Query Fanout
Scopri come funziona Query Fanout nei sistemi di ricerca AI. Scopri come l'IA espande singole query in più sotto-query per migliorare la precisione delle rispos...
12 min di lettura
Scopri come i moderni sistemi di intelligenza artificiale come Google AI Mode e ChatGPT scompongono una singola query in più ricerche. Impara i meccanismi di query fanout, le implicazioni per la visibilità nell’AI e come ottimizzare la strategia dei contenuti.
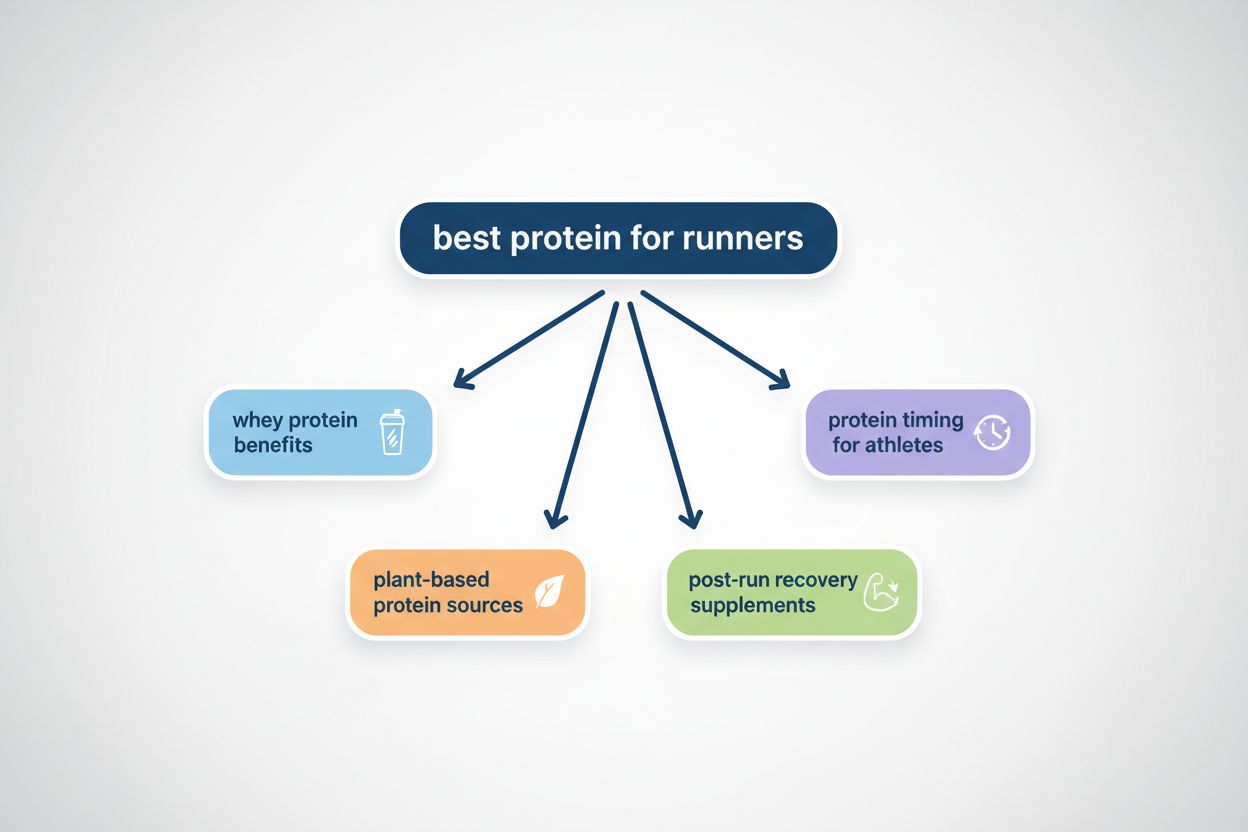
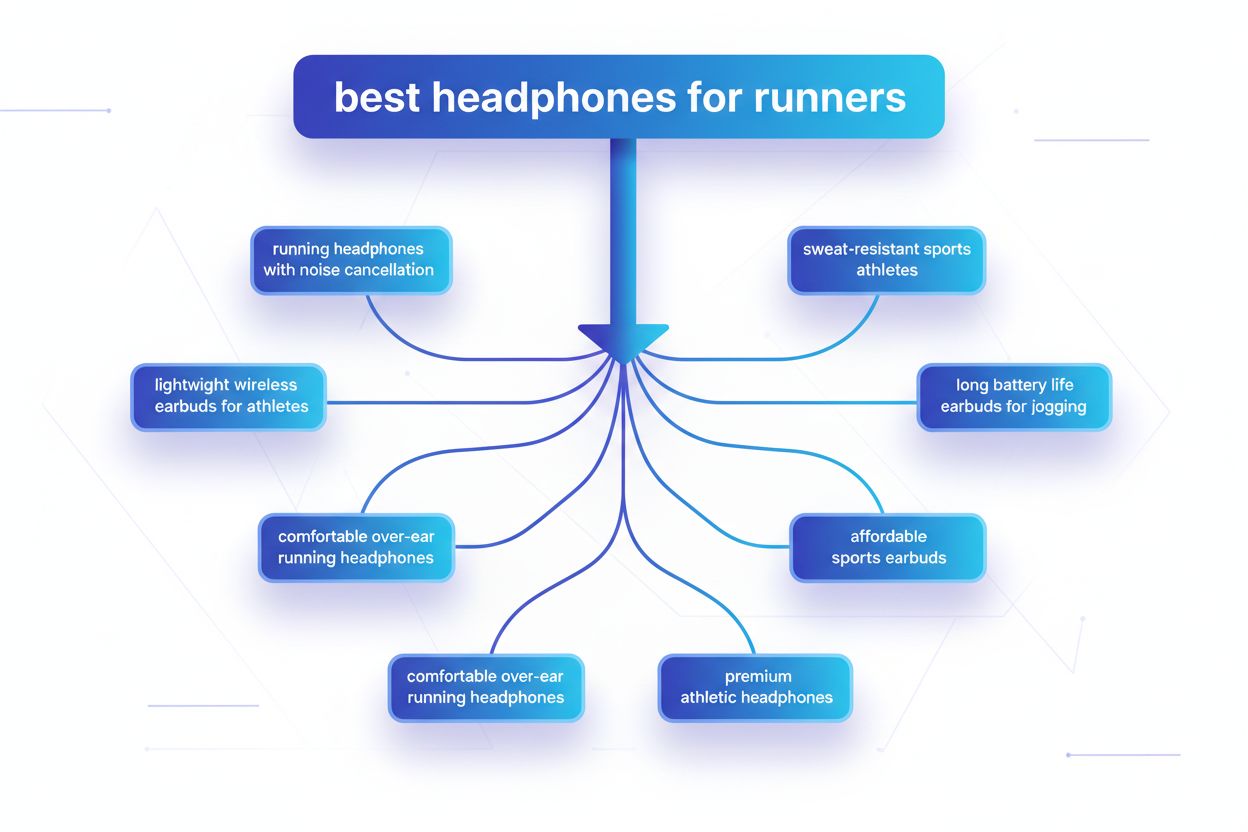
Il query fanout è il processo tramite cui i grandi modelli linguistici suddividono automaticamente una singola query utente in più sotto-query per raccogliere informazioni più complete da fonti diverse. Invece di eseguire una sola ricerca, i moderni sistemi AI scompongono l’intento dell’utente in 5-15 query correlate che catturano diversi punti di vista, interpretazioni e aspetti della richiesta originale. Ad esempio, quando un utente cerca “migliori cuffie per runner” nella modalità AI di Google, il sistema genera circa 8 ricerche diverse, comprese varianti come “cuffie da corsa con cancellazione del rumore”, “auricolari