Definiția Algoritmului Sonar
Algoritmul Sonar este sistemul proprietar de clasificare RAG (retrieval-augmented generation) al Perplexity care alimentează motorul său de răspunsuri, combinând căutarea semantică hibridă și pe cuvinte-cheie, reordonarea neurală și generarea de citări în timp real. Spre deosebire de motoarele de căutare tradiționale care clasifică pagini pentru afișare într-o listă de rezultate, Sonar clasifică fragmente de conținut pentru a fi sintetizate într-un singur răspuns unificat cu citări inline către documentele sursă. Algoritmul prioritizează noutatea conținutului, relevanța semantică și citabilitatea pentru a livra răspunsuri bine fundamentate, bazate pe surse, minimizând halucinațiile. Sonar reprezintă o schimbare fundamentală în modul în care sistemele AI recuperează și clasifică informația—trecând de la semnale de autoritate bazate pe linkuri la metrici de utilitate axate pe răspunsuri, care pun accent pe satisfacerea directă a intenției utilizatorului și pe citarea clară a conținutului în răspunsurile sintetizate. Această distincție este esențială pentru a înțelege cum diferă vizibilitatea în motoarele AI de răspuns față de SEO-ul tradițional, deoarece Sonar evaluează conținutul nu pentru capacitatea de a se clasa într-o listă, ci pentru capacitatea de a fi extras, sintetizat și atribuit în cadrul unui răspuns generat de AI.
Context și fundal: Evoluția clasificării AI
Apariția Algoritmului Sonar reflectă o schimbare de paradigmă la nivelul industriei, spre generarea augmentată prin recuperare ca arhitectură dominantă pentru motoarele AI de răspuns. Când Perplexity a fost lansat la sfârșitul anului 2022, compania a identificat o lacună critică în peisajul AI: deși ChatGPT oferea capabilități conversaționale puternice, îi lipsea accesul la informații în timp real și atribuirea surselor, ceea ce genera halucinații și răspunsuri depășite. Echipa fondatoare Perplexity, care lucra inițial la un instrument de traducere a interogărilor de baze de date, s-a reorientat total spre a construi un motor de răspunsuri care să combine căutarea web live cu sinteza LLM. Această decizie strategică a modelat arhitectura Sonar de la început—algoritmul a fost proiectat nu pentru a clasa pagini pentru navigarea umană, ci pentru a recupera și clasa fragmente de conținut pentru sinteză și citare automată. În ultimii doi ani, Sonar a evoluat într-unul dintre cele mai sofisticate sisteme de clasificare din ecosistemul AI, cu modelele Sonar ale Perplexity ocupând locurile 1 până la 4 în evaluarea Search