Vplyv AI crawlerov na serverové zdroje: Čo očakávať
Zistite, ako AI crawlery ovplyvňujú serverové zdroje, šírku pásma a výkon. Objavte reálne štatistiky, stratégie zmiernenia a infraštruktúrne riešenia na efektívne zvládanie záťaže botov.
Publikované dňa Jan 3, 2026.Naposledy upravené dňa Jan 3, 2026 o 3:24 am
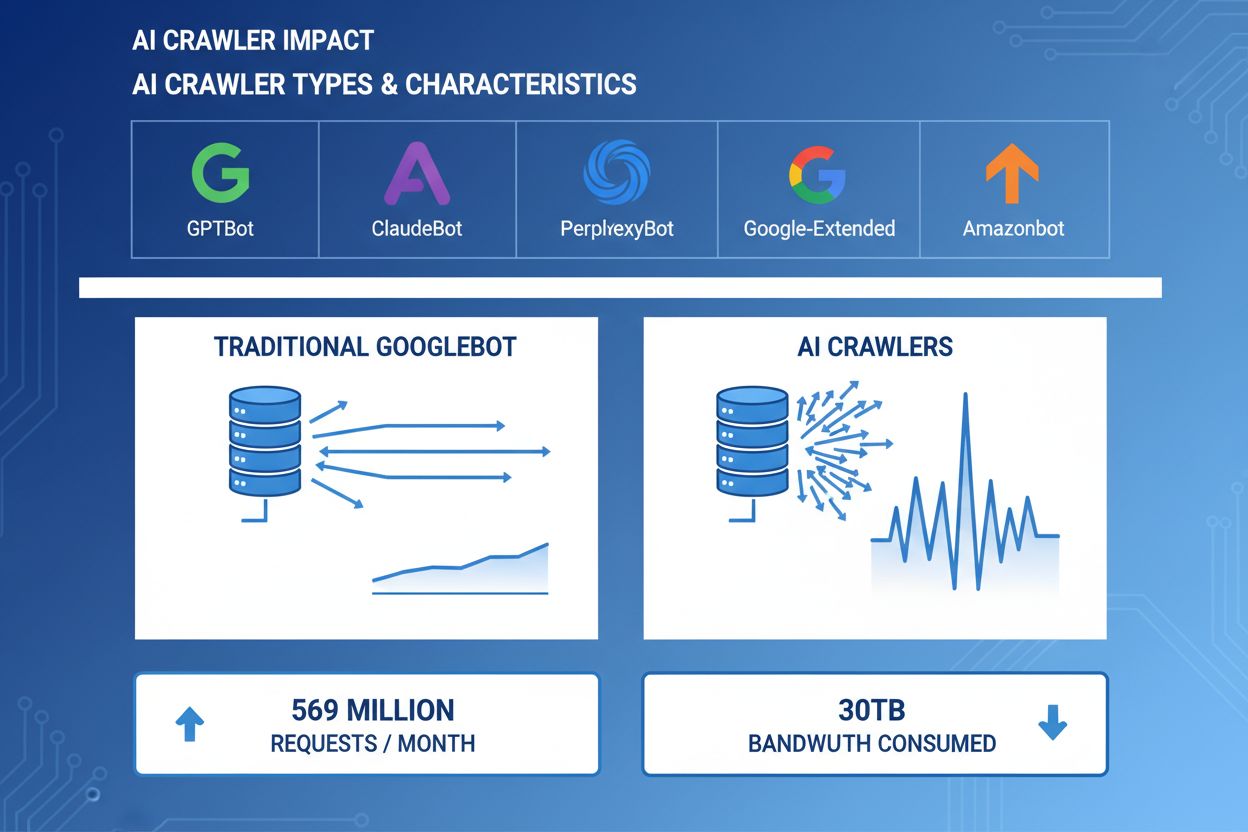
AI crawlery sa stali významnou súčasťou webovej návštevnosti – hlavné AI spoločnosti nasadzujú sofistikované boty na indexovanie obsahu pre trénovanie a vyhľadávanie. Tieto crawlery pracujú vo veľkom rozsahu a generujú približne 569 miliónov požiadaviek mesačne na webe a spotrebujú viac ako 30TB šírky pásma globálne. Medzi hlavné AI crawlery patria GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity AI), Google-Extended (Google) a Amazonbot (Amazon), pričom každý má jedinečné vzory prehľadávania aj nároky na zdroje. Pochopenie správania a vlastností týchto crawlerov je pre správcov webov kľúčové na správne riadenie serverových zdrojov a prijímanie informovaných rozhodnutí o prístupových politikách.
