Card de Referință AI Crawler: Toți Boții dintr-o Privire
Ghid complet de referință pentru crawlerele și boții AI. Identifică GPTBot, ClaudeBot, Google-Extended și peste 20 de alte crawlere AI cu user agent, rate de crawl și strategii de blocare.
Publicat la Jan 3, 2026.Ultima modificare la Jan 3, 2026 la 3:24 am
Înțelegerea diferenței dintre crawlerele AI și crawlerele tradiționale
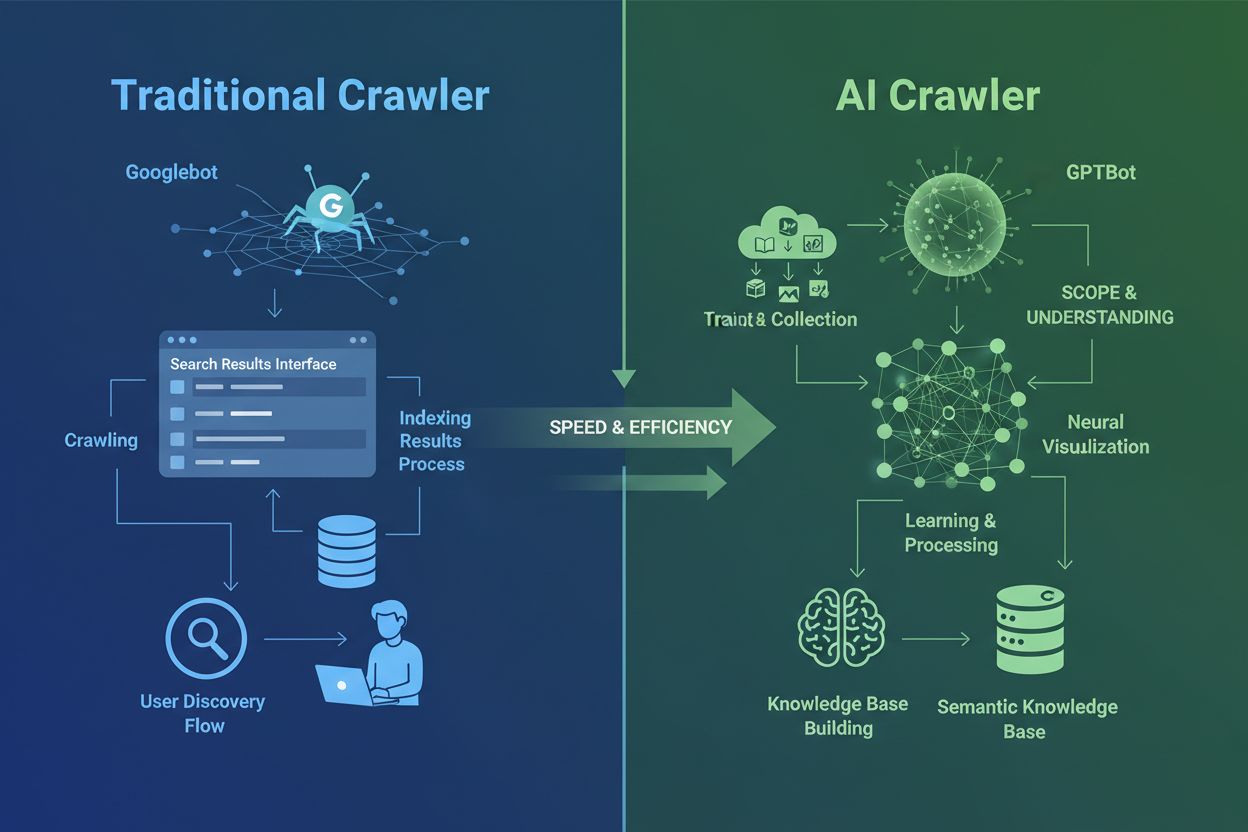
Crawlerele AI sunt fundamental diferite de crawlerele tradiționale ale motoarelor de căutare pe care le cunoști de zeci de ani. În timp ce Googlebot și Bingbot indexează conținutul pentru a ajuta utilizatorii să găsească informații prin rezultate de căutare, crawlerele AI precum GPTBot și ClaudeBot colectează date special pentru a antrena modele lingvistice mari. Această distincție este crucială: crawlerele tradiționale creează căi pentru descoperirea umană, în timp ce crawlerele AI alimentează bazele de cunoștințe ale sistemelor de inteligență artificială. Conform datelor recente, crawlerele AI reprezintă acum aproape 80% din tot traficul de boți către site-uri, cu crawlerele de antrenament consumând cantități vaste de conținut și trimițând trafic de referință minim înapoi publisherilor. Spre deosebire de crawlerele tradiționale care au dificultăți cu site-urile dinamice pline de JavaScript, crawlerele AI folosesc machine learning avansat pentru a înțelege contextual conținutul, asemănător cu modul în care ar face-o un cititor uman. Acestea pot interpreta sensul, tonul și scopul fără actualizări manuale de configurare. Aceasta reprezintă un salt calitativ în tehnologia de indexare web, care îi obligă pe deținătorii de site-uri să își regândească complet strategiile de management ale crawlerelor.