Arena, depășind semnificativ modelele competitoare de la Google și OpenAI. Algoritmul procesează acum peste 400 de milioane de interogări pe lună, indexând peste 200 de miliarde de adrese URL unice și menținând noutatea în timp real prin zeci de mii de actualizări de index pe secundă. Această amploare și sofisticare subliniază importanța Sonar ca paradigmă definitorie în era căutării AI.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
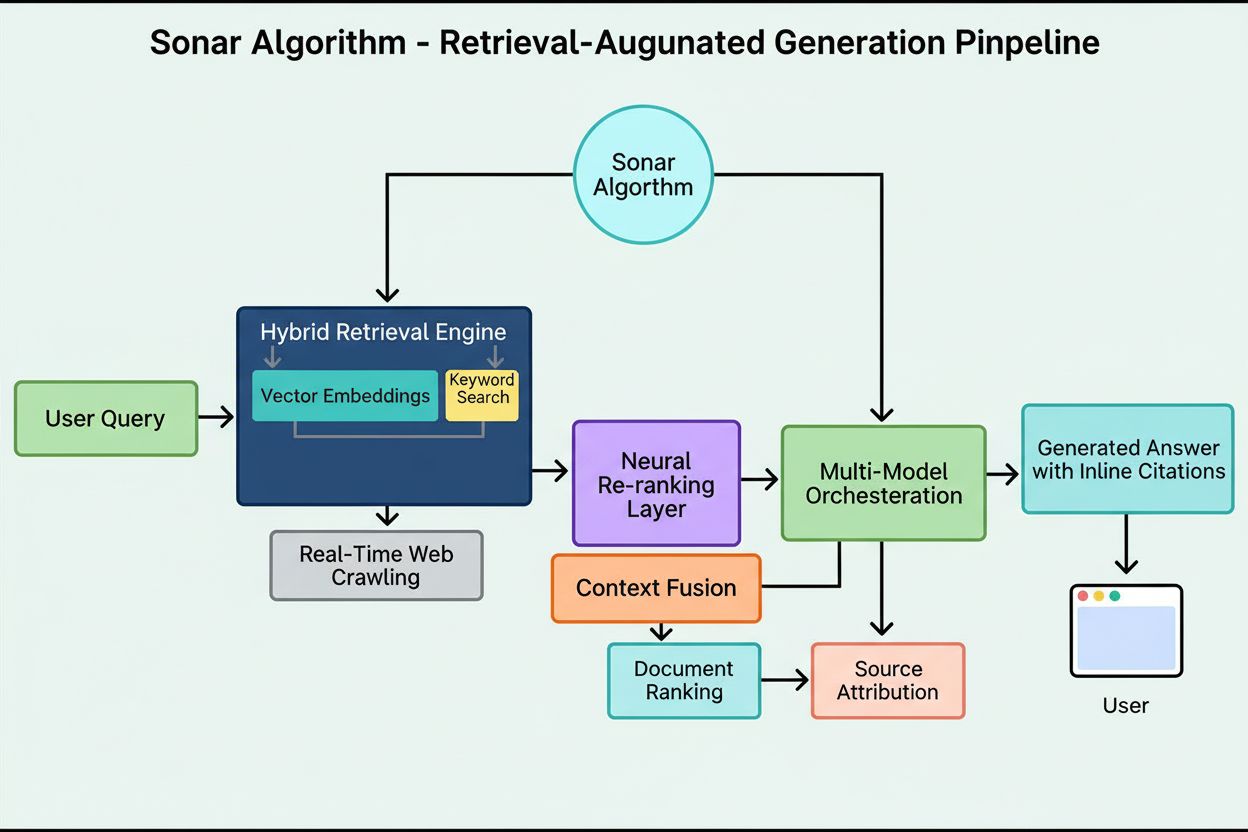
Cum funcționează Algoritmul Sonar: Pipeline-ul RAG multi-etapă
Sistemul de clasificare Sonar funcționează printr-un pipeline de generare augmentată prin recuperare în cinci etape, care transformă interogările utilizatorilor în răspunsuri fundamentate și citate. Prima etapă, Analiza intenției interogării, folosește un LLM pentru a depăși simpla potrivire pe cuvinte-cheie și pentru a înțelege semantic ce dorește cu adevărat utilizatorul, interpretând contextul, nuanța și intenția de bază. A doua etapă, Recuperarea web live, trimite interogarea analizată către indexul distribuit masiv al Perplexity, alimentat de Vespa AI, care caută în timp real pagini și documente relevante. Acest sistem de recuperare combină recuperarea densă (căutare vectorială cu embeddinguri semantice) și recuperarea rară (căutare lexicală/pe cuvinte-cheie), îmbinând rezultatele pentru a produce aproximativ 50 de documente candidate diverse. A treia etapă, Extracția și contextualizarea fragmentelor, nu transmite textul integral al paginilor către modelul generativ; în schimb, algoritmii extrag cele mai relevante fragmente, paragrafe sau bucăți direct legate de interogare, agregându-le într-o fereastră contextuală focalizată. A patra etapă, Generarea răspunsului sintetizat cu citări, transmite acest context curat către un LLM ales (din familia proprietară Sonar a Perplexity sau modele terțe precum GPT-4 sau Claude), care generează un răspuns în limbaj natural bazat strict pe informațiile recuperate. Esențial, citările inline leagă fiecare afirmație de documentele sursă, asigurând transparență și verificabilitate. A cincea etapă, Rafinamentul conversațional, menține contextul conversațional pe mai multe rânduri, permițând întrebări de clarificare și rafinarea răspunsurilor prin căutări web iterative. Principiul definitoriu al pipeline-ului—“nu trebuie să spui nimic ce nu ai recuperat”—asigură că răspunsurile generate de Sonar sunt ancorate în surse verificabile, reducând fundamental halucinațiile comparativ cu modelele ce se bazează doar pe date de antrenament.
