
Meta Tag-uri NoAI: Controlul Accesului AI prin Headere
Află cum să implementezi meta tag-urile noai și noimageai pentru a controla accesul crawlerelor AI la conținutul site-ului tău. Ghid complet pentru headerele de...
7 min citire
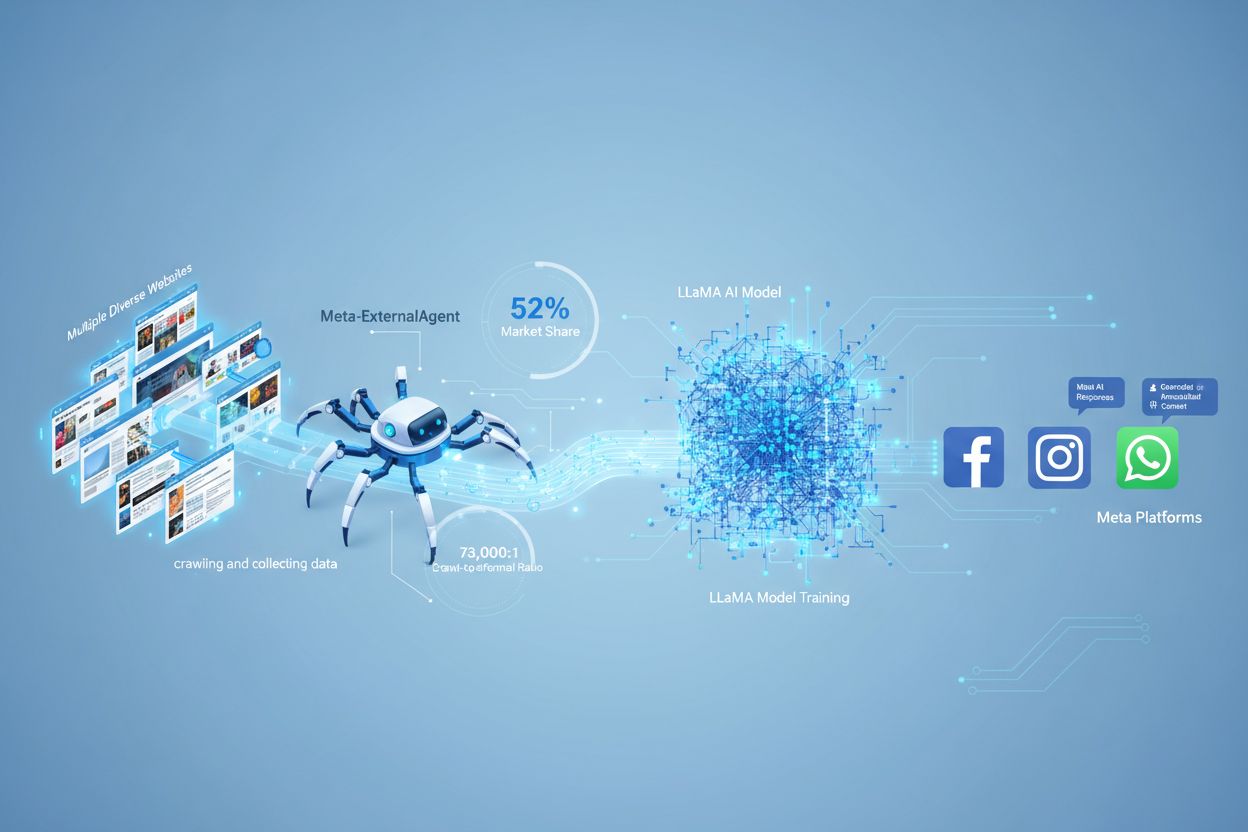
Meta-ExternalAgent este botul de tip crawler web al companiei Meta, lansat în iulie 2024 pentru a colecta conținut public disponibil în scopul antrenării modelelor de inteligență artificială precum LLaMA. Se identifică prin șirul User-Agent meta-externalagent/1.1 și controlează dacă un anumit conținut apare în răspunsurile Meta AI pe Facebook, Instagram și WhatsApp. Editorii pot bloca acest crawler prin robots.txt sau prin configurații la nivel de server, însă respectarea acestor reguli este voluntară și nu are caracter obligatoriu din punct de vedere legal.
