Prečo ChatGPT miluje Reddit: Pochopenie preferencií zdrojov
Zistite, prečo Reddit dominuje citáciám ChatGPT so 40,1 % všetkých AI odpovedí. Spoznajte, ako fungujú preferencie AI zdrojov a čo to znamená pre viditeľnosť va...
10 min čítania

Zistite, odkiaľ ChatGPT získava svoje tréningové dáta, ako cituje zdroje, dátumy ohraničenia znalostí a prečo je dôležité sledovať AI citácie pre vašu značku.
Znalostná báza ChatGPT je postavená na rozmanitej zbierke verejne dostupných internetových dát, skombinovaných s licencovanými datasetmi a spätno-väzbovým doladením od ľudí. Model bol trénovaný na troch hlavných zdrojoch: verejne dostupné internetové dáta (webstránky, články a online obsah), licencované datasety (vrátane kníh a akademických publikácií) a ľudská spätná väzba od trénerov, ktorí pomáhali doladiť odpovede. Tieto tréningové dáta zahŕňajú mimoriadne široké spektrum zdrojov vrátane spravodajských webstránok, vedeckých časopisov, kníh, technickej dokumentácie, fór ako Reddit a Stack Overflow, článkov z Wikipédie a nespočetných ďalších verejne dostupných stránok. Samotný objem a rozmanitosť týchto zdrojov—naprieč viacerými jazykmi, doménami a pohľadmi—vytvára komplexnú znalostnú bázu, ktorá ChatGPT umožňuje diskutovať o témach od kvantovej fyziky cez stredoveké dejiny až po súčasnú popkultúru. Je však dôležité pochopiť, že ChatGPT nemá prístup k informáciám v reálnom čase ani k proprietárnym databázam; môže čerpať len z toho, čo bolo dostupné počas jeho tréningového obdobia.
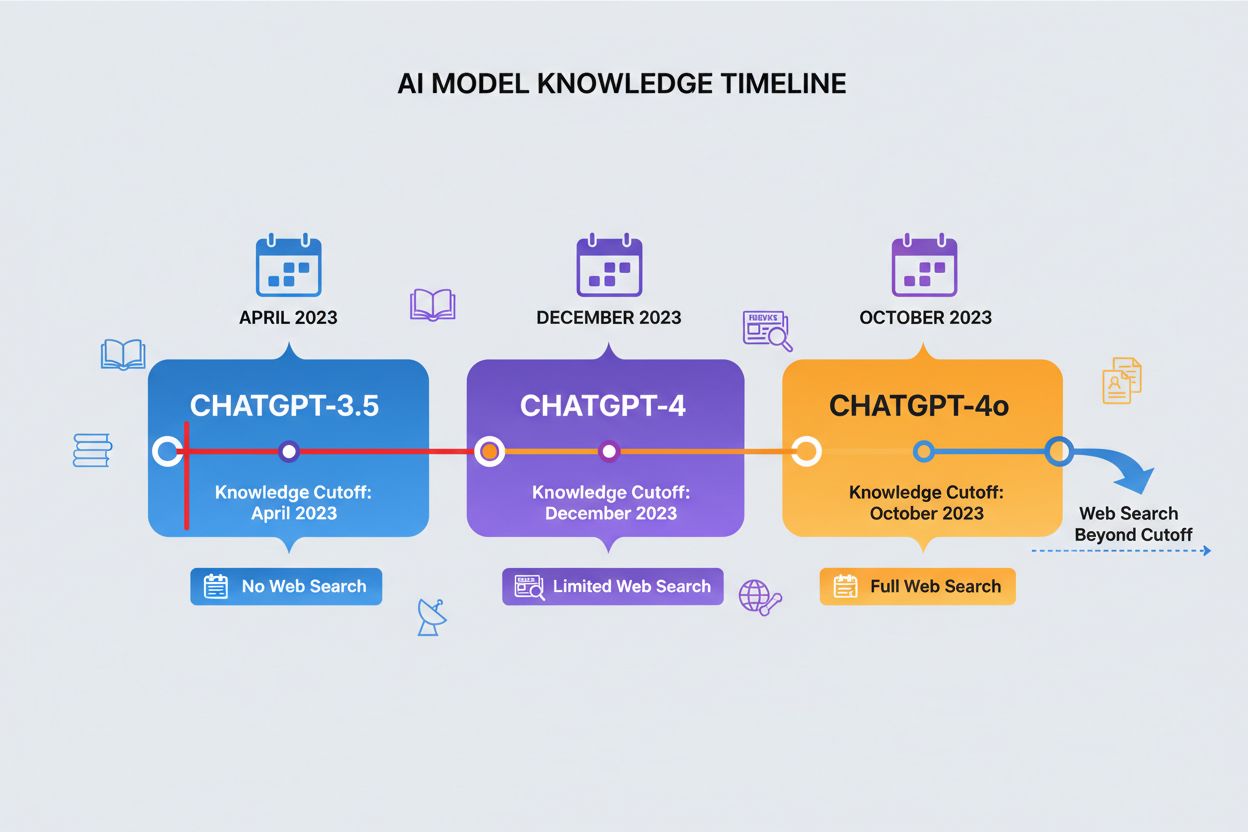
Dátum ohraničenia znalostí predstavuje časový bod, po ktorom už ChatGPT nemá žiadne tréningové dáta, čím vytvára jasnú hranicu pre informácie, ku ktorým má prístup. Rôzne verzie ChatGPT majú rôzne dátumy ohraničenia: ChatGPT-4 bol trénovaný na dátach do decembra 2023, zatiaľ čo ChatGPT-4o (optimalizovaná verzia) má ohraničenie v októbri 2023. Tieto dátumy výrazne ovplyvňujú presnosť a relevantnosť odpovedí, najmä pri nedávnych udalostiach, novo publikovanom výskume alebo aktuálnych štatistikách, ktoré sa mohli od zberu tréningových dát zmeniť. Niektoré novšie verzie ChatGPT dokážu vykonávať webové vyhľadávania