Tabel comparativ: Algoritmul Sonar vs. Căutarea tradițională și alte sisteme LLM
| Aspect | Căutare tradițională (Google) | Algoritmul Sonar (Perplexity) | Clasificare ChatGPT | Clasificare Gemini | Clasificare Claude |
|---|
| Unitate principală | Listă ordonată de linkuri | Un singur răspuns sintetizat cu citări | Menționări bazate pe consens de entități | Conținut aliniat E-E-A-T | Surse neutre, bazate pe fapte |
| Focus recuperare | Cuvinte-cheie, linkuri, semnale ML | Căutare semantică hibridă + cuvinte-cheie | Date de antrenament + browsing web | Integrare knowledge graph | Filtre de siguranță constituțională |
| Prioritate noutate | Query-deserves-freshness (QDF) | Recuperare web live, impuls de 37% în 48h | Prioritate scăzută, depinde de datele de antrenament | Moderată, integrată cu Google Search | Prioritate scăzută, accent pe stabilitate |
| Semnale de clasificare | Backlink-uri, autoritate domeniu, CTR | Noutate, relevanță semantică, citabilitate, autoritate | Recunoaștere entități, menționări consens | E-E-A-T, aliniere conversațională, date structurate | Transparență, citări verificabile, neutralitate |
| Mecanism citare | Fragmente URL în rezultate | Citări inline cu linkuri sursă | Implicit, adesea fără citări | AI Overviews cu atribuire | Atribuire explicită sursă |
| Diversitate conținut | Rezultate multiple pe site-uri | Câteva surse selectate pentru sinteză | Sintetizare din mai multe surse | Surse multiple în overview | Surse echilibrate, neutre |
| Personalizare | Subtilă, mai ales implicită | Moduri focus explicite (Web, Academic, Finance etc.) | Implicit din conversație | Implicit după tipul interogării | Minima, accent pe consistență |
| Gestionare PDF | Indexare standard | Avantaj de 22% la citare față de HTML | Indexare standard | Indexare standard | Indexare standard |
| Impact schema | FAQ schema la featured snippets | FAQ schema crește citările cu 41%, reduce timpul cu 6h | Impact direct minim | Impact moderat pe knowledge graph | Impact direct minim |
| Optimizare latență | Milisecunde pentru clasificare | Recuperare + generare subsecundă | Secunde pentru sinteză | Secunde pentru sinteză | Secunde pentru sinteză |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Arhitectura tehnică: Recuperare hibridă și reordonare neurală
Fundamentul tehnic al Algoritmului Sonar se bazează pe un motor de recuperare hibrid care combină strategii multiple de căutare pentru a maximiza atât acuratețea, cât și precizia. Recuperarea densă (căutare vectorială) folosește embeddinguri semantice pentru a înțelege sensul conceptual al interogărilor, găsind documente contextuale similare chiar fără potriviri exacte pe cuvinte-cheie. Această abordare utilizează embeddinguri bazate pe transformere care mapează interogările și documentele în spații vectoriale de mare dimensiune unde conținutul similar semantic se grupează. Recuperarea rară (căutare lexicală) completează recuperarea densă oferind precizie pentru termeni rari, nume de produse, identificatori interni de companie și entități specifice unde ambiguitatea semantică nu este dorită. Sistemul folosește funcții de clasificare precum BM25 pentru potrivire exactă pe acești termeni critici. Aceste două metode de recuperare sunt îmbinate și deduplicate pentru a oferi aproximativ 50 de documente candidate diverse, evitând supraspecializarea pe domenii și asigurând o acoperire largă pe surse autoritare multiple. După recuperarea inițială, stratul de reordonare neurală Sonar utilizează modele ML avansate (precum DeBERTa-v3 cross-encoders) pentru a evalua candidații cu ajutorul unui set bogat de caracteristici: scoruri de relevanță lexicală, similaritate vectorială, autoritate document, semnale de noutate, metrici de engagement și metadate. Această arhitectură multi-fază permite Sonar să rafineze progresiv rezultatele sub constrângeri stricte de latență, asigurând ca setul final să reprezinte cele mai relevante și calitative surse pentru sinteză. Întreaga infrastructură de recuperare este construită pe Vespa AI, o platformă de căutare distribuită capabilă să gestioneze indexare la scară web (200+ miliarde de URL-uri), actualizări în timp real (zeci de mii pe secundă) și înțelegere granulară a conținutului prin fragmentare de documente. Această alegere arhitecturală permite echipei tehnice compacte Perplexity să se concentreze pe componente diferențiatoare—orchestrare RAG, fine-tuning modele Sonar și optimizare inferență—nu pe reinventarea căutării distribuite.
