Schema Markup pentru AI: Ce tipuri contează cel mai mult pentru vizibilitatea LLM
Află care tipuri de schema markup contează cel mai mult pentru vizibilitatea AI. Descoperă cum interpretează LLM-urile datele structurate și implementează strategii de schema markup care îți aduc brandul citat în răspunsurile AI.
Publicat la Jan 3, 2026.Ultima modificare la Jan 3, 2026 la 3:24 am
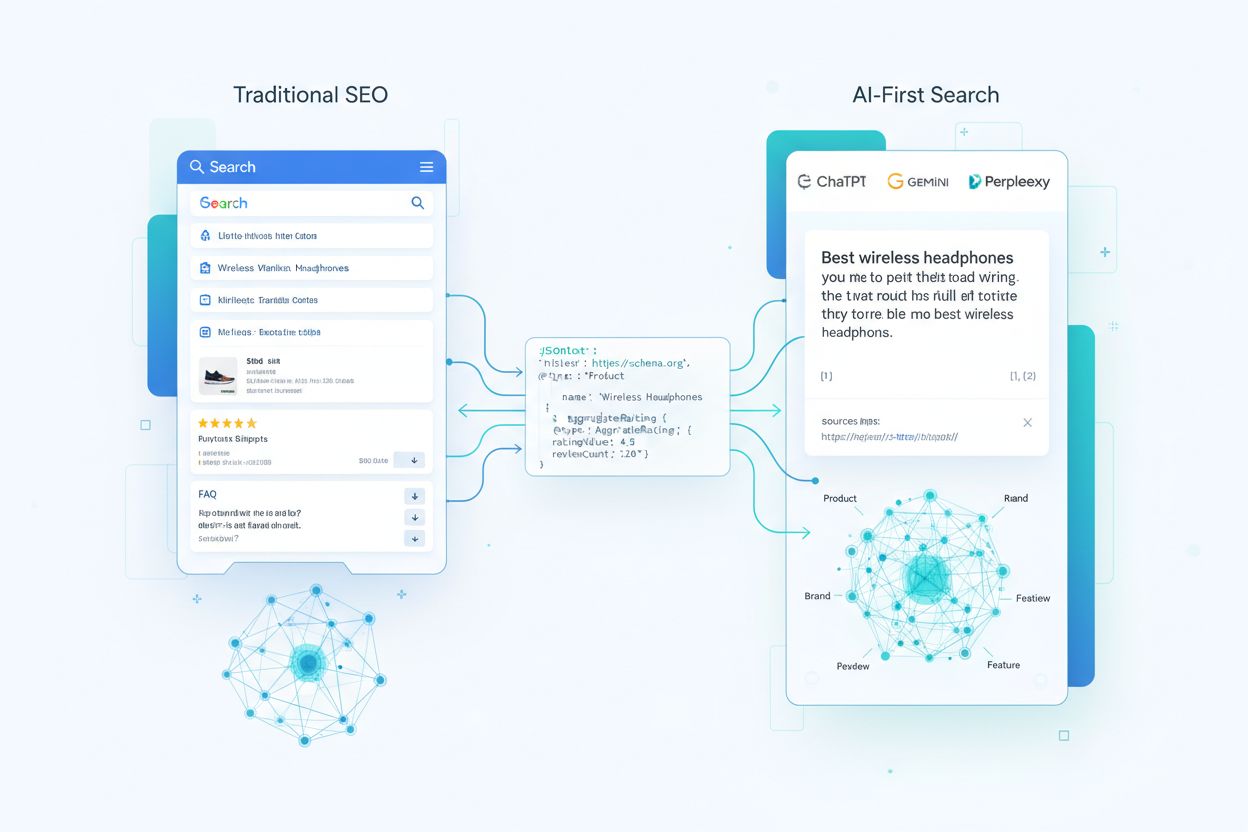
Ani la rând, schema markup a fost folosită în principal pentru a câștiga rich results—acel rating cu stele, carduri de produs și acordioane FAQ care apăreau în rezultatele tradiționale din căutare. Astăzi, această strategie devine depășită. Modelele lingvistice mari și motoarele AI de răspuns interpretează schema markup în moduri fundamental diferite, folosind-o nu pentru îmbunătățiri vizuale, ci pentru a construi knowledge graphs și a înțelege relațiile dintre entități la scară largă. Cu aproximativ 45 de milioane de site-uri (12,4% din toate domeniile înregistrate) care implementează acum o formă de schema.org markup, sistemele AI au acces la cantități fără precedent de date structurate din care să învețe și pe care să se bazeze. Schimbarea este profundă: schema markup influențează acum dacă brandul tău este citat în răspunsurile generate AI, cât de precis modelele prezintă produsele și serviciile tale și dacă conținutul tău devine o sursă de încredere într-un peisaj de căutare AI-first.
