
Rozpoznávanie entít
Rozpoznávanie entít je schopnosť AI a NLP identifikovať a kategorizovať pomenované entity v texte. Zistite, ako funguje, jeho využitie v AI monitoringu a jeho ú...
9 min čítania

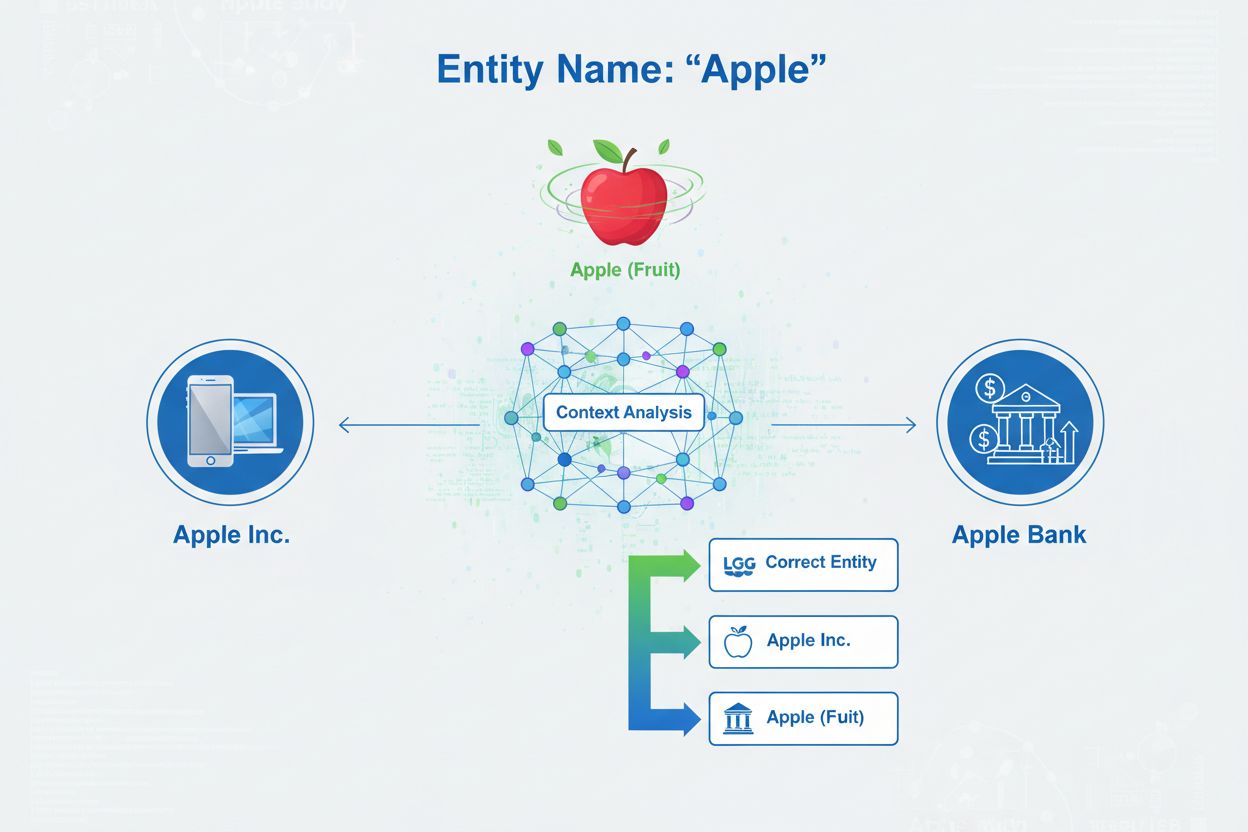
Disambiguácia entít je proces určovania, na ktorú konkrétnu entitu sa odkazuje v prípade, že viacero entít zdieľa rovnaké meno. Pomáha AI systémom presne porozumieť a citovať obsah tým, že rieši nejednoznačnosť v odkazoch na pomenované entity, a zabezpečuje, že zmienky o ‘Apple’ správne identifikujú, či ide o Apple Inc., ovocie alebo inú entitu s rovnakým menom.