Ecosistemul principal al crawlerelor AI
Peisajul crawlerelor AI a devenit tot mai aglomerat pe măsură ce companiile mari de tehnologie se grăbesc să își construiască propriile modele lingvistice mari. OpenAI, Anthropic, Google, Meta, Amazon, Apple și Perplexity operează fiecare mai multe crawlere specializate, fiecare având funcții distincte în cadrul ecosistemului AI propriu. Companiile lansează mai multe crawlere deoarece scopuri diferite necesită comportamente diferite: unele crawlere se concentrează pe colectarea masivă de date pentru antrenare, altele se ocupă de indexare în timp real, iar altele preiau conținut la cerere atunci când utilizatorii îl solicită. Înțelegerea acestui ecosistem presupune recunoașterea a trei categorii principale de crawlere: crawlere de antrenament care colectează date pentru îmbunătățirea modelelor, crawlere de căutare și citare care indexează conținutul pentru experiențe de căutare AI, și fetchere activate de utilizator ce preiau conținut la solicitarea explicită a utilizatorilor prin asistenți AI. Tabelul următor oferă o privire rapidă asupra principalilor jucători:
Companie
Nume Crawler
Scop Principal
Rată Crawl
Date de Antrenament
OpenAI
GPTBot
Antrenament model
100 pagini/oră
Da
OpenAI
ChatGPT-User
Cereri utilizator în timp real
2400 pagini/oră
Nu
OpenAI
OAI-SearchBot
Indexare căutare
150 pagini/oră
Nu
Anthropic
ClaudeBot
Antrenament model
500 pagini/oră
Da
Anthropic
Claude-User
Acces web în timp real
<10 pagini/oră
Nu
Google
Google-Extended
Antrenament AI Gemini
Variabil
Da
Google
Gemini-Deep-Research
Funcție de cercetare
<10 pagini/oră
Nu
Meta
Meta-ExternalAgent
Antrenament model AI
1100 pagini/oră
Da
Amazon
Amazonbot
Îmbunătățirea serviciului
1050 pagini/oră
Da
Perplexity
PerplexityBot
Indexare căutare
150 pagini/oră
Nu
Apple
Applebot-Extended
Antrenament AI
<10 pagini/oră
Da
Common Crawl
CCBot
Set de date deschis
<10 pagini/oră
Da
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
OpenAI operează trei crawlere distincte, fiecare cu roluri specifice în ecosistemul ChatGPT. Înțelegerea acestor crawlere este esențială deoarece GPTBot de la OpenAI este unul dintre cele mai agresive și răspândite crawlere AI de pe internet:
GPTBot – Crawlerul principal de antrenament al OpenAI care colectează sistematic date publice pentru a antrena și îmbunătăți modelele GPT, inclusiv ChatGPT și GPT-4o. Acest crawler operează la aproximativ 100 pagini pe oră și respectă directivele robots.txt. OpenAI publică adresele IP oficiale la https://openai.com/gptbot.json pentru verificare.
ChatGPT-User – Acest crawler apare atunci când un utilizator real interacționează cu ChatGPT și îi solicită accesarea unei anumite pagini. Operează la rate mult mai mari (până la 2400 pagini/oră) deoarece este declanșat de acțiunile utilizatorului, nu de crawling sistematic. Conținutul accesat prin ChatGPT-User nu este folosit pentru antrenamentul modelelor, fiind valoros pentru vizibilitate în timp real în rezultatele ChatGPT.
