Rozvetvenie dotazu (Query Fanout)
Zistite, ako funguje rozvetvenie dotazu v AI vyhľadávacích systémoch. Objavte, ako AI rozširuje jeden dotaz na viacero poddotazov pre zvýšenie presnosti odpoved...
10 min čítania
Objavte, ako moderné AI systémy ako Google AI Mode a ChatGPT rozkladajú jeden dotaz na viacero vyhľadávaní. Spoznajte mechanizmy query fanout, dopady na viditeľnosť v AI a optimalizáciu obsahovej stratégie.
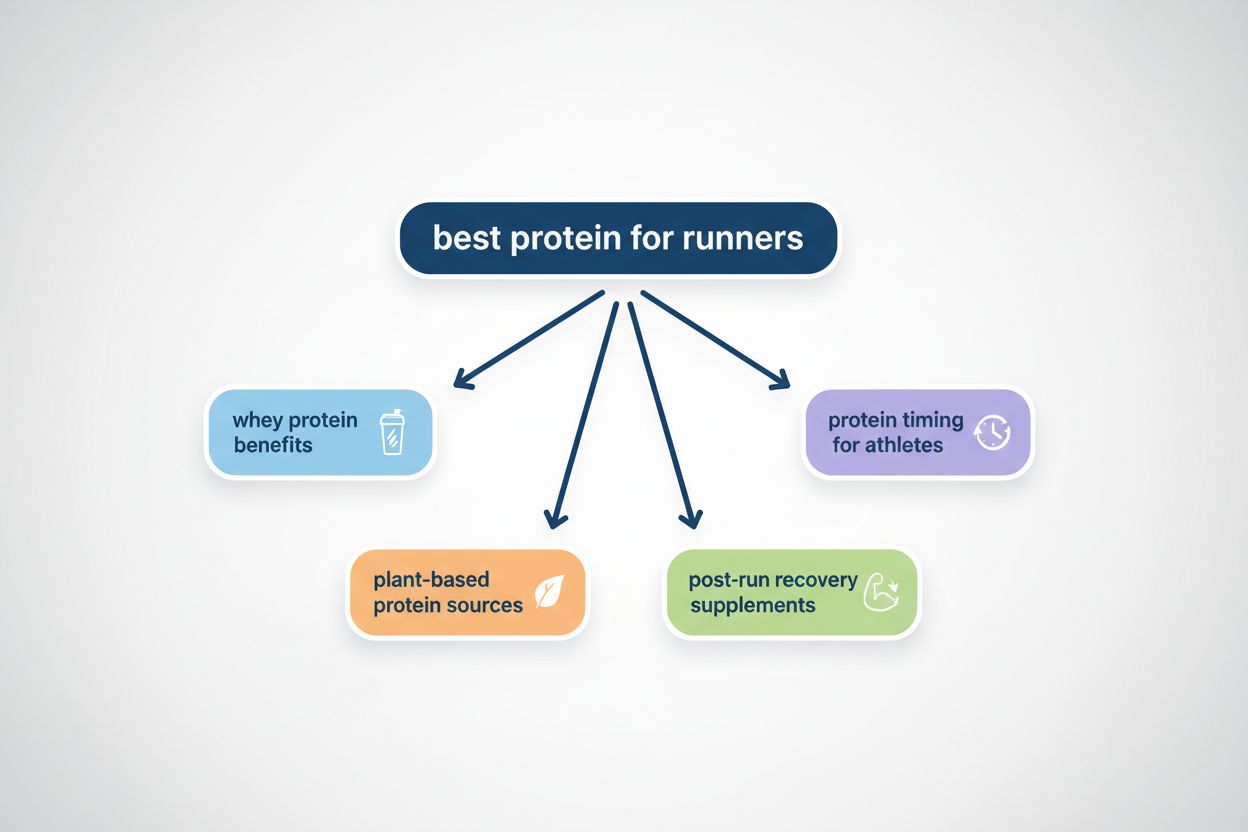
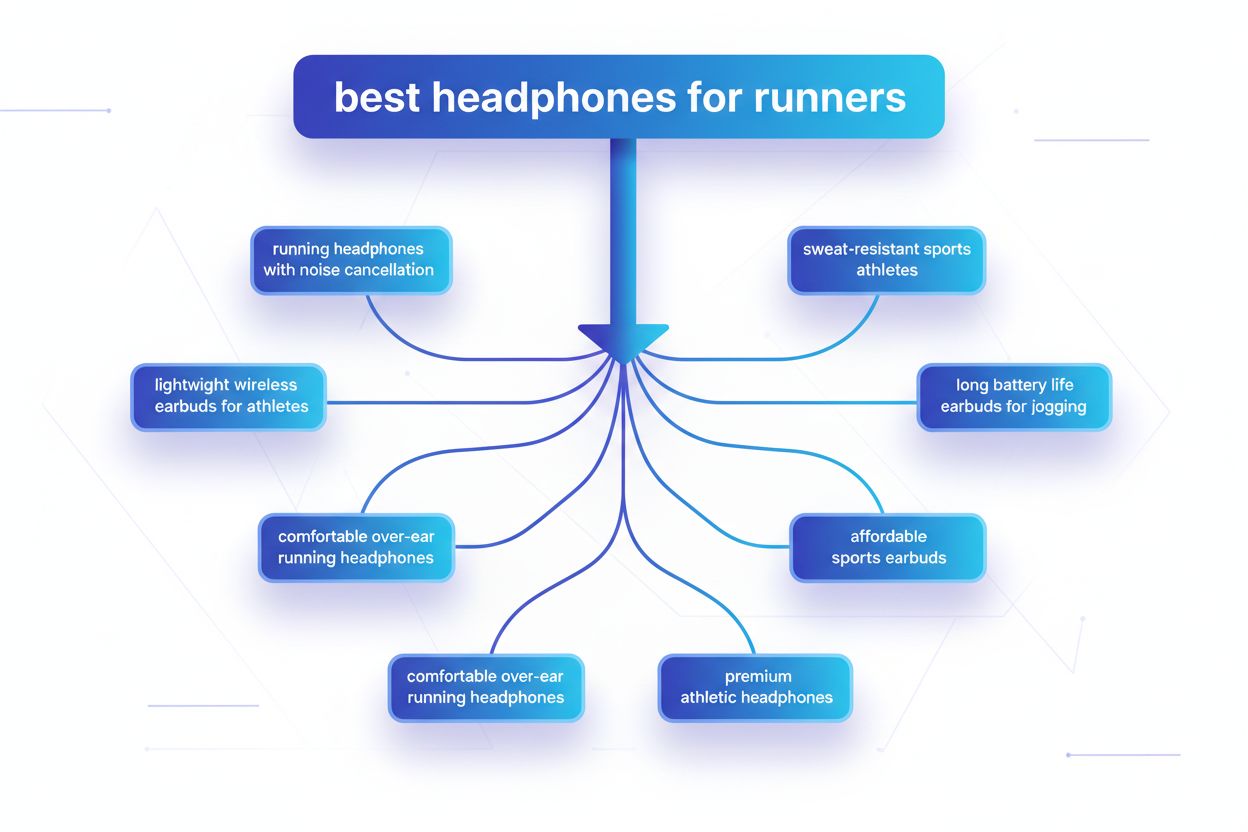
Query fanout je proces, pri ktorom veľké jazykové modely automaticky rozdelia jeden používateľský dotaz na viacero poddotazov, aby získali komplexnejšie informácie z rôznych zdrojov. Namiesto vykonania jedného vyhľadávania moderné AI systémy rozložia zámer používateľa na 5–15 príbuzných dotazov, ktoré zachytávajú rôzne pohľady, interpretácie a aspekty pôvodnej požiadavky. Napríklad keď používateľ vyhľadáva „najlepšie slúchadlá pre bežcov“ v režime Google AI, systém vygeneruje približne 8 rôznych vyhľadávaní vrátane variácií ako „bežecké slúchadlá s potlačením hluku“, „ľahké bezdrôtové slúchadlá pre športovcov“, „slúchadlá odolné proti potu pre šport“, a „slúchadlá s dlhou výdržou batérie na behanie“. To predstavuje zásadný odklon od tradičného vyhľadávania, kde sa jeden reťazec dotazu porovnáva s indexom. Hlavné charakteristiky query fanoutu zahŕňajú:
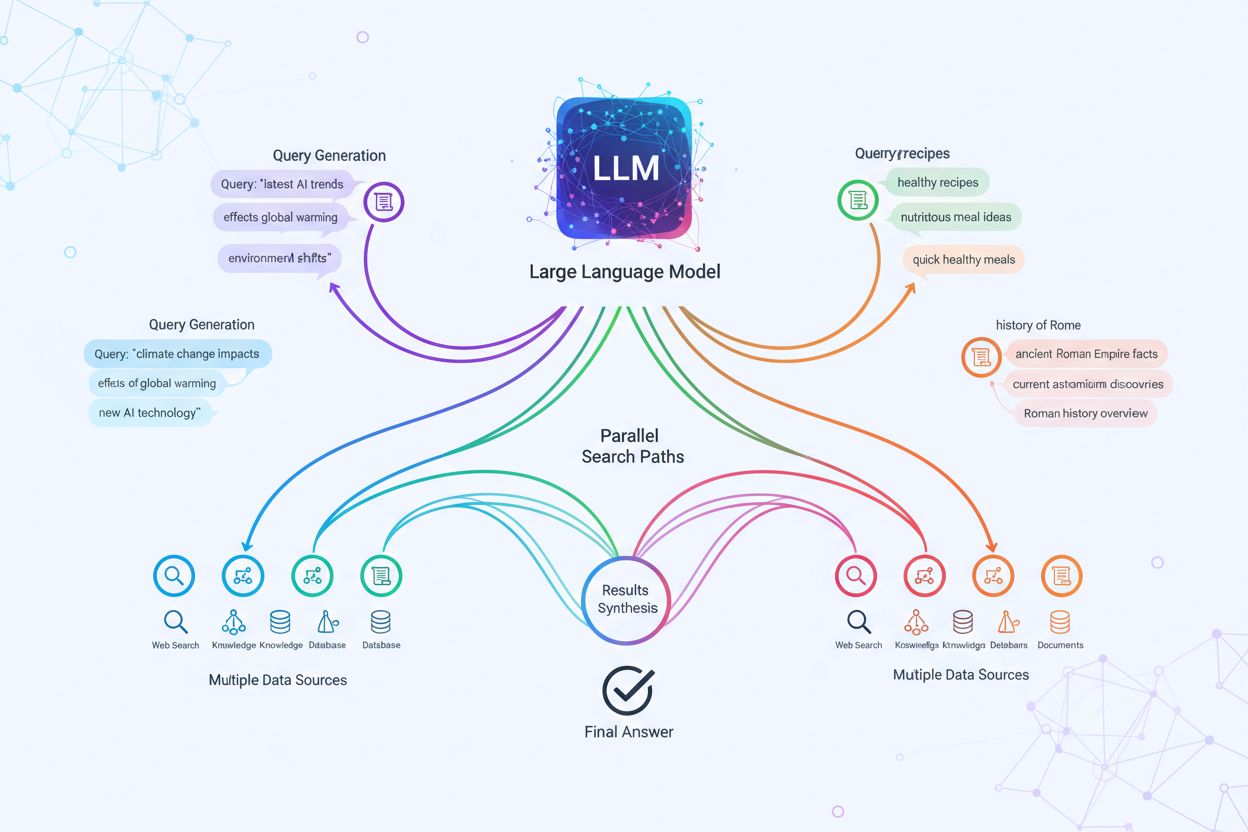