wireless leggeri per atleti”, “cuffie sportive resistenti al sudore” e “auricolari con lunga durata della batteria per jogging”. Questo rappresenta un cambiamento fondamentale rispetto alla ricerca tradizionale, dove una singola stringa di query viene confrontata con un indice. Le caratteristiche chiave del query fanout includono:
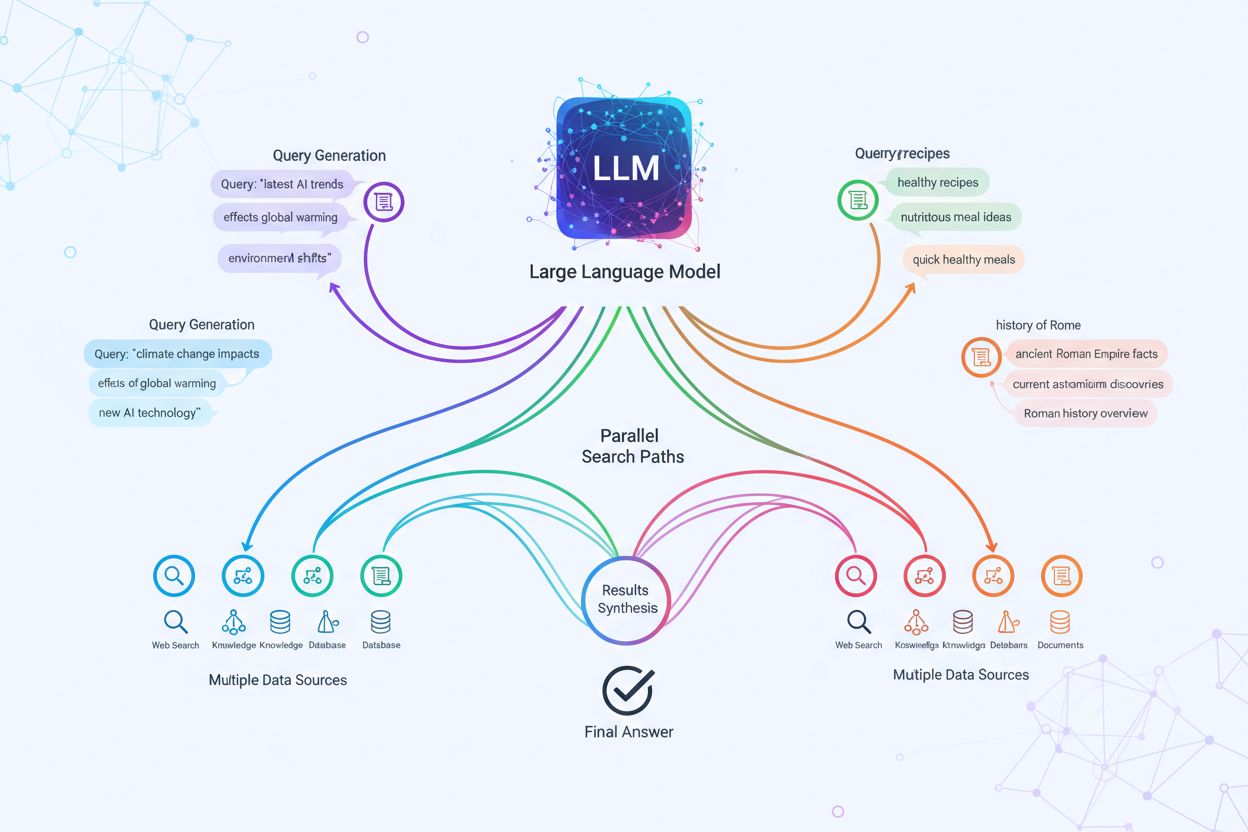
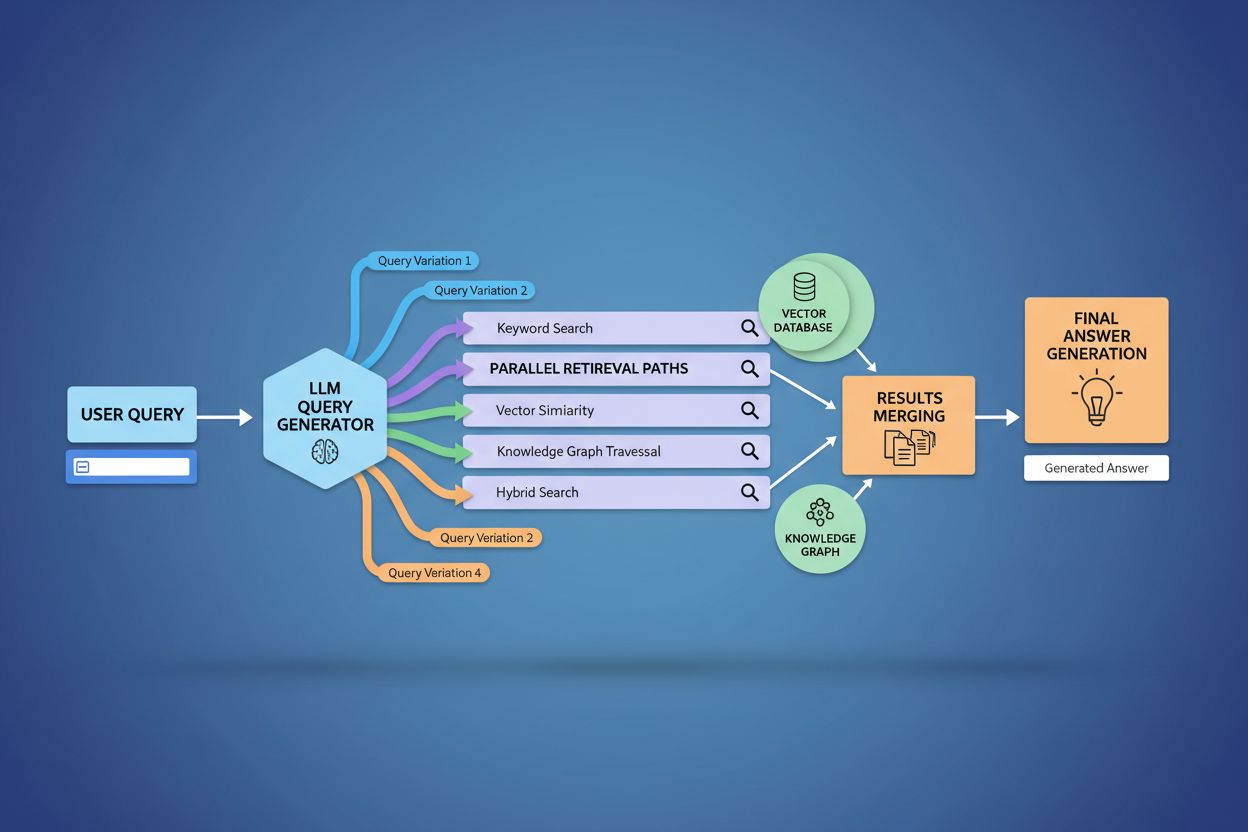
L’implementazione tecnica del query fanout si basa su sofisticati algoritmi NLP che analizzano la complessità della query e generano varianti semanticamente significative. I LLM producono otto tipi principali di varianti di query: query equivalenti (riformulazione con significato identico), query di follow-up (approfondimento di argomenti correlati), query di generalizzazione (ampliamento dello scopo), query di specificazione (focalizzazione), query di canonizzazione (standardizzazione della terminologia), query di traduzione (conversione tra domini), query di implicazione (esplorazione delle implicazioni logiche) e query di chiarificazione (disambiguazione di termini ambigui). Il sistema utilizza modelli linguistici neurali per valutare