Meta-ExternalAgent este botul de tip crawler web al companiei Meta, lansat în iulie 2024 pentru a colecta conținut public disponibil în scopul antrenării modelelor de inteligență artificială precum LLaMA. Se identifică prin șirul User-Agent meta-externalagent/1.1 și controlează dacă un anumit conținut apare în răspunsurile Meta AI pe Facebook, Instagram și WhatsApp. Editorii pot bloca acest crawler prin robots.txt sau prin configurații la nivel de server, însă respectarea acestor reguli este voluntară și nu are caracter obligatoriu din punct de vedere legal.
Meta-ExternalAgent este un crawler web operat de Meta Platforms, lansat în iulie 2024 pentru a colecta date destinate antrenării modelelor de inteligență artificială. Identificat prin șirul User-Agent meta-externalagent/1.1, acest crawler este diferit de crawlerul mai vechi al Meta, facebookexternalhit, care era folosit în principal pentru previzualizări de link-uri și funcții de partajare pe rețelele sociale. Meta-ExternalAgent marchează o schimbare semnificativă în modul în care Meta colectează date pentru inițiativele sale AI, inclusiv modelele de limbaj LLaMA și chatbotul Meta AI integrat pe Facebook, Instagram și WhatsApp. Spre deosebire de crawlerele anterioare Meta, acest agent operează cu transparență minimă și a fost lansat fără un anunț public formal.

Meta-ExternalAgent funcționează ca un bot automatizat care accesează sistematic site-uri web de pe internet pentru a extrage text și conținut în scopul antrenării modelelor AI. Crawlerul trimite cereri HTTP către serverele web, se identifică prin antetul User-Agent unic și descarcă conținutul paginilor pentru procesare. După colectarea conținutului, sistemele Meta analizează și tokenizează textul, transformându-l în date de antrenament care ajută la îmbunătățirea capacităților modelelor de limbaj de mari dimensiuni. Crawlerul respectă fișierul robots.txt pe bază voluntară, acesta fiind un sistem de onoare și nu o obligație legală. Conform datelor Cloudflare, Meta-ExternalAgent reprezintă aproximativ 52% din tot traficul crawlerelor AI de pe internet, ceea ce îl face una dintre cele mai agresive operațiuni de colectare de date din industria AI. Crawlerul funcționează continuu, unii editori raportând frecvențe de acces care sugerează că Meta prioritizează acoperirea completă a conținutului web, nu o colectare selectivă.
| Nume Crawler | User-Agent | Scop Principal | Data lansării | Utilizare date |
|---|---|---|---|---|
| Meta-ExternalAgent | meta-externalagent/1.1 | Antrenare modele AI (LLaMA, Meta AI) | iulie 2024 | Date de antrenament pentru AI generativ |
| facebookexternalhit | facebookexternalhit/1.1 | Previzualizări link și partajare socială | ~2010 | Metadate Open Graph, miniaturi |
| Facebot | facebot/1.0 | Verificare conținut aplicații Facebook | ~2015 | Validare conținut pentru aplicații mobile |
| Applebot | Applebot/0.1 | Siri Apple și indexare căutare | ~2015 | Indexare căutare și asistent vocal |
| Googlebot | Googlebot/2.1 | Indexare Google Search | ~1998 | Construirea indexului motorului de căutare |
Meta-ExternalAgent reprezintă un motiv de îngrijorare major pentru creatorii de conținut și editori, deoarece operează la o scară fără precedent, oferind în același timp vizibilitate minimă asupra modului în care este folosit conținutul. Conform cercetărilor Cloudflare, Meta-ExternalAgent reprezintă 52% din tot traficul crawlerelor AI, depășind cu mult concurenții precum GPTBot de la OpenAI și crawlerele AI de la Google. Această dominație înseamnă că Meta colectează mai multe date de antrenament decât orice altă companie AI, iar editorii nu primesc nici compensație, nici atribuire atunci când conținutul lor este folosit pentru antrenarea modelelor AI ale Meta. Raportul de 73.000:1 crawl-to-referral demonstrează că Meta extrage cantități uriașe de conținut, dar nu trimite aproape deloc trafic către site-urile sursă—un dezechilibru fundamental în schimbul de valoare. În ciuda acestor probleme, doar 2% dintre site-uri blochează activ Meta-ExternalAgent, față de 25% care blochează GPTBot, ceea ce sugerează că mulți editori nu sunt conștienți de prezența crawlerului sau de implicațiile acestuia. Cu Meta investind 40 de miliarde de dolari în infrastructura AI, angajamentul companiei pentru colectarea agresivă de date este probabil să crească, ceea ce face esențial ca editorii să înțeleagă și să gestioneze activ relația cu acest crawler.
