
Card de Referință AI Crawler: Toți Boții dintr-o Privire
Ghid complet de referință pentru crawlerele și boții AI. Identifică GPTBot, ClaudeBot, Google-Extended și peste 20 de alte crawlere AI cu user agent, rate de cr...
14 min citire

Descoperă diferențele critice dintre crawlerii de antrenament AI și crawlerii de căutare. Află cum acestea influențează vizibilitatea conținutului tău, strategiile de optimizare și citările AI.
Crawlerii motoarelor de căutare precum Googlebot și Bingbot sunt coloana vertebrală a operațiunilor tradiționale ale motoarelor de căutare. Acești roboți automatizați navighează sistematic web-ul, descoperind și indexând conținutul pentru a determina ce apare în paginile cu rezultate ale motoarelor de căutare (SERP). Googlebot, operat de Google, este cel mai cunoscut și activ crawler de căutare, urmat de Bingbot de la Microsoft și YandexBot de la Yandex. Acești crawleri au capabilități sofisticate care le permit să execute JavaScript, să redea conținut dinamic și să înțeleagă structuri complexe de site-uri. Vizitează frecvent site-urile, în funcție de factori precum autoritatea site-ului, prospețimea conținutului și istoricul actualizărilor, site-urile cu autoritate ridicată fiind crawl-uite mai des. Scopul principal al crawlerilor de căutare este indexarea conținutului pentru clasificare, ceea ce înseamnă că evaluează paginile în funcție de relevanță, calitate și semnale privind experiența utilizatorului.
| Tip crawler | Scop principal | Suport JavaScript | Frecvență crawling | Obiectiv |
|---|---|---|---|---|
| Googlebot | Indexare pentru clasamente în căutare | Da (cu limitări) | Frecvent, în funcție de autoritate | Clasare & vizibilitate |
| Bingbot | Indexare pentru clasamente în căutare | Da (cu limitări) | Regulată, bazată pe actualizări de conținut | Clasare & vizibilitate |
| YandexBot | Indexare pentru clasamente în căutare | Da (cu limitări) | Regulată, bazată pe semnale ale site-ului | Clasare & vizibilitate |
Crawlerii de antrenament AI reprezintă o categorie fundamental diferită de roboți web, concepuți pentru a colecta date pentru antrenarea modelelor lingvistice mari (LLM), nu pentru indexarea căutării. GPTBot, operat de OpenAI, este cel mai proeminent crawler de antrenament AI, alături de ClaudeBot de la Anthropic, PetalBot de la Huawei și CCBot de la Common Crawl. Spre deosebire de crawlerii de căutare care urmăresc clasificarea conținutului, crawlerii de antrenament AI se concentrează pe colectarea de informații de calitate, bogate contextual, pentru a îmbunătăți baza de cunoștințe și capacitățile de generare a răspunsurilor ale modelelor AI. Acești crawleri operează de obicei mai rar decât crawlerii de căutare, vizitând un site doar o dată la câteva săptămâni sau luni, și prioritizează calitatea conținutului în detrimentul volumului. Distincția este crucială: deși conținutul tău poate fi indexat temeinic de Googlebot pentru vizibilitate în căutare, el poate fi doar parțial sau rar crawl-uit de GPTBot pentru antrenamentul modelelor AI.
| Tip crawler | Scop principal | Suport JavaScript | Frecvență crawling | Obiectiv |
|---|---|---|---|---|
| GPTBot | Colectează date pentru antrenarea LLM | Nu | Rar, selectiv | Calitatea datelor de antrenament |
| ClaudeBot | Colectează date pentru antrenarea LLM | Nu | Rar, selectiv | Calitatea datelor de antrenament |
| PetalBot | Colectează date pentru antrenarea LLM | Nu | Rar, selectiv | Calitatea datelor de antrenament |
| CCBot | Colectează date pentru Common Crawl | Nu | Rar, selectiv | Calitatea datelor de antrenament |
Distincțiile tehnice dintre crawlerii de căutare și cei de antrenament AI generează implicații semnificative pentru vizibilitatea conținutului. Cea mai importantă diferență este executarea JavaScript: crawlerii de căutare precum Googlebot pot executa JavaScript (deși cu anumite limitări), permițându-le să vadă conținutul redat dinamic. Crawlerii de antrenament AI, în schimb, nu execută deloc JavaScript—ei parcurg doar HTML-ul brut disponibil la încărcarea inițială a paginii. Această diferență fundamentală înseamnă că orice conținut încărcat dinamic prin scripturi pe partea clientului rămâne complet invizibil pentru crawlerii AI. În plus, crawlerii de căutare respectă bugetele de crawling și prioritizează paginile pe baza arhitecturii site-ului și a legăturilor interne, în timp ce crawlerii AI folosesc modele de crawling mai selective, centrate pe calitate. Crawlerii de căutare respectă de obicei cu strictețe regulile robots.txt, în timp ce unii crawleri AI au fost istoric mai puțin transparenți în privința conformității. Frecvența crawling-ului diferă dramatic: crawlerii de căutare vizitează site-urile active de mai multe ori pe săptămână sau chiar zilnic, pe când crawlerii AI pot vizita doar o dată la câteva săptămâni sau luni. Mai mult, crawlerii de căutare sunt proiectați să înțeleagă semnalele de clasare și metricele experienței utilizatorului, în timp ce crawlerii AI se concentrează pe extragerea de text curat și bine structurat pentru antrenarea modelelor.
