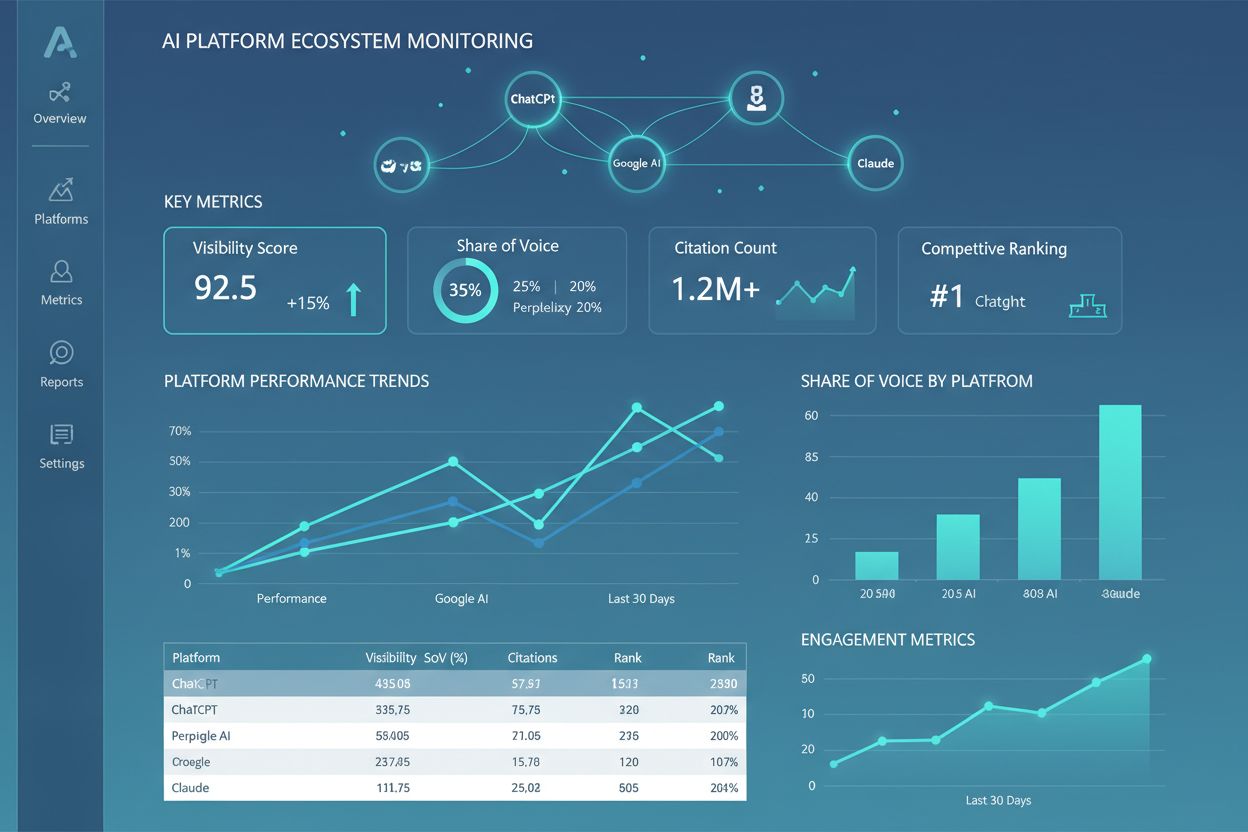
Ekosystém AI platforiem
Zistite, čo je ekosystém AI platforiem, ako spolupracujú prepojené AI systémy a prečo je dôležité riadiť vašu značku naprieč viacerými AI platformami pre lepšiu...
5 min čítania

Izolované sandboxové prostredia navrhnuté na validáciu, vyhodnocovanie a ladenie modelov a aplikácií umelej inteligencie pred nasadením do produkcie. Tieto kontrolované priestory umožňujú testovanie výkonnosti AI obsahu na rôznych platformách, meranie metrík a zabezpečenie spoľahlivosti bez ovplyvnenia živých systémov alebo odhalenia citlivých údajov.