Technická implementácia query fanoutu sa opiera o sofistikované NLP algoritmy, ktoré analyzujú zložitosť dotazu a generujú sémanticky významné varianty. LLM generujú osem hlavných typov variantov dotazov: ekvivalentné dotazy (preformulovanie s rovnakým významom), nadväzujúce dotazy (skúmanie príbuzných tém), generalizačné dotazy (rozširovanie záberu), špecifikačné dotazy (zúženie zamerania), kanonizačné dotazy (štandardizácia terminológie), prekladové dotazy (prevod medzi doménami), dotazy implikácie (skúmanie logických dôsledkov) a objasňujúce dotazy (odstránenie nejednoznačnosti pojmov). Systém využíva neurónové jazykové modely na posúdenie zložitosti dotazu – meria faktory ako počet entít, hustotu vzťahov a sémantickú nejednoznačnosť – aby určil, koľko poddotazov má vygenerovať. Po vygenerovaní sa tieto dotazy vykonávajú paralelne naprieč viacerými systémami získavania vrátane webových crawlerov, znalostných grafov (napríklad Google Knowledge Graph), štruktúrovaných databáz a vektorových indexov podobnosti. Rôzne platformy implementujú túto architektúru s rôznou mierou transparentnosti a sofistikovanosti:
| Platforma | Mechanizmus | Transparentnosť | Počet dotazov | Metóda hodnotenia |
|---|---|---|---|---|
| Google AI Mode | Explicitný fanout s viditeľnými dotazmi | Vysoká | 8–12 dotazov | Viacstupňové hodnotenie |
| Microsoft Copilot | Iteratívny Bing Orchestrator | Stredná | 5–8 dotazov | Hodnotenie relevantnosti |