Cum interpretează sistemele AI schema markup
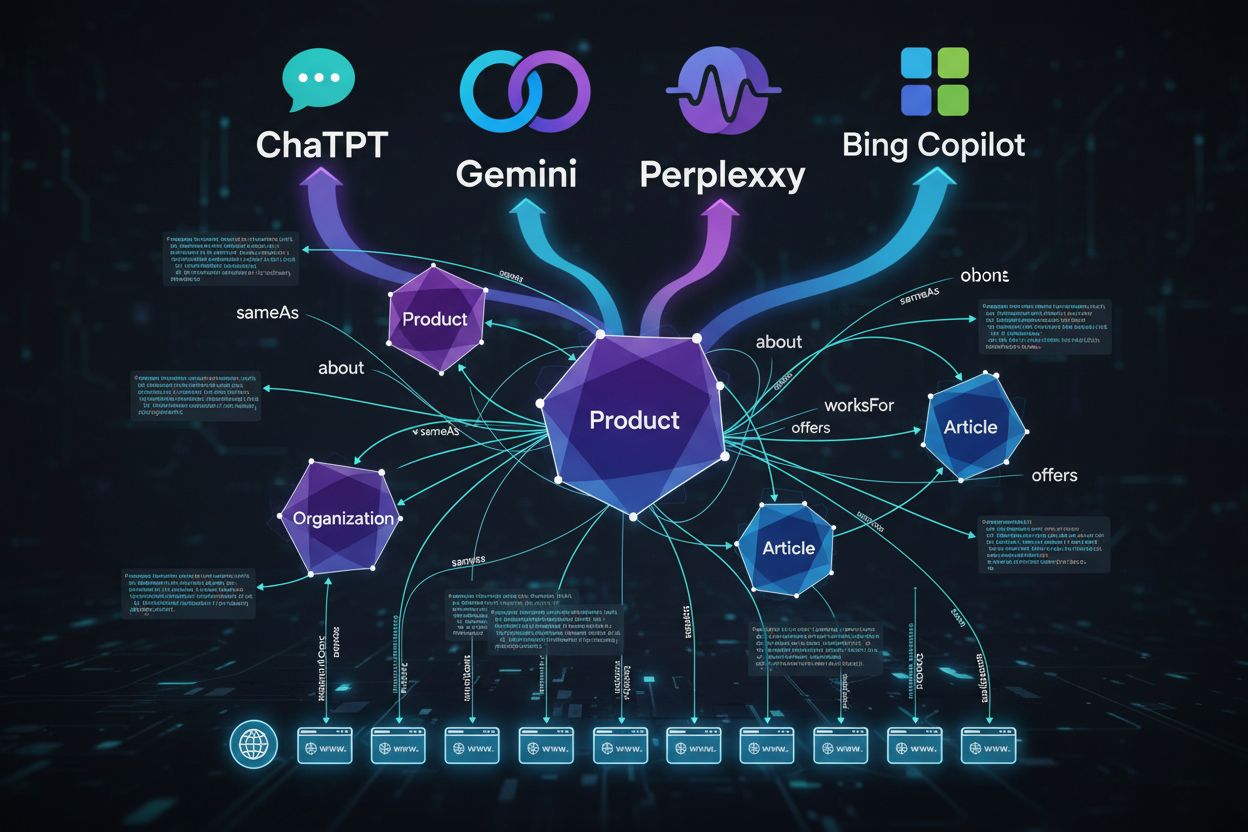
Pentru a înțelege cum consumă sistemele AI schema markup, trebuie să urmărești traseul datelor structurate de la prima scanare până la răspunsurile generate de LLM. Când un crawler ajunge pe pagina ta, extrage blocurile JSON-LD, microdata sau RDFa și le normalizează într-un index, alături de textul și media nestructurate. Aceste date structurate devin parte a unui knowledge graph la scară web, unde entitățile sunt conectate prin relații și primesc embeddings pentru căutare semantică. În sistemele RAG (retrieval-augmented generation), schema poate fi inclusă direct în chunk-urile care populează indici vectoriali—un singur chunk poate conține atât descrierea unui produs, cât și markup-ul său JSON-LD, oferind modelelor atât context narativ cât și atribute structurate de tip key-value. Diferite arhitecturi LLM consumă schema diferit: unele modele se suprapun indexurilor de căutare și knowledge graphs existente, în timp ce altele folosesc pipeline-uri de retragere multi-sursă care extrag din conținut structurat și nestructurat. Cel mai important lucru este că o schema bine implementată acționează ca un contract cu modelul, declarând într-o formă foarte structurată care fapte de pe pagina ta le consideri canonice și de încredere.
Tip arhitectură
Utilizare schemă
Impact citare
Proprietăți cheie
Căutare tradițională + Strat LLM
Îmbunătățește knowledge graph-ul existent
Mare - modelele citează surse bine structurate
Organization, Product, Article
RAG (retrieval-augmented generation)
Inclusă în chunk-uri vectoriale
Mediu-Mare - schema ajută la precizie
Toate tipurile cu proprietăți detaliate
Motoare de răspuns multi-sursă
Folosită pentru rezolvarea entităților
Mediu - concurează cu alte semnale
Person, LocalBusiness, Service
AI conversațional
Susține înțelegerea contextului
Variabil - depinde de datele de antrenament
FAQPage, HowTo, BlogPosting