la complessità della query—misurando fattori come numero di entità, densità di relazioni e ambiguità semantica—per determinare quante sotto-query generare. Una volta generate, queste query vengono eseguite in parallelo su più sistemi di recupero, inclusi web crawler, knowledge graph (come il Knowledge Graph di Google), database strutturati e indici di similarità vettoriale. Diverse piattaforme implementano questa architettura con gradi diversi di trasparenza e sofisticazione:
| Piattaforma | Meccanismo | Trasparenza | Numero Query | Metodo di Ranking |
|---|---|---|---|---|
| Google AI Mode | Fanout esplicito con query visibili | Alta | 8-12 query | Ranking multi-stadio |
| Microsoft Copilot | Orchestratore Bing iterativo | Media | 5-8 query | Punteggio di rilevanza |
| Perplexity | Recupero ibrido con ranking multi-stadio | Alta | 6-10 query | Basato su citazioni |
| ChatGPT | Generazione implicita di query | Bassa | Sconosciuto | Pesatura interna |
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Le query complesse subiscono una sofisticata scomposizione in cui il sistema le suddivide in entità, attributi e relazioni costitutive prima di generare varianti. Quando si elabora una query come “cuffie Bluetooth con comodo design over-ear e batteria a lunga durata adatte ai runner”, il sistema effettua una comprensione centrata sulle entità identificando le entità chiave (cuffie Bluetooth, runner) ed estraendo gli attributi critici (comode, over-ear, batteria a lunga durata). Il processo di scomposizione sfrutta i knowledge graph per comprendere come queste entità si relazionano tra loro e quali variazioni semantiche esistono—riconoscendo che “cuffie over-ear” e “cuffie circumaurali” sono equivalenti, o che “batteria a lunga durata” può significare 8+ ore, 24+ ore o più giorni di autonomia a seconda del contesto. Il sistema identifica concetti correlati tramite misure di similarità semantica, comprendendo che le query su “resistenza al sudore” e “resistenza all’acqua” sono correlate ma distinte, e che i “runner” potrebbero essere interessati anche a “ciclisti”, “frequentatori di palestra” o “atleti outdoor”. Questa scomposizione consente la generazione di sotto-query mirate che catturano diverse sfaccettature dell’intento dell’utente invece di limitarsi a riformulare la richiesta originale.
