previnam redundâncias e suportem consultas complexas que recuperam informações com base em múltiplos critérios.
| Aspecto | Tabelas Orientadas a Linhas | Tabelas Orientadas a Colunas | Abordagens Híbridas |
|---|---|---|---|
| Método de Armazenamento | Dados armazenados e acessados por registros completos | Dados armazenados e acessados por colunas individuais | Combina benefícios das duas abordagens |
| Desempenho em Consultas | Otimizado para consultas transacionais que recuperam registros completos | Otimizado para consultas analíticas em colunas específicas | Desempenho equilibrado para cargas de trabalho mistas |
| Casos de Uso | OLTP (Processamento de Transações Online), operações de negócios | OLAP (Processamento Analítico Online), data warehousing | Analytics em tempo real, inteligência operacional |
| Exemplos de Bancos de Dados | MySQL, PostgreSQL, Oracle, SQL Server | Vertica, Cassandra, HBase, Parquet | Snowflake, BigQuery, Apache Iceberg |
| Eficiência de Compressão | Taxas de compressão menores devido à diversidade dos dados | Taxas de compressão maiores para valores similares em colunas | Compressão otimizada para padrões específicos |
| Desempenho de Escrita | Escritas rápidas para registros completos | Escritas mais lentas devido a atualizações em colunas | Desempenho de escrita equilibrado |
| Escalabilidade | Escala bem para volume de transações | Escala bem para volume de dados e complexidade de consultas | Escala para ambas as dimensões |
Em sistemas de gerenciamento de bancos de dados relacionais (SGBDR), as tabelas são implementadas como coleções estruturadas de linhas, onde cada linha segue um esquema predefinido. O esquema define a estrutura da tabela, especificando nomes de colunas, tipos de dados, restrições e relacionamentos. Quando dados são inseridos em uma tabela, o sistema de gerenciamento de banco de dados valida se cada valor corresponde ao tipo de dado da coluna e atende a quaisquer restrições definidas. Por exemplo, uma coluna definida como INTEGER rejeitará valores de texto, e uma coluna marcada como NOT NULL rejeitará entradas vazias. Índices são criados em colunas frequentemente consultadas para acelerar a recuperação dos dados, funcionando como referências organizadas que permitem ao banco localizar linhas específicas sem escanear toda a tabela. Normalização é um princípio de design que organiza tabelas para minimizar a redundância e melhorar a integridade dos dados, quebrando informações em tabelas relacionadas conectadas por chaves. Bancos de dados modernos suportam transações, que garantem que múltiplas operações em tabelas sejam bem-sucedidas ou falhem juntas, mantendo a consistência mesmo em falhas do sistema. O otimizador de consultas dos mecanismos de banco de dados analisa comandos SQL e determina a forma mais eficiente de acessar os dados da tabela, considerando índices disponíveis e estatísticas da tabela.
Tabelas servem como principal mecanismo para apresentar dados estruturados a usuários em formatos digitais e impressos. Em aplicações de inteligência de negócios e análise, as tabelas exibem métricas agregadas, indicadores de desempenho e registros de transações detalhados que permitem que tomadores de decisão compreendam conjuntos de dados complexos rapidamente. Pesquisas indicam que 83% dos profissionais de negócios utilizam tabelas de dados como principal ferramenta para análise de informações, pois as tabelas permitem comparação precisa de valores e reconhecimento de padrões. Tabelas HTML em sites utilizam marcação semântica com elementos <table>, <tr> (linha da tabela), <td> (dado da tabela) e <th> (cabeçalho da tabela) para estruturar dados tanto para exibição visual quanto interpretação programática. Aplicativos de planilhas como Microsoft Excel, Google Sheets e LibreOffice Calc expandem a funcionalidade básica de tabelas com fórmulas, formatação condicional e tabelas dinâmicas que permitem aos usuários realizar cálculos e reorganizar dados dinamicamente. Boas práticas de visualização de dados recomendam o uso de tabelas quando valores precisos são mais importantes que padrões visuais, ao comparar múltiplos atributos de registros individuais ou quando usuários precisam fazer buscas ou cálculos. A Iniciativa de Acessibilidade Web do W3C enfatiza que tabelas adequadamente estruturadas com cabeçalhos claros e marcação apropriada são essenciais para tornar dados acessíveis a pessoas com deficiência, especialmente aquelas que utilizam leitores de tela.