| Caracteristică | Crawleri de căutare | Crawleri de antrenament AI |
|---|---|---|
| Executare JavaScript | Da (cu limitări) | Nu |
| Frecvență crawling | Mare (de mai multe ori pe săptămână) | Mică (o dată la câteva săptămâni) |
| Parcurgere conținut | Randare completă a paginii | Doar HTML brut |
| Respectare robots.txt | Strictă | Variabilă |
| Focalizare buget crawling | Prioritizare pe baza autorității | Selecție pe baza calității |
| Gestionare conținut dinamic | Poate reda și indexa | Ratează complet |
| Scop principal | Clasare & vizibilitate în căutare | Colectare date pentru antrenament |
| Toleranță timeout | Mai mare (permite randare complexă) | Strânsă (1-5 secunde) |
Incapacitatea crawlerilor AI de a executa JavaScript creează un decalaj critic de vizibilitate care afectează multe site-uri moderne. Când un site se bazează pe JavaScript pentru a încărca conținut dinamic—cum ar fi descrierile produselor, recenziile clienților, informațiile despre prețuri sau imaginile—acel conținut devine invizibil pentru crawlerii AI. Aceasta este deosebit de problematică pentru aplicațiile de tip single-page (SPA) construite cu React, Vue sau Angular, unde cea mai mare parte a conținutului este încărcat pe partea clientului după servirea HTML-ului inițial. De exemplu, un site de ecommerce poate afișa disponibilitatea produselor și prețurile prin JavaScript, ceea ce înseamnă că GPTBot vede doar o pagină goală sau un schelet HTML de bază. În mod similar, site-urile care folosesc încărcare la cerere pentru imagini sau scroll infinit pentru conținut nu vor avea acele elemente accesate deloc de crawlerii AI. Impactul de business este substanțial: dacă detaliile produselor, mărturiile clienților sau conținutul cheie sunt ascunse în spatele JavaScript-ului, sistemele AI precum ChatGPT și Perplexity nu vor avea acces la acea informație când generează răspunsuri. Aceasta creează o situație în care conținutul tău poate avea un clasament bun în Google, dar să fie complet absent din răspunsurile generate de AI, făcându-te practic invizibil pentru o categorie în creștere de utilizatori care se bazează pe AI pentru a descoperi informații.