OAI-SearchBot – Conceput special pentru funcționalitatea de căutare a ChatGPT, acest crawler indexează conținut pentru rezultate de căutare în timp real fără a colecta date pentru antrenament. Operează la aproximativ 150 pagini/oră și ajută conținutul tău să apară în ChatGPT atunci când utilizatorii pun întrebări relevante.
Crawlerele OpenAI respectă directivele robots.txt și operează din intervale IP verificate, fiind relativ ușor de gestionat comparativ cu competitorii mai puțin transparenți.
Crawlerele Claude de la Anthropic
Anthropic, compania din spatele Claude AI, operează mai multe crawlere cu scopuri și niveluri de transparență diferite. Compania a fost mai puțin transparentă în documentație comparativ cu OpenAI, însă comportamentul crawlerelor este bine documentat prin analiza logurilor serverului:
ClaudeBot – Principalul crawler de antrenament al Anthropic care colectează conținut web pentru a îmbunătăți baza de cunoștințe și capacitățile lui Claude. Acest crawler operează la aproximativ 500 pagini/oră și este ținta principală dacă dorești să previi utilizarea conținutului tău pentru antrenarea modelelor Claude. Stringul complet user agent este Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com).
Claude-User – Activat când utilizatorii Claude solicită acces web în timp real, acest crawler preia conținut la cerere cu volum minim. Respectă autentificarea și nu încearcă să ocolească restricții, fiind relativ benign din perspectiva resurselor.
Claude-SearchBot – Susține capabilitățile interne de căutare ale lui Claude, ajutând conținutul tău să apară în rezultate atunci când utilizatorii pun întrebări. Acest crawler are volum foarte mic și servește mai ales scopuri de indexare, nu de antrenament.
O preocupare critică privind crawlerele Anthropic este raportul crawl-vizită-referință: datele Cloudflare arată că, pentru fiecare referință trimisă de Anthropic către un site, crawlerele sale au vizitat deja aproximativ 38.000 – 70.000 de pagini. Acest dezechilibru masiv înseamnă că al tău conținut este consumat mult mai agresiv decât este citat, ridicând întrebări importante despre compensarea corectă a utilizării conținutului.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Crawlerele de antrenament AI ale Google
Abordarea Google privind crawling-ul AI diferă semnificativ de cea a competitorilor deoarece compania menține o separare strictă între indexarea pentru căutare și antrenamentul AI. Google-Extended este crawlerul specific responsabil cu colectarea datelor pentru antrenarea Gemini (fostul Bard) și a altor produse AI Google, complet separat de Googlebot-ul tradițional:
User agent-ul pentru Google-Extended este: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Google-Extended/1.0. Această separare este intenționată și benefică pentru deținătorii de site-uri deoarece poți bloca Google-Extended prin robots.txt fără a afecta deloc vizibilitatea în Google Search. Google afirmă oficial că blocarea Google-Extended nu are niciun impact asupra pozițiilor sau includerii în AI Overviews, deși unii webmasteri au semnalat preocupări ce merită monitorizate. Gemini-Deep-Research este un alt crawler Google care susține funcția de research a Gemini, cu volum foarte scăzut și impact minim asupra resurselor. Un avantaj tehnic semnificativ al crawlerelor Google este capacitatea lor de a executa JavaScript și de a reda conținut dinamic, spre deosebire de majoritatea competitorilor. Asta înseamnă că Google-Extended poate indexa eficient aplicații React, Vue sau Angular, în timp ce GPTBot de la OpenAI și ClaudeBot de la Anthropic nu pot. Pentru proprietarii de site-uri cu aplicații complexe în JavaScript, această distincție contează semnificativ pentru vizibilitatea AI.