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Cele mai importante tipuri de schemă pentru vizibilitatea AI
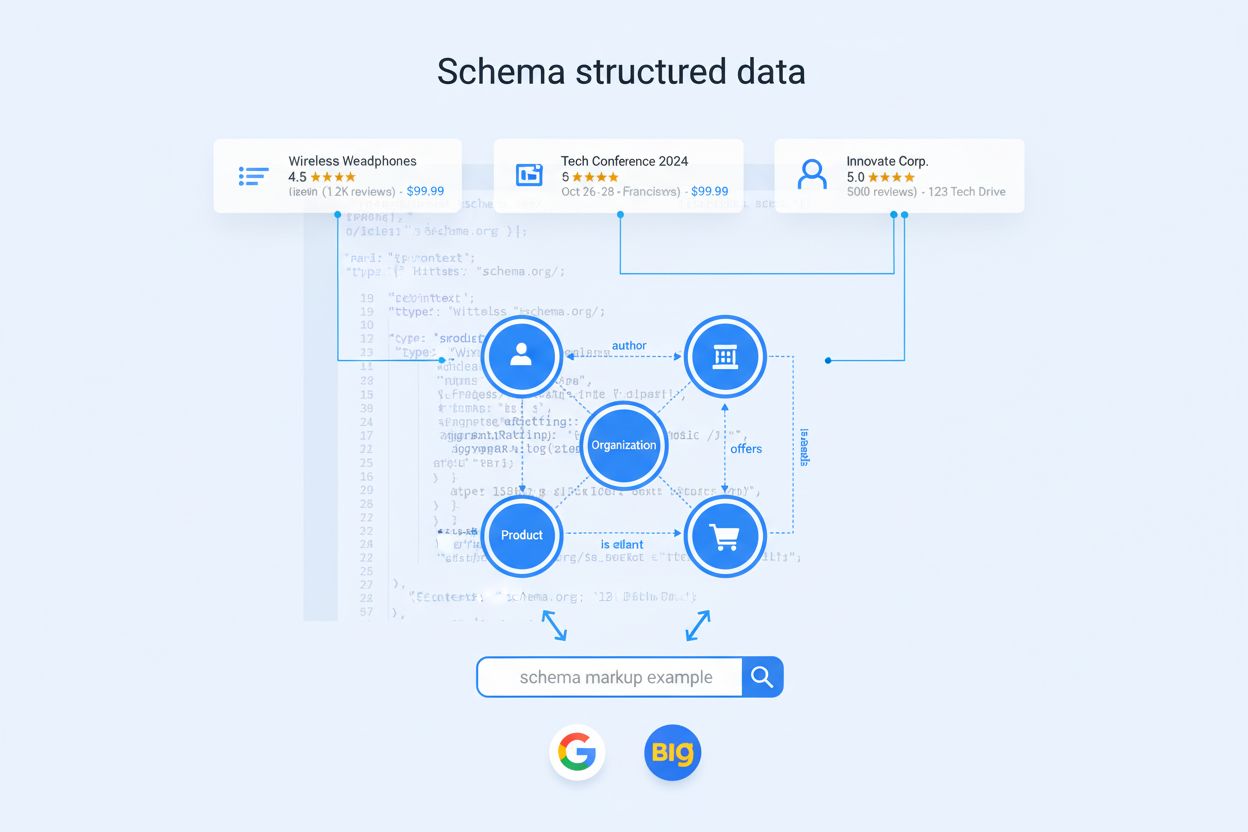
Nu toate tipurile de schemă au aceeași greutate în era AI. Organization este ancora întregului tău grafic de entități, ajutând modelele să înțeleagă identitatea brandului, autoritatea și relațiile. Schema de Product este esențială pentru e-commerce și retail, permițând sistemelor AI să compare caracteristici, prețuri și rating-uri între surse. Article și BlogPosting ajută modelele să identifice conținutul lung, potrivit pentru întrebări explicative și leadership de opinie. Person este vitală pentru stabilirea credibilității autorului și atribuirea expertizei în răspunsurile AI. FAQPage corespunde direct întrebărilor conversaționale pentru care asistenții AI sunt proiectați să răspundă. Pentru companiile SaaS și B2B, tipurile SoftwareApplication și Service sunt la fel de importante, apărând frecvent în comparații de tipul “cele mai bune instrumente pentru X” și evaluări de caracteristici. Pentru afacerile locale și furnizorii de servicii medicale, tipurile LocalBusiness și MedicalOrganization oferă precizie geografică și claritate în reglementare. Diferențierea reală, însă, nu vine din simpla adoptare a tipurilor de bază, ci din proprietățile avansate pe care le suprapui—consistență pe pagini, identificatori de entitate clari și mapare explicită a relațiilor.
Proprietăți avansate de schemă folosite efectiv de LLM-uri
Proprietățile de bază precum name, description și URL sunt acum standard; 72,6% din paginile care apar pe prima pagină Google folosesc deja o formă de schema markup. Proprietățile care fac diferența pentru vizibilitatea AI sunt acele elemente de legătură care ajută modelele să rezolve entități, să înțeleagă relații și să dezambiguizeze sensul. Iată cele mai importante proprietăți avansate:
sameAs: Leagă entitatea ta de profiluri canonice pe Wikipedia, LinkedIn, Crunchbase sau site-uri ale producătorului, reducând dramatic șansa ca modelul să confunde brandul tău cu un omonim