Izolované sandboxové prostredia navrhnuté na validáciu, vyhodnocovanie a ladenie modelov a aplikácií umelej inteligencie pred nasadením do produkcie. Tieto kontrolované priestory umožňujú testovanie výkonnosti AI obsahu na rôznych platformách, meranie metrík a zabezpečenie spoľahlivosti bez ovplyvnenia živých systémov alebo odhalenia citlivých údajov.
Testovacie prostredie pre AI je kontrolovaný, izolovaný výpočtový priestor navrhnutý na validáciu, vyhodnocovanie a ladenie modelov a aplikácií umelej inteligencie pred nasadením do produkčných systémov. Slúži ako sandbox, kde môžu vývojári, dátoví vedci a QA tímy bezpečne spúšťať AI modely, testovať rôzne konfigurácie a merať výkon podľa vopred definovaných metrík bez ovplyvnenia živých systémov alebo odhalenia citlivých údajov. Tieto prostredia replikujú produkčné podmienky pri úplnej izolácii, čo tímom umožňuje identifikovať problémy, optimalizovať správanie modelov a zabezpečiť spoľahlivosť v rôznych scenároch. Testovacie prostredie predstavuje kľúčovú kvalitatívnu bránu v životnom cykle vývoja AI, prepája experimentálne prototypovanie s podnikovým nasadením.

Komplexné testovacie prostredie pre AI pozostáva z viacerých prepojených technických vrstiev, ktoré spolu poskytujú úplné testovacie možnosti. Vykonávacia vrstva modelu zabezpečuje samotnú inferenciu a výpočty, podporuje viacero frameworkov (PyTorch, TensorFlow, ONNX) a typov modelov (LLM, počítačové videnie, časové rady). Vrstva správy dát spravuje testovacie datasety, fixture a generovanie syntetických dát pri zachovaní izolácie a súladu dát. Hodnotiaci rámec obsahuje metrické enginy, knižnice asercie a skórovacie systémy, ktoré porovnávajú výstupy modelov s očakávanými výsledkami. Vrstva monitorovania a logovania zachytáva trasovanie vykonávania, výkonnostné metriky, latenciu a chybové logy na analýzu po teste. Orchestrovaná vrstva riadi testovacie workflowy, paralelné vykonávanie, alokáciu zdrojov a provisionovanie prostredí. Nižšie je porovnanie kľúčových architektonických komponentov naprieč rôznymi typmi testovacích prostredí:
| Komponent | Testovanie LLM | Počítačové videnie | Časové rady | Multi-modálne |
|---|---|---|---|---|
| Modelový runtime | Transformer inferencia | GPU-akcelerovaná inferencia | Sekvenčné spracovanie | Hybridné vykonávanie |
| Formát dát | Text/tokeny | Obrázky/tenzory | Číselné sekvencie | Zmiešané médiá |
| Hodnotiace metriky | Sémantická podobnosť, halucinácie | Presnosť, IoU, F1-skóre | RMSE, MAE, MAPE | Cross-modálna zhoda |
