
Ce este MUM și cum afectează căutarea AI?
Află despre Multitask Unified Model (MUM) al Google și impactul său asupra rezultatelor de căutare AI. Înțelege cum procesează MUM interogări complexe prin mai ...
9 min citire
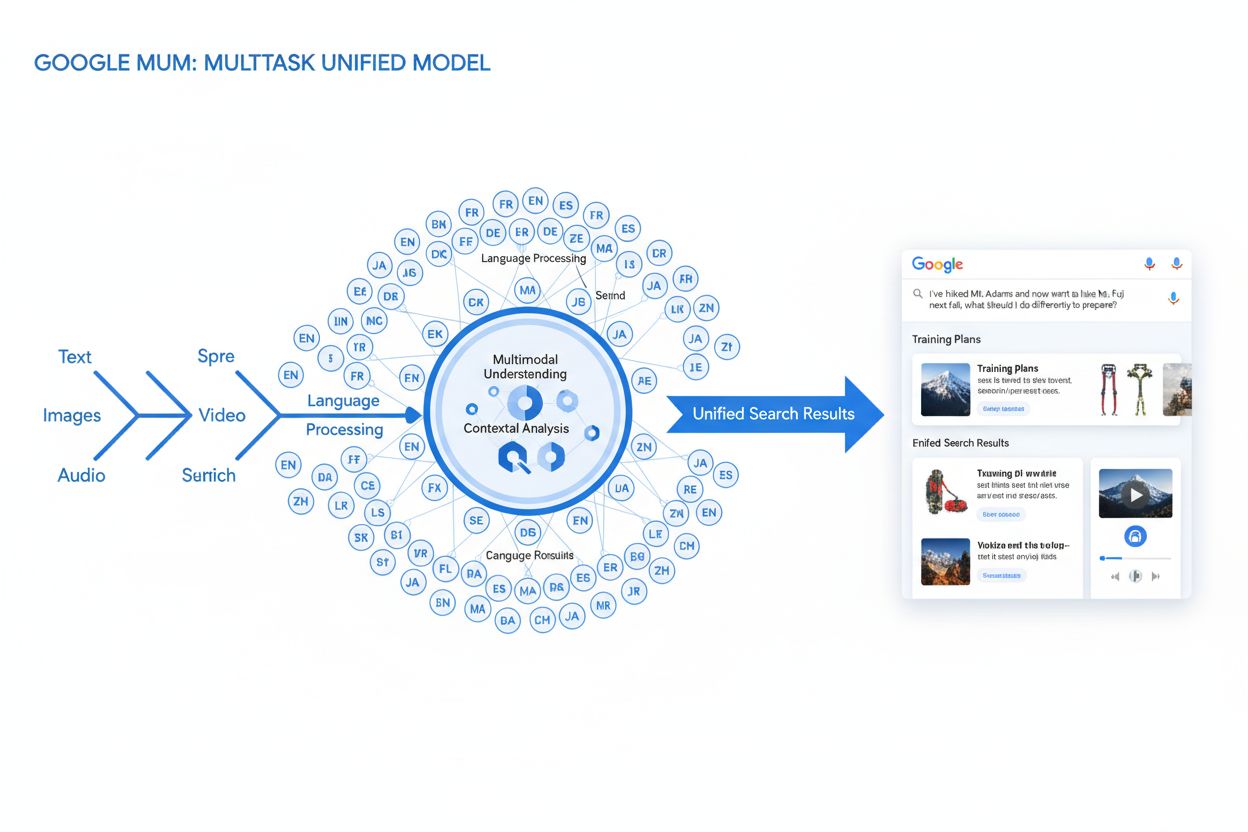
MUM (Multitask Unified Model) este modelul AI multimodal avansat al Google, care procesează simultan text, imagini, video și audio în peste 75 de limbi pentru a oferi rezultate de căutare mai cuprinzătoare și contextuale. Lansat în 2021, MUM este de 1.000 de ori mai puternic decât BERT și reprezintă o schimbare fundamentală în modul în care motoarele de căutare înțeleg și răspund la interogările complexe ale utilizatorilor.