Il query fanout rafforza fondamentalmente la componente di recupero dei framework di Retrieval-Augmented Generation (RAG) permettendo una raccolta di prove più ricca e diversificata prima della fase di generazione. Nei tradizionali pipeline RAG, una singola query viene incorporata e confrontata con un database vettoriale, rischiando di perdere informazioni rilevanti che utilizzano terminologia o concetti diversi. Il query fanout affronta questa limitazione eseguendo molteplici operazioni di recupero in parallelo, ciascuna ottimizzata per una specifica variante di query, che insieme raccolgono prove da angolazioni e fonti diverse. Questa strategia di recupero parallelo riduce significativamente il rischio di allucinazioni ancorando le risposte dei LLM a molteplici fonti indipendenti—quando il sistema recupera informazioni su “cuffie over-ear”, “design circumaurali” e “cuffie full-size” separatamente, può incrociare e validare le affermazioni tra questi diversi risultati di recupero. L’architettura incorpora il semantic chunking e il recupero basato su passaggi, in cui i documenti vengono suddivisi in unità semantiche significative invece che in blocchi a lunghezza fissa, permettendo al sistema di recuperare i passaggi più pertinenti indipendentemente dalla struttura del documento. Combinando le prove dai recuperi di più sotto-query, i sistemi RAG producono risposte più complete, meglio documentate e meno soggette a errori sicuri ma errati tipici degli approcci a recupero singolo.
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Il contesto utente e i segnali di personalizzazione modellano dinamicamente il modo in cui il query fanout espande le singole richieste, creando percorsi di recupero personalizzati che possono divergere significativamente da un utente all’altro. Il sistema incorpora molteplici dimensioni di personalizzazione tra cui attributi utente (posizione geografica, profilo demografico, ruolo professionale), pattern di cronologia delle ricerche (query precedenti e risultati cliccati), segnali temporali (ora del giorno, stagione, eventi attuali) e contesto del task (se l’utente sta facendo ricerca, shopping o formazione). Ad esempio, una query su “migliori cuffie per runner” si espande in modo diverso per un atleta di ultramaratona di 22 anni in Kenya rispetto a un jogger occasionale di 45 anni in Minnesota—l’espansione per il primo utente potrebbe enfatizzare la durabilità e la resistenza al calore mentre per il secondo il comfort e l’accessibilità. Tuttavia, questa personalizzazione introduce il problema della “two-point transformation” in cui il sistema tratta le query attuali come variazioni di pattern storici, potenzialmente limitando l’esplorazione e rafforzando le preferenze esistenti. La personalizzazione può creare involontariamente filter bubble in cui l’espansione della query favorisce sistematicamente fonti e prospettive allineate al comportamento storico dell’utente, limitando l’esposizione a punti di vista alternativi o informazioni emergenti. Comprendere questi meccanismi di personalizzazione è fondamentale per i content creator, poiché uno stesso contenuto può essere o meno recuperato a seconda del profilo e della cronologia dell’utente.