about/mentions: Clarifică ce subiecte și entități sunt cu adevărat în centrul paginii, ajutând modelele să aleagă între multe surse “relevante” pentru întrebări nuanțate
@id: Oferă identificatori stabili, unici, care permit rezolvarea consistentă a entităților pe tot site-ul tău și pe web
additionalType: Oferă indicii de tip mai specifice dincolo de schema principală, ajutând modelele să înțeleagă categorii nuanțate
additionalProperty: Codifică atribute și specificații personalizate care apar adesea în comparații, recenzii și conținut evaluativ
mentions: Identifică explicit entitățile discutate pe pagină, ajutând modelele să înțeleagă contextul și relațiile
Aceste proprietăți transformă schema dintr-un simplu container de date într-o hartă semantică pe care modelele o pot naviga cu încredere. Când folosești sameAs pentru a lega organizația ta de pagina de Wikipedia, nu adaugi doar metadate—transmiți modelului “aceasta este sursa autoritară pentru informații despre noi.” Când folosești additionalProperty pentru a codifica specificații de produs sau caracteristici de servicii, oferi exact atributele pe care sistemele AI le caută pentru a construi comparații sau recomandări.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Strategie de implementare schema: de la bazic la optimizat pentru LLM
Majoritatea organizațiilor tratează schema markup ca pe o sarcină unică de implementare, însă avantajul competitiv în căutarea condusă de AI necesită să o tratezi ca pe o disciplină continuă de guvernanță a datelor. Un cadru util este un model de maturitate în patru niveluri care ajută echipele să înțeleagă unde sunt și unde trebuie să ajungă:
Nivelul 1 – Schema bazică pentru rich result se concentrează pe markup minim pe anumite template-uri, în principal pentru eligibilitatea la stele, carduri de produs sau fragmente FAQ. Guvernanța este lejeră, consistența scăzută, iar scopul este mai degrabă cosmetic decât semantic.