Editorii pot controla accesul Meta-ExternalAgent prin fișierul robots.txt, deși este important de înțeles că acest mecanism este voluntar și nu are forță juridică. Pentru a bloca Meta-ExternalAgent, adaugă următoarea directivă în fișierul robots.txt:
User-agent: meta-externalagent
Disallow: /
Alternativ, dacă dorești să permiți crawlerului accesul, dar să îl restricționezi la anumite directoare, poți folosi:
User-agent: meta-externalagent
Disallow: /private/
Disallow: /admin/
Allow: /public/
Totuși, unii editori au raportat că Meta-ExternalAgent continuă să acceseze site-urile chiar și după implementarea restricțiilor în robots.txt, ceea ce sugerează că Meta nu respectă întotdeauna aceste directive. Pentru o protecție mai cuprinzătoare, editorii pot implementa blocare la nivel de antet HTTP sau pot folosi reguli Content Delivery Network (CDN) pentru a identifica și respinge cererile provenite de la Meta-ExternalAgent pe baza șirului User-Agent. De asemenea, editorii pot monitoriza jurnalele serverului pentru User-Agent-ul meta-externalagent/1.1 pentru a verifica dacă crawlerul accesează conținutul. Instrumente precum AmICited.com îi pot ajuta pe editori să urmărească dacă și cum conținutul lor este citat sau referențiat în răspunsurile Meta AI, oferind vizibilitate asupra modului în care lucrările lor sunt folosite de sistemele AI ale Meta.

Când utilizatorii interacționează cu chatboturile Meta AI pe Facebook, Instagram sau WhatsApp, răspunsurile generate se bazează parțial pe conținut colectat de Meta-ExternalAgent. Totuși, răspunsurile Meta AI nu includ de obicei citări vizibile sau atribuirea sursei, ceea ce înseamnă că utilizatorii nu știu care editori au contribuit la răspunsul primit. Această lipsă de transparență creează o provocare semnificativă pentru creatorii de conținut care doresc să înțeleagă valoarea pe care o oferă sistemelor AI ale Meta. Spre deosebire de unii concurenți care includ citări în răspunsurile AI, abordarea Meta prioritizează experiența utilizatorului în detrimentul atribuirii pentru editori. Absența citărilor vizibile înseamnă și că editorii nu pot urmări cu ușurință cât de des conținutul lor influențează răspunsurile Meta AI, ceea ce face dificilă evaluarea impactului de business al folosirii conținutului pentru antrenarea AI. Acest deficit de vizibilitate este unul dintre principalele motive pentru care soluțiile de monitorizare devin din ce în ce mai importante pentru editorii care doresc să își înțeleagă rolul în ecosistemul AI.
