
PerplexityBot: Čo by mal vedieť každý vlastník webu
Kompletný sprievodca robotom PerplexityBot – pochopte, ako funguje, spravujte jeho prístup, sledujte citácie a optimalizujte viditeľnosť pre Perplexity AI. Zist...
8 min čítania

Zistite, ako stealth crawlery obchádzajú príkazy robots.txt, aké technické mechanizmy využívajú na vyhýbanie sa detekcii a aké sú možnosti ochrany vášho obsahu pred neoprávneným AI scrapovaním.
Webové prehľadávanie sa s nástupom systémov umelej inteligencie zásadne zmenilo. Na rozdiel od tradičných vyhľadávačov, ktoré rešpektujú zaužívané protokoly, niektoré AI firmy začali používať stealth crawling—zámerné maskovanie aktivity ich botov, aby obišli obmedzenia webových stránok a príkazy v robots.txt. Táto prax predstavuje významný odklon od spolupráce, ktorá definovala web crawling takmer tri desaťročia, a nastoľuje zásadné otázky o vlastníctve obsahu, dátovej etike a budúcnosti otvoreného internetu.

Najvýraznejším príkladom je Perplexity AI, AI odpovedací engine, ktorý bol prichytený pri použití nedeclarovaných crawlerov na prístup k obsahu výslovne blokovanému vlastníkmi stránok. Vyšetrovanie spoločnosti Cloudflare ukázalo, že Perplexity prevádzkuje deklarované crawlery (ktoré sa poctivo identifikujú) aj stealth crawlery (ktoré sa vydávajú za bežné webové prehliadače), aby obišiel pokusy o blokovanie. Táto dvojcestná stratégia umožňuje Perplexity získavať obsah aj vtedy, keď webstránky výslovne zakazujú prístup cez súbory robots.txt a firewall pravidlá.
Súbor robots.txt je od roku 1994, kedy bol predstavený v rámci Robots Exclusion Protocolu, hlavným mechanizmom na správu crawlerov na internete. Tento jednoduchý textový súbor umiestnený v koreňovom adresári webu obsahuje príkazy, ktoré určujú, ktoré časti stránky môžu a nemôžu crawlery navštíviť. Typický zápis v robots.txt môže vyzerať takto:
User-agent: GPTBot
Disallow: /
Tento príkaz hovorí crawleru GPTBot od OpenAI, aby neprechádzal žiadny obsah stránky. Robots.txt je však postavený na základnom princípe: je úplne dobrovoľný. Príkazy v súbore robots.txt nemajú žiadny donucovací mechanizmus; je na crawleri, či ich bude rešpektovať. Zatiaľ čo Googlebot a iné rešpektované crawlery tieto príkazy dodržujú, protokol nevymáha ich dodržiavanie. Crawler môže jednoducho robots.txt ignorovať a technicky mu v tom nemožno zabrániť.
| Crawler | Deklarovaný user agent | Rešpektuje robots.txt | Status dodržiavania |
|---|---|---|---|
| GPTBot (OpenAI) | Mozilla/5.0 (compatible; GPTBot/1.0) | Áno | Vyhovuje |
| ChatGPT-User | Mozilla/5.0 (compatible; ChatGPT-User/1.0) | Áno | Vyhovuje |
| ClaudeBot (Anthropic) | Mozilla/5.0 (compatible; Claude-Web/1.0) | Áno | Vyhovuje |
| Google-Extended | Mozilla/5.0 (compatible; Google-Extended/1.0) | Áno | Vyhovuje |
| Perplexity-User | Mozilla/5.0 (compatible; Perplexity-User/1.0) | Nie | Nevhodné |
| Nedeclarovaný stealth crawler | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) Chrome/124.0.0.0 | Nie | Stealth/Vyhybavý |
Rozdiel medzi slušnými a nečestnými crawlermi je čoraz dôležitejší. Rešpektované AI firmy ako OpenAI a Anthropic zverejňujú svoje IP rozsahy, poskytujú transparentnú dokumentáciu a rešpektujú preferencie vlastníkov stránok. Oproti tomu stealth crawlery zámerne skrývajú svoju identitu a ignorujú príkazy stránok, pričom robots.txt vnímajú ako prekážku, ktorú je potrebné prekonať, nie ako smernicu.
