Ako identifikovať AI crawlerov vo vašich serverových logoch
Naučte sa identifikovať a monitorovať AI crawlery ako GPTBot, ClaudeBot a PerplexityBot vo vašich serverových logoch. Kompletný sprievodca s user-agent reťazcami, IP overovaním a praktickými stratégiami monitorovania.
Publikované dňa Jan 3, 2026.Naposledy upravené dňa Jan 3, 2026 o 3:24 am
Krajina webovej návštevnosti sa zásadne zmenila s nástupom AI zberu dát, ktorý ďaleko presahuje tradičné indexovanie vyhľadávačmi. Na rozdiel od Googlebotu či crawlera od Bingu, ktoré existujú už desaťročia, AI crawlery dnes predstavujú významnú a rýchlo rastúcu časť serverovej prevádzky—niektoré platformy zaznamenávajú medziročný rast vyše 2 800%. Pochopenie aktivity AI crawlerov je pre vlastníkov webov kľúčové, pretože priamo ovplyvňuje náklady na pásmo, výkon servera, štatistiky využitia dát a najmä vašu možnosť kontrolovať, ako je váš obsah využívaný na trénovanie AI modelov. Bez riadneho monitoringu ste prakticky slepí voči veľkej zmene v tom, ako sú vaše dáta pristupované a využívané.
Typy AI crawlerov a user-agent reťazce
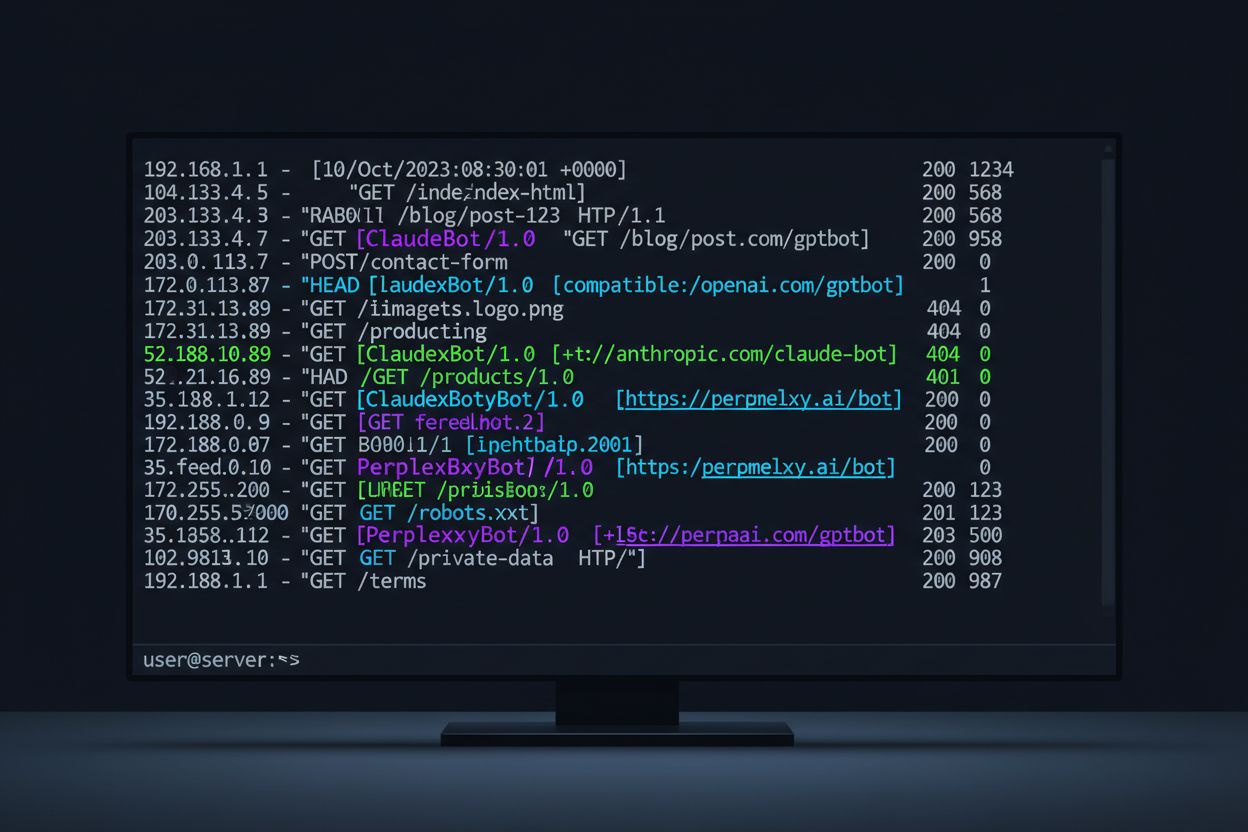
AI crawlery majú mnoho podôb, každá so špecifickým účelom a identifikovateľnými znakmi cez svoje user-agent reťazce. Tieto reťazce sú digitálnymi odtlačkami, ktoré crawlery zanechávajú v serverových logoch, vďaka čomu presne identifikujete, ktoré AI systémy pristupujú k vášmu obsahu. Nižšie je komplexná referenčná tabuľka hlavných AI crawlerov aktuálne aktívnych na webe:
Analýza serverových logov na AI crawlerov vyžaduje systematický prístup a znalosť formátu logov, ktoré váš webový server generuje. Väčšina webov používa Apache alebo Nginx, každý so svojou štruktúrou logov, ale oba sú rovnako účinné na identifikáciu crawlerov. Dôležité je vedieť, kde hľadať a aké vzory vyhľadávať. Tu je príklad záznamu access logu Apache:
Tento príkaz extrahuje user-agent reťazec, filtruje záznamy podobné botom a spočíta výskyt, čím získate jasný prehľad o tom, ktoré crawlery najčastejšie navštevujú vašu stránku.