Alte crawlere AI importante
Dincolo de giganții tech, numeroase alte organizații operează crawlere AI care merită atenție. Meta-ExternalAgent, lansat discret în iulie 2024, scrapează conținut web pentru antrenarea modelelor AI ale Meta și pentru îmbunătățirea produselor din Facebook, Instagram și WhatsApp. Acest crawler operează la aproximativ 1100 pagini/oră și a primit mai puțină atenție publică față de competitori, deși este foarte agresiv. Bytespider, operat de ByteDance (compania-mamă TikTok), a devenit unul dintre cele mai agresive crawlere de pe internet după lansarea din aprilie 2024. Monitorizarea terță parte sugerează că Bytespider crawlează mult mai agresiv decât GPTBot sau ClaudeBot, deși multiplicatorii exacți variază. Unele rapoarte indică faptul că nu respectă mereu directivele robots.txt, făcând blocarea pe IP mai fiabilă.
Crawlerele Perplexity includ PerplexityBot pentru indexare căutare și Perplexity-User pentru fetch real-time. Perplexity a avut rapoarte ocazionale că ignoră directivele robots.txt, deși compania susține conformitatea. Amazonbot alimentează capabilitățile de răspuns la întrebări ale Alexa și respectă protocolul robots.txt, operând la aproximativ 1050 pagini/oră. Applebot-Extended, introdus în iunie 2024, determină modul în care conținutul deja indexat de Applebot va fi folosit pentru antrenarea AI Apple, deși nu crawlează direct pagini web. CCBot, operat de Common Crawl (o organizație non-profit), construiește arhive web deschise folosite de mai multe companii AI inclusiv OpenAI, Google, Meta și Hugging Face. Crawlere emergente de la companii precum xAI (Grok), Mistral și DeepSeek încep să apară în logurile serverelor, semnalând extinderea continuă a ecosistemului crawlerelor AI.
Tabel complet de referință pentru crawlerele AI
Mai jos este un tabel comprensiv cu crawlerele AI verificate, scopurile, stringurile user agent și sintaxa robots.txt pentru blocare. Tabelul este actualizat regulat pe baza analizei logurilor și documentației oficiale. Fiecare intrare a fost verificată cu liste IP oficiale, când sunt disponibile:
Nume Crawler
Companie
Scop
User Agent
Rată Crawl
Verificare IP
Sintaxă robots.txt
GPTBot
OpenAI
Colectare date antrenament
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot)
100/oră
✓ Oficial
User-agent: GPTBot Disallow: /
ChatGPT-User
OpenAI
Cereri utilizator în timp real
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0
2400/oră
✓ Oficial
User-agent: ChatGPT-User Disallow: /
OAI-SearchBot
OpenAI
Indexare căutare
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36; compatible; OAI-SearchBot/1.3
150/oră
✓ Oficial
User-agent: OAI-SearchBot Disallow: /
ClaudeBot
Anthropic
Colectare date antrenament
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
500/oră
✓ Oficial
User-agent: ClaudeBot Disallow: /
Claude-User
Anthropic
Acces web în timp real
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Claude-User/1.0)
<10/oră
✗ Indisponibil
User-agent: Claude-User Disallow: /
Claude-SearchBot
Anthropic
Indexare căutare
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Claude-SearchBot/1.0)
<10/oră
✗ Indisponibil
User-agent: Claude-SearchBot Disallow: /
Google-Extended
Google
Antrenament AI Gemini
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Google-Extended/1.0)
Variabil
✓ Oficial
User-agent: Google-Extended Disallow: /
Gemini-Deep-Research
Google
Funcție de cercetare
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Gemini-Deep-Research)
<10/oră
✓ Oficial
User-agent: Gemini-Deep-Research Disallow: /
Bingbot
Microsoft
Bing search & Copilot
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0)
Nu toate crawlerele AI au același scop și înțelegerea acestor diferențe este esențială pentru decizii informate de blocare. Crawlerele de antrenament reprezintă aproximativ 80% din tot traficul de boți AI și colectează conținut special pentru a construi seturi de date pentru dezvoltarea modelelor lingvistice mari. Odată ce conținutul tău ajunge într-un set de date de antrenament, el devine parte a bazei de cunoștințe permanente a modelului, reducând posibil nevoia utilizatorilor de a vizita site-ul tău. Crawlerele de antrenament precum GPTBot, ClaudeBot și Meta-ExternalAgent operează cu volum mare și modele sistematice, returnând trafic de referință minim sau zero publisherilor.