Podrobné vyšetrovanie správania crawlerov Perplexity od Cloudflare poskytuje doteraz najkomplexnejšiu dokumentáciu o stealth crawlingových taktikách. Výskumný tím vytvoril viacero testovacích domén s jasnými príkazmi v robots.txt zakazujúcimi akýkoľvek automatizovaný prístup. Napriek týmto jasným obmedzeniam Perplexity ďalej poskytoval detailné informácie o obsahu testovacích domén pri dopytoch cez svoje AI rozhranie.
Vyšetrovanie odhalilo sofistikovanú dvojprúdovú crawlingovú stratégiu. Deklarovaný crawler Perplexity (Perplexity-User) realizuje 20-25 miliónov požiadaviek denne a poctivo sa identifikuje. Ak však tento deklarovaný crawler narazí na blokovanie alebo obmedzenie v robots.txt, Perplexity nasadí nedeclarovaný stealth crawler, ktorý vykonáva ďalších 3-6 miliónov požiadaviek denne a vydáva sa za legitímny prehliadač Chrome na macOS. Tento stealth variant používa generický user agent reťazec: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36.
Stealth crawler využíva viacero techník na vyhýbanie sa detekcii naraz. Rotuje IP adresy, ktoré nie sú uvedené v oficiálnej dokumentácii Perplexity, takže vlastníci stránok nemôžu blokovať na základe známej infraštruktúry Perplexity. Okrem toho mení zdrojové ASNs (identifikátory poskytovateľov siete), čím ešte viac maskuje svoj pôvod. Táto aktivita bola pozorovaná na desiatkach tisíc domén, pričom generovala milióny požiadaviek denne.
Na ostrý kontrast, keď Cloudflare vykonal identické testy s ChatGPT, pozorovali zásadne iné správanie. ChatGPT-User načítal súbor robots.txt, rozpoznal príkaz na zákaz a okamžite ukončil crawling. Pri blokovaní na úrovni siete ChatGPT neurobil žiadne ďalšie pokusy z iných user agentov alebo IP adries. To dokazuje, že dodržiavanie pravidiel je technicky možné a firmy, ktoré robots.txt ignorujú, tak robia na základe vedomého obchodného rozhodnutia, nie kvôli technickým limitáciám.
Stealth crawlery používajú sofistikovaný arzenál techník na vyhýbanie sa detekcii a obchádzanie obmedzení webových stránok. Porozumenie týmto mechanizmom je kľúčom k vývoju efektívnych opatrení:
User Agent Spoofing: Crawlery sa vydávajú za legitímne prehliadače použitím realistických user agent reťazcov zodpovedajúcich skutočným prehliadačom Chrome, Safari či Firefox. Na prvý pohľad sú tak na nerozoznanie od ľudských návštevníkov.
Rotácia IP adries a proxy siete: Namiesto crawlovania z jednej IP alebo známeho dátového centra, stealth crawlery rozdeľujú požiadavky cez stovky až tisíce rôznych IP adries, často využívajú rezidenčné proxy siete, ktoré smerujú prevádzku cez skutočné domáce internetové pripojenia.
Rotácia ASN: Zmenou ASN (identifikátora poskytovateľa internetu) crawlery vyzerajú, že pochádzajú od rôznych providerov, čím znemožňujú blokovanie podľa IP.
Simulácia headless prehliadačov: Moderné stealth crawlery používajú skutočné prehliadačové enginy (Chrome Headless, Puppeteer, Playwright), ktoré vykonávajú JavaScript, ukladajú cookies a simulujú reálne interakcie (pohyby myši, náhodné oneskorenia).
Manipulácia rýchlosti: Namiesto rýchlych sekvenčných požiadaviek, ktoré vyvolávajú detekciu, crawlery zavádzajú variabilné oneskorenia medzi požiadavkami a napodobňujú prirodzené ľudské prehliadanie.
Randomizácia fingerprintu: Crawlery menia prehliadačové fingerprinty—charakteristiky ako rozlíšenie obrazovky, časové pásmo, nainštalované fonty či podpisy TLS handshake—aby sa vyhli detekcii systémami device fingerprintingu.