MUM (Multitask Unified Model) este modelul AI multimodal avansat al Google, care procesează simultan text, imagini, video și audio în peste 75 de limbi pentru a oferi rezultate de căutare mai cuprinzătoare și contextuale. Lansat în 2021, MUM este de 1.000 de ori mai puternic decât BERT și reprezintă o schimbare fundamentală în modul în care motoarele de căutare înțeleg și răspund la interogările complexe ale utilizatorilor.
MUM (Multitask Unified Model) este modelul de inteligență artificială multimodală avansată al Google conceput pentru a revoluționa modul în care motoarele de căutare înțeleg și răspund la interogările complexe ale utilizatorilor. Anunțat în mai 2021 de Pandu Nayak, Google Fellow și Vicepreședinte al Search, MUM reprezintă o schimbare fundamentală în tehnologia de regăsire a informațiilor. Construit pe framework-ul T5 text-to-text și având aproximativ 110 miliarde de parametri, MUM este de 1.000 de ori mai puternic decât BERT, precedentul model revoluționar de procesare a limbajului natural al Google. Spre deosebire de algoritmii tradiționali de căutare care procesează textul izolat, MUM procesează simultan text, imagini, video și audio și înțelege informațiile în peste 75 de limbi nativ. Această capacitate multimodală și multilingvă permite lui MUM să înțeleagă interogări complexe care anterior necesitau mai multe căutări din partea utilizatorilor, transformând căutarea dintr-un simplu exercițiu de potrivire a cuvintelor cheie într-un sistem inteligent de regăsire a informațiilor contextuale. MUM nu doar înțelege limbajul, ci îl și generează, fiind capabil să sintetizeze informații din surse și formate diverse pentru a oferi răspunsuri cuprinzătoare și nuanțate, care abordează pe deplin intenția utilizatorului.
Drumul Google către MUM reflectă ani de inovații incrementale în procesarea limbajului natural și învățarea automată. Evoluția a început cu Hummingbird (2013), care a introdus înțelegerea semantică pentru a interpreta sensul din spatele interogărilor, nu doar potrivirea cuvintelor cheie. A urmat RankBrain (2015), care a folosit machine learning pentru a înțelege cuvinte-cheie din coada lungă și tipare noi de căutare. Neural Matching (2018) a avansat și mai mult, folosind rețele neuronale pentru a asocia interogările cu conținut relevant la un nivel semantic mai profund. BERT (Bidirectional Encoder Representations from Transformers), lansat în 2019, a fost o piatră de hotar, permițând înțelegerea contextului în fraze și paragrafe, îmbunătățind capacitatea Google de a interpreta limbajul nuanțat. Totuși, BERT avea limitări semnificative—procesa doar text, avea suport multilingv limitat și nu putea gestiona complexitatea interogărilor care necesitau sinteză de informații din mai multe formate. Conform cercetărilor Google, utilizatorii emit în medie opt interogări separate pentru a răspunde la întrebări complexe, precum compararea a două destinații de drumeție sau evaluarea opțiunilor de produse. Această statistică a evidențiat un decalaj critic în tehnologia de căutare pe care MUM a fost conceput special să îl rezolve. Helpful Content Update (2022) și framework-ul E-E-A-T (2023) au rafinat modul în care Google prioritizează conținutul autorizat și de încredere. MUM se bazează pe toate aceste inovații, introducând capabilități ce depășesc limitările anterioare, reprezentând nu doar o îmbunătățire incrementală, ci o schimbare de paradigmă în modul în care motoarele de căutare procesează și furnizează informații.