Noutatea conținutului ca factor dominant de clasificare
Noutatea conținutului este unul dintre cele mai puternice semnale de clasificare ale Sonar, cercetările empirice demonstrând că paginile recent actualizate primesc rate de citare semnificativ mai mari. În testări A/B controlate derulate timp de 24 de săptămâni pe 120 de URL-uri, articolele actualizate în ultimele 48 de ore au fost citate cu 37% mai frecvent decât conținutul identic cu timestamp-uri mai vechi. Acest avantaj a persistat la aproximativ 14% după două săptămâni, indicând că noutatea oferă un impuls susținut, dar în scădere graduală. Mecanismul din spatele acestei prioritizări izvorăște din filosofia Sonar: algoritmul tratează conținutul învechit ca având risc crescut de halucinații, presupunând că informațiile vechi pot fi depășite de evoluții recente. Infrastructura Perplexity procesează zeci de mii de cereri de actualizare a indexului pe secundă, permițând semnale de noutate în timp real. Un model ML prezice dacă un URL necesită reindexare și programează actualizările după importanța paginii și frecvența istorică a modificărilor, asigurând ca paginile valoroase să fie actualizate mai agresiv. Chiar și editările cosmetice minore resetează ceasul noutății, dacă CMS-ul republică timestamp-ul. Pentru editori, asta creează o imperativă strategică: adoptă un ritm de redacție cu actualizări săptămânale sau zilnice, sau privește conținutul evergreen pierzând treptat vizibilitate. Implicația este profundă—în era Sonar, viteza de actualizare nu mai este un vanitate metric, ci un mecanism de supraviețuire. Brandurile care automatizează micro-actualizări săptămânale, adaugă changelog-uri live sau mențin fluxuri continue de optimizare vor obține o cotă de citare disproporționată față de concurenții care se bazează pe pagini statice, rar actualizate.
Relevanța semantică și structura conținutului axată pe răspuns
Sonar prioritizează relevanța semantică în defavoarea densității cuvintelor-cheie, răsplătind fundamental conținutul care răspunde direct la întrebări în limbaj natural, conversațional. Sistemul de recuperare al algoritmului folosește embeddinguri vectoriale dense pentru a potrivi interogările cu conținut la nivel conceptual, ceea ce înseamnă că paginile care folosesc sinonime, termeni înrudiți sau limbaj contextual bogat pot depăși la clasificare paginile supraîncărcate cu cuvinte-cheie, dar sărace semantic. Această schimbare de la ranking-ul centrat pe cuvinte-cheie la cel centrat pe sens are implicații profunde pentru strategia de conținut. Conținutul care câștigă în Sonar prezintă câteva caracteristici structurale: începe cu un rezumat factual scurt înainte de detalii, folosește heading-uri H2/H3 descriptive și paragrafe scurte pentru a facilita extragerea ușoară a fragmentelor, include citări clare și linkuri către surse primare, și menține timestamp-uri și note de versiune vizibile pentru a semnaliza noutatea. Fiecare paragraf funcționează ca o unitate semantică atomică, optimizată pentru claritate la nivel de copy-paste și pentru înțelegerea LLM. Tabelele, listele cu bullet-uri și graficele etichetate sunt extrem de valoroase, deoarece prezintă informația în formate structurate, ușor de citat. Algoritmul răsplătește și analiza originală și datele unice față de simpla agregare, motorul de sinteză Sonar căutând surse cu perspective originale, documente primare sau insight-uri proprietare care le diferențiază de prezentările generale. Accentul pe bogăția semantică și structura axată pe răspuns marchează o ruptură fundamentală față de SEO-ul tradițional, unde prioritatea era plasarea cuvintelor-cheie și autoritatea linkurilor. În era Sonar, conținutul trebuie proiectat pentru recuperare și sinteză automată, nu pentru navigare umană.
Găzduirea PDF ca avantaj strategic
PDF-urile găzduite public reprezintă un avantaj semnificativ, adesea neglijat, în sistemul de clasificare Sonar, testarea empirică arătând că versiunile PDF ale conținutului depășesc echivalentele HTML cu aproximativ 22% la frecvența citărilor. Acest avantaj derivă din faptul că crawler-ul Sonar tratează PDF-urile mai favorabil decât paginile HTML. PDF-urile nu au bannere de cookie, cerințe de randare JavaScript, autentificare paywall și alte complicații HTML care pot ascunde sau întârzia accesul la conținut. Crawler-ul Sonar poate citi PDF-urile curat și predictibil, extrăgând textul fără ambiguitatea de parsare care afectează structurile HTML complexe. Editorii pot valorifica strategic acest avantaj găzduind PDF-uri în directoare publice, folosind nume de fișiere semantice care reflectă subiectul conținutului și semnalând PDF-ul ca fiind canonic cu tag-ul <link rel="alternate" type="application/pdf"> în head-ul HTML. Acest lucru creează așa-numitul “LLM honey-trap”—un activ cu vizibilitate mare pe care scripturile de tracking ale competitorilor nu îl pot detecta sau monitoriza ușor. Pentru companiile B2B, furnizorii SaaS și organizațiile axate pe cercetare, această strategie este deosebit de puternică: publicarea de whitepaper-uri, rapoarte de cercetare, studii de caz și documentații tehnice sub formă de PDF poate crește semnificativ ratele de citare Sonar. Cheia este tratarea PDF-ului nu ca pe un simplu atașament descărcabil, ci ca pe o copie canonică ce merită cel puțin la fel de multă optimizare ca versiunea HTML. Această abordare s-a dovedit eficientă în special pentru conținutul enterprise, unde PDF-urile conțin informații mai structurate și mai autoritare decât paginile web.