Nivelul 2 – Acoperire centrată pe entități standardizează Organization, Product, Article și Person pe template-uri cheie, introduce utilizarea consistentă a valorilor @id și adaugă linkuri sameAs de bază pentru a preveni confuzia între entități.
Nivelul 3 – Schema integrată cu knowledge graph aliniază ID-urile de schemă cu modele interne de date (CMS, PIM, CRM), folosește pe scară largă proprietățile about/mentions/additionalType și codifică relații cross-page pentru ca modelele să înțeleagă cum se leagă nodurile de conținut între ele și cu entități externe.
Nivelul 4 – Schema optimizată pentru LLM și aliniată RAG structurează deliberat markup-ul pentru întrebări conversaționale și formate de snippet AI, aliniază schema cu pipeline-urile RAG interne și include măsurare și iterare ca practici de bază.
Majoritatea brandurilor se opresc la nivelurile 1–2, ceea ce înseamnă că adoptarea de bază este acum un factor de igienă, nu un diferențiator. Avansul spre nivelurile 3–4 este locul unde optimizarea schema pentru LLM devine un șanț competitiv durabil, deoarece modelele pot interpreta în mod fiabil entitățile tale în multe formulări de interogări și suprafețe.
Pattern-uri de schemă specifice verticalei pentru motoarele AI de răspuns
Industriile diferite au entități, profile de risc și intenții ale utilizatorilor diferite, deci utilizarea avansată a schemelor nu poate fi universală. Principiile de bază—claritatea entității, modelarea relațiilor și alinierea cu conținutul on-page—rămân constante, dar tipurile și proprietățile de schemă pe care le accentuezi ar trebui să reflecte modul real de căutare al oamenilor în sectorul tău.
Pentru e-commerce și retail, entitățile principale sunt Products, Offers, Reviews și Organization. Fiecare pagină de produs cu intenție mare ar trebui să expună markup Product granular, incluzând identificatori (SKU, GTIN), brand, model, dimensiuni, materiale și atribute diferențiatoare prin additionalProperty. Asociază asta cu Offers pentru prețuri și disponibilitate, și structuri AggregateRating care ajută modelele să înțeleagă social proof-ul. Dincolo de bază, gândește-te la modul în care clienții formulează întrebări: “Este impermeabil?”, “Vine cu garanție?”, “Care este politica de retur?” Codificarea acestor răspunsuri ca FAQPage pe același URL și sincronizarea atributelor Product cu conținutul FAQ face mult mai ușoară citarea corectă a paginii de către motoarele de răspuns.
Pentru SaaS și servicii B2B, entitățile sunt mai abstracte, dar se potrivesc bine cu SoftwareApplication, Service și Organization. Pentru fiecare produs sau ofertă principală, definește o entitate SoftwareApplication sau Service cu descrieri clare despre categorie, platforme suportate, integrări și modele de prețuri, folosind additionalProperty pentru a enumera funcționalități care apar frecvent în comparații de tipul “cele mai bune instrumente pentru X”. Leagă-le de Organization prin relații provider sau offers și de echipa de experți prin Person. Pe partea de conținut, Article, BlogPosting, FAQPage și HowTo ajută LLM-urile să identifice cele mai bune resurse pentru întrebări evaluative și educaționale.