| Latenciu požiadavky | 100-500ms typicky | 50-200ms typicky | <100ms typicky | 200-1000ms typicky |
| Izolačná metóda | Kontajner/VM | Kontajner/VM | Kontajner/VM | Firecracker microVM |
Moderné testovacie prostredia pre AI musia podporovať heterogénne ekosystémy modelov, čo tímom umožňuje vyhodnocovať aplikácie naprieč rôznymi poskytovateľmi LLM, frameworkami a cieľmi nasadenia súčasne. Multiplatformové testovanie umožňuje organizáciám porovnávať výstupy modelov od OpenAI GPT-4, Anthropic Claude, Mistral a open-source alternatív ako Llama v tom istom testovacom prostredí, čo uľahčuje informované rozhodnutie o výbere modelu. Platformy ako E2B poskytujú izolované sandboxy, ktoré vykonávajú kód generovaný akýmkoľvek LLM, podporujú Python, JavaScript, Ruby a C++ s plným prístupom k filesystemu, možnosťou terminálu a inštaláciou balíčkov. IntelIQ.dev umožňuje vedľa seba porovnávať viacero AI modelov s jednotným rozhraním, čo tímom umožňuje testovať promptové šablóny s bezpečnostnými pravidlami naprieč rôznymi poskytovateľmi. Testovacie prostredia musia zvládnuť:
Testovacie prostredia pre AI slúžia rôznym potrebám organizácií v oblasti vývoja, zabezpečenia kvality a súladu. Vývojové tímy využívajú testovacie prostredia na overovanie správania modelu počas iteratívneho vývoja, testovanie variácií promptov, ladenie parametrov a ladenie nečakaných výstupov pred integráciou. Dátové tímy v týchto prostrediach hodnotia výkon modelov na odložených datasetoch, porovnávajú rôzne architektúry a merajú metriky ako presnosť, recall, F1-skóre. Monitorovanie produkcie zahŕňa kontinuálne testovanie nasadených modelov voči základným metrikám, detekciu poklesu výkonu a spúšťanie retraining pipeline pri prekročení limitov kvality. Tímy pre súlad a bezpečnosť validujú v testovacích prostrediach, či modely spĺňajú regulačné požiadavky, negenerujú zaujaté výstupy a správne spracúvajú citlivé dáta. Podnikové aplikácie zahŕňajú:
Súčasný trh testovania AI zahŕňa špecializované platformy navrhnuté pre rôzne scenáre testovania a rozsahy organizácií. DeepEval je open-source rámec na hodnotenie LLM, ktorý poskytuje viac ako 50 vedecky podložených metrík vrátane správnosti odpovedí, sémantickej podobnosti, detekcie halucinácií a hodnotenia toxicity, s natívnou integráciou do Pytest pre CI/CD workflowy. LangSmith (od LangChain) ponúka komplexnú pozorovateľnosť, hodnotenie a nasadzovanie s integrovaným trasovaním, verziovaním promptov a správou