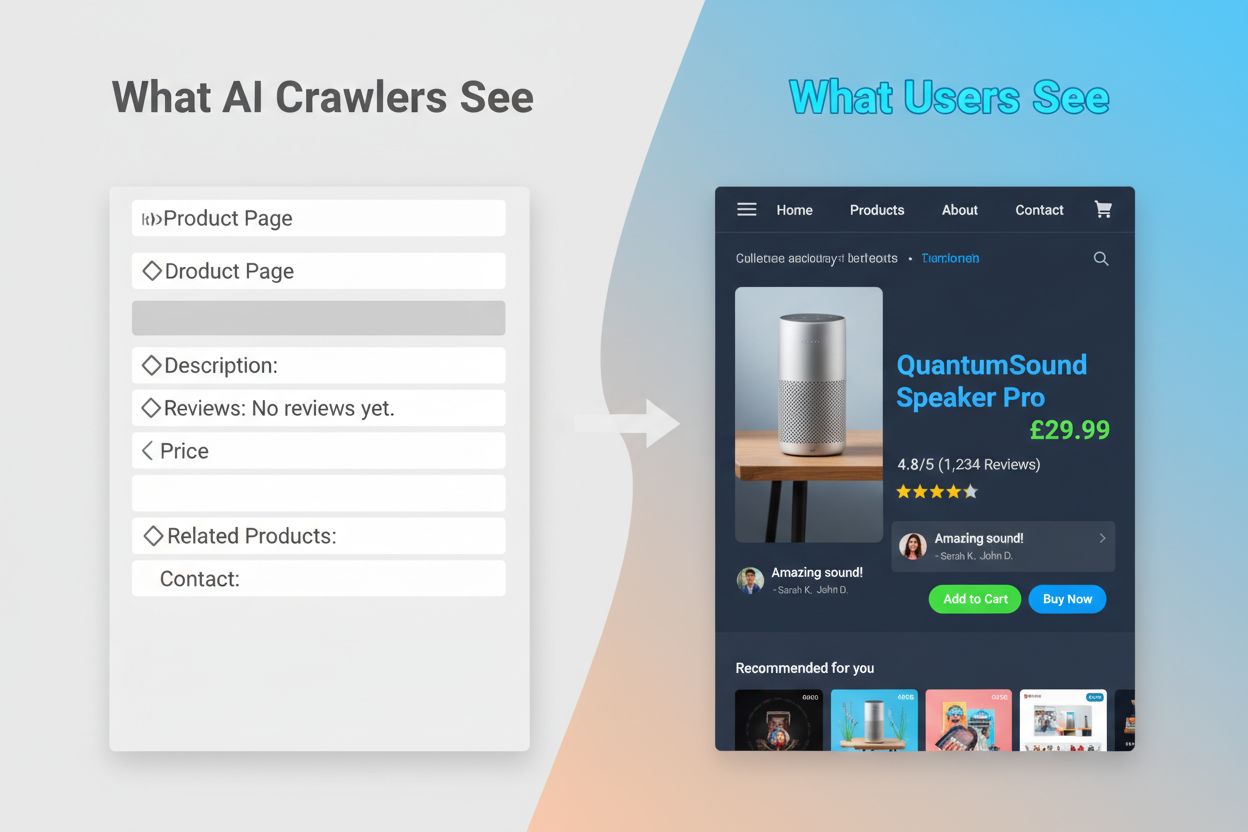
Consecințele practice ale acestor diferențe tehnice sunt profunde și deseori neînțelese de proprietarii de site-uri. Site-ul tău poate obține poziții excelente în Google, dar să fie simultan aproape invizibil pentru ChatGPT, Perplexity și alte sisteme AI. Acest lucru creează o situație paradoxală în care succesul SEO tradițional nu garantează și vizibilitatea în AI. Când utilizatorii întreabă ChatGPT despre industria sau produsul tău, sistemul AI poate cita concurenții tăi în locul tău, pur și simplu pentru că conținutul lor a fost mai accesibil crawlerilor AI. Relația dintre datele de antrenament și citările din căutarea AI adaugă un alt nivel de complexitate: conținutul folosit la antrenarea unui model AI poate primi tratament preferențial în rezultatele de căutare generate de acel model, ceea ce înseamnă că blocarea crawlerilor AI poate reduce vizibilitatea ta în răspunsurile generate de AI. Pentru editori și creatori de conținut, aceasta înseamnă că decizia strategică de a permite sau bloca crawlerii AI are consecințe reale pentru traficul viitor. Un site care blochează GPTBot pentru a proteja conținutul de la antrenare poate, în același timp, să își reducă șansele de a apărea în rezultatele de căutare ChatGPT. Pe de altă parte, permiterea accesului crawlerilor AI la conținut oferă date pentru antrenament, dar nu garantează citări sau trafic, creând o adevărată dilemă strategică fără o soluție perfectă.