No contexto de plataformas de monitoramento de IA como a AmICited, as tabelas desempenham papel crítico na organização e apresentação de dados sobre como o conteúdo aparece em diferentes sistemas de IA. Tabelas de monitoramento acompanham métricas como frequência de citação, datas de aparição, fontes das plataformas de IA (ChatGPT, Perplexity, Google AI Overviews, Claude) e informações contextuais sobre como domínios e URLs são referenciados. Essas tabelas permitem que organizações entendam sua visibilidade de marca em respostas geradas por IA e identifiquem tendências sobre como diferentes sistemas citam ou referenciam seu conteúdo. A natureza estruturada das tabelas de monitoramento possibilita filtragem, ordenação e agregação dos dados de citação, permitindo responder a perguntas como “Quais das nossas URLs aparecem com mais frequência nas respostas do Perplexity?” ou “Como evoluiu nossa taxa de citação no último mês?”. Tabelas de dados em sistemas de monitoramento também facilitam comparações em múltiplas dimensões — comparando padrões de citação entre diferentes plataformas de IA, analisando o crescimento de citações ao longo do tempo ou identificando quais tipos de conteúdo recebem mais referências de IA. A capacidade de exportar dados de monitoramento das tabelas para relatórios, painéis e outras ferramentas de análise torna as tabelas indispensáveis para organizações que buscam entender e otimizar sua presença em conteúdos gerados por IA.
O design eficaz de tabelas exige consideração cuidadosa da estrutura, convenções de nomenclatura e princípios de organização de dados. Nomes de colunas devem ser claros e descritivos, refletindo com precisão os dados que contêm, evitando abreviações que possam confundir usuários ou desenvolvedores. Seleção de tipos de dados é crítica — escolher tipos apropriados previne entrada de dados inválidos e permite operações corretas de ordenação e comparação. Definição de chave primária garante que cada linha possa ser identificada de forma única, essencial para a integridade dos dados e estabelecimento de relações com outras tabelas. Normalização reduz a redundância de dados ao organizar informações em tabelas relacionadas, em vez de armazenar dados duplicados em múltiplas localizações. Estratégia de indexação deve equilibrar o desempenho das consultas com o custo de manter índices durante modificações nos dados. Documentação da estrutura da tabela, incluindo definições de colunas, tipos de dados, restrições e relacionamentos, é fundamental para a manutenção a longo prazo. Controle de acesso deve ser implementado para garantir que dados sensíveis nas tabelas estejam protegidos contra acesso não autorizado. Otimização de desempenho envolve monitorar tempos de execução das consultas e ajustar estruturas de tabelas, índices ou consultas para melhorar a eficiência. Procedimentos de backup e recuperação devem ser estabelecidos para proteger os dados das tabelas contra perda ou corrupção.
O futuro da organização de dados baseada em tabelas está evoluindo para atender a requisitos de dados cada vez mais complexos, mantendo os princípios fundamentais que tornam as tabelas eficazes. Formatos de armazenamento colunar como Apache Parquet e ORC estão se tornando padrão em ambientes de big data, otimizando tabelas para cargas de trabalho analíticas e mantendo a estrutura tabular. Dados semiestruturados em formatos JSON e XML são cada vez mais armazenados em colunas de tabelas, permitindo que elas acomodem tanto dados estruturados quanto flexíveis. Integração com aprendizado de máquina está permitindo que bancos de dados otimizem automaticamente estruturas de tabelas e execução de consultas com base nos padrões de uso. Plataformas de análise em tempo real estão expandindo tabelas para suportar dados de streaming e atualizações contínuas, indo além das operações tradicionais orientadas a lote. Bancos de dados nativos em nuvem estão redesenhando implementações de tabelas para aproveitar computação distribuída, permitindo que tabelas escalem por múltiplos servidores e regiões geográficas. Frameworks de governança de dados estão dando maior ênfase a metadados de tabelas, rastreamento de linhagem e métricas de qualidade para garantir confiabilidade dos dados. O surgimento de plataformas de dados impulsionadas por IA está criando novas oportunidades para que tabelas sirvam como fontes estruturadas para treinamento de modelos de machine learning, ao mesmo tempo que levanta questões sobre como as tabelas devem ser projetadas para fornecer dados de treinamento de alta qualidade. À medida que as organizações continuam a gerar volumes exponencialmente maiores de dados, as tabelas permanecem como a estrutura fundamental para organizar, consultar e analisar informações, com inovações focadas em melhorar desempenho, escalabilidade e integração com tecnologias modernas de dados.