Editorii pot verifica activitatea Meta-ExternalAgent prin analiza jurnalelor serverului, care evidențiază adresele IP ale crawlerului, tiparele de acces și frecvența cu care este accesat conținutul. Prin examinarea jurnalelor de acces, editorii pot identifica cererile cu User-Agent-ul meta-externalagent/1.1 și pot determina ce pagini sunt accesate cel mai des. Instrumentele avansate de monitorizare pot urmări tiparele de crawl în timp, relevând dacă Meta prioritizează anumite tipuri de conținut sau secțiuni ale site-ului. Editorii ar trebui să monitorizeze și consumul de lățime de bandă, deoarece crawlingul agresiv realizat de Meta-ExternalAgent poate consuma resurse server considerabile, mai ales pentru site-urile cu biblioteci mari de conținut. În plus, editorii pot folosi instrumente precum AmICited.com pentru a verifica dacă conținutul lor apare în răspunsurile Meta AI și pentru a urmări tiparele de citare pe platformele Meta. Configurarea alertelor pentru activitate de crawl neobișnuită îi poate ajuta pe editori să detecteze schimbări în comportamentul de colectare de date al Meta și să răspundă proactiv. Auditările regulate ale jurnalelor serverului ar trebui să facă parte din orice strategie de management al crawlerelor AI, pentru a asigura conștientizarea modului în care conținutul este accesat și utilizat.
Statutul legal al Meta-ExternalAgent rămâne contestat, existând procese în desfășurare din partea creatorilor de conținut, artiștilor și editorilor care contestă dreptul Meta de a le folosi lucrările pentru antrenarea AI fără consimțământ explicit sau compensație. În timp ce Meta susține că crawlingul web se încadrează în doctrina fair use, criticii consideră că amploarea și natura comercială a colectării de date, combinate cu lipsa atribuirii, constituie încălcarea drepturilor de autor. Fișierul robots.txt, deși respectat ca standard în industrie, nu are forță juridică, ceea ce înseamnă că Meta nu este obligată legal să respecte directivele de blocare. Mai multe jurisdicții dezvoltă reglementări privind colectarea datelor pentru antrenarea AI, iar Legea AI a Uniunii Europene și propunerile legislative din alte regiuni ar putea impune cerințe mai stricte pentru companii precum Meta. Din perspectivă etică, întrebarea fundamentală este dacă creatorii de conținut ar trebui să aibă dreptul de a controla modul în care lucrările lor sunt folosite în scopuri comerciale de antrenare AI și dacă sistemul actual îi compensează adecvat pentru valoarea oferită. Editorii ar trebui să rămână la curent cu evoluțiile legislative și să consulte juriști cu privire la drepturile și obligațiile față de accesul crawlerelor AI. Echilibrul dintre inovația AI și protejarea drepturilor creatorilor rămâne nerezolvat, fiind un domeniu cu evoluții legale și de reglementare constante.
Peisajul managementului crawlerelor AI evoluează rapid, pe măsură ce editorii, reglementatorii și companiile AI negociază condițiile de colectare și utilizare a datelor. Implementarea agresivă a Meta-ExternalAgent arată că marile companii tech consideră conținutul web esențial pentru antrenarea sistemelor AI competitive, iar această tendință va accelera pe măsură ce capacitățile AI devin centrale pentru strategiile de business. Dezvoltările viitoare ar putea include protecții legale mai puternice pentru creatori, cadre obligatorii de licențiere pentru datele de antrenament AI și standarde tehnice care să faciliteze controlul și monetizarea folosirii conținutului în sisteme AI de către editori. Apariția unor instrumente precum AmICited.com reflectă cererea tot mai mare pentru transparență și responsabilitate privind utilizarea conținutului publicat de sistemele AI, ceea ce sugerează că monitorizarea și verificarea vor deveni practici standard pentru creatorii de conținut. Pe măsură ce industria AI se maturizează, ne putem aștepta la negocieri mai sofisticate între creatori și companiile AI, posibil conducând la noi modele de business care să compenseze corect editorii pentru contribuțiile aduse la antrenarea AI.