Názov crawlera
Spoločnosť
Účel
Vzor požiadaviek
GPTBot
OpenAI
Trénovacie dáta pre ChatGPT a GPT modely
Agresívne, vysoká frekvencia požiadaviek
ClaudeBot
Anthropic
Trénovacie dáta pre modely Claude AI
Stredná frekvencia, rešpektujúci crawling
PerplexityBot
Perplexity AI
Vyhľadávanie v reálnom čase a generovanie odpovedí
Stredná až vysoká frekvencia
Google-Extended
Google
Rozšírené indexovanie pre AI funkcie
Kontrolované, rešpektuje robots.txt
Amazonbot
Amazon
Indexovanie produktov a obsahu
Premenlivé, zamerané na e-commerce
Metriky spotreby serverových zdrojov
AI crawlery spotrebúvajú serverové zdroje v rôznych oblastiach a merateľne ovplyvňujú výkon infraštruktúry. Využitie CPU môže počas špičky crawlerov vyskočiť o 300 % a viac, keď servery spracovávajú tisíce súbežných požiadaviek a analyzujú HTML obsah. Spotreba šírky pásma patrí medzi najviditeľnejšie náklady – populárny web môže denne poskytnúť crawlerom gigabajty dát. Výrazne rastie aj spotreba pamäte, keď servery udržiavajú spojenia a buffrujú veľké množstvá dát na spracovanie. Dopyty do databázy sa násobia, keď crawlery požadujú stránky spúšťajúce dynamickú generáciu obsahu, čo vytvára ďalší tlak na I/O. Diskové operácie sa môžu stať úzkym miestom, keď servery musia načítať obsah z úložiska pre požiadavky crawlerov, najmä pri veľkých obsahových knižniciach.
Zdroj
Vplyv
Reálny príklad
CPU
Špičky 200-300 % počas crawlovania
Priemerná záťaž servera stúpne z 2.0 na 8.0
Šírka pásma
15-40 % celkovej mesačnej spotreby
500GB web poskytne crawlerom 150GB mesačne
Pamäť
20-30 % nárast spotreby RAM
8GB server potrebuje pri crawleroch 10GB
Databáza
2-5x zvýšenie dopytov
Odozva dotazu stúpne zo 50ms na 250ms
Diskové I/O
Trvalé vysoké čítania
Využitie disku z 30 % na 85 %
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
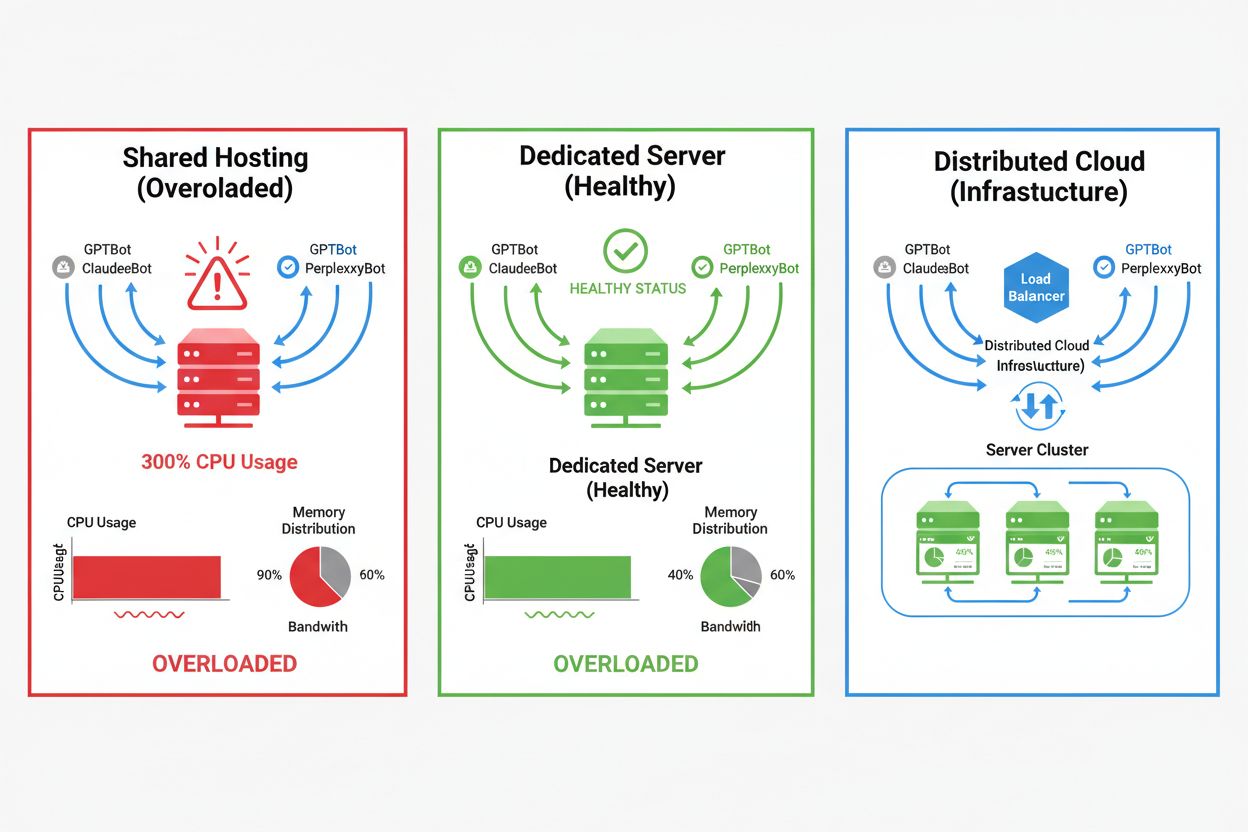
Dopad AI crawlerov sa výrazne líši podľa vášho hostingového prostredia. Najvýraznejšie dôsledky má zdieľaný hosting, kde sa prejavuje „syndróm hlučného suseda“ – ak jeden web na zdieľanom serveri pritiahne veľkú návštevnosť crawlerov, spotrebuje zdroje, ktoré by inak slúžili ostatným stránkam, a zhorší výkon pre všetkých. Dedikované servery a cloudová infraštruktúra ponúkajú lepšiu izoláciu a garanciu zdrojov, takže zvládnete crawlerov bez dopadov na iné služby. Aj tak však vyžadujú dôkladné monitorovanie a škálovanie, ak má na serveri paralelne pracovať viac AI crawlerov.