Le principali piattaforme AI implementano il query fanout con architetture, livelli di trasparenza e approcci strategici molto diversi, riflettendo la loro infrastruttura sottostante e le filosofie di design. Google AI Mode impiega un query fanout esplicito e visibile in cui gli utenti possono vedere le 8-12 sotto-query generate visualizzate insieme ai risultati, lanciando centinaia di ricerche individuali sull’indice di Google per raccogliere prove complete. Microsoft Copilot utilizza un approccio iterativo alimentato dal Bing Orchestrator, che genera 5-8 query in sequenza, affinando il set di query in base ai risultati intermedi prima di eseguire la fase finale di recupero. Perplexity implementa una strategia di recupero ibrida con ranking multi-stadio, generando 6-10 query ed eseguendole sia su fonti web che sul proprio indice proprietario, applicando poi sofisticati algoritmi di ranking per mostrare i passaggi più rilevanti. L’approccio di ChatGPT rimane in gran parte opaco agli utenti, con la generazione delle query che avviene in modo implicito all’interno dell’elaborazione interna del modello, rendendo difficile capire quante query vengono generate o come vengono eseguite. Queste differenze architetturali hanno importanti implicazioni per trasparenza, riproducibilità e possibilità per i content creator di ottimizzare per ciascuna piattaforma:
| Aspetto | Google AI Mode | Microsoft Copilot | Perplexity | ChatGPT |
|---|---|---|---|---|
| Visibilità Query | Completamente visibile agli utenti | Parzialmente visibile | Visibile nelle citazioni | Nascosta |
| Modello di Esecuzione | Batch parallelo | Iterativo sequenziale | Parallelo con ranking | Interno/implicito |
| Diversità delle Fonti | Solo indice Google | Bing + proprietario | Web + indice proprietario | Dati di training + plugin |
| Trasparenza Citazioni | Alta | Media | Molto alta | Bassa |
| Opzioni di Personalizzazione | Limitate | Medie | Alte | Medie |
Il query fanout introduce diverse sfide tecniche e semantiche che possono portare il sistema a divergere dall’effettivo intento dell’utente, recuperando informazioni tecnicamente correlate ma non utili. Si verifica drift semantico durante l’espansione generativa quando il LLM crea varianti di query che, pur semanticamente correlate all’originale, ne modificano progressivamente il significato—una query su “migliori cuffie per runner” può espandersi in “cuffie atletiche”, poi “attrezzatura sportiva”, poi “accessori fitness”, allontanandosi dall’intento iniziale. Il sistema deve distinguere tra intento latente (ciò che l’utente potrebbe volere se sapesse di più) e intento esplicito (ciò che ha effettivamente chiesto), e un’espansione troppo aggressiva può confondere queste categorie, recuperando informazioni su prodotti che l’utente non intendeva considerare. La divergenza da espansione iterativa si verifica quando ogni query generata genera ulteriori sotto-query, creando una ramificazione di ricerche sempre più tangenziali che nel complesso recuperano informazioni lontane dalla richiesta originale. I filter bubble e i bias di personalizzazione fanno sì che due utenti che pongono la stessa domanda ricevano espansioni di query sistematicamente diverse in base ai loro profili, creando potenzialmente delle echo chamber in cui ciascuna espansione rafforza le preferenze esistenti. Scenari reali dimostrano queste criticità: un utente che cerca “cuffie economiche” può vedere la propria query espansa includendo marchi di lusso in base alla sua cronologia di navigazione, oppure una query su “cuffie per utenti con problemi di udito” può essere ampliata includendo prodotti di accessibilità generale, diluendo la specificità dell’intento originale.
L’ascesa del query fanout sposta fondamentalmente la strategia dei contenuti dall’ottimizzazione per ranking delle parole chiave verso la visibilità basata su citazioni, richiedendo ai content creator di ripensare come strutturare e presentare le informazioni. La SEO tradizionale si concentrava sul ranking per specifiche parole chiave; la ricerca guidata dall’AI privilegia l’essere citati come fonte autorevole attraverso molteplici varianti di query e contesti. I content creator dovrebbero adottare strategie di contenuti atomici ricchi di entità, in cui le informazioni sono strutturate attorno a specifiche entità (prodotti, concetti, persone) con markup semantico ricco che permetta ai sistemi AI di estrarre e citare i passaggi rilevanti. Il clustering tematico e l’autorità tematica diventano sempre più importanti—anziché creare articoli isolati su singole parole chiave, i contenuti di successo coprono in modo completo le aree tematiche, aumentando le probabilità di essere recuperati tra le diverse varianti di query generate dal fanout. L’implementazione di schema markup e dati strutturati consente ai sistemi AI di comprendere la struttura dei contenuti ed estrarre informazioni rilevanti in modo più efficace, aumentando la probabilità di citazione. Le metriche di successo si spostano dal monitoraggio dei ranking delle parole chiave al monitoraggio della frequenza di citazione tramite strumenti come AmICited.com, che traccia quante volte brand e contenuti compaiono nelle risposte generate dall’AI. Le best practice includono: creare contenuti completi e ben documentati che affrontano più angolazioni di un argomento; implementare markup schema ricco (Organization, Product, Article schema); costruire autorità tematica tramite contenuti interconnessi; e verificare regolarmente come i propri contenuti appaiono nelle risposte AI su diverse piattaforme e segmenti di utenti.