Disambiguácia entít je proces určovania, na ktorú konkrétnu entitu sa odkazuje v prípade, že viacero entít zdieľa rovnaké meno. Pomáha AI systémom presne porozumieť a citovať obsah tým, že rieši nejednoznačnosť v odkazoch na pomenované entity, a zabezpečuje, že zmienky o 'Apple' správne identifikujú, či ide o Apple Inc., ovocie alebo inú entitu s rovnakým menom.
Disambiguácia entít je proces určovania, na ktorú konkrétnu entitu sa odkazuje v prípade, že viacero entít zdieľa rovnaké meno alebo podobné odkazy. V kontexte umelej inteligencie a spracovania prirodzeného jazyka (NLP) disambiguácia entít zabezpečuje, aby AI systém pri stretnutí s pomenovanou entitou v texte správne identifikoval, na ktorý reálny objekt, osobu, organizáciu alebo miesto sa odkazuje. To sa zásadne líši od rozpoznávania pomenovaných entít (NER), ktoré len určuje, že existuje entita, a zaraďuje ju do kategórie ako „osoba“, „organizácia“ alebo „miesto“. Zatiaľ čo NER odpovedá na otázku „Je tu nejaká entita?“, disambiguácia entít odpovedá „Ktorá konkrétna entita to je?“. Napríklad pri spracovaní vety „Apple bol mozgovým dieťaťom Steva Jobsa“ NER identifikuje „Apple“ ako organizáciu, ale disambiguácia určí, či ide o Apple Inc., technologickú spoločnosť, alebo potenciálne inú entitu s rovnakým názvom. Toto rozlíšenie je kľúčové pre AI systémy, ktoré potrebujú presne porozumieť a citovať obsah, preto AmICited.com sleduje, ako AI systémy ako ChatGPT, Perplexity a Google AI Overviews riešia disambiguáciu entít pri generovaní odpovedí o značkách a organizáciách.
Základný problém, ktorý disambiguácia entít rieši, je nejednoznačnosť — skutočnosť, že mnohé názvy entít môžu označovať rôzne reálne objekty. Táto nejednoznačnosť vytvára značné výzvy pre AI systémy snažiace sa porozumieť a generovať presný obsah. Podľa Stanford AI Index 2024 viac ako 18 % výstupov LLM súvisiacich so značkovými entitami obsahuje buď halucinácie, alebo nesprávne priradenia, čo znamená, že AI systémy často zamieňajú jednu entitu za inú alebo generujú nepravdivé informácie o entitách. Táto chybovosť má vážne dôsledky na reprezentáciu značky a presnosť obsahu. Keď AI systém nesprávne identifikuje entitu, môže poskytnúť nesprávne informácie, pripísať výroky nesprávnej organizácii alebo neschopnosť správne citovať zdroj informácie.
| Názov entity | Možné významy | Miera zámien AI |
|---|---|---|
| Apple | Tech spoločnosť / ovocie / banka | Vysoká |
| Delta | Letecká spoločnosť / výrobca batérií / grécke písmeno | Vysoká |
| Jaguar | Výrobca áut / druh zvieraťa | Stredná |
| Amazon | E-commerce spoločnosť / dažďový prales / rieka | Vysoká |
| Orange | Farba / ovocie / telekomunikačná spoločnosť | Stredná |
Dôsledky zlej disambiguácie entít presahujú jednoduché faktické chyby. Pre tvorcov obsahu a značky môže nesprávna identifikácia v AI-generovaných odpovediach viesť k strate viditeľnosti, nesprávnej atribúcii a poškodeniu reputácie značky. Ak sa používateľ opýta AI systému na „Delta“, môže očakávať informácie o Delta Airlines, ale ak systém zamení túto entitu za Delta Faucet Company, používateľ dostane irelevantné informácie. Práve preto AmICited.com monitoruje, ako AI systémy disambiguujú entity – aby značky vedeli, či sú správne identifikované a citované v AI-generovanom obsahu na viacerých platformách.
Disambiguácia entít prebieha prostredníctvom systematického procesu, ktorý kombinuje viacero NLP techník na riešenie nejednoznačnosti a správnu identifikáciu entít. Pochopenie tohto procesu vysvetľuje, prečo niektoré AI systémy dosahujú lepšiu citáciu ako iné.
