
Token
Află ce sunt tokenii în modelele de limbaj. Tokenii sunt unități fundamentale de procesare a textului în sistemele AI, reprezentând cuvinte, subcuvinte sau cara...
12 min citire

Descoperă cum limitele de tokenuri afectează performanța AI și învață strategii practice pentru optimizarea conținutului, inclusiv tehnici RAG, fragmentare și sumarizare.
Tokenurile sunt elementele de bază fundamentale pe care modelele AI le folosesc pentru a procesa și înțelege informația. În loc să lucreze cu cuvinte sau propoziții complete, modelele lingvistice de mari dimensiuni împart textul în unități mai mici numite tokenuri, care pot fi caractere individuale, subcuvinte sau cuvinte complete, în funcție de algoritmul de tokenizare. Fiecărui token i se atribuie un identificator numeric unic pe care modelul îl folosește intern pentru calcule. Acest proces de tokenizare este esențial deoarece permite sistemelor AI să gestioneze eficient intrări de lungimi variabile și să mențină o procesare consistentă pentru diferite tipuri de conținut. Înțelegerea tokenurilor este crucială pentru oricine lucrează cu sisteme AI, deoarece ele influențează direct performanța, costul și calitatea rezultatelor obținute.
Diferite modele AI au limite de tokenuri extrem de variate, care definesc cantitatea maximă de informație pe care o pot procesa într-o singură cerere. Aceste limite au evoluat dramatic în ultimii ani, modelele noi suportând ferestre de context mult mai mari. Limita de tokenuri include atât tokenurile de intrare (promptul tău și datele), cât și tokenurile de ieșire (răspunsul modelului), creând un buget comun care trebuie gestionat atent. Înțelegerea acestor limite este esențială pentru a alege modelul potrivit pentru cazul tău de utilizare și pentru a-ți planifica corespunzător arhitectura aplicației.
| Model | Limită Tokenuri | Caz principal de utilizare | Nivel cost |
|---|---|---|---|
| GPT-3.5 Turbo | 4.096 | Conversații scurte, sarcini rapide | Scăzut |
| GPT-4 | 8.192 | Aplicații standard, complexitate moderată | Mediu |
| GPT-4 Turbo | 128.000 | Documente lungi, analize complexe | Ridicat |
| Claude 3.5 Sonnet | 200.000 | Documente extinse, analize cuprinzătoare | Ridicat |
| Gemini 1.5 Pro | 1.000.000 | Seturi masive de date, cărți întregi, analiză video | Foarte ridicat |
Considerații cheie când evaluezi limitele de tokenuri:
Limitele de tokenuri creează constrângeri semnificative care afectează direct acuratețea, fiabilitatea și eficiența costurilor aplicațiilor AI. Dacă depășești limita de tokenuri a unui model, aplicația eșuează complet — nu există o degradare grațioasă sau procesare parțială. Chiar și atunci când rămâi în limite, abordările naive precum trunchierea simplă pot degrada sever performanța prin eliminarea contextului critic de care modelul are nevoie pentru a genera răspunsuri precise. Acest lucru este deosebit de problematic în domenii precum analiza juridică, cercetarea medicală și ingineria software, unde lipsa chiar și a unui singur detaliu important poate duce la concluzii eronate. Provocarea devine și mai complexă dacă luăm în calcul că diferite tipuri de conținut consumă tokenuri în ritmuri diferite — datele structurate precum codul sau JSON necesită mult mai mulți tokeni decât textul simplu în limba engleză, din cauza simbolurilor și formatării.
Trunchierea este metoda cea mai simplă pentru a face față limitelor de tokenuri — pur și simplu tai conținutul în exces când depășește capacitatea modelului. Deși este ușor de implementat, această abordare implică riscuri mari. Când trunchiezi textul, pierzi inevitabil informații, iar modelul nu are nicio modalitate de a ști ce a fost eliminat. Acest lucru poate duce la analize incomplete, context pierdut și halucinații, unde modelul generează informații plauzibile dar incorecte pentru a umple golurile din înțelegerea sa.
def truncate_text(text: str, max_tokens: int) -> str:
"""Simple truncation approach - not recommended for production"""
tokens = encode(text)
if len(tokens) > max_tokens:
truncated_tokens = tokens[:max_tokens]
return decode(truncated_tokens)
return text
# Exemplu: Trunchiere la 4000 de tokenuri
long_document = load_document("legal_contract.pdf")
truncated = truncate_text(long_document, 4000)
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": truncated}]
)
O strategie de trunchiere mai sofisticată face diferența între conținut esențial și opțional. Poți prioritiza elementele obligatorii precum interogarea actuală a utilizatorului și instrucțiunile de bază, apoi adăuga contextul opțional (cum ar fi istoricul conversației) doar dacă mai există spațiu. Această abordare păstrează informațiile critice, respectând totodată limitele de tokenuri.