datasetov pre LLM aplikácie. E2B poskytuje bezpečné, izolované sandboxy postavené na Firecracker microVMs, podporuje vykonávanie kódu s nábehom pod 200 ms, až 24-hodinové relácie a integráciu s hlavnými poskytovateľmi LLM. IntelIQ.dev kladie dôraz na testovanie so zameraním na súkromie s end-to-end šifrovaním, riadením prístupov na báze rolí a podporou viacerých AI modelov vrátane GPT-4, Claude a open-source alternatív. Nasledujúca tabuľka porovnáva kľúčové schopnosti:
| Nástroj | Primárne zameranie | Metriky | CI/CD integrácia | Podpora viacerých modelov | Model ceny |
|---|---|---|---|---|---|
| DeepEval | Hodnotenie LLM | 50+ metrík | Natívny Pytest | Obmedzená | Open-source + cloud |
| LangSmith | Pozorovateľnosť & hodnotenie | Vlastné metriky | API integrácia | Ekosystém LangChain | Freemium + enterprise |
| E2B | Vykonávanie kódu | Výkonnostné metriky | GitHub Actions | Všetky LLM | Platba za použitie + enterprise |
| IntelIQ.dev | Testovanie so zameraním na súkromie | Vlastné metriky | Workflow builder | GPT-4, Claude, Mistral | Predplatné |
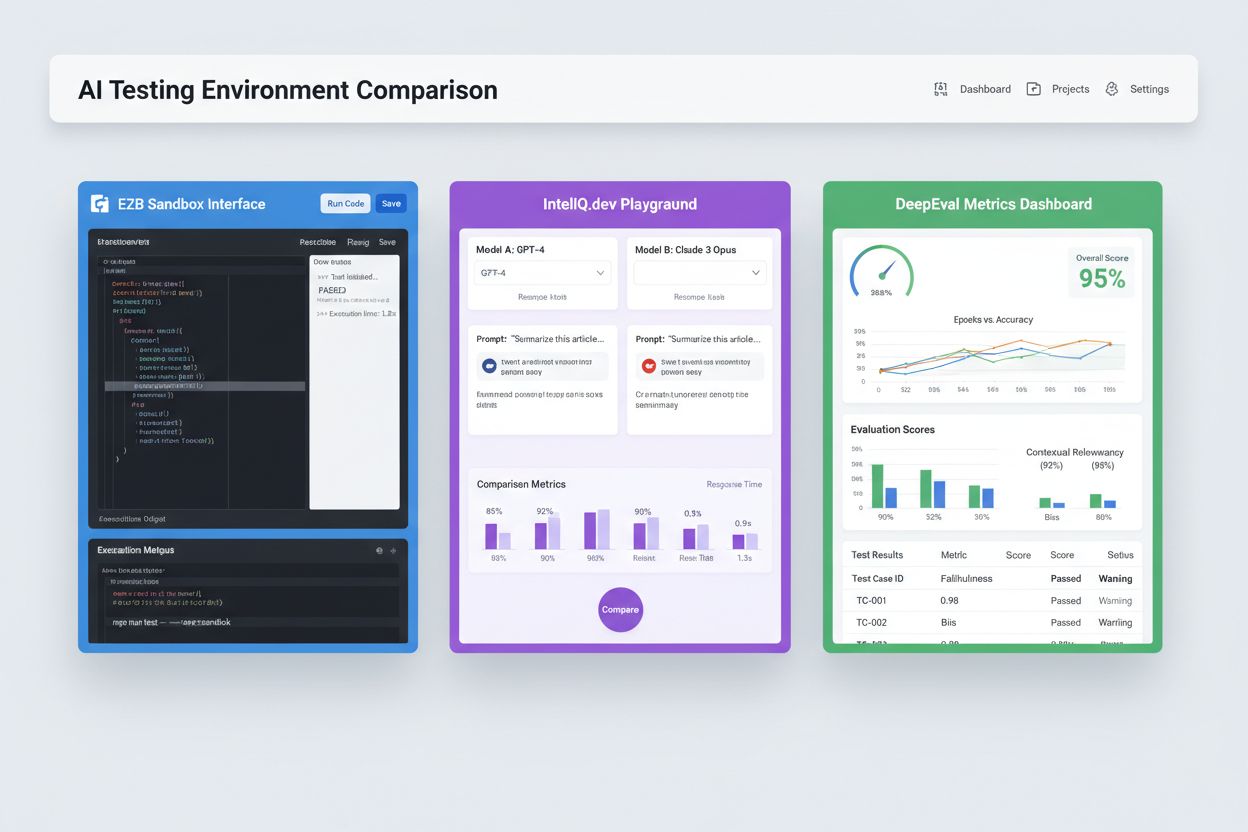
Podnikové testovacie prostredia pre AI musia implementovať prísne bezpečnostné opatrenia na ochranu citlivých údajov, zachovanie regulačnej zhody a zabránenie neoprávnenému prístupu. Izolácia dát znamená, že testovacie údaje nikdy neuniknú do externých API alebo služieb tretích strán; platformy ako E2B používajú Firecracker microVMs na zabezpečenie úplnej procesovej izolácie bez zdieľaného jadra. Šifrovacie štandardy by mali zahŕňať end-to-end šifrovanie pre dáta v pokoji aj pri prenose, s podporou pre požiadavky HIPAA, SOC 2 Type 2 a GDPR. Riadenie prístupov musí vynucovať povolenia na základe rolí, auditné logy a schvaľovacie workflowy pre citlivé testovacie scenáre. Najlepšie postupy zahŕňajú: udržiavanie oddelených testovacích datasetov bez produkčných dát, implementáciu maskovania dát pre osobne identifikovateľné informácie (PII), využívanie generovania syntetických dát pre realistické testovanie bez rizika narušenia súkromia, pravidelné bezpečnostné audity testovacej infraštruktúry a dokumentáciu všetkých testovacích výsledkov pre účely súladu. Organizácie by mali zaviesť aj detekciu zaujatosti na identifikáciu diskriminačného správania modelov, používať interpretačné nástroje ako SHAP alebo LIME na pochopenie rozhodnutí modelu a zaviesť logovanie rozhodnutí na sledovanie, ako modely prichádzajú k špecifickým výstupom pre regulačnú zodpovednosť.