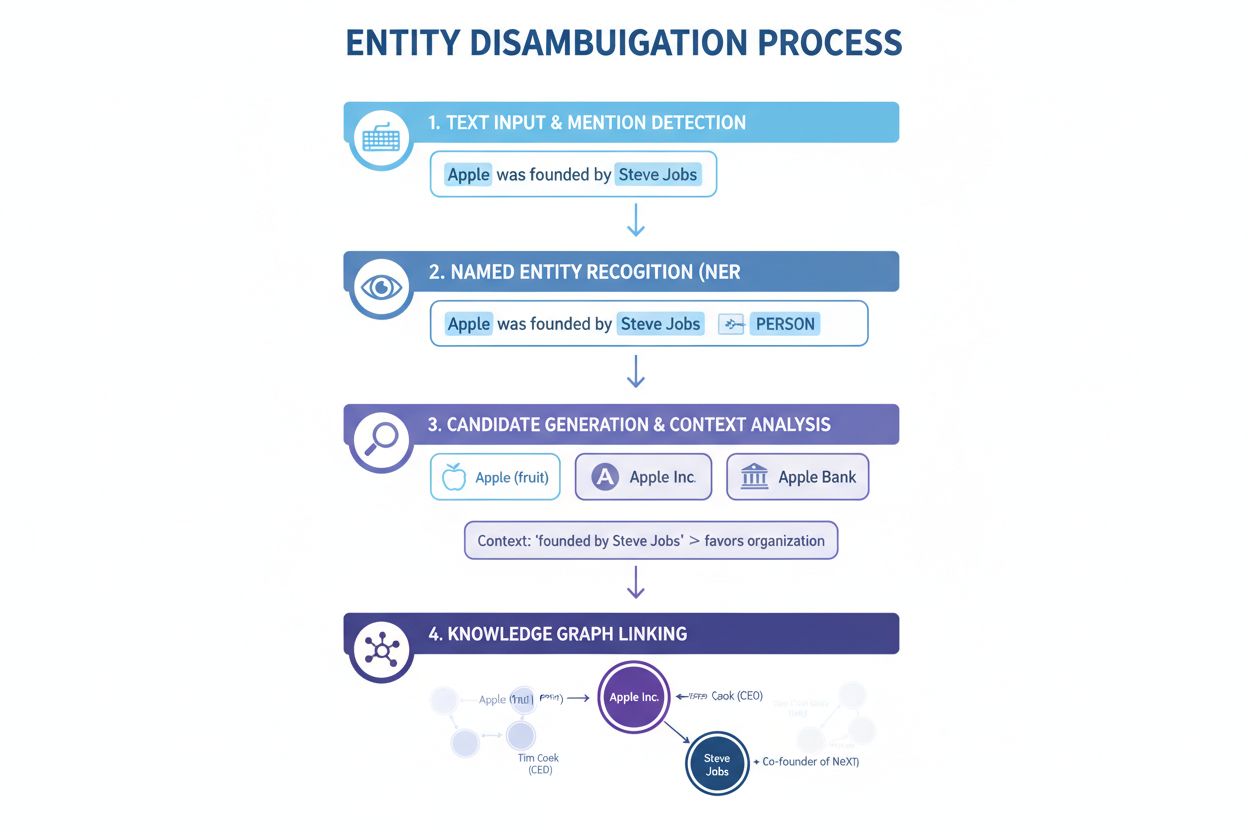
Rozpoznávanie pomenovaných entít (NER): Prvým krokom je identifikácia a klasifikácia pomenovaných entít v texte. Systémy NER prehľadávajú text a nachádzajú zmienky o entitách, pričom ich zaraďujú do preddefinovaných kategórií ako osoba, organizácia, miesto, produkt alebo dátum. Napríklad vo vete „Apple bol mozgovým dieťaťom Steva Jobsa“ NER identifikuje „Apple“ a „Steve Jobs“ ako entity a priradí im kategórie organizácia a osoba. Tento základný krok je nevyhnutný, pretože disambiguácia nie je možná bez predchádzajúcej identifikácie entít.