Il query fanout rappresenta il cambiamento architetturale più significativo nella ricerca dai tempi dell’indicizzazione mobile-first, trasformando radicalmente il modo in cui le informazioni vengono scoperte e presentate agli utenti. L’evoluzione verso un’infrastruttura semantica significa che i sistemi di ricerca opereranno sempre più sul significato piuttosto che sulle parole chiave, con il query fanout che diventerà il meccanismo predefinito per il recupero delle informazioni e non più un semplice potenziamento opzionale. Le metriche di citazione stanno diventando importanti quanto i backlink nel determinare la visibilità e l’autorevolezza dei contenuti—un contenuto citato in 50 diverse risposte AI pesa più di un contenuto al primo posto per una sola parola chiave. Questo cambiamento crea sia sfide che opportunità: gli strumenti SEO tradizionali che tracciano il ranking per parola chiave diventano meno rilevanti, richiedendo nuovi framework di misurazione focalizzati sulla frequenza di citazione, diversità delle fonti e presenza tra le diverse varianti di query. Tuttavia, questa evoluzione offre anche opportunità ai brand per ottimizzare specificamente per la ricerca AI, creando contenuti autorevoli e ben strutturati che fungano da fonte affidabile tra molteplici interpretazioni di query. Il futuro probabilmente vedrà una maggiore trasparenza sui meccanismi di query fanout, con le piattaforme che competono su quanto chiaramente mostrano agli utenti il ragionamento dietro il loro approccio multi-query, e i content creator che sviluppano strategie specializzate per massimizzare la visibilità tra i diversi percorsi di recupero creati dal fanout.
Comprendi come appare il tuo brand sulle piattaforme di ricerca AI quando le query vengono espanse e scomposte. Tieni traccia delle citazioni e menzioni nelle risposte generate dall'AI.
Scopri come funziona Query Fanout nei sistemi di ricerca AI. Scopri come l'IA espande singole query in più sotto-query per migliorare la precisione delle rispos...
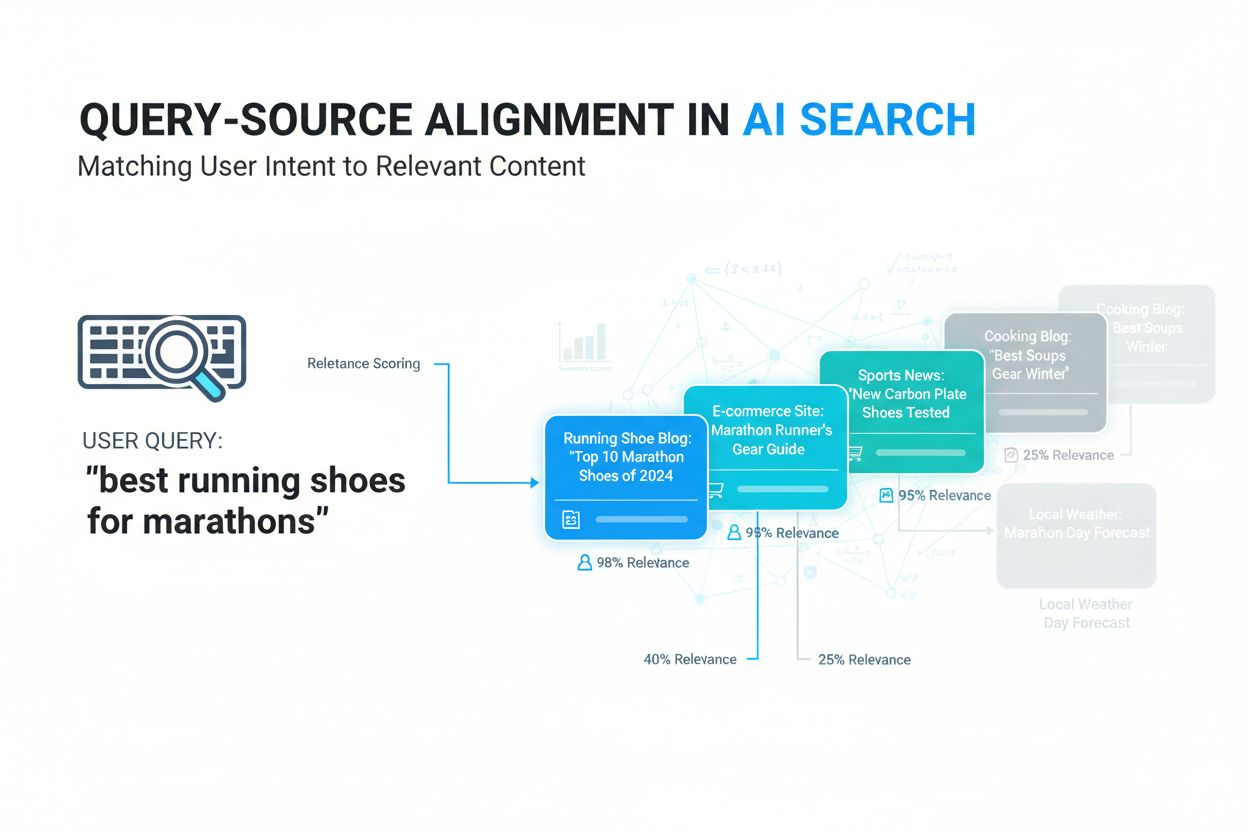
Scopri cos'è l'allineamento query-fonte, come i sistemi IA abbinano le query degli utenti alle fonti pertinenti e perché è fondamentale per la visibilità dei co...