Tieto techniky sa kombinujú do viacvrstvovej stratégie, ktorá prekonáva tradičné metódy detekcie. Crawler môže naraz použiť sfalšovaný user agent, rotáciu cez rezidenčné proxy, náhodné oneskorenia a randomizovaný fingerprint, vďaka čomu je prakticky nerozpoznateľný od legitímnej návštevnosti.
Rozhodnutie nasadiť stealth crawlery je v zásade poháňané hladom po dátach. Tréning špičkových jazykových modelov vyžaduje obrovské množstvá kvalitných textových dát. Najhodnotnejší obsah—odborný výskum, platené články, exkluzívne diskusie či špecializované databázy—je často výslovne obmedzený vlastníkmi stránok. Firmy tak stoja pred voľbou: rešpektovať preferencie stránok a uspokojiť sa s menej kvalitnými dátami, alebo obísť obmedzenia a získať prémiový obsah.
Konkurenčný tlak je obrovský. AI firmy investujúce miliardy do vývoja modelov veria, že lepšie trénovacie dáta znamenajú lepšie modely a tým aj trhovú výhodu. Ak sú konkurenti ochotní scrapovať obmedzený obsah, rešpektovanie robots.txt znamená konkurenčnú nevýhodu. Vzniká tak špirála, kde je etické správanie trhom “trestané”.
Okrem toho prakticky neexistujú vymáhacie mechanizmy. Vlastníci stránok technicky nemôžu zabrániť odhodlanému crawleru v prístupe k obsahu. Právne postupy sú pomalé, drahé a neisté. Ak stránka nepodnikne formálne právne kroky—čo si väčšina organizácií nemôže dovoliť—nečestný crawler nemá žiadne bezprostredné následky. Riziko ignorovania robots.txt je tak minimálne oproti potenciálnemu zisku.
Právna situácia je navyše nejasná. Porušenie robots.txt síce môže znamenať porušenie podmienok používania, ale legálny status scrapovania verejne dostupných dát sa líši podľa jurisdikcie. Niektoré súdy rozhodli, že scrapovanie verejných dát je legálne, iné to považujú za porušenie zákona o počítačových podvodoch a zneužití. Táto neistota povzbudzuje firmy pohybujúce sa v šedej zóne.
Dôsledky stealth crawlingu idú ďaleko za technické nepríjemnosti. Reddit zistil, že jeho používateľský obsah slúži na tréning AI modelov bez povolenia a kompenzácie. Platforma v reakcii dramaticky zvýšila ceny API špeciálne pre AI firmy, pričom CEO Steve Huffman výslovne spomenul Microsoft, OpenAI, Anthropic a Perplexity za „používanie dát Redditu zadarmo“.
Twitter/X zvolil ešte agresívnejší prístup, dočasne zablokoval prístup k tweetom bez prihlásenia a zaviedol prísne limity aj pre prihlásených používateľov. Elon Musk výslovne uviedol, že išlo o núdzové opatrenie na zastavenie „stoviek organizácií“ scrapujúcich Twitter, čo zhoršovalo používateľský zážitok a zaťažovalo servery.
Spravodajské vydavateľstvá sú obzvlášť hlasné v tejto téme. The New York Times, CNN, Reuters a The Guardian aktualizovali svoje robots.txt, aby zablokovali GPTBot od OpenAI. Niektoré vydavateľstvá pristúpili k právnym krokom, New York Times dokonca podal žalobu na OpenAI za porušenie autorských práv. Associated Press zvolil iný postup, dohodol si licenciu s OpenAI výmenou za prístup k technológii – vôbec prvé komerčné partnerstvo tohto typu.
Stack Overflow zažil koordinované scrapovacie útoky, pri ktorých útočníci vytvorili tisíce účtov a používali sofistikované techniky na maskovanie sa medzi legitímnych používateľov pri zbere kódov. Inžiniersky tím platformy zdokumentoval, ako scrapery používajú identické TLS fingerprinty na mnohých spojeniach, udržiavajú perzistentné relácie a dokonca platia za prémiové účty, aby sa vyhli detekcii.
