Rozwinięcie zapytania (Query Fanout)
Dowiedz się, jak działa rozwinięcie zapytania w systemach wyszukiwania AI. Odkryj, jak AI rozszerza pojedyncze zapytania na wiele podzapytań, by poprawić trafno...
10 min czytania
Dowiedz się, jak nowoczesne systemy AI, takie jak Google AI Mode i ChatGPT, rozkładają pojedyncze zapytania na wiele wyszukiwań. Poznaj mechanizmy query fanout, ich wpływ na widoczność w AI oraz optymalizację strategii treści.
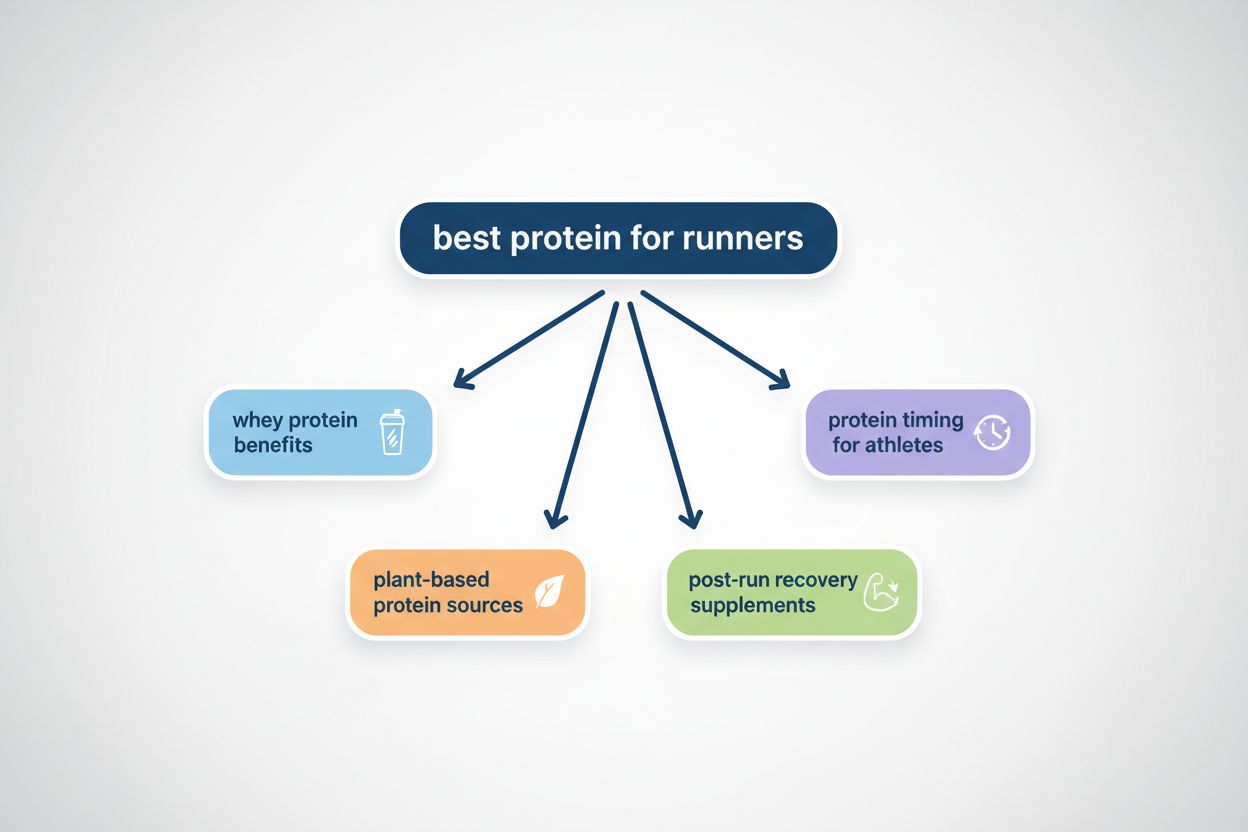
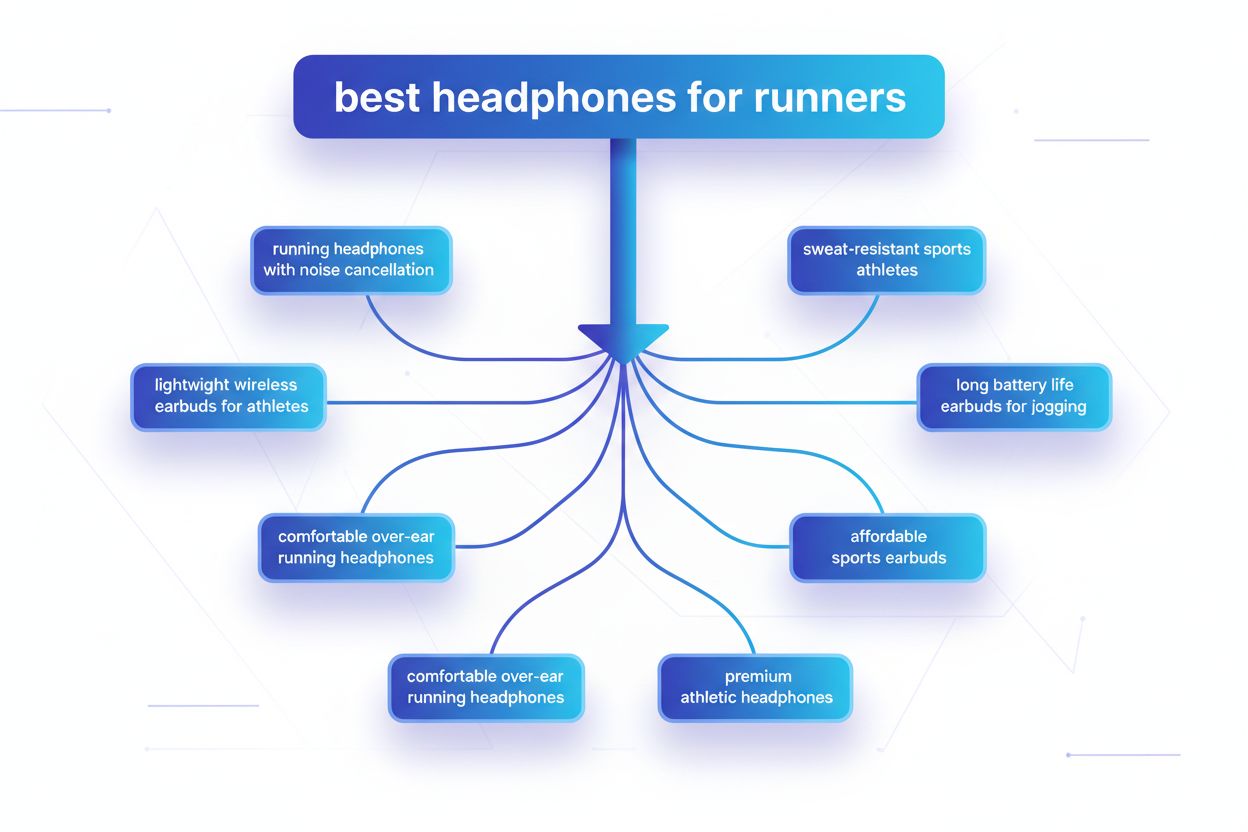
Query fanout to proces, w którym duże modele językowe automatycznie rozbijają pojedyncze zapytanie użytkownika na wiele podzapytań, aby zebrać pełniejsze informacje z różnych źródeł. Zamiast wykonać jedno wyszukiwanie, nowoczesne systemy AI rozkładają intencję użytkownika na 5-15 powiązanych zapytań, obejmujących różne perspektywy, interpretacje i aspekty pierwotnej prośby. Przykładowo, gdy użytkownik szuka „najlepszych słuchawek dla biegaczy” w Google AI Mode, system generuje około 8 różnych wyszukiwań, w tym warianty takie jak „słuchawki do biegania z redukcją