| Perplexity | Hybridné získavanie s viacstupňovým hodnotením | Vysoká | 6–10 dotazov | Na základe citácií |
| ChatGPT | Implicitná generácia dotazov | Nízka | Neznáme | Interné váženie |
Komplexné dotazy prechádzajú sofistikovaným rozkladom, pri ktorom systém rozdelí dotaz na základné entity, atribúty a vzťahy pred generovaním variantov. Pri spracovaní dotazu ako „Bluetooth slúchadlá s pohodlným náhlavným oblúkom a dlhou výdržou batérie vhodné pre bežcov“ systém vykonáva pochopenie založené na entitách tým, že identifikuje kľúčové entity (Bluetooth slúchadlá, bežci) a extrahuje dôležité atribúty (pohodlné, náhlavný oblúk, dlhá výdrž batérie). Proces rozkladu využíva znalostné grafy na pochopenie vzťahov medzi entitami a aké sémantické variácie existujú – rozpoznáva, že „náhlavné slúchadlá“ a „circumaurálne slúchadlá“ sú ekvivalentné, alebo že „dlhá výdrž batérie“ môže znamenať 8+ hodín, 24+ hodín alebo viacdňovú výdrž v závislosti od kontextu. Systém identifikuje príbuzné koncepty pomocou sémantických mier podobnosti, chápe, že dotazy o „odolnosti voči potu“ a „vodotesnosti“ sú príbuzné, ale odlišné, a že „bežci“ môžu mať záujem aj o „cyklistov“, „návštevníkov posilňovne“ alebo „outdoorových športovcov“. Tento rozklad umožňuje generovanie cielených poddotazov, ktoré zachytávajú rôzne aspekty zámeru používateľa namiesto jednoduchého preformulovania pôvodnej požiadavky.