Fundația tehnică a MUM se bazează pe arhitectura Transformer, în special pe framework-ul T5 (Text-to-Text Transfer Transformer) dezvoltat anterior de Google. Framework-ul T5 tratează toate sarcinile de procesare a limbajului natural ca probleme text-to-text, convertind inputurile și outputurile într-o reprezentare textuală unificată. MUM extinde această abordare prin includerea capabilităților de procesare multimodală, permițându-i să gestioneze text, imagini, video și audio simultan într-un singur model unificat. Această alegere arhitecturală este semnificativă deoarece permite lui MUM să înțeleagă relații și context între diferite tipuri de media în moduri imposibile pentru modelele anterioare. De exemplu, la procesarea unei interogări despre drumeția pe Mt. Fuji combinată cu imaginea unui anumit tip de bocanci, MUM nu analizează separat textul și imaginea—le procesează împreună, înțelegând cum caracteristicile bocancilor se raportează la contextul interogării. Cei 110 miliarde de parametri ai modelului îi oferă capacitatea de a stoca și procesa un volum vast de cunoștințe despre limbaj, concepte vizuale și relațiile dintre acestea. MUM este antrenat pe 75 de limbi diferite și pe multe sarcini simultan, ceea ce îi permite să dezvolte o înțelegere mai cuprinzătoare a informațiilor și a cunoașterii globale decât modelele antrenate pe o singură limbă sau sarcină. Această abordare multitasking face ca MUM să recunoască tipare și relații transferabile între limbi și domenii, fiind mai robust și generalizabil decât modelele anterioare. Procesarea simultană a mai multor limbi în timpul antrenării permite lui MUM să realizeze transfer de cunoștințe între limbi, adică să înțeleagă informații scrise într-o limbă și să aplice acea înțelegere la interogările din altă limbă, depășind astfel barierele lingvistice care anterior limitau rezultatele căutărilor.
| Atribut | MUM (2021) | BERT (2019) | RankBrain (2015) | Framework-ul T5 |
|---|---|---|---|---|
| Funcție principală | Înțelegere multimodală a interogărilor și sinteză de răspuns | Înțelegere contextuală pe bază de text | Interpretare a cuvintelor-cheie din coada lungă | Învățare transfer text-to-text |
| Tipuri de input | Text, imagini, video, audio | Doar text | Doar text | Doar text |
| Suport lingvistic | Peste 75 de limbi nativ | Suport multilingv limitat | Preponderent engleză | Preponderent engleză |
| Număr parametri model | ~110 miliarde | ~340 milioane | Nedezvăluit | ~220 milioane |
| Comparație de putere | De 1.000x mai puternic decât BERT | Reper de bază | Precursorul lui BERT | Fundament pentru MUM |
| Capabilități | Înțelegere + generare | Doar înțelegere | Recunoaștere tipare | Transformare text |
| Impact în SERP | Rezultate multiformat îmbogățite | Fragmente mai bune și context | Relevanță îmbunătățită | Tehnologie fundamentală |
| Gestionare complexitate interogări | Interogări complexe, cu mai multe etape | Context pentru o singură interogare | Variații din coada lungă | Sarcini de transformare text |
| Transfer de cunoștințe | Între limbi și modalități | Doar în interiorul unei limbi | Transfer limitat | Transfer între sarcini |
| Aplicație reală | Google Search, AI Overviews | Clasificare Google Search | Clasificare Google Search | Fundația tehnică pentru MUM |
Procesarea interogărilor de către MUM implică mai multe etape sofisticate care colaborează pentru a oferi răspunsuri cuprinzătoare și contextuale. Când un utilizator trimite o interogare, MUM începe cu preprocesarea independentă de limbă, înțelegând interogarea în oricare din cele peste 75 de limbi suportate, fără a necesita traducere. Această înțelegere nativă păstrează nuanțele lingvistice și contextul regional care s-ar putea pierde prin traducere. Următorul pas implică potrivirea secvențială (sequence-to-sequence), analizând întreaga interogare ca o secvență de sens, nu doar ca un set de cuvinte-cheie izolate. Astfel, MUM poate înțelege relațiile dintre concepte—de exemplu, recunoscând că o interogare despre „pregătirea pentru Mt. Fuji după ce ai urcat pe Mt. Adams” implică comparație, pregătire și adaptare contextuală. Simultan, MUM realizează analiza inputului multimodal, procesând orice imagini, videoclipuri sau alte media incluse în interogare. Modelul efectuează apoi procesare simultană a interogării, evaluând mai multe posibile intenții ale utilizatorului în paralel, nu doar interpretarea unei singure variante. Astfel, MUM poate recunoaște că o interogare despre drumeția pe Mt. Fuji ar putea viza pregătirea fizică, alegerea echipamentului, experiențe culturale sau logistica de călătorie—și afișează informații relevante pentru toate aceste interpretări. Înțelegerea semantică bazată pe vectori convertește interogarea și conținutul indexat în vectori de înaltă dimensiune care reflectă sensul semantic, permițând regăsirea pe baza similarității conceptuale, nu doar a potrivirii de cuvinte cheie. MUM aplică apoi filtrarea conținutului prin transfer de cunoștințe, folosind machine learning antrenat pe loguri de căutare, date de navigare și tipare comportamentale pentru a prioritiza sursele de înaltă calitate și autoritate. În final, MUM generează o compoziție SERP multimedia îmbogățită, combinând fragmente text, imagini, videoclipuri, întrebări conexe și elemente interactive într-o experiență vizuală stratificată, pe o singură pagină de căutare. Întregul proces are loc în milisecunde, permițându-i lui MUM să livreze rezultate care răspund nu doar la interogarea explicită, ci și la întrebări ulterioare anticipate și nevoilor conexe de informare.