szumów”, „lekkie bezprzewodowe słuchawki dla sportowców”, „odporne na pot słuchawki sportowe” czy „słuchawki z długim czasem pracy na baterii do joggingu”. To fundamentalna zmiana względem tradycyjnego wyszukiwania, gdzie pojedynczy ciąg zapytania był dopasowywany do indeksu. Kluczowe cechy query fanout to:
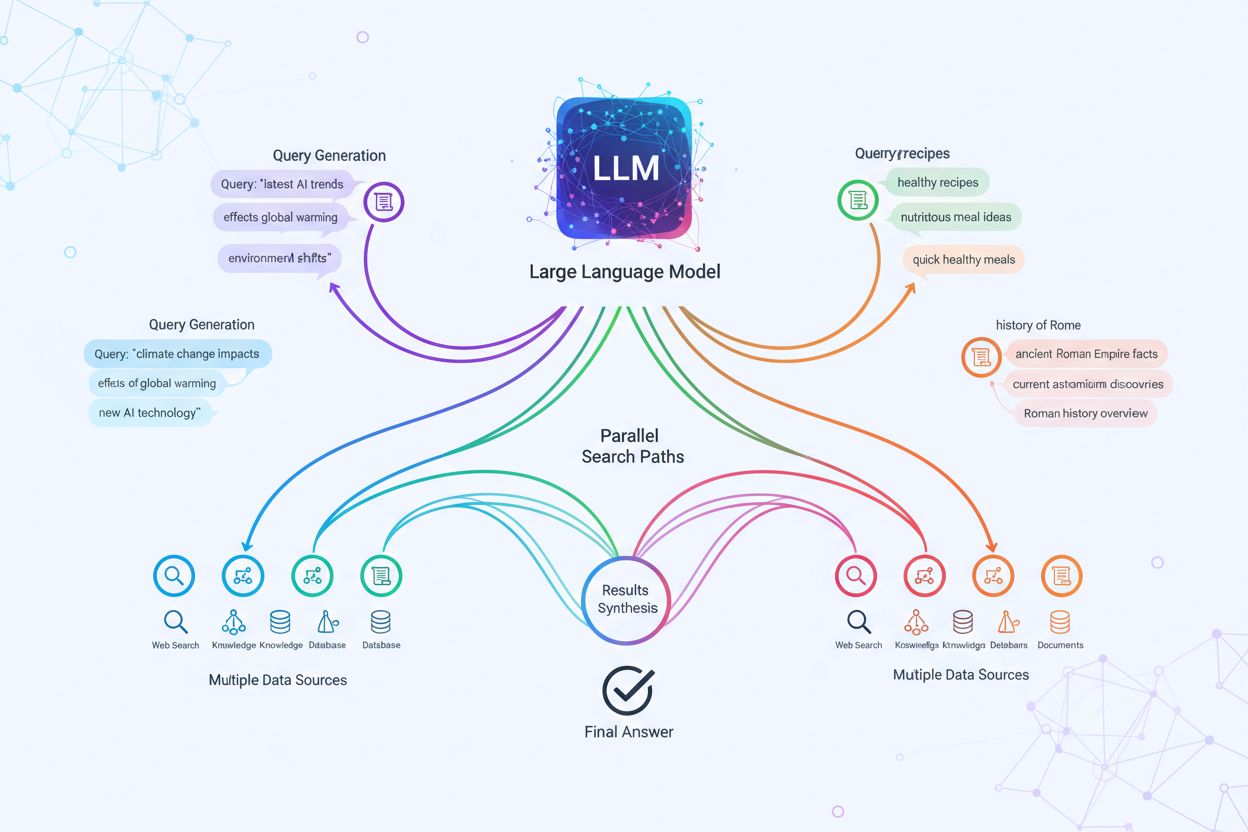
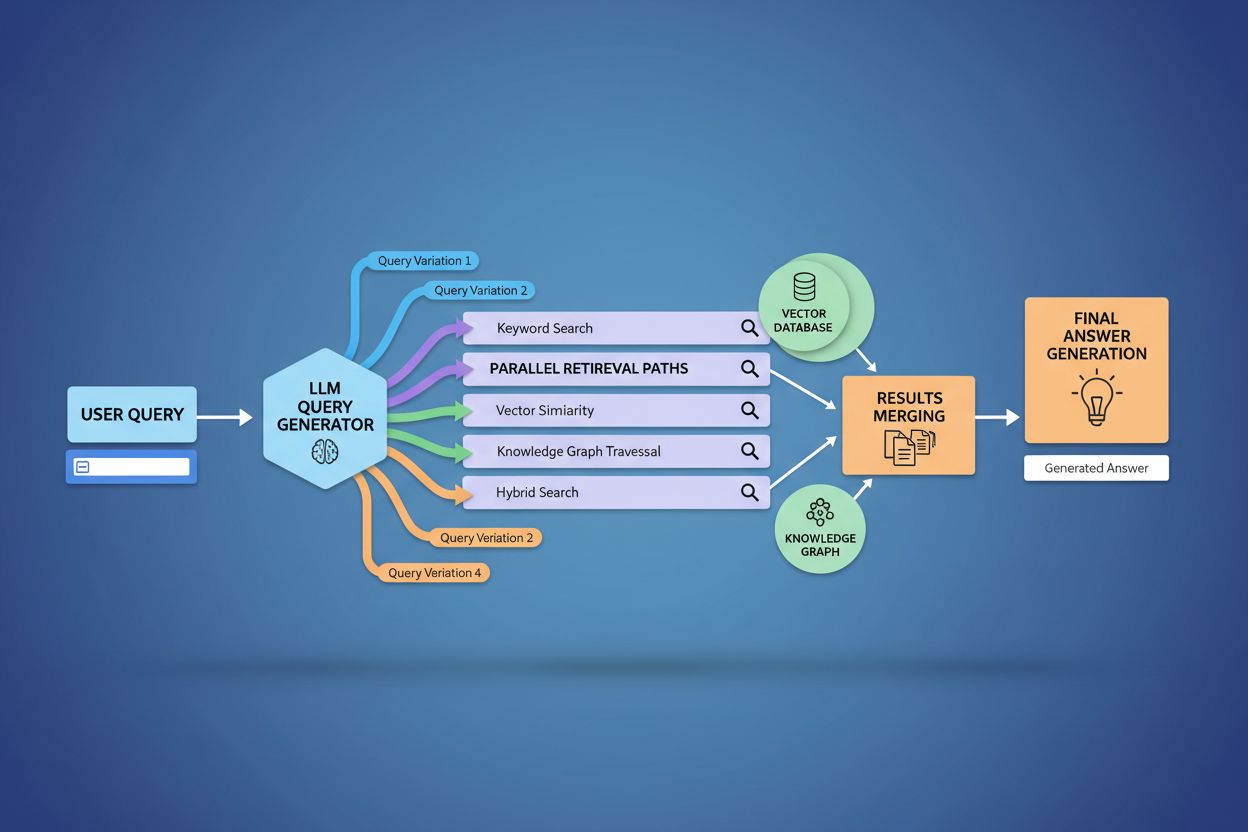
Techniczna realizacja query fanout opiera się na zaawansowanych algorytmach NLP, które analizują złożoność zapytania i generują semantycznie znaczące warianty. LLM-y tworzą osiem głównych typów wariantów zapytań: zapytania równoważne (przeformułowanie o tym samym znaczeniu), zapytania doprecyzowujące (eksploracja powiązanych tematów), zapytania generalizujące (poszerzające zakres), zapytania specyfikujące (zawężające zakres), zapytania kanonizujące (standaryzujące terminologię), zapytania translacyjne (przenoszące między domenami), zapytania implikujące (badanie logicznych powiązań) oraz zapytania wyjaśniające (usuwające niejednoznaczności). System wykorzystuje modele językowe do oceny złożoności