Overenie IP a autentifikácia
User-agent reťazce je možné sfalšovať, čo znamená, že škodlivý aktér sa môže tváriť ako GPTBot, aj keď je v skutočnosti niekto iný. Preto je overenie IP nevyhnutné na potvrdenie, že prevádzka deklarovaná ako od AI spoločnosti skutočne pochádza z ich infraštruktúry. Môžete vykonať spätné DNS vyhľadávanie IP adresy na overenie vlastníctva:
nslookup 192.0.2.1
Ak reverzné DNS smeruje na doménu patriacu OpenAI, Anthropic alebo inej legitímnej AI spoločnosti, môžete byť s väčšou istotou, že prevádzka je autentická. Kľúčové metódy overovania sú:
Spätné DNS vyhľadávanie: Skontrolujte, či reverzné DNS IP zodpovedá doméne spoločnosti
Overenie IP rozsahu: Porovnajte s publikovanými IP rozsahmi OpenAI, Anthropic a ďalších AI spoločností
WHOIS vyhľadávanie: Overte, či je IP blok registrovaný na deklarovanú organizáciu
Historická analýza: Sledujte, či IP konzistentne pristupuje k vášmu webu s rovnakým user-agentom
Behaviorálne vzory: Legitimne crawlery majú predvídateľné vzory; falošné boty často vykazujú chaotické správanie
Overenie IP je dôležité, pretože vás chráni pred falošnými crawlermi, ktoré môžu byť konkurenciou alebo škodlivými aktérmi snažiacimi sa zahltiť vaše servery pod zámienkou legitímnych AI služieb.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Detekcia AI crawlerov v analytických nástrojoch
Tradičné analytické platformy ako Google Analytics 4 a Matomo sú navrhnuté na filtrovanie botov, čo znamená, že aktivita AI crawlerov je v štandardných analytických paneloch do veľkej miery neviditeľná. To vytvára slepé miesto, kde si neuvedomujete, koľko prevádzky a pásma tieto systémy spotrebujú. Na správne monitorovanie AI crawlerov potrebujete serverové riešenia, ktoré zaznamenávajú surové dáta ešte pred ich filtrovaním:
ELK Stack (Elasticsearch, Logstash, Kibana): Centralizované zhromažďovanie a vizualizácia logov
Splunk: Firemná analýza logov s upozorneniami v reálnom čase
Datadog: Cloudový monitoring s detekciou botov
Grafana + Prometheus: Open-source monitoring pre vlastné dashboardy
AI crawler dáta môžete integrovať aj do Google Data Studio pomocou Measurement Protokolu pre GA4, čo vám umožní vytvárať vlastné reporty zobrazujúce AI prevádzku spolu s vašou bežnou analytikou. Tak získate kompletný prehľad o všetkej prevádzke na vašom webe, nielen o ľudských návštevníkoch.
Praktický workflow analýzy logov
Implementácia praktického workflow pre monitorovanie AI crawlerov vyžaduje stanovenie základných metrík a ich pravidelnú kontrolu. Začnite zberom údajov za jeden týždeň, aby ste pochopili svoje bežné vzory crawlerov, potom nastavte automatizovaný monitoring na detekciu anomálií. Tu je denný kontrolný zoznam:
Skontrolujte celkový počet požiadaviek crawlerov a porovnajte so základom
Identifikujte nové crawlery, ktoré ste predtým nevideli
Sledujte nezvyčajné rýchlosti alebo vzory crawlovania
Overte IP adresy najaktívnejších crawlerov
Monitorujte spotrebu pásma crawlermi
Upozorňujte na crawlery prekračujúce limity
Na automatizáciu dennej analýzy použite tento bash skript:
Tento skript naplánujte na denné spúšťanie cez cron:
09 * * * /usr/local/bin/crawler_analysis.sh
Na vizualizáciu v dashboarde použite Grafana a vytvorte panely zobrazujúce trendy crawler prevádzky v čase, s oddelenými vizualizáciami pre každý významný crawler a upozorneniami na anomálie.