Capacitățile multimodale ale MUM reprezintă o ruptură fundamentală față de sistemele de căutare bazate doar pe text. Modelul poate procesa și înțelege simultan informații din text, imagini, video și audio, extrăgând sens din fiecare modalitate și sintetizându-l în răspunsuri coerente. Această capacitate este deosebit de utilă pentru interogările care au nevoie de context vizual. De exemplu, dacă un utilizator întreabă „Pot folosi acești bocanci de drumeție pentru Mt. Fuji?” și prezintă o imagine cu bocancii, MUM înțelege caracteristicile bocancilor din imagine—material, modelul tălpii, înălțime, culoare—și le corelează cu cunoștințe despre terenul, clima și cerințele de drumeție pe Mt. Fuji pentru a oferi un răspuns contextualizat. Dimensiunea multilingvă a MUM este la fel de transformatoare. Cu suport nativ pentru peste 75 de limbi, MUM poate face transfer de cunoștințe între limbi, adică învață din surse într-o limbă și aplică acea cunoaștere la interogări în alta. Acest lucru elimină o barieră majoră care limita anterior rezultatele căutărilor la conținutul din limba utilizatorului. Dacă informațiile detaliate despre Mt. Fuji se găsesc cu precădere în surse japoneze—ghiduri locale de drumeție, modele sezoniere de vreme, perspective culturale—MUM poate înțelege acest conținut în japoneză și afișa informații relevante utilizatorilor vorbitori de engleză. Conform testelor Google, MUM a reușit să listeze 800 de variante de vaccinuri COVID-19 în peste 50 de limbi în câteva secunde, demonstrând amploarea și viteza procesării multilingve. Această înțelegere multilingvă este deosebit de valoroasă pentru utilizatorii din piețe non-engleze și pentru interogările despre subiecte cu informație bogată în mai multe limbi. Combinația procesării multimodale și multilingve permite lui MUM să afișeze informații relevante indiferent de formatul în care au fost prezentate sau limba în care au fost publicate inițial, creând o experiență de căutare cu adevărat globală.
MUM transformă fundamental modul în care rezultatele căutării sunt afișate și experimentate de utilizatori. În locul listelor tradiționale de linkuri albastre care au dominat căutarea decenii întregi, MUM creează SERP-uri îmbogățite și interactive ce combină mai multe formate de conținut pe o singură pagină. Utilizatorii pot vedea fragmente text, imagini de înaltă rezoluție, carusele video, întrebări conexe și elemente interactive, fără să părăsească pagina de rezultate. Această schimbare are implicații profunde asupra modului în care utilizatorii interacționează cu căutarea. În loc să efectueze mai multe căutări pentru a strânge informații despre un subiect complex, utilizatorii pot explora diferite unghiuri și subiecte conexe direct în SERP. De exemplu, o interogare precum „pregătirea pentru Mt. Fuji toamna” poate afișa comparații de altitudini, prognoze meteo, recomandări de echipament, ghiduri video și recenzii ale utilizatorilor—totul organizat contextual pe o singură pagină. Integrarea Google Lens, alimentată de MUM, permite utilizatorilor să caute folosind imagini în loc de cuvinte cheie, transformând elementele vizuale din fotografii în instrumente interactive de descoperire. Panelurile „Lucruri de știut” descompun interogările complexe în subiecte ușor de digerat, ghidând utilizatorii prin diferite aspecte ale unui subiect cu fragmente relevante pentru fiecare. Imaginile de înaltă rezoluție, cu zoom apar direct în rezultate, permițând comparații vizuale și reducând fricțiunea în primele etape ale luării deciziilor. Funcționalitatea „Rafinează și extinde” sugerează concepte conexe pentru a ajuta utilizatorii să aprofundeze anumite aspecte sau să exploreze subiecte adiacente. Aceste schimbări marchează trecerea de la căutarea ca simplu mecanism de regăsire la căutarea ca experiență interactivă și exploratorie care anticipează nevoile utilizatorului și oferă informații cuprinzătoare chiar în interfața de căutare. Cercetările indică faptul că această experiență SERP mai bogată reduce numărul mediu de căutări necesare pentru a răspunde la întrebări complexe, însă înseamnă și că utilizatorii pot consuma informația direct în rezultate, fără a mai vizita site-urile web.