zapytania — analizując takie czynniki jak liczba encji, gęstość relacji czy niejednoznaczność semantyczna — by określić, ile podzapytań wygenerować. Po wygenerowaniu zapytania te są wykonywane równolegle w różnych systemach pobierania, w tym przez web crawlery, grafy wiedzy (np. Google Knowledge Graph), bazy danych i indeksy podobieństwa wektorowego. Różne platformy implementują tę architekturę z różną przejrzystością i stopniem zaawansowania:
| Platforma | Mechanizm | Przejrzystość | Liczba zapytań | Metoda rankingowa |
|---|---|---|---|---|
| Google AI Mode | Jawny fanout z widocznymi zapytaniami | Wysoka | 8-12 zapytań | Ranking wieloetapowy |
| Microsoft Copilot | Iteracyjny Bing Orchestrator | Średnia | 5-8 zapytań | Ocena trafności |
| Perplexity | Hybrydowy retrieval z wieloetapowym rankingiem | Wysoka | 6-10 zapytań | Oparta o cytowania |
| ChatGPT | Ukryte generowanie zapytań | Niska | Nieznana | Wewnętrzne ważenie |
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Złożone zapytania są zaawansowanie rozkładane przez system, który dzieli je na poszczególne encje, atrybuty i relacje przed wygenerowaniem wariantów. Przetwarzając zapytanie takie jak „słuchawki Bluetooth z wygodną wokółuszną konstrukcją i długą żywotnością baterii odpowiednie dla biegaczy”, system dokonuje rozpoznania encji (słuchawki Bluetooth, biegacze) oraz wyodrębnia kluczowe atrybuty (wygodne, wokółuszne, długi czas pracy na baterii). Proces rozkładu wykorzystuje grafy wiedzy do zrozumienia, jak te encje są powiązane i jakie istnieją wariacje semantyczne — rozpoznając, że „słuchawki wokółuszne” i „słuchawki circumauralne” są równoważne, a „długa żywotność baterii” może oznaczać zarówno 8+, 24+ godzin, jak i kilkudniową pracę w zależności od kontekstu. System identyfikuje powiązane pojęcia za pomocą miar podobieństwa semantycznego, rozumiejąc, że zapytania o „odporność na pot” i „odporność na wodę” są pokrewne, ale różne, a „biegacze” mogą interesować się także „kolarzami”, „bywalcami siłowni” lub „sportowcami outdoorowymi”. Taki rozkład umożliwia generowanie ukierunkowanych podzapytań, które oddają różne aspekty intencji użytkownika, a nie tylko parafrazują oryginalną prośbę.