Kľúčové rozdiely medzi hostingovými prostrediami:
Zdieľaný hosting: Obmedzené zdroje, žiadna izolácia, návštevnosť crawlerov priamo ovplyvňuje iné stránky, minimálna kontrola nad prístupom crawlerov
VPS/Cloud: Vyčlenené zdroje, lepšia izolácia, škálovateľná kapacita, detailná kontrola nad správou návštevnosti
Dedikovaný server: Plné vyhradenie zdrojov, úplná kontrola, najvyššie náklady, vyžaduje manuálne škálovanie
CDN + origin: Distribuovaná záťaž, caching na edge, crawleri pohltení na edge, origin server chránený
Dôsledky na šírku pásma a náklady
Finančný dopad AI crawlerov nekončí pri samotných nákladoch na šírku pásma, ale zahŕňa aj priame aj skryté výdavky, ktoré môžu významne zaťažiť váš rozpočet. Priame náklady zahŕňajú zvýšené poplatky za šírku pásma od hostingu, ktoré môžu dosiahnuť stovky až tisíce eur mesačne podľa objemu návštevnosti a intenzity crawlerov. Skryté náklady sa objavujú cez zvýšené požiadavky na infraštruktúru – možno budete musieť prejsť na vyšší hostingový balík, implementovať ďalšie caching vrstvy či investovať do CDN špeciálne kvôli crawlerom. Výpočet ROI je zložitý, pretože AI crawlery prinášajú vašej firme minimálnu priamu hodnotu, no spotrebúvajú zdroje, ktoré by mohli slúžiť platiacim zákazníkom alebo zlepšovať užívateľskú skúsenosť. Mnohí majitelia webov zistia, že náklady na akomodáciu crawlerov prevyšujú akékoľvek potenciálne prínosy z trénovania AI modelov alebo zobrazenia vo výsledkoch AI vyhľadávačov.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Dopad na výkon a užívateľskú skúsenosť
AI crawlery priamo zhoršujú užívateľskú skúsenosť legitímnych návštevníkov tým, že spotrebúvajú serverové zdroje, ktoré by inak obsluhovali ľudí rýchlejšie. Metriky Core Web Vitals sa merateľne zhoršujú – Largest Contentful Paint (LCP) sa predĺži o 200-500 ms, Time to First Byte (TTFB) sa zhorší o 100-300 ms počas špičky crawlerov. Tieto výkonnostné degradácie spúšťajú lavínu ďalších negatívnych efektov: pomalšie načítanie znižuje angažovanosť, zvyšuje bounce rate a znižuje konverzie na e-shopoch či lead-gen stránkach. Trpia aj pozície vo vyhľadávačoch, keďže Google zohľadňuje Core Web Vitals ako faktor hodnotenia, čím vzniká bludný kruh, kde crawleri nepriamo škodia vášmu SEO. Návštevníci zažívajúci pomalé načítanie stránok odchádzajú ku konkurencii, čo priamo ovplyvňuje tržby i vnímanie značky.