na získanie aktuálnych informácií nad rámec svojho dátumu ohraničenia, no táto funkcia nie je dostupná vo všetkých verziách či kontextoch. Poznať dátum ohraničenia svojho modelu je kľúčové pre používateľov, ktorí potrebujú aktuálne informácie, pretože ChatGPT nevie poskytnúť presné odpovede o udalostiach či vývoji, ktoré nastali po skončení jeho tréningového obdobia. Toto obmedzenie je jedným z najdôležitejších faktorov pri hodnotení spoľahlivosti ChatGPT pre časovo citlivé otázky.
| Verzia ChatGPT | Dátum ohraničenia znalostí | Schopnosť webového vyhľadávania | Hlavné použitie |
|---|---|---|---|
| ChatGPT-4 | December 2023 | Obmedzené | Všeobecné znalosti, analýza, uvažovanie |
| ChatGPT-4o | Október 2023 | Dostupné | Optimalizovaný výkon, multimodálne úlohy |
| ChatGPT-3.5 | Apríl 2023 | Nie | Základné otázky, úsporná možnosť |
| ChatGPT s prehliadaním | Reálny čas | Áno | Aktuálne udalosti, najnovší výskum |
Na rozdiel od vyhľadávačov, ktoré vyhľadávajú konkrétne dokumenty alebo webstránky v reakcii na dopyty, ChatGPT generuje odpovede syntetizovaním vzorov naučených počas tréningu—čo je zásadne odlišný proces. Keď sa ChatGPT opýtate otázku, nevyhľadáva v databáze alebo indexe; namiesto toho používa štatistické vzory zo svojich tréningových dát na predikciu najpravdepodobnejšej sekvencie slov, ktorá by tvorila užitočnú odpoveď. Tento prístup založený na generovaní znamená, že ChatGPT kombinuje informácie z viacerých zdrojov v tréningových dátach na vytvorenie nových odpovedí, ktoré sa nemusia doslovne nikde v zdrojoch vyskytovať. Model sa v podstate učí vzťahy medzi pojmami, faktami a ideami a potom túto znalosť rekonštruuje v reakcii na vašu konkrétnu otázku. Tento proces má však zásadnú nevýhodu: ak si model nie je istý informáciami alebo keď sú vzory v tréningových dátach protichodné či riedke, môže generovať dôveryhodne znejúce, ale nepravdivé informácie, čo sa nazýva “halucinácia”. Novšie verzie ChatGPT, ktoré integrujú funkciu webového vyhľadávania, môžu tento proces doplniť získavaním aktuálnych informácií z internetu, no táto funkcia si vyžaduje explicitné zapnutie a nie je dostupná na všetkých platformách.