Pentru organizațiile care urmăresc prezența lor în sistemele AI, MUM reprezintă o evoluție critică în modul în care informația este descoperită și afișată. Pe măsură ce MUM este din ce în ce mai integrat în Google Search și influențează alte sisteme AI, înțelegerea felului în care brandurile și domeniile apar în rezultatele generate de MUM devine esențială pentru menținerea vizibilității. Procesarea multimodală a MUM impune ca brandurile să optimizeze pe mai multe formate de conținut, nu doar pe text. Un brand care anterior se baza pe poziționarea după anumite cuvinte cheie trebuie acum să asigure descoperirea conținutului său prin imagini, videoclipuri și date structurate. Capacitatea modelului de a sintetiza informații din surse diverse face ca vizibilitatea unui brand să depindă nu doar de propriul website, ci și de modul în care informațiile despre brand sunt prezente în întreg ecosistemul web. Capabilitățile multilingve ale MUM creează noi oportunități și provocări pentru brandurile globale. Conținutul publicat într-o limbă poate fi descoperit de utilizatori care caută în alte limbi, extinzând potențialul de acoperire. Totuși, brandurile trebuie să se asigure că informațiile sunt corecte și consistente în toate limbile, deoarece MUM poate afișa informații din surse multilingve pentru aceeași interogare. Pentru platformele de monitorizare AI precum AmICited, urmărirea impactului MUM este crucială deoarece reflectă modul în care sistemele AI moderne regăsesc și afișează informații. Când se monitorizează locul în care apare un brand în răspunsurile AI—fie în Google AI Overviews, Perplexity, ChatGPT sau Claude—înțelegerea tehnologiei de bază a MUM ajută la explicarea motivului pentru care anumite conținuturi sunt afișate și cum se poate optimiza vizibilitatea. Trecerea la căutarea multimodală și multilingvă înseamnă că brandurile au nevoie de monitorizare complexă, care urmărește prezența în diferite formate de conținut și limbi, nu doar poziționarea tradițională după cuvinte cheie. Organizațiile care înțeleg capabilitățile MUM își pot optimiza mai bine strategia de conținut pentru a asigura vizibilitatea în acest nou peisaj al căutărilor.