Spoločným menovateľom vo všetkých týchto prípadoch je strata kontroly. Tvorcovia obsahu už nemajú možnosť rozhodnúť, ako sa ich dielo využíva, kto z neho profituje, alebo či dostanú kompenzáciu. Ide o zásadnú zmenu v mocenskej dynamike internetu.
Našťastie, organizácie vyvíjajú sofistikované nástroje na detekciu a blokovanie stealth crawlerov. Cloudflare’s AI Crawl Control (predtým AI Audit) poskytuje prehľad o tom, ktoré AI služby pristupujú k vášmu obsahu a či rešpektujú vaše pravidlá robots.txt. Nová funkcia platformy Robotcop ide ešte ďalej – automaticky prekladá príkazy robots.txt do pravidiel Web Application Firewallu (WAF), ktoré vymáhajú súlad na úrovni siete.
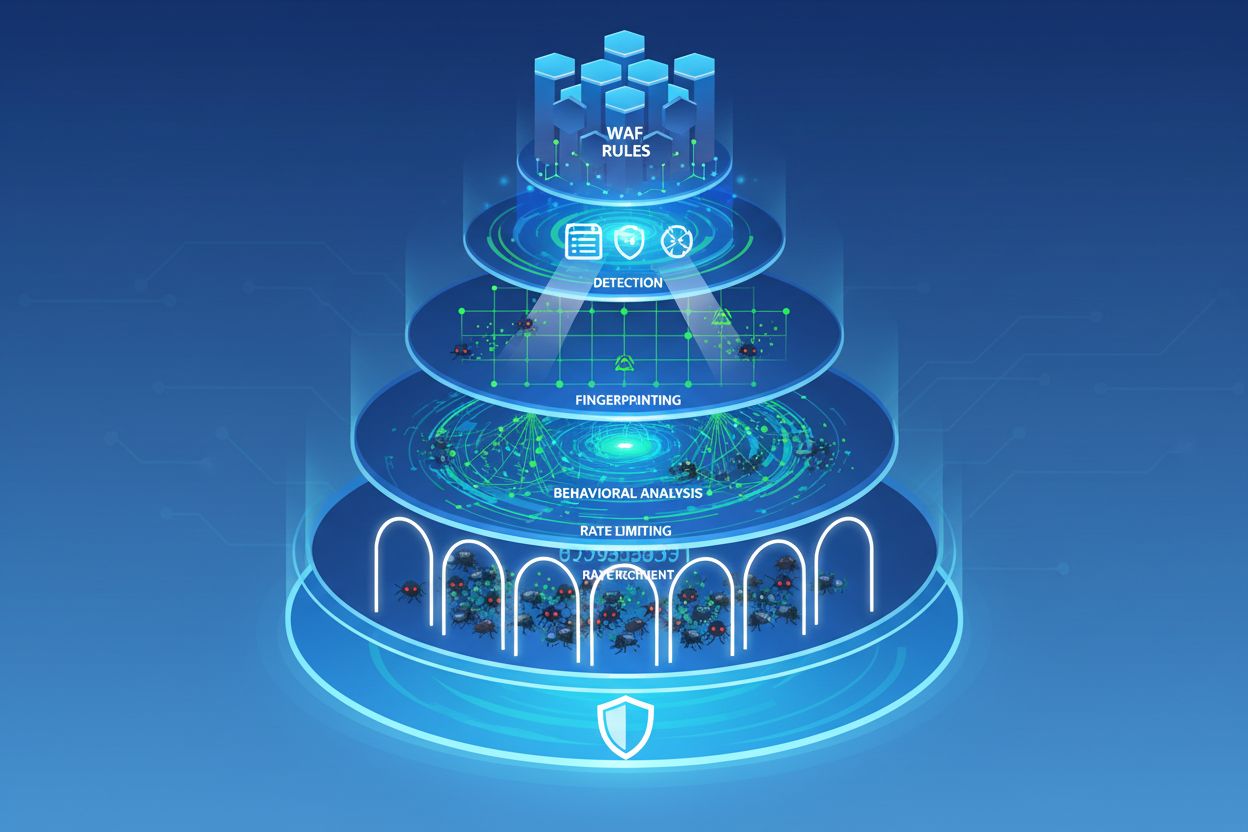
Device fingerprinting predstavuje silnú detekčnú techniku. Analýzou desiatok signálov—verzia prehliadača, rozlíšenie obrazovky, operačný systém, nainštalované fonty, podpisy TLS handshake a behaviorálne vzorce—môžu bezpečnostné systémy odhaliť nezrovnalosti signalizujúce botov. Crawler vydávajúci sa za Chrome na macOS môže mať TLS fingerprint, ktorý nezodpovedá skutočnému Chromu, alebo mu môžu chýbať niektoré API, ktoré reálne prehliadače poskytujú.