În loc să trunchiezi, fragmentarea împarte conținutul în bucăți mai mici, ușor de gestionat, care pot fi procesate independent sau selectiv. Fragmentarea cu dimensiune fixă împarte textul în segmente uniforme, în timp ce fragmentarea semantică folosește embedding-uri pentru a identifica puncte naturale de separare bazate pe sens, nu pe numărul arbitrar de tokenuri. Ferestrele glisante cu suprapunere păstrează contextul între fragmente, asigurându-se că informațiile importante care se întind peste limitele fragmentelor nu sunt pierdute.
Fragmentarea ierarhică creează mai multe niveluri de abstractizare — paragrafe individuale la nivelul cel mai fin, secțiuni la nivelul următor și capitole la cel mai înalt nivel. Această abordare permite strategii de recuperare sofisticate, unde poți identifica rapid secțiunile relevante fără a procesa întregul document. Combinate cu baze de date vectoriale și căutare semantică, fragmentarea devine un instrument puternic pentru gestionarea marilor baze de cunoștințe, menținând totodată relevanța și acuratețea.
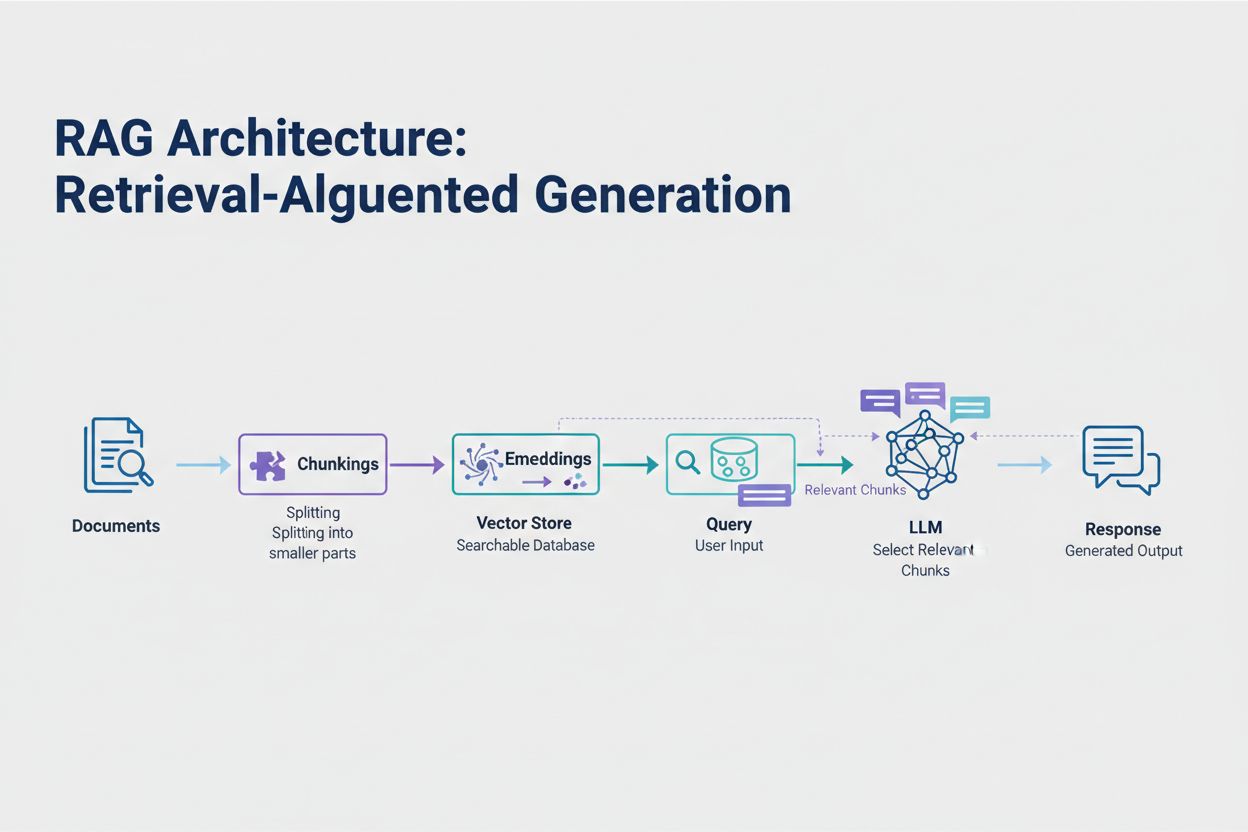
Retrieval-Augmented Generation (RAG) reprezintă cea mai eficientă abordare modernă pentru gestionarea limitelor de tokenuri. În loc să încerci să încadrezi toate datele în fereastra de context a modelului, RAG recuperează doar informațiile cele mai relevante la momentul interogării. Procesul începe prin convertirea documentelor în embedding-uri — reprezentări numerice care captează sensul semantic. Aceste embedding-uri sunt stocate într-o bază de date vectorială, permițând căutări rapide pe bază de similaritate.