Tréningové dáta ChatGPT čerpajú z viacerých hlavných kategórií zdrojov, pričom každá prináša do jeho znalostnej bázy jedinečnú hodnotu:
Význam týchto rozmanitých zdrojov spočíva v ich vzájomne sa dopĺňajúcich silných stránkach: vedecké články dávajú dôslednosť, spravodajské články aktuálnosť, knihy hĺbku a fóra praktické využitie. Kvalita zdrojov sa však značne líši—recenzovaný vedecký článok má väčšiu váhu než náhodný blog, no tréningový proces ChatGPT ich explicitne nerozlišuje. To znamená, že znalosti ChatGPT odrážajú zároveň kvalitné autoritatívne zdroje aj menej kvalitný či potenciálne zavádzajúci obsah, a preto je overovanie nevyhnutné pri použití modelu na dôležité rozhodnutia.
Po počiatočnom tréningu na obrovskom množstve textových dát využila spoločnosť OpenAI techniku zvanú posilňované učenie s ľudskou spätnou väzbou (RLHF) na doladenie odpovedí ChatGPT. V tomto procese ľudskí tréneri hodnotili výstupy modelu a poskytovali spätnú väzbu, čím systém naučili, ktoré odpovede sú užitočnejšie, presnejšie a viac v súlade s ľudskými hodnotami. Títo tréneri nekontrolovali pravdivosť každého tvrdenia; hodnotili celkovú kvalitu, užitočnosť a bezpečnosť odpovedí, čo nepriamo ovplyvňuje, ako model informácie uprednostňuje a prezentuje. Proces RLHF významne ovplyvňuje, ktoré informácie sa v odpovediach zdôrazňujú a ako sú jednotlivé témy formulované, čím do čisto štatistického modelu vstupuje ľudský úsudok. Tento proces však má svoje limity: tréneri majú vlastné zaujatosti, znalostné medzery a obmedzenia a nemôžu hodnotiť presnosť každého tvrdenia naprieč všetkými odbormi. Navyše, spätná väzba je zdrojovo náročná a dá sa aplikovať len na zlomok možných výstupov modelu, takže veľká časť správania ChatGPT stále odráža surové vzory v tréningových dátach a nie explicitnú ľudskú kuratelu.
Citovanie ChatGPT je dôležité pre akademickú integritu a transparentnosť, aby čitatelia pochopili, odkiaľ informácie pochádzajú a mohli vaše zistenia prípadne overiť alebo zopakovať. Formát citácie závisí od požadovaného štýlu, tu sú najbežnejšie prístupy:
Príklad formátu MLA:
OpenAI. "ChatGPT." Accessed [Dátum], https://chat.openai.com.
V MLA štýle citujete ChatGPT ako webstránku, vrátane dátumu prístupu, keďže obsah je dynamický a môže sa meniť. Ak citujete konkrétnu odpoveď, mali by ste uviesť dátum prístupu a ideálne aj prompt alebo otázku, ktorú ste položili.
Príklad formátu APA:
OpenAI. (2024). ChatGPT (Version 4) [Large language model].
Retrieved from https://chat.openai.com
APA štýl považuje ChatGPT za softvérový nástroj alebo aplikáciu, uvádza číslo verzie a dátum získania. Niektoré pokyny APA odporúčajú pridať aj konkrétny prompt do citácie alebo ako doplnkovú poznámku.