Testovacie prostredia pre AI sa musia bez problémov integrovať do existujúcich pipeline nepretržitej integrácie a nasadzovania (CI/CD), aby umožnili automatizované kvalitatívne brány a rýchle iterácie. Natívna integrácia s CI/CD umožňuje automatické spustenie testov pri commitoch, pull requestoch alebo v plánovaných intervaloch cez platformy ako GitHub Actions, GitLab CI alebo Jenkins. Pytest integrácia DeepEval umožňuje vývojárom písať testovacie prípady ako štandardné Python testy, ktoré sa vykonávajú v rámci existujúcich CI workflowov, pričom výsledky sa zobrazujú spolu s bežnými unit testami. Automatizované hodnotenie môže merať výkonnostné metriky modelu, porovnávať výstupy s referenčnými verziami a blokovať nasadenia, ak nie sú splnené prahové hodnoty kvality. Správa artefaktov znamená ukladanie testovacích datasetov, checkpointov modelov a výsledkov hodnotenia do systémov verzovania alebo repozitárov artefaktov pre replikovateľnosť a audit. Vzorce integrácie zahŕňajú:
Oblasť testovacích prostredí pre AI sa rýchlo vyvíja, aby reagovala na nové výzvy v komplexnosti, škálovaní a rôznorodosti modelov. Agentické testovanie nadobúda na význame, keďže AI systémy prechádzajú od jedného modelu k multi-step workflowom, kde agenti používajú nástroje, rozhodujú sa a komunikujú s externými systémami – čo si vyžaduje nové hodnotiace rámce na meranie úspešnosti úloh, bezpečnosti a spoľahlivosti. Distribuované hodnotenie umožňuje testovanie vo veľkom rozsahu vďaka spusteniu tisícov paralelných testovacích inštancií v cloude, čo je kľúčové pre reinforcement learning a veľkokapacitný tréning modelov. Monitorovanie v reálnom čase sa mení z dávkového hodnotenia na kontinuálne produkčné testovanie, ktoré deteguje pokles výkonu, drift dát a vznikajúce zaujatosti v živých systémoch. Pozorovacie platformy ako AmICited sa stávajú nevyhnutným nástrojom pre komplexný monitoring a vizibilitu AI, poskytujú centralizované dashboardy, ktoré sledujú výkon modelov, vzorce používania a kvalitatívne metriky naprieč celým AI portfóliom. Budúce testovacie prostredia budú čoraz viac obsahovať automatizovanú nápravu, kde systémy nielen detegujú problémy, ale automaticky spúšťajú retrainovanie alebo aktualizácie modelov, a cross-modálne hodnotenie, ktoré umožňuje súčasné testovanie textových, obrazových, zvukových a video modelov v jednotných frameworkoch.
Testovacie prostredie pre AI je izolovaný sandbox, kde môžete bezpečne testovať modely, promptov a konfigurácie bez ovplyvnenia živých systémov alebo používateľov. Produkčné nasadenie je živé prostredie, kde modely slúžia skutočným používateľom. Testovacie prostredia umožňujú zachytiť chyby, optimalizovať výkon a validovať zmeny ešte pred nasadením do produkcie, čím znižujú riziko a zabezpečujú kvalitu.