Stratégie monitorovania a detekcie
Efektívne zvládanie AI crawlerov začína dôkladným monitorovaním a detekciou, ktoré vám umožnia pochopiť rozsah problému ešte pred zavedením riešení. Väčšina webových serverov zaznamenáva user-agent reťazce, ktoré identifikujú crawlera pri každej požiadavke – to je základ pre analýzu návštevnosti a rozhodovanie o filtrovaní. Serverové logy, analytické platformy a špecializované monitorovacie nástroje dokážu tieto reťazce analyzovať a určiť vzory crawlerov.
Kľúčové metódy a nástroje detekcie:
Analýza logov: Prehľadávajte serverové logy po user-agent reťazcoch (GPTBot, ClaudeBot, Google-Extended, CCBot) na identifikáciu požiadaviek crawlerov
Analytické platformy: Google Analytics, Matomo a podobné dokážu segmentovať návštevnosť crawlerov zvlášť od ľudských používateľov
Monitoring v reálnom čase: Nástroje ako New Relic a Datadog poskytujú živý prehľad o aktivite crawlerov a spotrebe zdrojov
DNS reverse lookup: Overte IP adresy crawlerov podľa zverejnených IP rozsahov od OpenAI, Anthropic a ďalších AI firiem
Behaviorálna analýza: Identifikujte podozrivé vzory ako rýchle sekvenčné požiadavky, nezvyčajné kombinácie user-agentov alebo požiadavky na citlivé oblasti
Stratégie zmiernenia – robots.txt a rate limiting
Prvou líniou obrany pred nadmernou návštevnosťou AI crawlerov je dobre nastavený súbor robots.txt, ktorý explicitne riadi prístup crawlerov na váš web. Tento jednoduchý textový súbor umiestnite do koreňového adresára webu – môžete v ňom zakázať konkrétnych crawlerov, obmedziť frekvenciu prehľadávania alebo nasmerovať crawlery len na sitemap s obsahom určeným na indexáciu. Rate limiting na aplikačnej či serverovej vrstve pridáva ďalšiu ochranu – obmedzuje požiadavky zo špecifických IP alebo user-agentov, čím predchádza vyčerpaniu zdrojov. Tieto stratégie nie sú blokujúce a sú ľahko vratné, preto sú ideálnym východiskom pred agresívnejšími opatreniami.
Web Application Firewally (WAF) a Content Delivery Networks (CDN) ponúkajú pokročilú, podnikovo orientovanú ochranu pred neželanou návštevnosťou crawlerov cez behaviorálnu analýzu a inteligentné filtrovanie. Cloudflare a podobní CDN poskytovatelia majú vstavané nástroje na správu botov, ktoré dokážu na základe správania, reputácie IP a charakteristík požiadaviek automaticky identifikovať a blokovať AI crawlery bez manuálneho nastavovania. WAF pravidlá môžu vyžadovať overenie, limitovať rýchlosť konkrétnych user-agentov alebo úplne blokovať známe IP rozsahy crawlerov. Tieto riešenia fungujú na edge úrovni – filtrovaním škodlivej návštevnosti ešte pred príchodom na váš server dramaticky znižujú záťaž infraštruktúry. Výhodou WAF a CDN riešení je schopnosť adaptovať sa na nové crawlery a meniace sa vzory útokov bez nutnosti ručnej úpravy konfigurácie.