Kontrola prístupu AI crawlerov
Kontrola prístupu AI crawlerov začína pochopením vašich možností a úrovne kontroly, ktorú potrebujete. Niektorí vlastníci webov chcú všetkých AI crawlerov blokovať na ochranu obsahu, iní ich naopak vítajú, ale chcú ich riadiť. Prvou líniou obrany je súbor robots.txt, ktorý crawlerom poskytuje pokyny, čo môžu a nemôžu prechádzať. Tu je príklad použitia:
Avšak robots.txt má značné obmedzenia: je to len odporúčanie, ktoré môžu crawlery ignorovať a škodliví aktéri ho nerešpektujú vôbec. Pre robustnejšiu kontrolu implementujte blokovanie na úrovni firewallu cez iptables alebo bezpečnostné skupiny vášho cloudového poskytovateľa. Môžete blokovať konkrétne IP rozsahy alebo user-agent reťazce na úrovni web servera cez Apache mod_rewrite alebo Nginx if statements. V praxi kombinujte robots.txt pre legitímnych crawlerov s firewall pravidlami pre tých, ktorí ho nerešpektujú, a monitorujte logy na zachytenie porušovateľov.
Pokročilé detekčné techniky
Pokročilé detekčné techniky idú ďalej než len porovnávanie user-agent na identifikáciu sofistikovaných crawlerov a aj sfalšovanej prevádzky. RFC 9421 HTTP Message Signatures poskytujú kryptografickú možnosť, aby crawlery preukázali svoju identitu podpisovaním požiadaviek súkromným kľúčom, čo robí falšovanie prakticky nemožným. Niektoré AI spoločnosti začínajú implementovať Signature-Agent hlavičky, ktoré obsahujú kryptografický dôkaz identity. Okrem podpisov môžete analyzovať behaviorálne vzory, ktoré rozlišujú legitímnych crawlerov od podvodníkov: legitímni crawlery konzistentne vykonávajú JavaScript, dodržiavajú predvídateľné rýchlosti crawlovania, rešpektujú limity a udržiavajú konzistentné IP adresy. Analýza obmedzenia rýchlosti odhalí podozrivé správanie—crawler, ktorý náhle zvýši požiadavky o 500% alebo pristupuje na stránky v náhodnom poradí namiesto podľa štruktúry webu, je pravdepodobne škodlivý. Ako sa agentické AI prehliadače zdokonaľujú, môžu vykazovať ľudské správanie vrátane vykonávania JavaScriptu, spracovania cookies a referrer vzorov, čo si vyžaduje sofistikovanejšie detekčné metódy sledujúce celú signatúru požiadavky, nielen user-agent reťazec.
Stratégia monitorovania v reálnom svete
Komplexná stratégia monitorovania v produkčnom prostredí vyžaduje stanovenie základov, detekciu anomálií a vedenie detailných záznamov. Začnite zberom dvojtýždňových základných dát na pochopenie bežných vzorov crawler prevádzky vrátane špičkových hodín, typického počtu požiadaviek na crawler a spotreby pásma. Nastavte detekciu anomálií, ktorá vás upozorní, ak niektorý crawler prekročí 150% základnej miery alebo ak sa objaví nový crawler. Konfigurujte hranice upozornení ako okamžité hlásenie, ak ktorýkoľvek crawler spotrebuje viac než 30% vášho pásma, alebo ak celková crawler prevádzka presiahne 50% vašej celkovej návštevnosti. Sledujte reportované metriky vrátane celkového počtu požiadaviek crawlerov, spotrebovaného pásma, detegovaných unikátnych crawlerov a zablokovaných žiadostí. Pre organizácie, ktorým záleží na použití ich dát na trénovanie AI, AmICited.com poskytuje doplnkový AI tracking citácií, ktorý ukáže presne, ktoré AI modely citujú váš obsah a dá vám prehľad, ako sú vaše dáta ďalej použité. Túto stratégiu implementujte kombináciou serverových logov, firewall pravidiel a analytických nástrojov, aby ste mali úplný prehľad a kontrolu nad aktivitou AI crawlerov.
Najčastejšie kladené otázky
Aký je rozdiel medzi AI crawlermi a crawlermi vyhľadávačov?