Kedy citovať ChatGPT: Nástroj by ste mali citovať vždy, keď použijete jeho výstup vo vedeckej práci, odborných správach alebo v akomkoľvek kontexte, kde je dôležité uvádzanie zdrojov. Zdokumentujte presný prompt, ktorý ste použili, dátum prístupu a ideálne aj verziu ChatGPT, keďže tieto údaje ovplyvňujú opakovateľnosť výsledkov. Kľúčový rozdiel oproti citovaniu tradičných zdrojov je v tom, že odpovede ChatGPT sú generované dynamicky—ten istý prompt môže v rôznych prípadoch priniesť mierne odlišné výstupy—preto je súčasťou správnej citácie aj samotný prompt. Mnohé inštitúcie ešte len vyvíjajú formálne pokyny pre citovanie AI, preto sa informujte o preferovanom formáte vašej organizácie alebo publikácie.
Napriek mimoriadnym schopnostiam má ChatGPT významné obmedzenia, ktoré ovplyvňujú spoľahlivosť jeho informácií. ChatGPT môže s istotou uvádzať nepravdivé informácie, čo je problém známy ako halucinácia, najmä pri otázkach na neznáme témy, aktuálne udalosti po dátume ohraničenia alebo pri protichodných informáciách v jeho tréningových dátach. Tréningové dáta modelu obsahujú inherentné zaujatosti odrážajúce perspektívy, demografiu a pohľady prítomné v zdrojových materiáloch, čo znamená, že odpovede môžu nevedomky uprednostňovať určité názory alebo obsahovať stereotypy. Informácie v tréningových dátach ChatGPT postupne zastarávajú časom, čo ho robí nespoľahlivým pre aktuálne štatistiky, najnovšie vedecké poznatky či vyvíjajúce sa situácie. Preto je overovanie tvrdení ChatGPT nevyhnutné, najmä pri dôležitých rozhodnutiach—kľúčové fakty overujte v primárnych zdrojoch, najnovších publikáciách a autoritatívnych databázach. Na overenie tvrdení ChatGPT porovnajte jeho odpovede s viacerými nezávislými zdrojmi, porovnajte dátumy a štatistiky s aktuálnymi údajmi a buďte obzvlášť opatrní pri konkrétnych číslach, menách či nedávnych udalostiach. Nakoniec, nezabúdajte, že ChatGPT nie je primárnym zdrojom; je sekundárnym zdrojom, ktorý syntetizuje informácie z iných zdrojov, takže pri vedeckej či odbornej práci by ste mali citovať originálne zdroje, na ktoré ChatGPT odkazuje, nie ChatGPT samotný.
S rastúcou integráciou ChatGPT a iných AI systémov do spôsobov, akými ľudia objavujú informácie, sa monitorovanie toho, ako tieto systémy citujú a odkazujú na vašu značku alebo organizáciu, stalo kľúčovým. AmICited je platforma na monitorovanie AI odpovedí navrhnutá špeciálne na sledovanie toho, ako ChatGPT, Claude a ďalšie veľké jazykové modely spomínajú, citujú alebo odkazujú na vašu spoločnosť, produkty či značku vo svojich odpovediach. Platforma vám pomáha pochopiť, kedy a ako sa vaša značka objavuje v AI-generovaných odpovediach, čím poskytuje prehľad o novom a rastúcom kanáli objavovania informácií, ktorý tradičné nástroje na monitorovanie webu často prehliadajú. Táto monitorovacia schopnosť je zásadná, pretože AI citácie fungujú inak ako tradičné webové citácie—sú zabudované v konverzačných odpovediach, s ktorými denne interagujú milióny používateľov, no väčšina značiek nemá prehľad o tom, ako sú reprezentované. Vďaka AmICited získate prehľad o vnímaní značky v AI systémoch, môžete identifikovať nepresnosti alebo zastarané informácie, ktoré treba opraviť, a pochopiť, ako si vaša značka stojí oproti konkurencii v AI-generovaných odpovediach. V ére, keď sa AI systémy stávajú pre mnohých používateľov primárnym zdrojom informácií, je monitorovanie vašej prítomnosti v týchto systémoch rovnako dôležité ako sledovanie tradičných výsledkov vyhľadávania, vďaka čomu sú nástroje ako AmICited nevyhnutné pre moderný manažment značky a transparentnosť AI.