A înțelege ce crawleri accesează site-ul tău și cât de frecvent te vizitează este esențial pentru optimizarea strategiei de conținut. Analiza fișierelor de log este metoda principală pentru identificarea activității crawlerilor, permițându-ți să segmentezi și să analizezi log-urile serverului pentru a vedea ce roboți au accesat site-ul, cât de des au vizitat și ce pagini au prioritizat. Prin examinarea șirurilor User-Agent din log-urile serverului, poți distinge între Googlebot, GPTBot, OAI-SearchBot și alți crawleri, dezvăluind tipare ale comportamentului acestora. Principalii indicatori de monitorizat sunt frecvența crawlingului (cât de des vizitează fiecare crawler), adâncimea crawlingului (câte niveluri din structura site-ului sunt parcurse) și bugetul de crawling (numărul total de pagini crawl-uite într-o anumită perioadă). Instrumente precum Google Search Console și Bing Webmaster Tools oferă informații despre activitatea crawlerilor de căutare, în timp ce soluții specializate precum AmICited.com oferă monitorizare detaliată a comportamentului crawlerilor AI pe mai multe platforme, inclusiv ChatGPT, Perplexity și Google AI Overviews. AmICited.com urmărește în mod special modul în care sistemele AI fac referire la brandul și conținutul tău, oferind vizibilitate asupra platformelor AI care te citează și cât de des. Înțelegerea acestor tipare te ajută să identifici din timp probleme tehnice, să optimizezi alocarea bugetului de crawling și să iei decizii informate despre accesul crawlerilor și optimizarea conținutului.
Optimizarea pentru crawlerii tradiționali de căutare necesită concentrarea pe fundamentele SEO tehnic consacrate, care asigură că site-ul tău este descoperibil și indexabil. Următoarele strategii rămân esențiale pentru menținerea unei vizibilități puternice în căutare:
Motoarele de căutare precum Google se concentrează tot mai mult pe eficiența crawlingului, reprezentanții Google indicând că Googlebot va crawlingui mai puțin în viitor. Asta înseamnă că site-ul tău ar trebui să fie cât mai eficient și ușor de înțeles, cu ierarhii clare și legături interne eficiente care să ghideze crawlerii direct către cele mai importante pagini.
Optimizarea pentru crawlerii de antrenament AI presupune o abordare diferită, axată pe calitatea, claritatea și accesibilitatea conținutului, nu pe semnalele de clasare. Deoarece crawlerii AI prioritizează conținutul bine structurat și bogat contextual, strategia ta de optimizare ar trebui să pună accent pe cuprindere și lizibilitate. Evită conținutul dependent de JavaScript pentru informații critice—asigură-te că detaliile produselor, prețurile, recenziile și datele cheie sunt prezente în HTML-ul brut, unde crawlerii AI le pot accesa. Creează conținut cuprinzător și detaliat care acoperă subiectele pe larg și oferă context din care modelele AI pot învăța. Folosește formatare clară cu titluri, liste cu bullet-uri și numerotate pentru a fragmenta textul și a-l face ușor de parcurs. Scrie cu claritate semantică folosind limbaj direct, fără jargon excesiv care ar putea confuza modelele AI. Implementează ierarhii corecte de titluri (H1, H2, H3) pentru a ajuta crawlerii AI să înțeleagă structura și relațiile din conținut. Include metadate relevante și schema markup pentru a oferi context despre conținutul tău. Asigură încărcarea rapidă a paginilor deoarece crawlerii AI au timeout-uri scurte (de obicei 1-5 secunde) și pot sări complet paginile lente.
Diferența cheie față de optimizarea pentru căutare este că crawlerii AI nu iau în calcul semnalele de clasare, backlink-urile sau densitatea cuvintelor cheie. În schimb, apreciază conținutul clar, bine organizat și bogat în informații. O pagină care poate nu are un clasament bun în Google poate fi extrem de valoroasă pentru modelele AI dacă conține informații cuprinzătoare, bine structurate despre un subiect.
Peisajul crawlingului web evoluează rapid, crawlerii AI devenind tot mai importanți pentru vizibilitatea conținutului și notorietatea brandului. Pe măsură ce instrumentele de căutare bazate pe AI precum ChatGPT, Perplexity și Google AI Overviews devin tot mai folosite, abilitatea de a fi descoperit și citat de aceste sisteme va fi la fel de critică precum clasamentele tradiționale în căutare. Distincția dintre crawlerii de antrenament și cei de căutare va deveni probabil mai nuanțată, companiile oferind, posibil, o separare mai clară între colectarea de date și recuperarea pentru căutare, similar abordării OpenAI cu GPTBot și OAI-SearchBot. Proprietarii de site-uri vor trebui să dezvolte strategii care să echilibreze optimizarea SEO tradițională cu vizibilitatea în AI, recunoscând că aceste obiective sunt complementare, nu concurente. Apariția instrumentelor și soluțiilor specializate de monitorizare va face mai ușoară urmărirea activității crawlerilor atât pe platforme tradiționale, cât și pe cele AI, permițând decizii bazate pe date privind accesul crawlerilor și optimizarea conținutului. Cei care optimizează acum atât pentru crawlerii de căutare, cât și pentru cei AI, vor avea un avantaj competitiv, poziționându-și conținutul pentru a fi descoperit prin mai multe canale, pe măsură ce peisajul căutării continuă să evolueze. Viitorul vizibilității conținutului depinde de înțelegerea și optimizarea pentru întregul spectru de crawleri care descoperă și folosesc conținutul tău.