Când un utilizator trimite o interogare, sistemul o transformă în embedding și recuperează cele mai relevante fragmente de document din baza vectorială. Doar aceste fragmente relevante sunt injectate în prompt alături de întrebarea utilizatorului, reducând dramatic consumul de tokenuri și îmbunătățind acuratețea. De exemplu, analiza unui contract juridic de 100 de pagini cu RAG ar putea necesita doar 3-5 clauze cheie în prompt, comparativ cu miile de tokenuri necesare pentru includerea documentului complet.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# Pasul 1: Încarcă și fragmentează documentele
documents = load_documents("knowledge_base/")
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.split_documents(documents)
# Pasul 2: Creează embedding-uri și baza vectorială
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(chunks, embeddings)
# Pasul 3: Configurează lanțul RAG
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
llm = ChatOpenAI(model="gpt-4", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
return_source_documents=True
)
# Pasul 4: Interoghează sistemul
result = qa_chain.run("Care sunt clauzele cheie ale acestui contract?")
Sumarizarea condensează conținutul lung păstrând informațiile esențiale, reducând astfel consumul de tokenuri. Sumarizarea extractivă selectează propozițiile cheie din textul original, în timp ce sumarizarea abstractivă generează un text nou, concis, care surprinde ideile principale. Sumarizarea ierarhică creează mai multe niveluri de sumar — mai întâi sumarizează secțiuni individuale, apoi combină aceste rezumate în sinteze superioare. Această abordare funcționează foarte bine pentru documente structurate, cum ar fi articole științifice sau rapoarte tehnice.
Compresia de context abordează problema diferit, eliminând redundanțele și conținutul inutil, menținând totodată formularea originală. Abordările bazate pe grafuri de cunoștințe extrag entități și relații din text, apoi reconstruiesc contextul folosind doar faptele cele mai relevante. Aceste tehnici pot obține o reducere de 40-60% a tokenurilor, păstrând acuratețea semantică, ceea ce le face valoroase pentru optimizarea costurilor în sisteme de producție.
Gestionarea tokenurilor are impact direct asupra costurilor aplicației tale AI. Fiecare token consumat în timpul inferenței implică un cost, iar cheltuielile cresc liniar cu utilizarea tokenurilor. Monitorizarea consumului de tokenuri este esențială pentru a înțelege structura costurilor și pentru a identifica oportunitățile de optimizare. Multe platforme AI oferă acum utilitare de numărare a tokenurilor și panouri de bord în timp real care urmăresc tiparele de utilizare, ajutându-te să identifici ce interogări sau funcții consumă cei mai mulți tokeni.
Monitorizarea eficientă dezvăluie oportunități de optimizare — poate anumite tipuri de interogări depășesc constant limitele de tokenuri sau anumite funcții consumă resurse disproporționat. Urmărind aceste tipare, poți lua decizii informate despre ce strategie de optimizare să implementezi. Unele aplicații beneficiază de rutarea cererilor mari către modele mai capabile (dar mai scumpe), în timp ce altele câștigă mai mult din implementarea RAG sau sumarizare. Cheia este să măsori performanța și costurile reale pentru a-ți valida alegerile de optimizare.
Alegerea strategiei potrivite de gestionare a tokenurilor depinde de cazul tău specific de utilizare, cerințele de performanță și constrângerile de cost. Aplicațiile care necesită acuratețe ridicată cu răspunsuri sursate beneficiază cel mai mult de RAG, care păstrează fidelitatea informației și gestionează consumul de tokenuri. Aplicațiile conversaționale de lungă durată beneficiază de tehnici de memorie tampon care sumarizează istoricul conversației, păstrând deciziile și contextul cheie. Aplicațiile ce implică multe documente, precum analiza juridică sau uneltele de cercetare, beneficiază adesea de sumarizare ierarhică combinată cu fragmentare semantică.