Query fanout zásadne posilňuje retrieval komponent v rámci Retrieval-Augmented Generation (RAG) tým, že umožňuje bohatšie, rozmanitejšie získavanie dôkazov pred fázou generovania. V tradičných RAG pipeline sa jeden dotaz vkladá a porovnáva s vektorovou databázou, čo môže viesť k zanedbaniu relevantných informácií, ktoré používajú inú terminológiu alebo konceptuálny rámec. Query fanout tento nedostatok rieši vykonávaním viacerých získavaní naraz, pričom každý je optimalizovaný pre konkrétny variant dotazu, čím sa kolektívne získavajú dôkazy z rôznych uhlov a zdrojov. Táto paralelná stratégia získavania výrazne znižuje riziko halucinácií tým, že odpovede LLM sú podložené viacerými nezávislými zdrojmi – keď systém získava informácie o „náhlavných slúchadlách“, „circumaurálnych modeloch“ a „plnoformátových slúchadlách“ zvlášť, môže tvrdenia krížovo overiť naprieč týmito výsledkami. Architektúra využíva sémantické chunkovanie a získavanie na úrovni pasáží, kde sú dokumenty delené na zmysluplné sémantické celky namiesto pevných blokov, čo umožňuje vyhľadanie najrelevantnejších pasáží bez ohľadu na štruktúru dokumentu. Kombinovaním dôkazov z viacerých poddotazov RAG systémy produkujú odpovede, ktoré sú komplexnejšie, lepšie doložené a menej náchylné na presvedčivé, no nesprávne výsledky, aké prináša prístup s jedným dotazom.
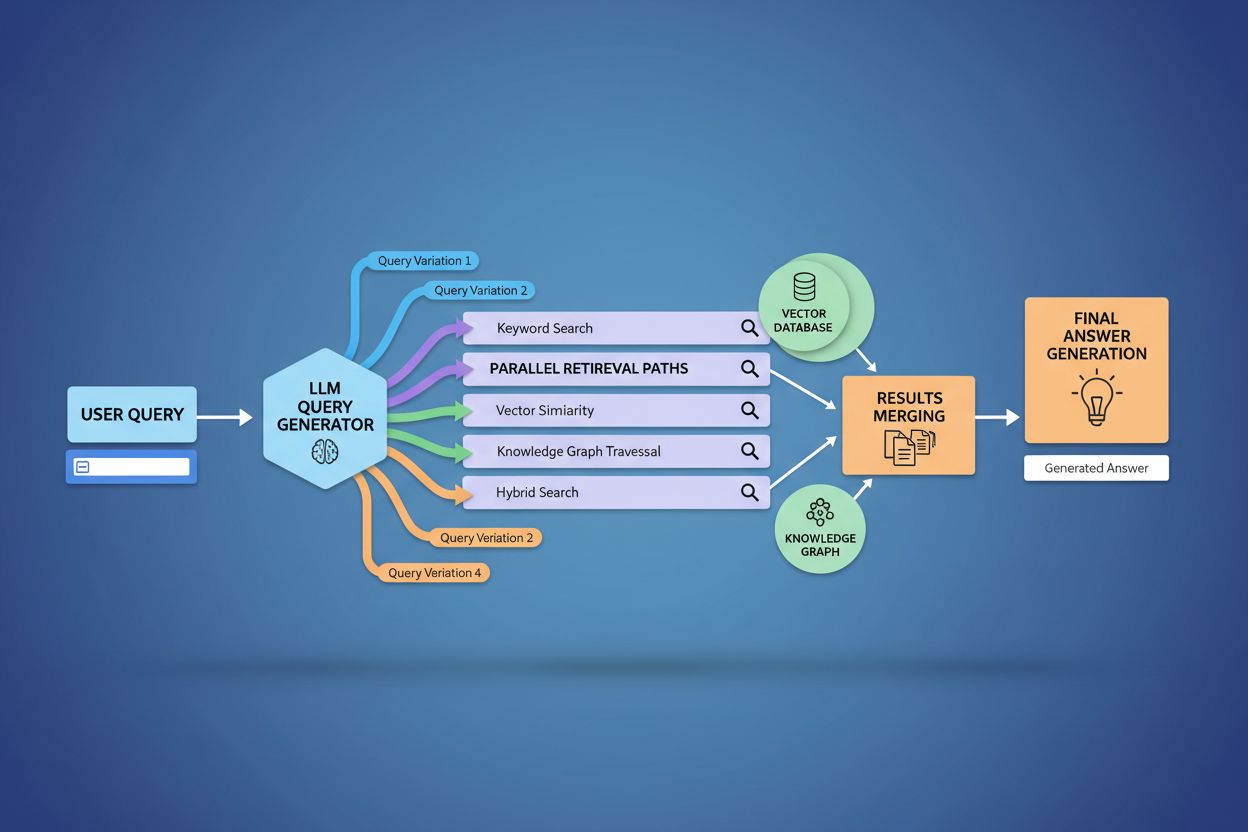
Používateľský kontext a personalizačné signály dynamicky ovplyvňujú, ako query fanout rozširuje jednotlivé požiadavky, čím vznikajú personalizované cesty získavania, ktoré sa u rôznych používateľov môžu výrazne líšiť. Systém zohľadňuje viacero dimenzií personalizácie vrátane atribútov používateľa (geografická poloha, demografický profil, profesijná rola), vzory vyhľadávacej histórie (predchádzajúce dotazy a kliknuté výsledky), časové signály (čas dňa, sezóna, aktuálne udalosti) a kontext úlohy (či používateľ hľadá informácie, nakupuje alebo sa učí). Napríklad dotaz „najlepšie slúchadlá pre bežcov“ bude rozšírený inak pre 22-ročného ultramaratónca v Keni a inak pre 45-ročného rekreačného bežca v Minnesote – prvýmu používateľovi sa rozšírenie zameria na odolnosť a tepelnú odolnosť, druhému na pohodlie a dostupnosť. Táto personalizácia však prináša problém „transformácie v dvoch bodoch“, kedy systém vníma aktuálne dotazy ako varianty historických vzorcov, čo môže obmedziť objavovanie a posilňovať existujúce preferencie. Personalizácia môže neúmyselne vytvárať filter bubliny, v ktorých rozšírenie dotazov systematicky uprednostňuje zdroje a pohľady zhodné s predchádzajúcim správaním používateľa, čím obmedzuje prístup k alternatívnym názorom alebo novým informáciám. Pochopenie týchto mechanizmov personalizácie je kľúčové pre tvorcov obsahu, pretože ten istý obsah môže, ale nemusí byť vyhľadaný v závislosti od profilu a histórie používateľa.