Crawlerele de căutare și citare indexează conținutul pentru experiențe de căutare AI și pot trimite ceva trafic publisherilor prin citări. Când utilizatorii întreabă în ChatGPT sau Perplexity, aceste crawlere ajută la afișarea surselor relevante. Spre deosebire de cele de antrenament, crawlerele de căutare precum OAI-SearchBot și PerplexityBot operează la volum moderat, cu comportament axat pe regăsire și pot include atribuire și link-uri. Fetcherele activate de utilizator pornesc doar când utilizatorii solicită explicit conținut prin asistenți AI. Când cineva inserează un URL în ChatGPT sau cere Perplexity să analizeze o anumită pagină, aceste fetchere preiau conținutul la cerere. Ele operează la volum foarte mic cu cereri individuale, nu crawling sistematic, iar majoritatea companiilor AI confirmă că acestea nu sunt folosite pentru antrenarea modelelor. Înțelegerea acestor categorii te ajută să iei decizii strategice privind ce crawlere să permiți și pe care să le blochezi în funcție de prioritățile afacerii tale.
Cum identifici crawlerele pe site-ul tău
Primul pas în gestionarea crawlerelor AI este să înțelegi care te vizitează efectiv. Logurile de acces ale serverului conțin înregistrări detaliate ale fiecărei cereri, inclusiv stringul user agent ce identifică crawlerul. Majoritatea panourilor de control de găzduire oferă instrumente de analiză a logurilor, dar poți accesa și logurile brute direct. Pentru serverele Apache, logurile sunt de obicei la /var/log/apache2/access.log, iar pentru Nginx la /var/log/nginx/access.log. Poți filtra aceste loguri cu grep pentru a găsi activitate crawler:
grep -i "gptbot\|claudebot\|google-extended\|bytespider" /var/log/apache2/access.log | head -20
Această comandă afișează cele mai recente 20 de cereri de la crawlere AI majore. Google Search Console oferă statistici de crawling pentru boții Google, deși afișează doar crawlerele Google. Cloudflare Radar oferă perspective globale despre traficul bot AI și te poate ajuta să identifici care crawlere sunt cele mai active. Pentru a verifica dacă un crawler este legitim sau falsificat, verifică adresa IP a cererii față de listele IP oficiale publicate de companiile mari. OpenAI publică IP-urile verificate la https://openai.com/gptbot.json, Amazon la https://developer.amazon.com/amazonbot/ip-addresses/, iar alții au liste similare. Un crawler fals care se dă drept unul legitim de pe o adresă IP neverificată trebuie blocat imediat, deoarece probabil reprezintă activitate de scraping malițios.
Ghid de implementare robots.txt
Fișierul robots.txt este principalul tău instrument pentru controlul accesului crawlerelor. Acest fișier text simplu, plasat în directorul rădăcină al site-ului, spune crawlerelor ce părți din site pot accesa. Pentru a bloca crawlere AI specifice, adaugă intrări ca acestea:
# Blochează GPTBot de la OpenAI
User-agent: GPTBot
Disallow: /
# Blochează ClaudeBot de la Anthropic
User-agent: ClaudeBot
Disallow: /
# Blochează antrenamentul AI Google (nu Googlebot)
User-agent: Google-Extended
Disallow: /
# Blochează Common Crawl
User-agent: CCBot
Disallow: /
Poți permite crawlerele, dar seta și rate limit pentru a preveni supraîncărcarea serverului:
Aceasta îi spune lui GPTBot să aștepte 10 secunde între cereri și să nu acceseze directorul privat. Pentru o abordare echilibrată care permite crawlerele de căutare și blochează pe cele de antrenament:
# Permite motoare tradiționale de căutare
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Blochează toate crawlerele AI de antrenament
User-agent: GPTBot
User-agent: ClaudeBot
User-agent: CCBot
User-agent: Google-Extended
User-agent: Bytespider
User-agent: Meta-ExternalAgent
Disallow: /
# Permite crawlerele de căutare AI
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
Majoritatea crawlerelor AI de încredere respectă directivele robots.txt, deși unele agresive le ignoră complet. De aceea robots.txt nu este suficient pentru protecție totală.