Uma linha é uma disposição horizontal de dados que representa um único registro ou entidade, enquanto uma coluna é uma disposição vertical que representa um atributo ou campo específico compartilhado entre todos os registros. Em uma tabela de banco de dados, cada linha contém informações completas sobre uma entidade (como um cliente), e cada coluna contém um tipo de informação (como nome do cliente ou endereço de e-mail). Juntas, linhas e colunas criam a estrutura bidimensional que define uma tabela.
As tabelas são a estrutura organizacional fundamental em bancos de dados relacionais, permitindo armazenamento, recuperação e manipulação eficiente dos dados. Elas possibilitam que os bancos de dados mantenham a integridade dos dados por meio de esquemas estruturados, suportam consultas complexas em várias dimensões e facilitam relações entre diferentes entidades de dados por meio de chaves primárias e estrangeiras. As tabelas tornam possível organizar milhões de registros de forma eficiente computacionalmente e logicamente significativa para operações de negócios.
Uma tabela é composta por vários componentes essenciais: colunas (campos/atributos) que definem tipos e categorias de dados, linhas (registros/tuplas) que contêm entradas individuais, cabeçalhos que identificam cada coluna, itens de dados (células) que armazenam valores reais, chaves primárias que identificam exclusivamente cada linha e, potencialmente, chaves estrangeiras que estabelecem relações com outras tabelas. Cada componente exerce um papel crítico na manutenção da organização e integridade dos dados.
Em plataformas de monitoramento de IA como a AmICited, as tabelas são essenciais para organizar e apresentar dados sobre aparições de modelos de IA, citações e menções de marca em diferentes sistemas de IA. As tabelas permitem que sistemas de monitoramento exibam dados estruturados sobre quando e onde conteúdos aparecem em respostas de IA, facilitando o acompanhamento de métricas, a comparação de desempenho entre plataformas e a identificação de tendências sobre como sistemas de IA citam ou referenciam domínios e URLs específicos.
Bancos de dados orientados a linhas (como bancos relacionais tradicionais) armazenam e acessam dados por registros completos, tornando-os eficientes para transações onde é necessário todas as informações sobre uma entidade. Bancos de dados orientados a colunas armazenam dados por coluna, sendo mais rápidos para consultas analíticas que precisam de atributos específicos em muitos registros. A escolha entre essas abordagens depende se seu uso principal envolve operações transacionais ou consultas analíticas.
Tabelas acessíveis requerem marcação HTML adequada usando elementos semânticos como `
Colunas de tabelas podem armazenar diversos tipos de dados incluindo inteiros, números de ponto flutuante, strings/textos, datas e horários, booleanos e tipos cada vez mais complexos como JSON ou XML. Cada coluna possui um tipo de dado definido que restringe quais valores podem ser inseridos, garantindo consistência dos dados e possibilitando operações corretas de ordenação e comparação. Alguns bancos de dados também suportam tipos especializados como dados geográficos, arrays ou tipos personalizados definidos pelo usuário.
Comece a rastrear como os chatbots de IA mencionam a sua marca no ChatGPT, Perplexity e outras plataformas. Obtenha insights acionáveis para melhorar a sua presença de IA.
Saiba o que são gráficos, seus tipos e como transformam dados brutos em insights acionáveis. Guia essencial sobre formatos de visualização de dados para análise...
Visualização de dados é a representação gráfica de dados usando gráficos, diagramas e dashboards. Aprenda como dados visuais transformam informações complexas e...
Definição de infográfico: representação visual que combina imagens, gráficos e texto para apresentar dados de forma clara. Saiba sobre tipos, princípios de desi...
Consentimento de Cookies
Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.