Deși MUM reprezintă un progres semnificativ, introduce și noi provocări și limitări pe care organizațiile trebuie să le gestioneze. Ratele mai mici de click-through reprezintă o preocupare majoră pentru publisheri și creatori de conținut, deoarece utilizatorii pot consuma informația direct în rezultatele căutării, fără a mai accesa website-urile. Această schimbare face ca metricile tradiționale de trafic să fie indicatori mai puțin fiabili ai succesului conținutului. Creșterea cerințelor pentru SEO tehnic înseamnă că, pentru a fi corect înțeles de MUM, conținutul trebuie să fie bine structurat, cu schema markup adecvată, HTML semantic și relații clare între entități. Conținutul fără această bază tehnică poate să nu fie indexat sau înțeles corect de procesarea multimodală a MUM. Saturația SERP creează dificultăți de vizibilitate, deoarece mai multe formate de conținut concurează simultan pentru atenție pe o singură pagină. Chiar și conținutul valoros poate obține mai puține sau zero clickuri dacă utilizatorii găsesc suficiente informații direct în SERP. Riscul de rezultate înșelătoare apare atunci când MUM afișează informații din surse multiple care se pot contrazice sau când contextul se pierde în sinteză. Dependența de date structurate face ca materialele nestructurate sau slab formate să nu fie corect înțelese sau afișate de MUM. Provocări de nuanță lingvistică și culturală pot apărea atunci când MUM transferă cunoștințe între limbi, pierzând uneori contextul cultural sau variațiile regionale de sens. Resursele computaționale necesare pentru rularea MUM la scară sunt considerabile, deși Google a investit în eficientizare pentru reducerea amprentei de carbon. Problematici de bias și corectitudine necesită monitorizare continuă pentru a preveni perpetuarea prejudecăților din datele de antrenament sau dezavantajarea anumitor perspective sau comunități.
Apariția MUM cere schimbări fundamentale în abordarea SEO și a strategiei de conținut a organizațiilor. Optimizarea tradițională centrată pe cuvinte cheie devine mai puțin eficientă când MUM poate înțelege intenția și contextul dincolo de potrivirile exacte. Strategia de conținut bazată pe subiecte devine mai importantă decât cea bazată pe cuvinte cheie, fiind nevoie de clustere de conținut cuprinzătoare care tratează subiectele din mai multe perspective. Crearea de conținut multimedia nu mai este opțională—organizațiile trebuie să investească în imagini, videoclipuri și conținut interactiv de calitate care să completeze materialul textual. Implementarea datelor structurate devine esențială, schema markup ajutând MUM să înțeleagă structura și relațiile din conținut. Construirea entităților și optimizarea semantică consolidează autoritatea pe subiecte și îmbunătățește modul în care MUM percepe conexiunile între materiale. Strategia multilingvă de conținut capătă importanță pe măsură ce capabilitățile de transfer lingvistic ale MUM permit descoperirea materialelor pe mai multe piețe. Cartografierea intențiilor utilizatorilor devine mai sofisticată, necesitând înțelegerea nu doar a intenției principale, ci și a întrebărilor conexe și subiectelor adiacente pe care utilizatorii le pot explora. Actualitatea și acuratețea conținutului devin critice, deoarece MUM sintetizează informații din surse multiple—materialul depășit sau inexact poate fi dezavantajat. Optimizarea cross-platform se extinde dincolo
În timp ce BERT (2019) s-a concentrat pe înțelegerea limbajului natural în cadrul interogărilor bazate pe text, MUM reprezintă o evoluție semnificativă. MUM este construit pe framework-ul T5 text-to-text și este de 1.000 de ori mai puternic decât BERT. Spre deosebire de procesarea doar a textului de către BERT, MUM este multimodal—procesează simultan text, imagini, video și audio. În plus, MUM suportă nativ peste 75 de limbi, în timp ce BERT avea suport multilingv limitat la lansare. MUM poate atât să înțeleagă, cât și să genereze limbaj, fiind capabil să gestioneze interogări complexe, cu mai multe etape, pe care BERT nu le putea aborda eficient.
Multimodal se referă la abilitatea MUM de a procesa și înțelege informații din mai multe tipuri de formate de intrare simultan. În loc să analizeze textul separat de imagini sau video, MUM procesează toate aceste formate împreună, într-un mod unificat. Aceasta înseamnă că atunci când cauți ceva de genul 'bocanci de drumeție pentru Mt. Fuji', MUM poate să înțeleagă interogarea ta textuală, să analizeze imagini cu bocanci, să urmărească recenzii video și să extragă descrieri audio—totul în același timp. Această abordare integrată permite MUM să ofere răspunsuri mai bogate și mai contextuale, care iau în considerare informații din toate aceste tipuri diferite de media.