Query fanout fundamentalnie wzmacnia komponent pobierania w ramach Retrieval-Augmented Generation (RAG), umożliwiając bogatsze i bardziej zróżnicowane pozyskiwanie dowodów przed fazą generowania. W tradycyjnych pipeline’ach RAG pojedyncze zapytanie jest embedowane i dopasowywane do bazy wektorowej, przez co można pominąć istotne informacje używające innej terminologii czy konceptualizacji. Query fanout rozwiązuje ten problem, wykonując wiele operacji pobierania równolegle, każdą zoptymalizowaną pod konkretny wariant zapytania, co łącznie pozwala zebrać dowody z różnych perspektyw i źródeł. Ta strategia znacząco zmniejsza ryzyko halucynacji, bo odpowiedzi LLM są osadzone w wielu niezależnych źródłach — gdy system pobiera informacje oddzielnie o „słuchawkach wokółusznych”, „konstrukcji circumauralnej” i „słuchawkach pełnowymiarowych”, może porównywać i weryfikować twierdzenia na podstawie tych różnorodnych wyników. Architektura wykorzystuje semantyczne chunking oraz retrieval oparty na fragmentach, gdzie dokumenty dzielone są na znaczące jednostki semantyczne zamiast na fragmenty o stałej długości, dzięki czemu system pobiera najbardziej istotne fragmenty niezależnie od struktury dokumentu. Łącząc dowody z wielu podzapytań, systemy RAG generują odpowiedzi bardziej kompleksowe, lepiej udokumentowane i mniej podatne na pewne, lecz błędne odpowiedzi typowe dla podejścia pojedynczego zapytania.
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Kontekst użytkownika i sygnały personalizacyjne dynamicznie kształtują, jak query fanout rozszerza indywidualne zapytania, tworząc spersonalizowane ścieżki pobierania, które mogą znacząco się różnić między użytkownikami. System uwzględnia wiele wymiarów personalizacji, w tym atrybuty użytkownika (lokalizacja geograficzna, profil demograficzny, rola zawodowa), wzorce historii wyszukiwania (poprzednie zapytania i kliknięcia), sygnały czasowe (pora dnia, sezon, bieżące wydarzenia) i kontekst zadania (czy użytkownik bada, kupuje, czy się uczy). Na przykład zapytanie „najlepsze słuchawki dla biegaczy” zostanie rozszerzone inaczej dla 22-letniego ultramaratończyka z Kenii niż dla 45-letniego rekreacyjnego biegacza z Minnesoty — dla pierwszego nacisk może być na trwałość i odporność na upał, dla drugiego na wygodę i dostępność. Jednak taka personalizacja wprowadza problem „transformacji dwupunktowej”, gdzie system traktuje bieżące zapytania jako wariacje historycznych wzorców, co może ograniczać eksplorację i wzmacniać istniejące preferencje. Personalizacja może niezamierzenie tworzyć bańki filtrujące, gdzie rozbudowa zapytań systematycznie faworyzuje źródła i perspektywy zgodne z dotychczasowym zachowaniem użytkownika, ograniczając dostęp do alternatywnych punktów widzenia czy nowych informacji. Zrozumienie tych mechanizmów personalizacji jest kluczowe dla twórców treści, bo te same materiały mogą być pobierane lub pomijane w zależności od profilu i historii użytkownika.