Crawlerii de căutare precum Googlebot indexează conținutul pentru clasamentele din căutare și pot executa JavaScript pentru a vedea conținutul dinamic. Crawlerii de antrenament AI precum GPTBot colectează date pentru a antrena LLM-uri și, de obicei, nu pot executa JavaScript, făcându-i să rateze conținutul încărcat dinamic. Această diferență fundamentală înseamnă că site-ul tău poate avea un clasament bun în Google, dar să fie aproape invizibil pentru ChatGPT.
Da, poți folosi robots.txt pentru a bloca anumiți crawleri AI precum GPTBot, permițând totodată crawlerilor de căutare accesul. Totuși, acest lucru poate reduce vizibilitatea ta în răspunsurile și rezumatele generate de AI. Decizia strategică depinde dacă prioritizezi protecția conținutului sau potențialul trafic de recomandare din AI.
Crawlerii AI precum GPTBot parcurg doar HTML-ul brut la încărcarea inițială a paginii și nu execută JavaScript. Conținutul încărcat dinamic prin scripturi—cum ar fi detalii despre produse, recenzii sau imagini—rămâne complet invizibil pentru ei. Aceasta este o limitare critică pentru site-urile moderne care se bazează pe randarea pe partea clientului.
Crawlerii de antrenament AI vizitează de obicei mai rar decât crawlerii de căutare, cu intervale mai lungi între vizite. Ei prioritizează conținutul cu autoritate ridicată și pot parcurge o pagină doar o dată la câteva săptămâni sau luni. Acest tipar de crawling rar reflectă accentul pus pe calitate, nu pe volum.
Detaliile despre produse, recenziile clienților, imaginile încărcate la cerere, elementele interactive (tab-uri, caruseluri, modale), informațiile despre prețuri și orice conținut ascuns în spatele JavaScript-ului sunt cele mai vulnerabile. Pentru site-urile ecommerce și cele bazate pe SPA, aceasta poate reprezenta o mare parte din conținutul critic.
Asigură-te că informațiile cheie se află în HTML-ul brut, îmbunătățește viteza site-ului, folosește o structură clară și formatare cu ierarhie corectă a titlurilor, implementează schema markup și evită conținutul critic dependent de JavaScript. Scopul este să faci conținutul accesibil pentru ambele tipuri de crawleri.
Instrumentele de analiză a fișierelor de log, Google Search Console, Bing Webmaster Tools și soluțiile specializate de monitorizare a crawlerilor precum AmICited.com te pot ajuta să urmărești comportamentul crawlerilor. AmICited.com monitorizează în mod special modul în care sistemele AI fac referire la brandul tău în ChatGPT, Perplexity și Google AI Overviews.
Potrivit, da. Deși blocarea crawlerilor de antrenament poate proteja conținutul tău, ar putea reduce vizibilitatea în rezultatele de căutare și rezumatele generate de AI. În plus, conținutul deja parsat înainte de blocare rămâne în modelele antrenate. Decizia necesită un echilibru între protecția conținutului și potențiala pierdere a descoperirii prin AI.
Urmărește modul în care sistemele AI fac referire la brandul tău în ChatGPT, Perplexity și Google AI Overviews. Obține informații în timp real despre vizibilitatea AI și optimizează-ți strategia de conținut.
Ghid complet de referință pentru crawlerele și boții AI. Identifică GPTBot, ClaudeBot, Google-Extended și peste 20 de alte crawlere AI cu user agent, rate de cr...

Aflați cum să luați decizii strategice despre blocarea crawlerilor AI. Evaluați tipul de conținut, sursele de trafic, modelele de venituri și poziția competitiv...

Află cum să identifici și să monitorizezi crawlerele AI precum GPTBot, PerplexityBot și ClaudeBot în jurnalele serverului tău. Descoperă șiruri user-agent, meto...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.