Testarea și validarea sunt critice înainte de a implementa orice strategie de gestionare a tokenurilor în producție. Creează cazuri de test care depășesc limitele de tokenuri ale modelului și evaluează cum afectează diferitele strategii acuratețea, latența și costul. Măsoară metrici precum relevanța răspunsului, acuratețea faptică și eficiența tokenurilor pentru a te asigura că soluția aleasă îndeplinește cerințele. Capcanele comune includ sumarizarea prea agresivă care pierde detalii critice, sisteme de recuperare care ratează informații relevante și strategii de fragmentare care rup conținutul în locuri semantic neadecvate.
Limitele de tokenuri continuă să crească pe măsură ce modelele devin mai sofisticate și mai eficiente. Tehnici emergente precum mecanismele de atenție rară și transformerele eficiente promit să reducă costul computațional al procesării ferestrelor mari de context. Modelele multimodale care pot gestiona simultan text, imagini, audio și video introduc noi provocări și oportunități de tokenizare. Tokenurile de raționament — tokenuri speciale folosite de modele pentru a „gândi” probleme complexe — reprezintă o nouă categorie de consum, care permite soluționarea sofisticată a problemelor, dar necesită gestionare atentă.
Traiectoria este clară: pe măsură ce ferestrele de context se extind și procesarea tokenurilor devine mai eficientă, blocajul se mută de la capacitatea brută la selecția inteligentă a conținutului. Viitorul aparține sistemelor care pot identifica și recupera eficient cele mai relevante informații din baze masive de cunoștințe, nu celor care doar procesează volume mai mari de date. Acest lucru face ca tehnici precum RAG și căutarea semantică să devină tot mai importante pentru dezvoltarea aplicațiilor AI scalabile și eficiente din punct de vedere al costurilor.
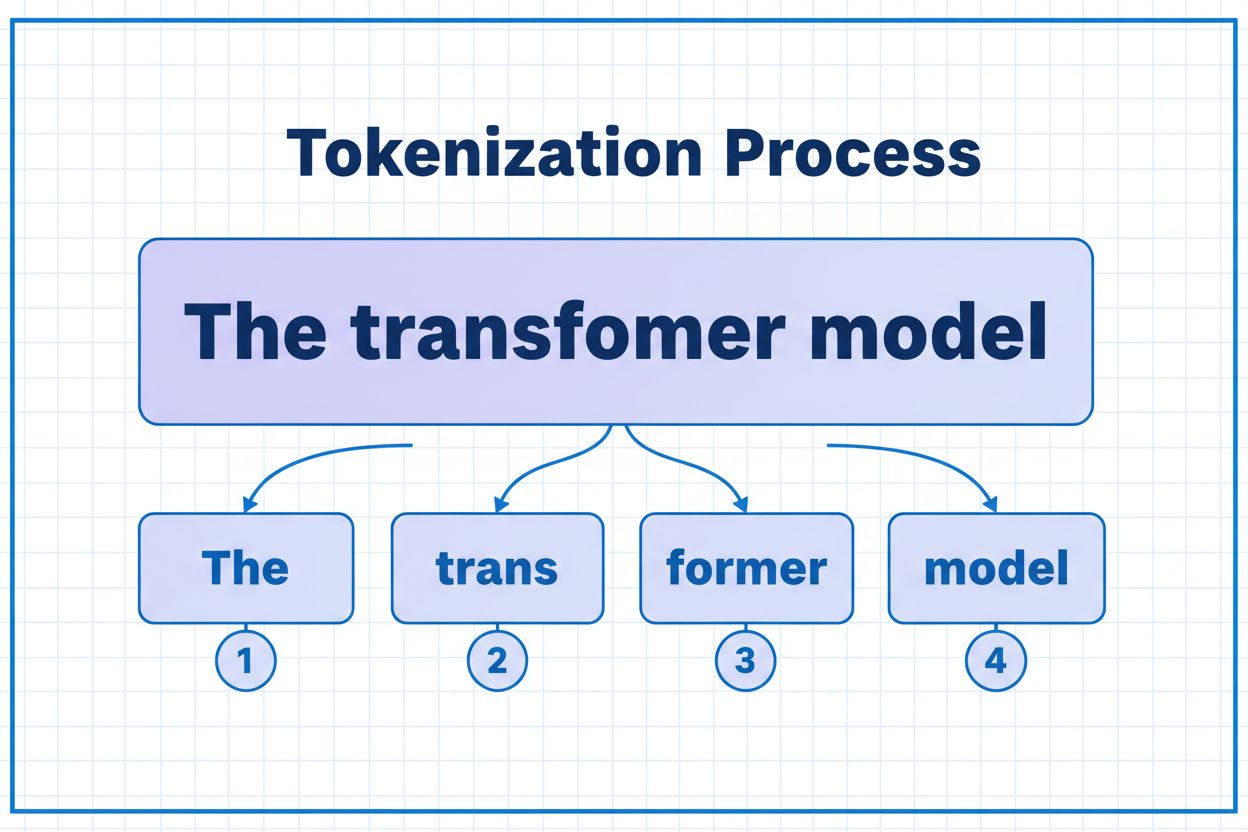
Un token este cea mai mică unitate de date pe care un model AI o procesează. Tokenurile pot fi caractere individuale, subcuvinte sau cuvinte complete, în funcție de algoritmul de tokenizare. De exemplu, cuvântul „transformer” poate fi împărțit în „trans” și „former” ca două tokenuri separate. Fiecărui token i se atribuie un identificator numeric unic pe care modelul îl folosește intern pentru calcul.