Hlavné AI platformy implementujú query fanout s výrazne odlišnými architektúrami, úrovňami transparentnosti a strategickými prístupmi, ktoré odrážajú ich infraštruktúru a filozofiu dizajnu. Google AI Mode využíva explicitný, viditeľný query fanout, kde používatelia môžu vidieť 8–12 vygenerovaných poddotazov zobrazených pri výsledkoch, pričom sa spustia stovky jednotlivých vyhľadávaní v indexe Google na získanie komplexných dôkazov. Microsoft Copilot používa iteratívny prístup poháňaný Bing Orchestratorom, ktorý generuje 5–8 dotazov postupne, pričom dotazový set sa počas procesu na základe priebežných výsledkov upravuje pred finálnou fázou získavania. Perplexity implementuje hybridnú stratégiu získavania s viacstupňovým hodnotením, generuje 6–10 dotazov a vykonáva ich voči webovým zdrojom aj vlastnému indexu, následne používa sofistikované algoritmy hodnotenia na výber najrelevantnejších pasáží. Prístup ChatGPT zostáva pre používateľov prevažne nejasný, generovanie dotazov prebieha implicitne vnútri modelu, takže nie je jasné, koľko dotazov sa generuje ani ako sú vykonávané. Tieto architektonické rozdiely majú zásadný vplyv na transparentnosť, reprodukovateľnosť a možnosť tvorcov obsahu optimalizovať pre každú platformu:
| Aspekt | Google AI Mode | Microsoft Copilot | Perplexity | ChatGPT |
|---|---|---|---|---|
| Viditeľnosť dotazov | Plne viditeľné používateľom | Čiastočne viditeľné | Viditeľné v citáciách | Skryté |
| Model vykonania | Paralelné dávkové | Iteratívne sekvenčné | Paralelné s hodnotením | Interné/implicitné |
| Rôznorodosť zdrojov | Iba index Google | Bing + proprietárne | Web + vlastný index | Tréningové dáta + pluginy |
| Transparentnosť citácií | Vysoká | Stredná | Veľmi vysoká | Nízka |
| Možnosti prispôsobenia | Obmedzené | Stredné | Vysoké | Stredné |
Query fanout prináša viaceré technické a sémantické výzvy, ktoré môžu spôsobiť, že systém sa odkloní od skutočného zámeru používateľa a získa technicky súvisiace, no v konečnom dôsledku neužitočné informácie. Sémantický drift nastáva generatívnym rozširovaním, keď LLM vytvára varianty dotazu, ktoré sú síce sémanticky príbuzné s pôvodným, no postupne menia význam – dotaz „najlepšie slúchadlá pre bežcov“ sa môže rozšíriť na „športové slúchadlá“, potom na „športové vybavenie“ až po „fitness pomôcky“, čím sa vzďaľuje pôvodnému zámeru. Systém musí rozlišovať medzi latentným zámerom (čo by používateľ mohol chcieť, ak by vedel viac) a