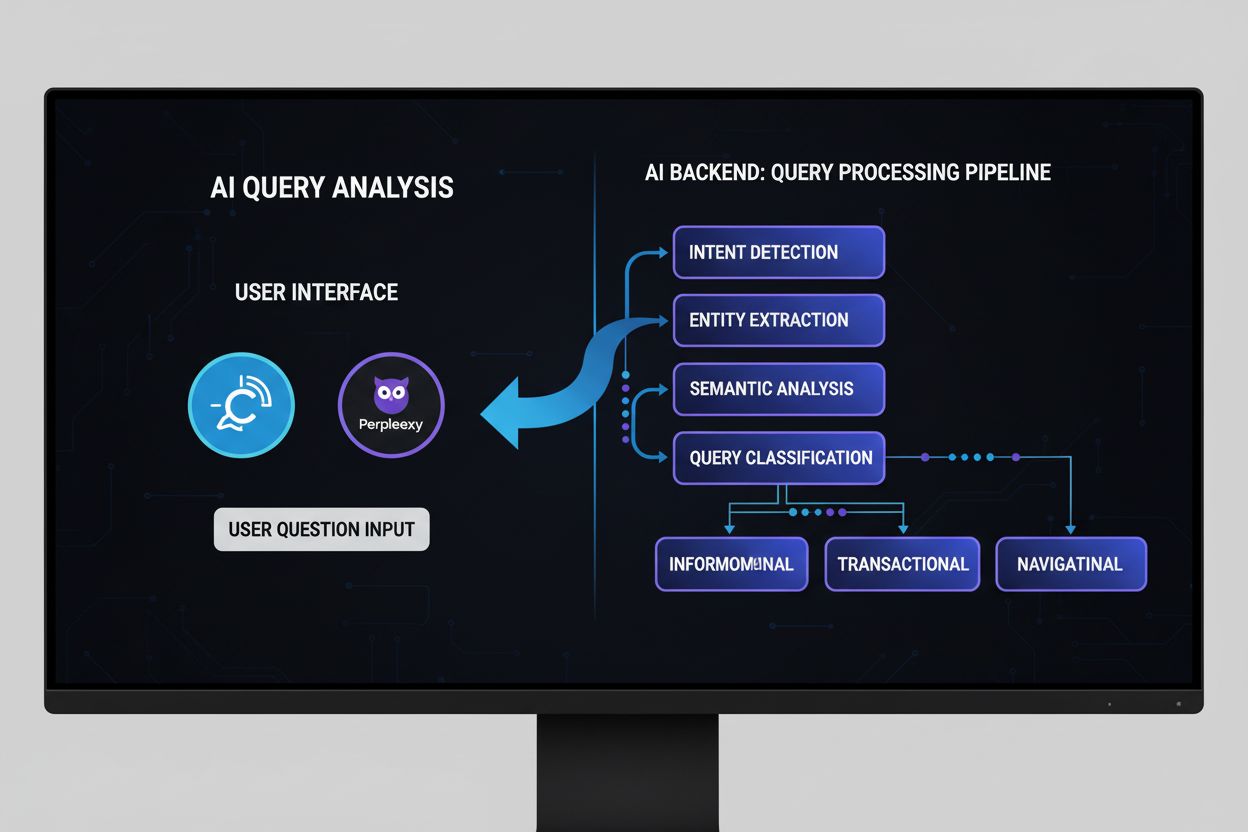
Scopri cos'è l'Analisi delle Query AI, come funziona e perché è importante per la visibilità nella ricerca AI. Comprendi la classificazione dell'intento della q...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.