Główne platformy AI wdrażają query fanout z odmiennymi architekturami, poziomem przejrzystości i podejściami strategicznymi, odzwierciedlającymi ich infrastrukturę i filozofię projektową. Google AI Mode stosuje jawny, widoczny query fanout, w którym użytkownicy widzą 8-12 wygenerowanych podzapytań wyświetlanych obok wyników, uruchamiając setki indywidualnych wyszukiwań w indeksie Google w celu zebrania kompletnych danych. Microsoft Copilot używa podejścia iteracyjnego, opartego na Bing Orchestrator, który generuje 5-8 zapytań sekwencyjnie, usprawniając zestaw na podstawie wyników pośrednich przed finalną fazą pobierania. Perplexity wdraża strategię hybrydową z wieloetapowym rankingiem, generując 6-10 zapytań uruchamianych zarówno wobec źródeł internetowych, jak i własnego indeksu, następnie stosuje zaawansowane algorytmy rankingowe do wyłonienia najtrafniejszych fragmentów. Podejście ChatGPT pozostaje w większości nieprzejrzyste dla użytkownika — generowanie zapytań odbywa się niejawnie w wewnętrznym procesie modelu, przez co trudno stwierdzić, ile zapytań jest generowanych i jak są wykonywane. Te różnice architektoniczne mają duże znaczenie dla przejrzystości, powtarzalności i możliwości optymalizacji treści pod kątem każdej platformy:
| Aspekt | Google AI Mode | Microsoft Copilot | Perplexity | ChatGPT |
|---|---|---|---|---|
| Widoczność zapytań | Całkowicie widoczne dla użytkownika | Częściowo widoczne | Widoczne w cytowaniach | Ukryte |
| Model wykonania | Równoległa paczka | Sekwencyjne iteracyjne | Równoległe z rankingiem | Wewnętrzne/implicitne |
| Różnorodność źródeł | Tylko indeks Google | Bing + własne | Web + własny indeks | Dane treningowe + wtyczki |
| Przejrzystość cytowania | Wysoka | Średnia | Bardzo wysoka | Niska |
| Opcje dostosowania | Ograniczone | Średnie | Wysokie | Średnie |
Query fanout wprowadza szereg technicznych i semantycznych wyzwań, które mogą sprawić, że system odejdzie od rzeczywistej intencji użytkownika, pobierając wprawdzie powiązane, ale ostatecznie nieprzydatne informacje. Dryf semantyczny następuje podczas generatywnego rozszerzania, gdy LLM tworzy warianty zapytań, które choć semantycznie powiązane z oryginałem, stopniowo zmieniają znaczenie — zapytanie o „najlepsze słuchawki dla biegaczy” może rozszerzyć się na „słuchawki sportowe”, następnie „sprzęt sportowy”, a potem „akcesoria fitness”, oddalając się od pierwotnej intencji. System musi odróżniać intencję ukrytą (czego użytkownik mógłby chcieć, gdyby wiedział więcej) od intencji jawnej (o co faktycznie poprosił), a zbyt agresywna rozbudowa zapytań może te kategorie pomylić, pobierając informacje o produktach, których użytkownik wcale nie miał na myśli. Dywergencja ekspansji iteracyjnej pojawia się, gdy każde podzapytanie generuje kolejne podzapytania, tworząc drzewo coraz bardziej odległych wyszukiwań, które ostatecznie pobierają dane niepowiązane z pierwotną prośbą. Bańki filtrujące i bias personalizacyjny sprawiają, że dwóch użytkowników zadających identyczne pytania otrzymuje systematycznie różne ekspansje w zależności od profilu, co może prowadzić do powstawania echo chamberów, w których rozszerzenie zapytań wzmacnia dotychczasowe preferencje. Przykłady z życia: użytkownik szukający „tanie słuchawki” może mieć zapytanie rozszerzone o marki luksusowe na podstawie historii przeglądania, a zapytanie o „słuchawki dla niedosłyszących” może zostać rozszerzone na ogólne produkty dostępnościowe, rozmywając pierwotną specyfikę.