Strategii avansate de blocare
Robots.txt este recomandare, nu obligație, adică crawlerele pot ignora directivele dacă doresc. Pentru protecție mai puternică împotriva crawlerelor care nu respectă robots.txt, implementează blocare pe bază de IP la nivel de server. Această abordare este mai fiabilă deoarece este mai greu de falsificat o adresă IP decât un user agent. Poți pune pe whitelist IP-uri verificate din sursele oficiale și bloca toate celelalte cereri care pretind a fi crawlere AI.
Pentru servere Apache, folosește reguli .htaccess pentru a bloca crawlerele la nivel de server:
Aceasta returnează un răspuns 403 Forbidden pentru user agent-urile potrivite, indiferent de robots.txt. Regulile de firewall oferă un strat suplimentar, permițând doar intervale IP verificate. Majoritatea firewall-urilor de aplicație web și furnizorii de hosting permit crearea de reguli ce acceptă cereri doar din IP-uri verificate pentru crawlere AI. Meta tag-urile HTML oferă control granular la nivel de pagină. Amazon și unele alte crawlere respectă directiva noarchive:
<metaname="robots"content="noarchive">
Aceasta spune crawlerelor să nu folosească pagina pentru antrenarea modelelor, permițând totuși alte tipuri de indexare. Alege metoda de blocare în funcție de capabilitățile tehnice și crawlerele țintite. Blocarea pe IP este cea mai sigură, dar necesită setup tehnic, în timp ce robots.txt este cel mai ușor de implementat dar mai puțin eficient împotriva crawlerelor neconforme.
Monitorizare și verificare
Implementarea blocajelor pentru crawlere este doar jumătate din ecuație; trebuie să și verifici eficiența. Monitorizarea regulată te ajută să identifici rapid probleme și să depistezi crawlere noi necunoscute anterior. Verifică logurile serverului săptămânal pentru activitate bot neobișnuită, căutând stringuri user agent ce conțin “bot”, “crawler”, “spider” sau nume de companii precum “GPT”, “Claude” sau “Perplexity”. Setează alerte pentru creșteri bruște de trafic bot ce pot indica crawlere noi sau comportament agresiv. Google Search Console afișează statistici de crawl pentru boții Google, ajutând la monitorizarea activității Googlebot și Google-Extended. Cloudflare Radar oferă perspective globale asupra traficului crawlerelor AI și ajută la identificarea celor emergente.
Pentru a verifica dacă blocajele robots.txt funcționează, accesează fișierul robots.txt direct la yoursite.com/robots.txt și confirmă toate user agent-urile și directivele. Pentru blocajele la nivel de server, monitorizează logurile pentru cereri din crawlere blocate. Dacă vezi cereri de la crawlere pe care le-ai blocat, ele fie ignoră directivele, fie își falsifică user agent-ul. Testează implementările verificând accesul crawlerelor în analytics și logurile serverului. Revizuirile trimestriale sunt esențiale deoarece peisajul crawlerelor AI evoluează rapid. Apar constant crawlere noi, cele existente își schimbă user agent-ul, iar companiile introduc boți noi fără notificare. Programează revizuiri periodice ale listei de blocare pentru a prinde noutăți și a te asigura că implementarea rămâne actuală.
Monitorizarea citărilor AI cu AmICited.com
Pe lângă gestionarea accesului crawlerelor, este la fel de important să înțelegi cum sistemele AI citează și refer
Întrebări frecvente
Care este diferența dintre crawlerele AI și crawlerele motoarelor de căutare?
Crawlerele AI precum GPTBot și ClaudeBot colectează conținut special pentru a antrena modele lingvistice mari, în timp ce crawlerele motoarelor de căutare precum Googlebot indexează conținutul pentru ca oamenii să îl poată găsi în rezultate de căutare. Crawlerele AI alimentează bazele de cunoștințe ale sistemelor AI, în timp ce crawlerele de căutare ajută utilizatorii să descopere conținutul tău. Diferența cheie este scopul: antrenament versus regăsire.
Blocarea crawlerelor AI îmi va afecta pozițiile în motoarele de căutare?
Nu, blocarea crawlerelor AI nu îți va afecta pozițiile tradiționale în căutare. Crawlerele AI precum GPTBot și ClaudeBot sunt complet separate de crawlerele motoarelor de căutare precum Googlebot. Poți bloca Google-Extended (pentru antrenament AI) și totuși să lași Googlebot (pentru căutare). Fiecare crawler are un rol diferit și blocarea unuia nu îl afectează pe celălalt.