Behaviorálna analýza skúma, ako návštevníci interagujú so stránkou. Reálni používatelia sa správajú prirodzene: čítajú obsah, logicky navigujú, robia chyby a opravujú ich. Boti často vykazujú typické znaky: pristupujú k stránkam v neprirodzených sekvenciách, načítavajú zdroje v nezvyčajnom poradí, nikdy neklikajú na interaktívne prvky alebo pristupujú k stránkam nemožnou rýchlosťou.
Rate limiting zostáva efektívny v kombinácii s inými technikami. Zavedením prísnych limitov na počet požiadaviek podľa IP, relácie alebo účtu možno scrapery výrazne spomaliť. Exponenciálne oneskorenia—kde každé porušenie zvyšuje čakaciu dobu—ďalej odrádzajú automatizované útoky.
AmICited rieši zásadnú medzeru v súčasnej situácii: prehľad o tom, ktoré AI systémy skutočne citujú vašu značku a obsah. Zatiaľ čo nástroje ako Cloudflare’s AI Crawl Control zobrazujú, ktoré crawlery pristupujú na váš web, AmICited ide ďalej a sleduje, ktoré AI systémy—ChatGPT, Perplexity, Google Gemini, Claude a ďalšie—v skutočnosti referencujú váš obsah vo svojich odpovediach.
Tento rozdiel je kľúčový. To, že crawler pristupuje na váš web, ešte neznamená, že váš obsah bude citovaný. Naopak, váš obsah môže byť citovaný AI systémami, ktoré ho získali nepriamo (napríklad z datasetov Common Crawl) a nie priamym crawlingom. AmICited poskytuje chýbajúci článok: dôkaz, že váš obsah je skutočne využívaný AI systémami, spolu s detailnými informáciami o spôsobe citácie.
Platforma identifikuje stealth crawlery pristupujúce k vášmu obsahu analýzou vzorcov návštevnosti, user agentov a behaviorálnych signálov. Keď AmICited deteguje podozrivú crawler aktivitu—najmä nedeclarované crawlery so sfalšovanými user agentmi—označí ich ako možné stealth crawlingové pokusy. To umožňuje vlastníkom stránok reagovať na nevyhovujúce crawlery a zároveň si zachovať prehľad o legitímnom AI prístupe.
Upozornenia v reálnom čase vás informujú o detekcii stealth crawlerov, čo umožňuje rýchlu reakciu. Integrácia s existujúcimi SEO a bezpečnostnými workflowmi znamená, že dáta z AmICited môžete začleniť do celej obsahovej a bezpečnostnej stratégie. Pre organizácie, ktoré sa obávajú využívania svojho obsahu v ére AI, je AmICited nevyhnutným zdrojom informácií.
Ochrana obsahu pred stealth crawlermi si vyžaduje viacvrstvový prístup:
Zaveďte jasné pravidlá v robots.txt: Aj keď stealth crawlery môžu robots.txt ignorovať, tie slušné ho budú rešpektovať. Výslovne zakážte crawlery, ktoré nechcete na svojom webe. Pridajte pravidlá pre známe AI crawlery ako GPTBot, ClaudeBot či Google-Extended.
Nasadzujte WAF pravidlá: Využívajte pravidlá Web Application Firewallu na vynucovanie pravidiel robots.txt na úrovni siete. Nástroje ako Cloudflare Robotcop dokážu tieto pravidlá automaticky generovať zo súboru robots.txt.