Meta-ExternalAgent este crawlerul dedicat pentru antrenarea AI lansat de Meta în iulie 2024, identificat prin User-Agent-ul meta-externalagent/1.1. Se diferențiază de facebookexternalhit, care generează previzualizări de link pentru partajarea pe rețelele sociale. Meta-ExternalAgent colectează specific conținut pentru antrenarea modelelor LLaMA și Meta AI, în timp ce facebookexternalhit este folosit pentru funcții sociale încă din jurul anului 2010.
Poți bloca Meta-ExternalAgent adăugând directive în fișierul robots.txt. Adaugă 'User-agent: meta-externalagent' urmat de 'Disallow: /' pentru a-l bloca complet. Pentru o protecție mai amplă, implementează blocare la nivel de server folosind .htaccess (Apache) sau reguli de configurare Nginx. Totuși, robots.txt este voluntar și nu are valoare legală, astfel încât unii editori au raportat că botul continuă să acceseze site-ul în ciuda blocării.
Nu, blocarea Meta-ExternalAgent nu va afecta previzualizările de link pe Facebook. Crawlerul facebookexternalhit se ocupă de previzualizări și funcțiile de partajare socială. Poți bloca meta-externalagent și totodată permite facebookexternalhit să continue să genereze previzualizări atractive atunci când conținutul tău este distribuit pe platformele Meta.
Meta-ExternalAgent are un raport crawl-to-referral de aproximativ 73.000:1, ceea ce înseamnă că Meta extrage conținut la scară uriașă, dar trimite practic zero trafic înapoi către site-urile sursă. Aceasta reprezintă un dezechilibru fundamental față de motoarele de căutare tradiționale, care accesează conținut în schimbul generării de trafic de recomandare.
robots.txt este un sistem bazat pe încredere și nu are caracter legal. Deși multe crawlere respectă directivele robots.txt, unii editori au raportat că Meta-ExternalAgent continuă să acceseze site-urile lor în ciuda restricțiilor explicite din robots.txt. Pentru protecție garantată, implementează blocarea la nivel de server folosind antete HTTP, reguli CDN sau configurări de firewall.
Verifică jurnalele de acces ale serverului pentru cereri cu User-Agent-ul 'meta-externalagent/1.1'. Poți folosi și instrumente de monitorizare precum AmICited.com pentru a urmări dacă conținutul tău apare în răspunsurile Meta AI. Instrumente precum Dark Visitors și Cloudflare Analytics oferă informații suplimentare despre activitatea crawlerelor AI pe site-ul tău.
Conform datelor Cloudflare, Meta-ExternalAgent reprezintă aproximativ 52% din tot traficul crawlerelor AI de pe internet, făcând din acesta cea mai agresivă operațiune de colectare de date pentru AI. Acest procent depășește cu mult concurenții precum GPTBot de la OpenAI și crawlerele AI de la Google, indicând poziția dominantă a Meta în colectarea conținutului web pentru antrenarea AI.
Decizia depinde de prioritățile afacerii tale. Dacă traficul din Meta AI este valoros pentru audiența ta, îl poți permite. Totuși, ține cont că Meta nu oferă compensații sau atribuire pentru conținutul folosit la antrenarea AI. Mulți editori implementează strategii de blocare selectivă, care opresc antrenarea AI, dar păstrează funcționalitatea de previzualizare a linkurilor pentru partajarea socială.
Urmărește modul în care conținutul tău apare în răspunsurile Meta AI pe Facebook, Instagram și WhatsApp. Obține vizibilitate asupra citărilor AI și înțelege prezența brandului tău în răspunsurile generate de inteligența artificială.
Află cum să implementezi meta tag-urile noai și noimageai pentru a controla accesul crawlerelor AI la conținutul site-ului tău. Ghid complet pentru headerele de...

Înțelegeți cum funcționează crawlerii AI precum GPTBot și ClaudeBot, diferențele lor față de crawlerii de căutare tradiționali și cum să vă optimizați site-ul p...

Descoperă cum optimizarea Meta AI transformă publicitatea pe Facebook și Instagram prin automatizare bazată pe AI, licitații în timp real și targetare inteligen...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.