explicitným zámerom (čo reálne žiada), pričom príliš agresívne rozširovanie môže tieto kategórie zamieňať a získavať informácie o produktoch, ktoré používateľ nechcel. Divergencia pri iteratívnom rozširovaní nastáva, keď každý generovaný dotaz vytvára ďalšie poddotazy, čím vzniká rozvetvený strom čoraz vzdialenejších vyhľadávaní, ktoré spoločne získajú informácie ďaleko od pôvodnej požiadavky. Filter bubliny a personalizačné skreslenie znamenajú, že dvaja používatelia s rovnakým dotazom dostanú systematicky odlišné rozšírenia na základe svojho profilu, čím vznikajú ozvenové komory, v ktorých rozšírenie posilňuje existujúce preferencie. Reálne scenáre ukazujú tieto úskalia: používateľ hľadajúci „dostupné slúchadlá“ môže mať dotaz rozšírený o luxusné značky na základe histórie prehliadania, alebo dotaz na „slúchadlá pre sluchovo znevýhodnených“ sa môže rozšíriť na všeobecné produkty pre prístupnosť, čím sa rozriedi špecifickosť pôvodného zámeru.
Vzostup query fanoutu zásadne mení obsahovú stratégiu z optimalizácie na poradie kľúčových slov na viditeľnosť cez citácie, čo vyžaduje, aby tvorcovia obsahu prehodnotili štruktúru a prezentáciu informácií. Tradičné SEO sa sústredilo na pozície pri konkrétnych kľúčových slovách; AI vyhľadávanie uprednostňuje citovanie ako autoritatívneho zdroja naprieč viacerými variantmi dotazov a kontextami. Tvorcovia by mali prijať stratégie atomického, na entity bohatého obsahu, kde sú informácie štruktúrované okolo konkrétnych entít (produkty, koncepty, osoby) s bohatým sémantickým označením (schema), ktoré umožní AI systémom extrahovať a citovať relevantné pasáže. Kľúčom sa stáva tematické zoskupovanie a tematická autorita – namiesto tvorby izolovaných článkov na jednotlivé kľúčové slová je úspešný obsah taký, ktorý komplexne pokrýva tematické oblasti a je pravdepodobnejšie, že bude získaný naprieč rôznymi variantmi dotazov z fanoutu. Implementácia schema značiek a štruktúrovaných dát umožňuje AI systémom lepšie pochopiť štruktúru obsahu a efektívnejšie extrahovať relevantné informácie, čím rastie pravdepodobnosť citácie. Metriky úspechu sa posúvajú od sledovania pozícií kľúčových slov k monitorovaniu frekvencie citácií pomocou nástrojov ako AmICited.com, ktoré sledujú, ako často sa značka a obsah objavujú v AI-generovaných odpovediach. Praktické odporúčania zahŕňajú: vytvárať komplexný, zdrojovaný obsah pokrývajúci viacero uhlov témy; implementovať bohaté schema značky (Organization, Product, Article); budovať tematickú autoritu cez prepojený obsah a pravidelne auditovať, ako sa váš obsah zobrazuje v AI odpovediach naprieč platformami a používateľskými segmentmi.