Áno, moderné testovacie prostredia pre AI podporujú testovanie viacerých modelov. Platformy ako E2B, IntelIQ.dev a DeepEval umožňujú testovať ten istý prompt alebo vstup naprieč rôznymi poskytovateľmi LLM (OpenAI, Anthropic, Mistral a iní) súčasne, čo umožňuje priamu komparáciu výstupov a výkonnostných metrík.
Podnikové testovacie prostredia pre AI implementujú viacero vrstiev bezpečnosti, vrátane izolácie dát (kontejnerizácia alebo microVM), end-to-end šifrovania, riadenia prístupov na základe rolí, auditných logov a certifikácií zhodnosti (SOC 2, GDPR, HIPAA). Dáta nikdy neopúšťajú izolované prostredie, pokiaľ nie sú explicitne exportované, čím chránia citlivé informácie.
Testovacie prostredia umožňujú súlad vďaka poskytovaniu audit trailov všetkých hodnotení modelov, podpore maskovania dát a generovania syntetických údajov, vynucovaniu prístupových práv a udržiavaniu úplnej izolácie testovacích dát od produkčných systémov. Táto dokumentácia a kontrola pomáha organizáciám splniť regulatorné požiadavky ako GDPR, HIPAA a SOC 2.
Kľúčové metriky závisia od vášho použitia: pre LLM sledujte presnosť, sémantickú podobnosť, mieru halucinácií a latenciu; pre RAG systémy merajte presnosť/recall kontextu a vierohodnosť; pre klasifikačné modely monitorujte presnosť, recall a F1-skóre; pre všetky modely sledujte zhoršovanie výkonu v čase a indikátory zaujatosti.
Náklady sa líšia podľa platformy: DeepEval je open-source a zadarmo; LangSmith ponúka bezplatnú úroveň s platenými plánmi od 39 $/mesiac; E2B používa platbu podľa použitia na základe behu sandboxu; IntelIQ.dev ponúka predplatné. Mnohé platformy ponúkajú aj podnikové ceny pre veľké nasadenia.
Áno, väčšina moderných testovacích prostredí podporuje integráciu do CI/CD. DeepEval sa natívne integruje s Pytest, E2B funguje s GitHub Actions a GitLab CI a LangSmith poskytuje integráciu cez API. To umožňuje automatizované testovanie pri každom commite a vynucovanie deployment brán.
End-to-end testovanie vníma celú AI aplikáciu ako čiernu skrinku a testuje konečný výstup voči očakávaným výsledkom. Komponentové testovanie hodnotí jednotlivé časti (LLM volania, retrievery, používanie nástrojov) samostatne pomocou trasovania a inštrumentácie. Komponentové testovanie poskytuje hlbší pohľad na to, kde vznikajú problémy, zatiaľ čo end-to-end testovanie overuje celkové správanie systému.
AmICited sleduje, ako AI systémy odkazujú na vašu značku a obsah v ChatGPT, Claude, Perplexity a Google AI. Získajte prehľad o svojej AI prítomnosti v reálnom čase vďaka komplexnému monitorovaniu a analytike.
Zistite, čo je ekosystém AI platforiem, ako spolupracujú prepojené AI systémy a prečo je dôležité riadiť vašu značku naprieč viacerými AI platformami pre lepšiu...
Zistite, čo je Centrum excelentnosti pre viditeľnosť AI, aké sú jeho hlavné zodpovednosti, monitorovacie schopnosti a ako umožňuje organizáciám udržať transpare...

Ovládnite A/B testovanie pre AI viditeľnosť s naším komplexným sprievodcom. Naučte sa GEO experimenty, metodológiu, najlepšie postupy a reálne prípadové štúdie ...
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.