Crawlery vyhľadávačov ako Googlebot indexujú obsah pre výsledky vyhľadávania, zatiaľ čo AI crawlery zbierajú dáta na trénovanie veľkých jazykových modelov alebo poháňajú AI odpovedacie systémy. AI crawlery často prechádzajú web agresívnejšie a môžu pristupovať k obsahu, ktorý vyhľadávače ignorujú, čím tvorí špecifický zdroj návštevnosti vyžadujúci samostatné monitorovanie a riadenie.
Môžu AI crawlery falšovať svoje user-agent reťazce?
Áno, user-agent reťazce je jednoduché sfalšovať, keďže sú len textové hlavičky v HTTP požiadavkách. Preto je overenie IP nevyhnutné—legitímne AI crawlery pochádzajú zo špecifických IP rozsahov patriacich ich spoločnostiam, takže overenie podľa IP je omnoho spoľahlivejšie ako len porovnávanie user-agenta.
Ako zablokujem konkrétny AI crawler na mojej stránke?
Môžete použiť robots.txt na navrhnutie blokovania (hoci crawleri to môžu ignorovať), alebo implementovať blokovanie na úrovni firewallu na serveri cez iptables, Apache mod_rewrite alebo Nginx pravidlá. Pre maximálnu kontrolu kombinujte robots.txt pre legitímnych crawlerov s firewall pravidlami pre tých, ktorí ho nerešpektujú.
Prečo moje analytické nástroje nezobrazujú návštevnosť AI crawlerov?
Google Analytics 4, Matomo a podobné platformy sú navrhnuté tak, aby filtrovali botov, takže AI crawlery sú v štandardných prehľadoch neviditeľné. Na zachytenie surových dát z logov a zobrazenie kompletnej aktivity crawlerov potrebujete serverové riešenia ako ELK Stack, Splunk alebo Datadog.
Aký vplyv majú AI crawlery na šírku pásma servera?
AI crawlery môžu spotrebovať významnú šírku pásma—niektoré stránky hlásia, že 30-50% ich celkovej návštevnosti tvoria crawlery. Samotný ChatGPT-User prelezie 2 400 stránok/hodinu a pri viacerých aktívnych AI crawlery naraz môžu náklady na pásmo výrazne stúpnuť bez riadneho monitorovania a riadenia.
Ako často by som mal monitorovať serverové logy na AI aktivitu?
Nastavte automatizované denné monitorovanie cez cron joby na analýzu logov a generovanie reportov. Pre kritické aplikácie implementujte upozornenia v reálnom čase, ktoré vás okamžite informujú, ak niektorý crawler prekročí základnú mieru o 150% alebo spotrebuje viac než 30% pásma.
Je overenie IP postačujúce na autentifikáciu AI crawlerov?
Overenie IP je omnoho spoľahlivejšie ako porovnávanie user-agent, no nie je neomylné—IP spoofing je technicky možný. Pre maximálnu bezpečnosť kombinujte overenie IP s RFC 9421 HTTP Message Signatures, ktoré poskytujú kryptografický dôkaz identity, ktorý je prakticky nemožné sfalšovať.
Čo robiť, ak zistím podozrivú aktivitu crawlera?
Najprv overte IP adresu podľa oficiálnych rozsahov danej spoločnosti. Ak nesedí, zablokujte IP na úrovni firewallu. Ak sedí, no správanie je nezvyčajné, nastavte obmedzenie rýchlosti alebo dočasne crawlera zablokujte počas vyšetrovania. Vždy uchovávajte detailné logy na analýzu a budúce použitie.
Sledujte, ako AI systémy odkazujú na váš obsah
AmICited monitoruje, ako AI systémy ako ChatGPT, Perplexity a Google AI Overviews citujú vašu značku a obsah. Získajte prehľad v reálnom čase o vašej AI viditeľnosti a chráňte svoje autorské práva.
Ako identifikovať AI crawlerov v serverových logoch: Kompletný sprievodca detekciou
Zistite, ako identifikovať a monitorovať AI crawlery ako GPTBot, PerplexityBot a ClaudeBot vo vašich serverových logoch. Objavte user-agent reťazce, metódy over...
Audit prístupu AI crawlerov: Vidia tie správne roboty váš obsah?
Zistite, ako vykonať audit prístupu AI crawlerov na vašej webstránke. Objavte, ktoré roboty vidia váš obsah a opravte prekážky, ktoré bránia AI vo viditeľnosti ...
Referenčná karta AI crawlerov: Všetky boty na prvý pohľad
Kompletný referenčný sprievodca AI crawlermi a botmi. Identifikujte GPTBot, ClaudeBot, Google-Extended a viac ako 20 ďalších AI crawlerov s user agentmi, rýchlo...
12 min čítania
Súhlas s cookies Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.