Rovnováha medzi viditeľnosťou a ochranou
Rozhodnutie, či blokovať AI crawlery, si vyžaduje zváženie kompromisov medzi ochranou serverových zdrojov a zachovaním viditeľnosti vo výsledkoch AI vyhľadávania a aplikáciách. Blokovanie všetkých AI crawlerov vylučuje možnosť, že sa váš obsah objaví vo výsledkoch vyhľadávania ChatGPT, odpovediach Perplexity AI či iných AI-powered nástrojoch, čo môže znížiť referral návštevnosť a viditeľnosť značky. Naopak, neobmedzený prístup crawlerov znamená vysoké náklady a zhoršenie užívateľskej skúsenosti bez merateľných prínosov pre váš biznis. Optimálna stratégia závisí od vašej situácie: veľké weby s dostatkom zdrojov môžu crawlery povoliť, zatiaľ čo stránky s limitovanými kapacitami by mali uprednostniť užívateľskú skúsenosť a crawlerov blokovať alebo obmedzovať. Rozhodnutie by malo vychádzať z vášho odvetvia, cieľovej skupiny, typu obsahu a obchodných cieľov, nie podľa jednotnej schémy.
Riešenia na škálovanie infraštruktúry
Pre weby, ktoré sa rozhodnú akceptovať návštevnosť od AI crawlerov, ponúka škálovanie infraštruktúry cestu, ako udržať výkon i pri zvýšenej záťaži. Vertikálne škálovanie – upgrade serverov s väčším CPU, RAM a šírkou pásma – je priame, ale drahé riešenie, ktoré narazí na fyzické limity. Horizontálne škálovanie – rozloženie návštevnosti na viac serverov cez load balancer – poskytuje lepšiu dlhodobú škálovateľnosť a odolnosť. Cloudové platformy ako AWS, Google Cloud a Azure umožňujú automatické škálovanie podľa záťaže, čím dynamicky pridávajú či uberajú zdroje a minimalizujú náklady. CDN siete dokážu cachovať statický obsah na edge uzloch, čím odľahčia váš origin server a zlepšia výkon pre ľudí aj crawlery. Optimalizácia databázy, cachovanie dotazov a úpravy na úrovni aplikácie môžu znížiť spotrebu zdrojov na jednu požiadavku a zvýšiť efektivitu bez ďalšieho hardvéru.
Nástroje monitorovania a najlepšie postupy
Dlhodobé monitorovanie a optimalizácia sú nevyhnutné na udržanie optimálneho výkonu aj pri neustálej návštevnosti AI crawlerov. Špecializované nástroje poskytujú prehľad o aktivite crawlerov, spotrebe zdrojov a výkonnostných metrikách, čo vám umožní robiť rozhodnutia na základe dát. Zavedením komplexného monitoringu už od začiatku si vytvoríte základ pre sledovanie trendov a meranie efektivity zavedených opatrení v čase.
Kľúčové nástroje a postupy monitorovania:
Monitoring servera: New Relic, Datadog alebo Prometheus na živé sledovanie CPU, pamäte či diskového I/O
Analýza logov: ELK Stack, Splunk alebo Graylog na parsing serverových logov a identifikáciu vzorov crawlerov
Špecializované riešenia: AmICited.com ponúka detailný monitoring AI crawlerov a prehľad, aké AI modely pristupujú k vášmu obsahu
Sledovanie výkonu: Google PageSpeed Insights, WebPageTest a monitoring Core Web Vitals na meranie dopadu na užívateľskú skúsenosť
Alertovanie: Nastavte si upozornenia na špičky v spotrebe zdrojov, nezvyčajné vzory návštevnosti a zhoršenie výkonu, aby ste mohli rýchlo reagovať
Dlhodobá stratégia a budúci vývoj
Oblasť riadenia AI crawlerov sa neustále vyvíja – nové štandardy a iniciatívy formujú interakciu medzi webmi a AI spoločnosťami. Štandard llms.txt predstavuje nový spôsob poskytovania štruktúrovaných informácií AI firmám o právach a preferenciách využitia obsahu, čo môže byť jemnejšou alternatívou k úplnému blokovaniu či povoľovaniu. Diskutuje sa aj o modeloch kompenzácie – AI firmy by v budúcnosti mohli platiť za prístup k trénovacím dátam, čo zásadne zmení ekonomiku návštevnosti crawlerov. Ak chcete byť pripravení, sledujte vývoj štandardov, monitorujte trendy v odvetví a udržujte flexibilitu v politike riadenia crawlerov. Budujte vzťahy s AI spoločnosťami, zapájajte sa do diskusií a presadzujte férové modely kompenzácie – to bude čoraz dôležitejšie, ako sa AI stáva ústrednou pre objavovanie a konzumáciu webového obsahu. Uspieť v tomto svete dokážu tie weby, ktoré spoja inováciu s pragmatizmom: ochránia si zdroje, no zároveň ostanú otvorené legitímnym príležitostiam na viditeľnosť a partnerstvá.