Limitele de tokenuri definesc cantitatea maximă de informație pe care modelul AI o poate procesa într-o singură cerere. Dacă depășești această limită, aplicația ta eșuează complet. Chiar și atunci când rămâi în limite, abordările naive precum trunchierea pot degrada acuratețea prin eliminarea contextului critic. Limitele de tokenuri influențează direct și costurile, deoarece de obicei plătești pentru fiecare token consumat.
Tokenurile de intrare sunt cele din promptul și datele pe care le trimiți modelului, în timp ce tokenurile de ieșire sunt cele generate de model în răspuns. Acestea împart un buget comun definit de fereastra de context a modelului. Dacă intrarea ta folosește 90% dintr-o fereastră de 128K tokenuri, îți rămâne doar 10% pentru ieșirea modelului.
Trunchierea este ușor de implementat, dar riscantă. Elimină informații fără ca modelul să știe ce s-a pierdut, ducând la analize incomplete și potențiale halucinații. Deși utilă ca soluție de ultimă instanță, abordări mai bune precum RAG, fragmentarea sau sumarizarea păstrează fidelitatea informațiilor și gestionează consumul de tokenuri mai eficient.
Retrieval-Augmented Generation (RAG) recuperează doar cele mai relevante informații la momentul interogării, în loc să includă documente întregi. Documentele tale sunt convertite în embedding-uri și stocate într-o bază de date vectorială. Când un utilizator întreabă ceva, sistemul recuperează doar fragmentele relevante și le injectează în prompt, reducând dramatic consumul de tokenuri și îmbunătățind acuratețea.
Majoritatea platformelor AI oferă utilitare de numărare a tokenurilor și panouri de bord în timp real pentru a urmări tiparele de utilizare. Monitorizează ce interogări sau funcții consumă cei mai mulți tokeni, apoi implementează strategii de optimizare precum RAG pentru aplicații cu multe documente, sumarizare pentru conversații lungi sau rutare către modele mai mari pentru sarcini complexe. Măsoară performanța și costurile reale pentru a-ți valida alegerile.
Serviciile AI percep de obicei costuri pentru fiecare token consumat. Costurile cresc liniar cu utilizarea tokenurilor, astfel că optimizarea acestora influențează direct cheltuielile tale. O reducere de 20% a consumului de tokenuri înseamnă o reducere de 20% a costurilor. Înțelegerea eficienței tokenurilor te ajută să alegi strategia de optimizare potrivită pentru constrângerile tale bugetare.
Limitele de tokenuri continuă să se extindă pe măsură ce modelele devin mai sofisticate. Tehnici emergente precum mecanismele de atenție rară promit să reducă costurile computaționale ale procesării contextelor mari. Viitorul se concentrează pe selecția și recuperarea inteligentă a conținutului, nu pe capacitatea brută de procesare, făcând ca tehnici precum RAG să devină tot mai importante pentru aplicațiile AI scalabile.
Înțelege eficiența tokenurilor și urmărește cum modelele AI citează brandul tău cu platforma completă de monitorizare a citărilor AI de la AmICited.
Află ce sunt tokenii în modelele de limbaj. Tokenii sunt unități fundamentale de procesare a textului în sistemele AI, reprezentând cuvinte, subcuvinte sau cara...

Află cum modelele AI procesează textul prin tokenizare, embedding-uri, blocuri transformer și rețele neuronale. Înțelege fluxul complet de la introducere la ieș...
Află strategii esențiale pentru a optimiza conținutul de suport pentru sisteme AI precum ChatGPT, Perplexity și Google AI Overviews. Descoperă cele mai bune pra...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.