Query fanout predstavuje najvýznamnejší architektonický posun vo vyhľadávaní od zavedenia mobile-first indexovania, pričom zásadne mení spôsob, akým sú informácie objavované a zobrazované používateľom. Vývoj smerom k sémantickej infraštruktúre znamená, že vyhľadávacie systémy budú čoraz viac pracovať s významom namiesto kľúčových slov, pričom query fanout sa stane štandardným mechanizmom získavania informácií a nie voliteľným vylepšením. Metriky citácií sa stávajú rovnako dôležité ako spätné odkazy pri určovaní viditeľnosti a autority obsahu – obsah citovaný v 50 rôznych AI odpovediach má väčšiu váhu než obsah na prvom mieste pre jedno kľúčové slovo. Tento posun prináša výzvy aj príležitosti: tradičné SEO nástroje na sledovanie pozícií kľúčových slov strácajú význam, pretože sú potrebné nové metriky založené na frekvencii citácií, rôznorodosti zdrojov a objavovaní sa naprieč variantmi dotazov. Tento vývoj však zároveň otvára príležitosti pre značky optimalizovať špeciálne pre AI vyhľadávanie budovaním autoritatívneho, dobre štruktúrovaného obsahu, ktorý slúži ako spoľahlivý zdroj naprieč viacerými interpretáciami dotazov. Budúcnosť pravdepodobne prinesie vyššiu transparentnosť mechanizmov query fanoutu, pričom platformy budú súťažiť v tom, ako jasne používateľom ukážu logiku svojho viacdotazového prístupu, a tvorcovia obsahu budú rozvíjať špecializované stratégie na maximalizáciu viditeľnosti naprieč rôznorodými cestami získavania, ktoré fanout vytvára.
Query fanout je automatizovaný proces, pri ktorom AI systémy rozkladajú jeden používateľský dotaz na viacero poddotazov a vykonávajú ich paralelne, zatiaľ čo query expansion tradične znamená pridávanie príbuzných výrazov k jednému dotazu. Query fanout je sofistikovanejší, generuje sémanticky rôznorodé varianty, ktoré zachytávajú rôzne pohľady a interpretácie pôvodného zámeru.
Query fanout výrazne ovplyvňuje viditeľnosť, pretože váš obsah musí byť objaviteľný naprieč viacerými variantmi dotazov, nielen pri presnom dotaze používateľa. Obsah, ktorý pokrýva rôzne pohľady, používa rôznu terminológiu a je dobre štruktúrovaný so schema značkami, má väčšiu šancu byť nájdený a citovaný naprieč rôznymi poddotazmi, ktoré vzniknú vďaka fanoutu.
Všetky hlavné AI vyhľadávacie platformy používajú mechanizmy query fanout: Google AI Mode využíva explicitný, viditeľný fanout (8–12 dotazov); Microsoft Copilot používa iteratívny fanout cez Bing Orchestrator; Perplexity implementuje hybridné získavanie s viacstupňovým hodnotením; a ChatGPT používa implicitnú generáciu dotazov. Každá platforma ho implementuje inak, ale všetky rozkladajú komplexné dotazy na viacero vyhľadávaní.
Áno. Optimalizujte tvorbou atomického, na entity bohatého obsahu štruktúrovaného okolo konkrétnych konceptov; implementujte komplexné schema značky; budujte tematickú autoritu prepojeným obsahom; používajte jasnú, rozmanitú terminológiu a pokrývajte viacero uhlov témy. Nástroje ako AmICited.com vám pomôžu sledovať, ako sa váš obsah zobrazuje naprieč rôznymi rozkladmi dotazov.
Query fanout zvyšuje latenciu, pretože viacero dotazov sa vykonáva paralelne, ale moderné systémy to zmierňujú paralelným spracovaním. Kým jeden dotaz môže trvať 200 ms, vykonanie 8 dotazov paralelne zvyčajne pridá len 300–500 ms celkovej latencie vďaka simultánnemu vykonaniu. Tento kompromis sa oplatí kvôli vyššej kvalite odpovedí.
Query fanout posilňuje Retrieval-Augmented Generation (RAG) tým, že umožňuje bohatšie získavanie dôkazov. Namiesto získavania dokumentov pre jeden dotaz, fanout získava dôkazy pre viacero variantov dotazov paralelne, čím poskytuje LLM rozmanitejší, komplexnejší kontext pre generovanie presných odpovedí a znižuje riziko halucinácií.
Personalizácia ovplyvňuje, ako sú dotazy rozkladané na základe atribútov používateľa (lokalita, história, demografia), časových signálov a kontextu úlohy. Ten istý dotaz sa rozšíri inak pre rôznych používateľov, čím vznikajú personalizované cesty získavania. To môže zvýšiť relevantnosť, ale aj vytvárať filter bubliny, v ktorých používatelia vidia systematicky odlišné výsledky podľa svojho profilu.