Pentru local, sănătate și industrii reglementate, LocalBusiness, MedicalOrganization și tipuri MedicalEntity conexe pot codifica adrese, arii de servicii, specialități, asigurări acceptate și program de funcționare mult mai puțin ambiguu decât textul liber. Acest lucru contează atunci când un asistent AI este întrebat “găsește un cardiolog pediatric aproape de mine care acceptă asigurarea mea” sau “recomandă un centru de urgență deschis acum”. În aceste sectoare, ai grijă să nu exagerezi sau să expui detalii sensibile—marchează doar fapte pe care ești confortabil să le reutilizezi în multe contexte și asigură-te că echipele legale și de conformitate revizuiesc orice atribut medical sau reglementat.
Măsurarea impactului schema asupra vizibilității AI
Comportamentul LLM este inerent stocastic, deci nu vei obține atribuție perfectă doar din schimbările de schema. Ce poți face este să construiești un sistem de monitorizare ușor care să probeze răspunsurile AI regulat pentru un set definit de interogări. Urmărește ce entități sunt menționate, ce URL-uri sunt citate, cum este descris brandul tău și dacă faptele cheie (prețuri, capabilități, detalii de conformitate) sunt corecte pe platforme precum ChatGPT, Gemini, Perplexity și Bing Copilot. Când apar probleme—funcționalități inventate, mențiuni lipsă sau citări care favorizează agregatoare în locul paginilor tale principale—începe prin a verifica semnalele conflictuale sau incomplete. Contrazice textul on-page schema? Lipsesc linkurile sameAs sau duc către profiluri depășite? Reivindică mai multe pagini a fi sursa canonică pentru aceeași entitate? La nivel strategic, planifică o revizuire schema cel puțin trimestrial, în concordanță cu noi oferte, clustere de conținut și schimbări în modul în care motoarele AI de răspuns îți afișează brandul.
Greșeli comune de schemă care afectează vizibilitatea LLM
Mai multe pattern-uri afectează constant eficiența schemei pentru AI. Marcarea conținutului care nu este vizibil pe pagină creează un deficit de încredere—modelele învață să ignore sursele unde schema și conținutul vizibil diferă. Folosirea unor tipuri prea generice fără specificitate (de ex., marcarea totului ca “Thing” sau “CreativeWork”) nu oferă niciun semnal semantic; modelele au nevoie de tipuri precise pentru a înțelege contextul. Copierea aceleiași schema pe mai multe pagini fără a ajusta detaliile entității este probabil cea mai comună greșeală—când fiecare pagină de produs are același markup Organization sau fiecare articol revendică același autor, modelele nu pot dezambiguiza și pot dezavantaja conținutul tău ca fiind cu semnal scăzut. Identificatorii de entitate inconsistenți pe pagini (folosirea unor @id diferite pentru aceeași organizație sau produs) rup rezolvarea entității și forțează modelele să trateze conținutul legat ca entități separate. Lipsa link-urilor sameAs către profiluri autoritare lasă modelele vulnerabile la confuzie cu omonimi. În final, informațiile conflictuale între schema și textul on-page semnalează lipsă de încredere; dacă schema spune că un produs este în stoc, dar pagina zice “out of stock”, modelele nu vor avea încredere în niciuna dintre surse.
Viitorul schemei și căutării AI
Schema markup trece de la o tactică SEO cosmetică la o tehnologie fundamentală pentru căutarea AI-first. Schema markup conectată—unde definești explicit relații între entități folosind proprietăți precum sameAs, about și mentions—construiește knowledge graphs pe care sistemele AI le pot naviga cu încredere. Avantajul competitiv nu mai este la cei care întreabă “Care este schema minimă pentru un rich result?”, ci la cei care întreabă “Ce reprezentare structurată ar face conținutul nostru neambigu pentru o mașină, chiar în afara SERP?”. Această schimbare împinge organizațiile spre pattern-uri de schemă mai complete, interconectate și centrate pe entități. Pe măsură ce căutarea condusă de AI devine principalul canal de descoperire, optimizarea schema pentru LLM evoluează dintr-o curiozitate tehnică într-o disciplină SEO de bază. Organizațiile care avansează prin nivelurile de maturitate—de la schema basic rich result la knowledge-graph-integrated și pattern-uri optimizate LLM—vor construi șanțuri durabile în descoperirea AI, asigurându-se că brandurile lor sunt citate ca autorități și conținutul lor apare ca surse de încredere.