Pravidelne monitorujte správanie crawlerov: Používajte nástroje ako AmICited a Cloudflare’s AI Crawl Control na sledovanie, ktoré crawlery pristupujú na váš web a či rešpektujú vaše pravidlá. Pravidelný monitoring umožní rýchlu identifikáciu stealth crawlerov.
Nasadzujte device fingerprinting: Využívajte riešenia device fingerprintingu, ktoré analyzujú prehliadačové charakteristiky a správanie, aby odhalili botov maskujúcich sa za ľudí.
Zvážte autentifikáciu pre citlivý obsah: Pre najcennejší obsah zvážte povinnú autentifikáciu alebo paywall. Tak zabezpečíte, že sa k obmedzenému materiálu nedostanú ani legitímne, ani stealth crawlery.
Buďte informovaní o nových taktikách crawlerov: Taktiky vyhýbania sa detekcii sa neustále vyvíjajú. Sledujte bezpečnostné novinky, výskum a pravidelne aktualizujte svoju obranu.
Súčasný stav—kedy niektoré AI firmy otvorene ignorujú robots.txt, kým iné ho rešpektujú—nie je dlhodobo udržateľný. Už teraz sa objavujú priemyselné i regulačné reakcie. Internet Engineering Task Force (IETF) pracuje na rozšíreniach špecifikácie robots.txt, ktoré umožnia detailnejšiu kontrolu nad AI tréningom a využívaním dát. Tieto rozšírenia umožnia vlastníkom stránok určovať rôzne politiky pre vyhľadávače, AI tréning či iné účely.
Web Bot Auth, novo navrhovaný otvorený štandard, umožňuje crawlerom kryptograficky podpisovať svoje požiadavky a dokázať tak svoju identitu a legitímnosť. Agent ChatGPT od OpenAI už tento štandard implementuje, čo dokazuje, že transparentná a overiteľná identifikácia crawlerov je technicky možná.
Regulačné zmeny sú pravdepodobné aj v blízkej budúcnosti. Prístup Európskej únie k regulácii AI v kombinácii s rastúcim tlakom zo strany tvorcov obsahu a vydavateľov naznačuje, že budúce predpisy môžu právne vyžadovať dodržiavanie robots.txt. Firmy ignorujúce robots.txt tak môžu čeliť nielen reputačným, ale aj regulačným postihom.
Priemysel sa posúva k modelu, kde transparentnosť a dodržiavanie pravidiel sa stávajú konkurenčnou výhodou. Firmy, ktoré rešpektujú preferencie vlastníkov stránok, jasne identifikujú svoje crawlery a prinášajú hodnotu tvorcom obsahu, si budujú dôveru a udržateľné vzťahy. Tí, ktorí sa spoliehajú na stealth taktiky, čelia rastúcim technickým, právnym a reputačným rizikám.
Pre vlastníkov stránok je odkaz jasný: proaktívny monitoring a vymáhanie pravidiel sú nevyhnutné. Zavedením vyššie uvedených nástrojov a postupov môžete udržať kontrolu nad tým, ako je váš obsah využívaný v ére AI a zároveň podporovať rozvoj zodpovedných AI systémov, ktoré rešpektujú základné princípy otvoreného internetu.
Stealth crawler zámerne maskuje svoju identitu tým, že sa vydáva za legitímne webové prehliadače a skrýva svoj skutočný pôvod. Na rozdiel od bežných crawlerov, ktoré sa identifikujú jedinečnými user agentmi a rešpektujú príkazy robots.txt, stealth crawlery používajú sfalšované user agenty, rotujú IP adresy a využívajú techniky vyhýbania sa detekcii, aby obišli obmedzenia webových stránok a získali prístup k obsahu, ktorý im bol výslovne zakázaný.
AI firmy ignorujú robots.txt najmä kvôli potrebe veľkého objemu dát na trénovanie jazykových modelov. Najhodnotnejší obsah je často obmedzený vlastníkmi stránok, čo vytvára konkurenčnú motiváciu obísť tieto obmedzenia. Okrem toho takmer neexistujú mechanizmy na vymáhanie pravidiel—vlastníci stránok technicky nemôžu zabrániť odhodlaným crawlerom a právne kroky sú pomalé a nákladné, čo spôsobuje, že riziko ignorovania robots.txt je nízke v porovnaní s potenciálnym ziskom.