MUM este antrenat pe peste 75 de limbi, ceea ce reprezintă un progres major pentru accesibilitatea globală a căutărilor. Această capacitate multilingvă înseamnă că MUM poate transfera cunoștințe între limbi—dacă există informații utile despre un subiect în japoneză, MUM le poate înțelege și afișa rezultate relevante pentru utilizatorii vorbitori de engleză. Acest lucru elimină barierele lingvistice care anterior limitau rezultatele căutărilor la conținutul în limba nativă a utilizatorului. Pentru branduri și creatori de conținut, aceasta înseamnă că materialele lor au potențial de vizibilitate pe mai multe piețe lingvistice, iar utilizatorii din întreaga lume pot accesa informații indiferent de limba în care au fost publicate inițial.
T5 (Text-to-Text Transfer Transformer) este un model anterior al Google bazat pe arhitectura transformer, pe care este construit MUM. Framework-ul T5 tratează toate sarcinile NLP ca probleme text-to-text, adică transformă atât inputul, cât și outputul în format text pentru o procesare unificată. MUM extinde capabilitățile T5 prin includerea procesării multimodale (gestionând imagini, video și audio) și scalând totul la aproximativ 110 miliarde de parametri. Această fundație îi permite lui MUM să înțeleagă și să genereze limbaj, păstrând eficiența și flexibilitatea care au făcut T5 de succes.
MUM schimbă fundamental modul în care conținutul este descoperit și afișat în rezultatele de căutare. În locul listelor tradiționale de linkuri albastre, MUM creează SERP-uri îmbogățite cu mai multe formate de conținut—imagini, videoclipuri, fragmente text și elemente interactive—pe aceeași pagină. Asta înseamnă că brandurile trebuie să optimizeze pe mai multe formate, nu doar pe text. Conținutul care anterior necesita ca utilizatorii să dea click pe mai multe pagini poate fi acum afișat direct în rezultatele căutării. Însă, acest lucru poate duce și la rate de click mai mici pentru anumite conținuturi, deoarece utilizatorii pot consuma informația direct în SERP. Brandurile trebuie acum să se concentreze pe vizibilitatea în rezultatele căutării și să se asigure că materialele sunt structurate cu schema markup pentru a fi corect înțelese de MUM.
MUM este esențial pentru platformele de monitorizare AI deoarece reflectă modul în care sistemele AI moderne înțeleg și recuperează informații. Pe măsură ce MUM devine tot mai prezent în Google Search și influențează alte sisteme AI, monitorizarea locului în care apar brandurile și domeniile în rezultatele generate de MUM devine esențială. AmICited urmărește modul în care brandurile sunt citate și apar în sistemele AI, inclusiv în căutarea Google îmbunătățită cu MUM. Înțelegerea capabilităților multimodale și multilingve ale MUM ajută organizațiile să își optimizeze prezența în diferite formate de conținut și limbi, asigurându-se că sunt vizibile atunci când sisteme AI precum MUM recuperează și afișează informațiile către utilizatori.
Da, MUM poate procesa imagini și videoclipuri cu un nivel sofisticat de înțelegere. Când încarci o imagine sau incluzi un videoclip într-o interogare, MUM nu doar recunoaște obiecte—ci extrage context, semnificație și relații. De exemplu, dacă îi arăți lui MUM o fotografie cu bocanci de drumeție și întrebi 'pot folosi aceștia pentru Mt. Fuji?', MUM înțelege caracteristicile bocancilor din imagine și le corelează cu întrebarea ta pentru a oferi un răspuns contextual. Această înțelegere multimodală este una dintre cele mai puternice caracteristici ale MUM, permițându-i să răspundă la întrebări care necesită atât cunoștințe vizuale, cât și textuale.
Începe să urmărești cum te menționează chatbot-urile AI pe ChatGPT, Perplexity și alte platforme. Obține informații utile pentru a-ți îmbunătăți prezența în AI.
Află despre Multitask Unified Model (MUM) al Google și impactul său asupra rezultatelor de căutare AI. Înțelege cum procesează MUM interogări complexe prin mai ...
Discuție în comunitate care explică Google MUM și impactul său asupra căutării AI. Experții împărtășesc modul în care acest model AI multi-modal influențează op...

Află cum sistemele de căutare AI multimodală procesează text, imagini, audio și video împreună pentru a livra rezultate mai precise și relevante contextual decâ...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.