Întrebări frecvente
Cum este diferit schema markup pentru AI față de SEO tradițional?
Schema tradițională se concentra pe rich results (stele, fragmente). Pentru AI, schema este despre claritatea entității, relații și knowledge graphs. Sistemele AI folosesc schema pentru a înțelege la nivel semantic despre ce este conținutul tău, nu doar pentru îmbunătățiri vizuale.
Care tipuri de schemă sunt cele mai importante pentru vizibilitatea LLM?
Organization, Product, Article, Person și FAQPage sunt fundamentale. Pentru SaaS, adaugă SoftwareApplication și Service. Pentru local/sănătate, adaugă LocalBusiness și MedicalOrganization. Importanța variază în funcție de industrie și intenția utilizatorului.
Trebuie să implementez toate tipurile de schemă?
Nu. Începe cu Organization și cele mai valoroase pagini (produse, servicii, articole cheie). Extinde treptat acoperirea în funcție de modelul de afaceri și unde răspunsurile AI ar fi cele mai valoroase.
Cât durează să văd rezultate din optimizarea schema?
Schimbările de schema pot influența citările AI în câteva săptămâni, dar relația este probabilistică. Planifică revizuiri trimestriale și monitorizare continuă pe mai multe platforme AI pentru a urmări impactul.
Care este diferența dintre proprietățile sameAs și about?
sameAs leagă entitatea ta de profiluri canonice (Wikipedia, LinkedIn) pentru a preveni confuzia cu omonimi. about/mentions clarifică pe ce este cu adevărat concentrată pagina ta, ajutând modelele să înțeleagă nuanța și contextul.
Poate schema markup singur să îmbunătățească vizibilitatea AI?
Nu. Schema funcționează cel mai bine când este aliniată cu un conținut on-page de calitate și bine structurat. Modelele au nevoie atât de date structurate, cât și de context narativ pentru a cita cu încredere paginile tale.
Cum măsor dacă schimbările de schema ajută la vizibilitatea AI?
Monitorizează răspunsurile AI pe platforme (ChatGPT, Gemini, Perplexity, Bing) pentru interogările țintă. Urmărește mențiunile entității, citările de URL, acuratețea faptelor și descrierea brandului. Caută tendințe pe săptămâni/luni.
Ar trebui să folosesc JSON-LD, microdata sau RDFa pentru schema markup?
JSON-LD este formatul recomandat pentru majoritatea cazurilor. Este mai ușor de implementat, întreținut și nu interferează cu HTML-ul. Microdata și RDFa sunt mai puțin folosite în implementările moderne.
Monitorizează-ți Brandul în Răspunsurile AI
Urmărește cum sistemele AI citează brandul tău pe ChatGPT, Gemini, Perplexity și Google AI Overviews. Obține informații despre ce tipuri de schemă generează vizibilitate.
Ce tipuri de Schema Markup ajută la căutarea AI? Ghid complet pentru 2025
Descoperă ce tipuri de schema markup îți cresc vizibilitatea în motoarele de căutare AI precum ChatGPT, Perplexity și Gemini. Învață strategii de implementare J...
Schema markup este un cod standardizat care ajută motoarele de căutare să înțeleagă conținutul. Află cum datele structurate îmbunătățesc SEO, permit rezultate î...
Cum să Implementezi Schema Organization pentru AI - Ghid Complet
Află cum să implementezi schema Organization pentru vizibilitate AI. Ghid pas cu pas pentru adăugarea datelor structurate JSON-LD, îmbunătățirea citărilor AI și...
10 min citire
Consimțământ Cookie Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.