Query fanout predstavuje najvýznamnejšiu zmenu vo vyhľadávaní od zavedenia mobile-first indexovania. Tradičné metriky poradia kľúčových slov strácajú význam, pretože ten istý dotaz sa rozširuje odlišne pre rôznych používateľov. SEO profesionáli musia presunúť dôraz z poradia na kľúčové slová na viditeľnosť cez citácie, štruktúru obsahu a optimalizáciu entít, aby uspeli v AI vyhľadávaní.
Zistite, ako sa vaša značka zobrazuje naprieč AI vyhľadávacími platformami, keď sú dotazy rozšírené a rozložené. Sledujte citácie a zmienky v AI-generovaných odpovediach.
Zistite, ako funguje rozvetvenie dotazu v AI vyhľadávacích systémoch. Objavte, ako AI rozširuje jeden dotaz na viacero poddotazov pre zvýšenie presnosti odpoved...

Zistite základné prvé kroky, ako optimalizovať váš obsah pre AI vyhľadávače ako ChatGPT, Perplexity a Google AI Overviews. Objavte, ako štruktúrovať obsah, impl...
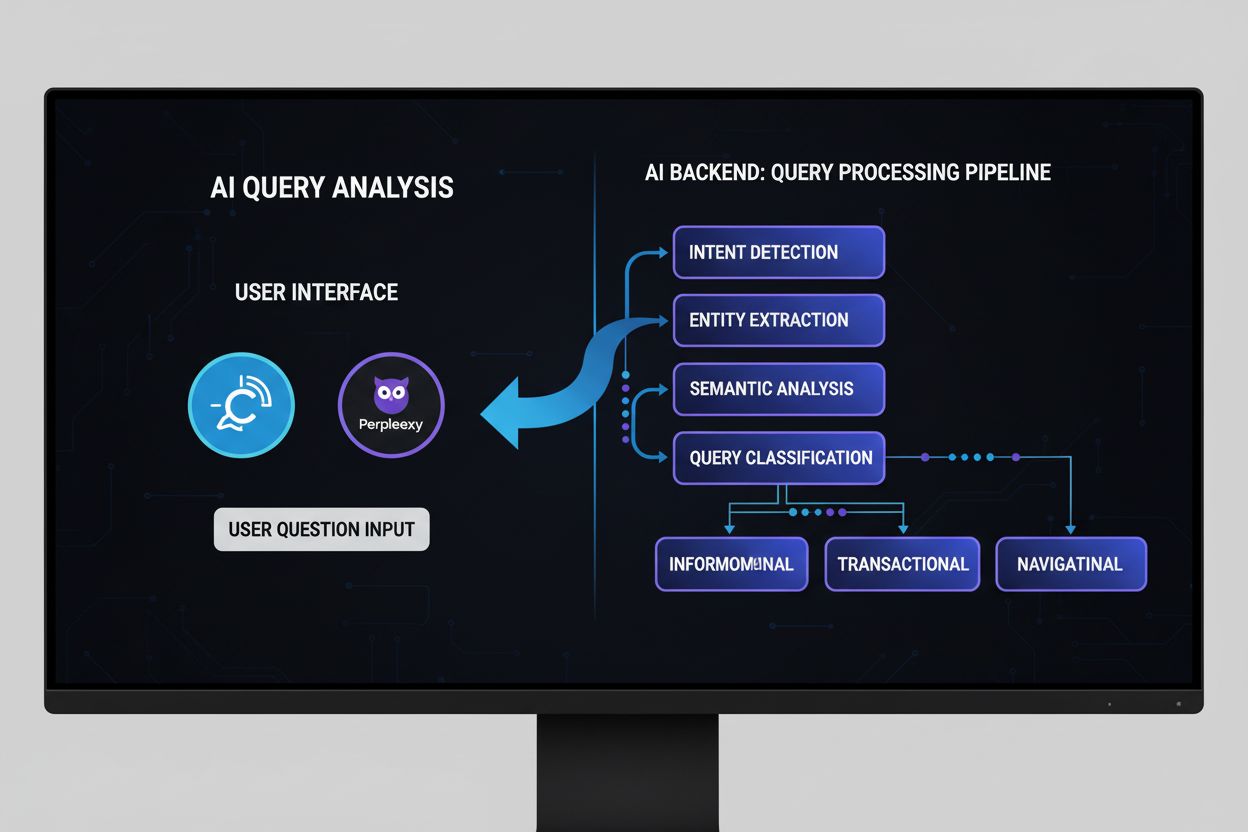
Zistite, čo je AI Query Analysis, ako funguje a prečo je dôležitá pre viditeľnosť v AI vyhľadávaní. Pochopte klasifikáciu zámeru dopytu, sémantickú analýzu a mo...
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.