Aj keď nemôžete úplne zabrániť všetkým stealth crawlerom, môžete výrazne znížiť neoprávnený prístup viacvrstvovou obranou. Zavedením jasných pravidiel robots.txt, nasadením WAF pravidiel, využívaním device fingerprintingu, monitorovaním správania crawlerov nástrojmi ako AmICited a zavedením autentifikácie pre citlivý obsah môžete skombinovať viacero techník a výrazne zvýšiť ochranu. Kľúčom je kombinovať viacero metód, nie spoliehať sa na jedno riešenie.
User agent spoofing je technika, keď sa crawler vydáva za legitímny webový prehliadač tým, že používa realistický user agent reťazec (napríklad Chrome alebo Safari). Vďaka tomu vyzerá ako ľudský návštevník, nie ako bot. Stealth crawlery využívajú túto techniku na obídenie jednoduchých blokovaní na základe user agenta a na vyhnutie sa detekcii bezpečnostnými systémami, ktoré hľadajú špecifické identifikátory botov.
Stealth crawlery môžete odhaliť analýzou vzorcov návštevnosti a vyhľadávaním podozrivého správania: požiadavky z neobvyklých IP adries, nemožné sekvencie navigácie, absencia ľudských interakcií, alebo požiadavky, ktoré nezodpovedajú legitímnym prehliadačom. Nástroje ako AmICited, Cloudflare's AI Crawl Control a riešenia na device fingerprinting dokážu túto detekciu automatizovať súčasnou analýzou desiatok signálov.
Právny status obchádzania crawlerov sa líši podľa jurisdikcie. Aj keď porušenie robots.txt môže znamenať porušenie podmienok používania, právny status scrapovania verejne dostupných informácií zostáva nejasný. Niektoré súdy rozhodli, že scrapovanie je legálne, iné zas, že ide o porušenie zákona o počítačových podvodoch a zneužití. Táto právna neistota povzbudzuje firmy, ktoré sú ochotné pohybovať sa v šedej zóne, hoci sa objavujú nové regulačné zmeny.
AmICited poskytuje prehľad o tom, ktoré AI systémy skutočne citujú vašu značku a obsah, nielen o tom, ktoré crawlery pristupujú na vašu stránku. Platforma identifikuje stealth crawlery analýzou vzorcov návštevnosti a behaviorálnych signálov, posiela upozornenia v reálnom čase pri detekcii podozrivej aktivity a integruje sa s existujúcimi SEO a bezpečnostnými workflowmi, aby ste mali kontrolu nad tým, ako je váš obsah využívaný.
Deklarované crawlery sa otvorene identifikujú jedinečnými user agent reťazcami, zverejňujú svoje IP rozsahy a zvyčajne rešpektujú príkazy robots.txt. Príkladmi sú GPTBot od OpenAI a ClaudeBot od Anthropic. Nedeclarované crawlery skrývajú svoju identitu vydávaním sa za prehliadače, používajú sfalšované user agenty a zámerne ignorujú obmedzenia stránok. Výrazným príkladom nedeclarovaného crawlera je stealth crawler od Perplexity.
Zistite, ktoré AI systémy citujú vašu značku a odhaľte stealth crawlery pristupujúce k vášmu obsahu pomocou pokročilej platformy na monitorovanie AmICited.
Kompletný sprievodca robotom PerplexityBot – pochopte, ako funguje, spravujte jeho prístup, sledujte citácie a optimalizujte viditeľnosť pre Perplexity AI. Zist...

Zistite, ako otestovať, či AI crawlery ako ChatGPT, Claude a Perplexity môžu pristupovať k obsahu vašej webstránky. Objavte metódy testovania, nástroje a najlep...
Zistite, ako povoliť AI robotom ako GPTBot, PerplexityBot a ClaudeBot prehľadávať váš web. Nakonfigurujte robots.txt, nastavte llms.txt a optimalizujte pre AI v...
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.