FAQ schema și optimizarea datelor structurate
Marcajul JSON-LD FAQ schema amplifică semnificativ ratele de citare Sonar, paginile cu trei sau mai multe blocuri FAQ primind citări cu 41% mai frecvent decât paginile fără schema. Această creștere dramatică reflectă preferința Sonar pentru conținut structurat, pe fragmente, care se aliniază logicii sale de recuperare și sinteză. Schema FAQ prezintă unități Q&A discrete, auto-conținute, pe care algoritmul le poate extrage, clasa și cita ca blocuri semantice atomice. Spre deosebire de SEO-ul tradițional, unde schema FAQ era un “nice-to-have”, Sonar tratează marcajul Q&A structurat ca un factor esențial de clasificare. În plus, Sonar citează adesea întrebările FAQ ca text ancoră, reducând riscul de pierdere a contextului care apare când LLM-ul rezumă propoziții aleatorii din mijlocul paragrafelor. Schema accelerează și timpul până la prima citare cu aproximativ șase ore, sugerând că parserul Sonar prioritizează blocurile Q&A structurate devreme în cascadă. Pentru editori, strategia de optimizare este directă: inserează trei până la cinci blocuri FAQ sub fold, cu întrebări conversaționale care oglindesc interogări reale ale utilizatorilor. Întrebările trebuie să folosească formulări long-tail și să aibă simetrie semantică cu interogările probabile ale Sonar. Fiecare răspuns trebuie să fie concis, factual și direct, evitând limbajul de marketing. Această abordare s-a dovedit deosebit de eficientă pentru companii SaaS, clinici medicale și firme de servicii profesionale, unde conținutul FAQ se aliniază natural atât cu intenția utilizatorului, cât și cu nevoile de sinteză ale Sonar.
Factori de clasificare și mecanici de citare: Cadru comprehensiv
Sistemul de clasificare Sonar integrează multiple semnale într-un cadru unificat de citare, cercetarea identificând opt factori principali care influențează selecția surselor și frecvența citărilor. În primul rând, relevanța semantică pentru întrebare domină recuperarea, algoritmul prioritizând conținutul care răspunde clar la interogare în limbaj natural. În al doilea rând, autoritatea și credibilitatea contează semnificativ, parteneriatele Perplexity cu publisheri și impulsurile algoritmice favorizând organizațiile media consacrate, instituțiile academice și experții recunoscuți. În al treilea rând, noutatea are greutate excepțională, după cum s-a discutat, actualizările recente declanșând creșteri de 37% în citări. În al patrulea rând, diversitatea și acoperirea sunt apreciate, Sonar preferând mai multe surse de calitate în locul răspunsurilor dintr-o singură sursă, reducând riscul de halucinații prin cross-validare. În al cincilea rând, modul și aria determină ce indexe caută Sonar—moduri precum Academic, Finance, Writing și Social restrâng tipurile de surse, iar selectorii de surse (Web, Org Files, Web + Org Files, None) decid dacă recuperarea trage din web-ul deschis, documente interne sau ambele. În al șaselea rând, citabilitatea și accesul sunt critice; dacă PerplexityBot poate indexa și citi conținutul, acesta e mai ușor de citat, făcând conformitatea robots.txt și viteza paginii esențiale. În al șaptelea rând, filtrele personalizate via API permit implementărilor enterprise să prefere sau să restricționeze anumite domenii, modificând clasificarea în colecțiile whitelisted. În al optulea rând, contextul conversației influențează întrebările de follow-up, paginile care se potrivesc cu intenția evolutivă depășind referințele generice. Împreună, acești factori creează un spațiu de clasificare multidimensional unde succesul necesită optimizare simultană pe mai multe axe, nu doar pe o singură pârghie precum backlink-urile sau densitatea cuvintelor-cheie.
Concluzii cheie și implicații strategice pentru optimizarea conținutului
- Noutatea este obligatorie: Automatizează actualizări să