Najčastejšie kladené otázky
Aký je rozdiel medzi AI crawlermi a prehliadačmi vyhľadávačov?
AI crawlery (GPTBot, ClaudeBot) získavajú obsah na trénovanie LLM bez toho, aby nutne smerovali návštevnosť späť. Prehľadávače vyhľadávačov (Googlebot) indexujú obsah pre vyhľadávateľnosť a zvyčajne prinášajú referenčnú návštevnosť. AI crawlery fungujú agresívnejšie, s väčšími dávkami požiadaviek a často ignorujú pokyny na šetrenie šírky pásma.
Koľko šírky pásma môžu AI crawlery spotrebovať?
Reálne príklady ukazujú viac ako 30TB mesačne od jedného crawlera. Spotreba závisí od veľkosti stránky, objemu obsahu a frekvencie crawlera. Samotný GPTBot od OpenAI generoval 569 miliónov požiadaviek za jediný mesiac v sieti Vercel.
Uškodí blokovanie AI crawlerov môjmu SEO?
Blokovanie crawlerov na trénovanie AI (GPTBot, ClaudeBot) neovplyvní pozície na Google. Avšak blokovanie AI vyhľadávacích crawlerov môže znížiť viditeľnosť vo vyhľadávaní poháňanom AI, ako je Perplexity či ChatGPT search.
Aké sú príznaky, že môj server je preťažený crawlermi?
Sledujte nevysvetliteľné špičky CPU (300 %+), zvýšené využitie šírky pásma bez rastu ľudskej návštevnosti, pomalšie načítanie stránok a nezvyčajné user-agent reťazce v serverových logoch. Výrazne sa môžu zhoršiť aj metriky Core Web Vitals.
Oplatí sa pre správu crawlerov prejsť na dedikovaný hosting?
Pre stránky s výraznou návštevnosťou od crawlerov poskytuje dedikovaný hosting lepšiu izoláciu zdrojov, kontrolu a predvídateľnosť nákladov. Zdieľané prostredie trpí 'syndrómom hlučného suseda', kde návštevnosť jedného crawlera ovplyvní všetky hostované stránky.
Aké nástroje mám použiť na monitorovanie aktivity AI crawlerov?
Použite Google Search Console na dáta o Googlebotovi, serverové prístupové logy na detailnú analýzu, analytiku CDN (Cloudflare) a špecializované platformy ako AmICited.com na komplexné monitorovanie a sledovanie AI crawlerov.
Môžem selektívne povoliť niektoré crawlery a iné blokovať?
Áno, pomocou direktív v robots.txt, pravidiel WAF a filtrovania podľa IP. Môžete povoliť užitočných crawlerov ako Googlebot a zároveň blokovať náročné crawlery na trénovanie AI pomocou pravidiel pre konkrétnych user-agentov.
Ako zistím, či AI crawlery ovplyvňujú výkon mojej stránky?
Porovnajte serverové metriky pred a po zavedení kontrol pre crawlery. Sledujte Core Web Vitals (LCP, TTFB), časy načítania stránok, využitie CPU a metriky používateľskej skúsenosti. Nástroje ako Google PageSpeed Insights a serverové monitorovacie platformy ponúkajú detailný prehľad.
Monitorujte vplyv AI crawlerov ešte dnes
Získajte prehľad v reálnom čase o tom, ako AI modely pristupujú k vášmu obsahu a ovplyvňujú serverové zdroje vďaka špecializovanej monitorovacej platforme AmICited.
Ktorým AI crawlerom by ste mali povoliť prístup? Kompletný sprievodca pre rok 2025
Zistite, ktorým AI crawlerom povoliť alebo zablokovať prístup vo vašom robots.txt. Komplexný sprievodca pokrývajúci GPTBot, ClaudeBot, PerplexityBot a ďalších 2...
Ako identifikovať AI crawlerov v serverových logoch: Kompletný sprievodca detekciou
Zistite, ako identifikovať a monitorovať AI crawlery ako GPTBot, PerplexityBot a ClaudeBot vo vašich serverových logoch. Objavte user-agent reťazce, metódy over...
Zistite, ako spravovať prístup AI crawlerov k obsahu vašej webovej stránky. Pochopte rozdiel medzi trénovacími a vyhľadávacími crawlermi, implementujte pravidlá...
7 min čítania
Súhlas s cookies Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.