ChatGPT bol trénovaný na troch hlavných zdrojoch: verejne dostupné internetové dáta (webstránky, články, fóra), licencované datasety (knihy a akademické publikácie) a spätná väzba od ľudských trénerov. Tréningové dáta zahŕňajú spravodajské webstránky, vedecké časopisy, technickú dokumentáciu, Wikipédiu, Reddit, Stack Overflow a nespočetné ďalšie verejne prístupné stránky zozbierané do dátumu ohraničenia znalostí.
Dátum ohraničenia znalostí je časový bod, po ktorom už ChatGPT nemá žiadne tréningové dáta. ChatGPT-4 má ohraničenie v decembri 2023, zatiaľ čo ChatGPT-4o má október 2023. Je to dôležité, pretože ChatGPT nemôže poskytovať presné informácie o udalostiach, výskume alebo vývoji, ktoré nastali po skončení jeho tréningového obdobia, čím sa stáva nespoľahlivým pre časovo citlivé otázky.
ChatGPT nemôže pristupovať k informáciám v reálnom čase len zo svojich tréningových dát. Novšie verzie ChatGPT však dokážu vykonávať webové vyhľadávania na získanie aktuálnych informácií nad rámec svojho dátumu ohraničenia znalostí, no táto funkcia nie je dostupná vo všetkých verziách alebo kontextoch a vyžaduje explicitné zapnutie.
V MLA formáte citujte ChatGPT ako webstránku s dátumom prístupu. V APA formáte ho považujte za softvér a uveďte číslo verzie. Oba formáty vyžadujú zdokumentovať presný prompt, ktorý ste použili, dátum prístupu a ideálne aj verziu ChatGPT, keďže ten istý prompt môže priniesť odlišné výstupy pri rôznych príležitostiach.
Nie. ChatGPT môže s istotou uvádzať nepravdivé informácie (halucinácie), najmä pri neznámych témach, aktuálnych udalostiach po dátume ohraničenia alebo protichodných informáciách. Jeho tréningové dáta obsahujú inherentné zaujatosti a informácie sa časom stávajú zastaranými. Vždy si overte dôležité tvrdenia v primárnych zdrojoch a autoritatívnych databázach.
Tréningové dáta ChatGPT sa neaktualizujú priebežne. Nové verzie vychádzajú periodicky s aktualizovaným dátumom ohraničenia znalostí, no základný model sa v reálnom čase neaktualizuje. OpenAI vydáva nové verzie (ako GPT-4o) s novšími tréningovými dátami, ale presný harmonogram aktualizácií nie je verejne dostupný.
ChatGPT necituje konkrétne zdroje pri jednotlivých tvrdeniach, pretože syntetizuje informácie zo vzorcov v tréningových dátach namiesto vyhľadávania konkrétnych dokumentov. Nemôže vás odkázať na presný zdroj faktu. Pri vedeckej práci by ste si mali tvrdenia ChatGPT overiť a citovať originálne zdroje, ktoré nájdete, nie samotný ChatGPT.
AmICited sleduje, ako ChatGPT, Claude a ďalšie AI systémy spomínajú, citujú alebo odkazujú na vašu značku vo svojich odpovediach. Poskytuje prehľad o tom, ako sa vaša spoločnosť objavuje v AI-generovaných odpovediach, pomáha identifikovať nepresnosti a ukazuje, ako si vaša značka stojí oproti konkurencii v AI systémoch – čo je nevyhnutné pre moderný manažment značky v ére AI.
Sledujte citácie ChatGPT a AI zmienky v reálnom čase pomocou AmICited. Pochopte, ako AI systémy odkazujú na vašu značku a zostaňte v predstihu v objavovaní informácií poháňaných AI.
Zistite, prečo Reddit dominuje citáciám ChatGPT so 40,1 % všetkých AI odpovedí. Spoznajte, ako fungujú preferencie AI zdrojov a čo to znamená pre viditeľnosť va...

Zistite, ako Wikipédia slúži ako kľúčový dataset pre tréning AI, jej vplyv na presnosť modelov, licenčné dohody a prečo sa na ňu AI spoločnosti spoliehajú pri t...
Kompletný sprievodca odhlásením sa zo zberu dát pre AI tréning na ChatGPT, Perplexity, LinkedIn a ďalších platformách. Naučte sa krok za krokom chrániť svoje dá...
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.