Pojawienie się query fanout fundamentalnie zmienia strategię treści z optymalizacji pod ranking słów kluczowych na widoczność opartą o cytowania, co wymusza na twórcach treści przemyślenie sposobu strukturyzowania i prezentowania informacji. Tradyczne SEO skupiało się na pozycjonowaniu pod konkretne słowa kluczowe; wyszukiwanie napędzane przez AI stawia na cytowanie jako autorytatywnego źródła w wielu wariantach zapytań i kontekstach. Twórcy powinni przyjąć strategie treści atomowych, bogatych w encje, gdzie informacje są zorganizowane wokół konkretnych bytów (produkty, pojęcia, osoby) z rozbudowanymi znacznikami semantycznymi, co pozwala systemom AI wyodrębniać i cytować odpowiednie fragmenty. Kluczowe stają się klastrowanie tematyczne i autorytet tematyczny — zamiast tworzyć pojedyncze artykuły pod konkretne słowa, skuteczna treść zapewnia pełne pokrycie obszarów tematycznych, zwiększając szansę na pobranie w różnych wariantach zapytań generowanych przez fanout. Wdrożenie znaczników schema i danych strukturalnych pozwala AI lepiej rozumieć układ treści i skuteczniej wyodrębniać odpowiednie informacje, zwiększając szansę na cytowanie. Mierniki sukcesu przesuwają się z monitorowania pozycji słów kluczowych na śledzenie częstotliwości cytowań poprzez narzędzia takie jak AmICited.com, które zlicza, jak często marka i treści pojawiają się w odpowiedziach generowanych przez AI. Praktyczne zalecenia obejmują: tworzenie wyczerpujących, dobrze udokumentowanych treści poruszających różne aspekty danego zagadnienia; wdrażanie bogatych znaczników schema (Organization, Product, Article); budowanie autorytetu tematycznego przez powiązanie treści; oraz regularny audyt pojawiania się treści w odpowiedziach AI na różnych platformach i segmentach użytkowników.
Query fanout to najważniejsza zmiana architektoniczna w wyszukiwaniu od czasu indeksowania mobile-first, fundamentalnie przebudowująca sposób odkrywania i prezentowania informacji użytkownikom. Ewolucja w kierunku infrastruktury semantycznej oznacza, że systemy wyszukiwania będą coraz częściej działać na poziomie znaczenia, a nie słów kluczowych, a query fanout stanie się domyślnym mechanizmem pobierania informacji zamiast opcjonalnym rozszerzeniem. Metryki cytowań stają się równie ważne jak backlinki w określaniu widoczności i autorytetu treści — materiał cytowany w 50 różnych odpowiedziach AI ma większą wagę niż treść na 1. miejscu dla pojedynczego słowa kluczowego. Ta zmiana to zarówno wyzwania, jak i szanse: tradycyjne narzędzia SEO śledzące rankingi słów kluczowych tracą na znaczeniu, konieczne są nowe metody pomiaru skupione na częstotliwości cytowań, różnorodności źródeł i widoczności w różnych wariantach zapytań. Jednocześnie daje to markom możliwość optymalizacji właśnie pod AI, przez budowę autorytatywnych, dobrze ustrukturyzowanych treści będących wiarygodnym źródłem w wielu interpretacjach zapytań. Przyszłość najpewniej przyniesie większą przejrzystość mechanizmów query fanout, gdzie platformy będą konkurować poziomem wyjaśniania użytkownikom logiki wielozapytaniowej, a twórcy treści rozwiną specjalistyczne strategie maksymalizowania widoczności na różnych ścieżkach pobierania, które ten mechanizm generuje.
Zrozum, jak Twoja marka pojawia się w platformach wyszukiwania AI, gdy zapytania są rozszerzane i rozbijane. Śledź cytowania oraz wzmianki w odpowiedziach generowanych przez AI.
Dowiedz się, jak działa rozwinięcie zapytania w systemach wyszukiwania AI. Odkryj, jak AI rozszerza pojedyncze zapytania na wiele podzapytań, by poprawić trafno...
Dowiedz się, jak duże modele językowe interpretują intencję użytkownika poza słowami kluczowymi. Poznaj rozszerzanie zapytań, rozumienie semantyczne oraz jak sy...
Dowiedz się, jak antycypacja zapytań pomaga Twoim treściom wychwytywać rozszerzone rozmowy AI poprzez odpowiadanie na pytania uzupełniające. Poznaj strategie id...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.