Cum pot afla ce crawlere AI îmi vizitează site-ul?
Verifică logurile de acces ale serverului pentru a vedea ce user agent vizitează site-ul tău. Caută nume de boți precum GPTBot, ClaudeBot, CCBot și Bytespider în stringurile user agent. Majoritatea panourilor de control de găzduire oferă instrumente de analiză a logurilor. Poți folosi și Google Search Console pentru a monitoriza activitatea de crawl, însă acesta afișează doar crawlerele Google.
Toate crawlerele AI respectă directivele robots.txt?
Nu toate crawlerele AI respectă robots.txt în mod egal. GPTBot de la OpenAI, ClaudeBot de la Anthropic și Google-Extended urmează în general regulile robots.txt. Bytespider și PerplexityBot au avut rapoarte că nu respectă mereu directivele robots.txt. Pentru crawlerele care nu respectă robots.txt va trebui să implementezi blocare pe bază de IP la nivel de server prin firewall sau fișierul .htaccess.
Ar trebui să blochez toate crawlerele AI sau doar pe cele de antrenament?
Decizia depinde de obiectivele tale. Blochează crawlerele de antrenament dacă ai conținut proprietar sau resurse server limitate. Permite crawlerele de căutare dacă vrei vizibilitate în rezultate de căutare AI și chatboți, ce pot aduce trafic și autoritate. Multe afaceri adoptă o abordare selectivă, permițând anumite crawlere și blocând pe cele agresive precum Bytespider.
Cât de des ar trebui să actualizez lista de blocare pentru crawlerele AI?
Apar regulat crawlere AI noi, deci revizuiește și actualizează lista de blocare cel puțin trimestrial. Urmărește resurse precum proiectul ai.robots.txt pe GitHub pentru liste întreținute de comunitate. Verifică logurile serverului lunar pentru a identifica crawlere noi care îți accesează site-ul și nu sunt în configurația curentă. Peisajul crawlerelor AI evoluează rapid, iar strategia ta trebuie să țină pasul cu el.
Pot verifica dacă un crawler este legitim sau falsificat?
Da, verifică adresa IP a cererii față de listele oficiale publicate de companii mari. OpenAI publică IP-uri verificate la https://openai.com/gptbot.json, Amazon la https://developer.amazon.com/amazonbot/ip-addresses/, iar alții au liste similare. Un crawler care falsifică un user agent legitim de pe o adresă IP neverificată trebuie blocat imediat, deoarece probabil reprezintă scraping malițios.
Ce impact au crawlerele AI asupra performanței site-ului meu?
Crawlerele AI pot consuma lățime de bandă și resurse de server semnificative. Bytespider și Meta-ExternalAgent sunt printre cele mai agresive crawlere. Unii publisheri raportează reducerea consumului de bandă de la 800GB la 200GB pe zi prin blocarea crawlerelor AI, economisind aproximativ 1.500 $ pe lună. Monitorizează resursele serverului în perioadele de vârf și implementează limitarea ratei pentru boții agresivi, dacă este necesar.
Preia Controlul Vizibilității Tale în AI
Monitorizează ce crawlere AI citează conținutul tău și optimizează-ți vizibilitatea în ChatGPT, Perplexity, Google Gemini și altele.
Ce este frecvența de crawl pentru căutarea AI? Înțelegerea comportamentului bot-urilor AI
Află cum determină crawlerele AI frecvența de crawl pentru site-ul tău. Descoperă cum ChatGPT, Perplexity și alte motoare AI accesează conținutul diferit față d...
Randare pe Server vs CSR: Impactul asupra Vizibilității în AI
Descoperă cum strategiile de randare SSR și CSR afectează vizibilitatea pentru crawlerele AI, mențiunile brandului în ChatGPT și Perplexity și prezența ta gener...
Factori tehnici SEO care influențează vizibilitatea în AI în ChatGPT, Perplexity & AI Search
Descoperă factorii tehnici SEO esențiali care îți influențează vizibilitatea în motoarele de căutare AI precum ChatGPT, Perplexity și Google AI Mode. Află cum v...
10 min citire
Consimțământ Cookie Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.