Kategorizácia entít: Po identifikácii musia byť entity presnejšie kategorizované. To znamená nielen širokú klasifikáciu, ale aj pochopenie konkrétneho typu a kontextu každej entity. Systém analyzuje okolitý text, aby zistil, či sa „Apple“ objavuje v technologickom kontexte (pravdepodobne Apple Inc.), v potravinovom (ovocie), alebo vo finančnom (Apple Bank). Táto kontextová analýza zužuje možnosti pred samotnou disambiguáciou.
Disambiguácia: Toto je kľúčový krok, kde systém určuje, na ktorú konkrétnu entitu sa odkazuje. Systém vyhodnotí viacero kandidátskych entít, ktoré zodpovedajú identifikovanému menu, a využije rôzne signály — vrátane kontextu, popisov entít, sémantických vzťahov a znalostných grafov — na výber najpravdepodobnejšej entity. Pri vete „Apple bol mozgovým dieťaťom Steva Jobsa“ systém rozpozná, že Steve Jobs je silne spojený s Apple Inc., čo je správna voľba disambiguácie.
Prepojenie na znalostnú bázu: Záverečným krokom je prepojenie disambiguovanej entity s unikátnym identifikátorom v externej znalostnej báze alebo znalostnom grafe, ako je Wikidata, Wikipedia alebo proprietárna databáza. Toto prepojenie potvrdzuje identitu entity a obohacuje text o sémantické informácie využiteľné na ďalšie spracovanie a analýzu. Entita dostane unikátne URI (Uniform Resource Identifier), ktorý slúži ako definitívny referenčný bod.
Postupom času sa vyvinuli rôzne prístupy k disambiguácii entít, každý s výhodami a obmedzeniami. Pochopenie týchto prístupov vysvetľuje, prečo majú moderné AI systémy rozdielnu presnosť disambiguácie.
Pravidlové prístupy: Tieto systémy používajú preddefinované jazykové pravidlá a heuristiky na disambiguáciu entít. Môžu aplikovať pravidlá ako „ak sa ‘Apple’ vyskytuje blízko ‘iPhone’ alebo ‘MacBook’, ide o Apple Inc.“ alebo „ak sa ‘Delta’ objaví pri ‘letecká spoločnosť’ alebo ‘let’, ide o Delta Airlines“. Pravidlové systémy sú prehľadné a nevyžadujú veľké trénovacie dáta, ale majú problém s novými kontextami a nevedia sa prispôsobiť novým významom bez manuálnych úprav.
Strojové učenie: Modely učenia s učiteľom sa učia z anotovaných trénovacích dát predikovať správnu entitu na základe kontextových znakov. Systémy extrahujú znaky z okolia textu a používajú algoritmy ako Support Vector Machines alebo Random Forests na klasifikáciu najpravdepodobnejšej entity. Strojové učenie je flexibilnejšie ako pravidlové systémy, ale vyžaduje veľa označených dát a nemusí dobre generalizovať na entity, ktoré nevidel počas tréningu.
Hĺbkové učenie a transformerové modely: Moderná disambiguácia entít sa čoraz viac spolieha na transformerové architektúry ako BERT, RoBERTa a špecializované modely ako GENRE a BLINK. Tieto modely využívajú neurónové siete na hlbšie pochopenie kontextu, zachytávajú sémantické vzťahy a nuansy jazyka. Transformery dosahujú vynikajúci výkon v štandardných benchmarkoch a lepšie zvládajú zložité scenáre disambiguácie. Napríklad systém Ontotext CEEL (Common English Entity Linking) využíva transformerovú architektúru optimalizovanú na efektívnosť CPU pri vysokej presnosti — dosahuje 96 % presnosť rozpoznania entít a 76 % presnosť prepojenia entít v štandardných benchmarkoch.
Integrácia znalostných grafov: Moderné systémy čoraz častejšie kombinujú strojové učenie so znalostnými grafmi — štruktúrovanými databázami reprezentujúcimi entity a ich vzťahy. Znalostné grafy poskytujú bohaté kontextové informácie o entitách, ich vlastnostiach a vzťahoch k iným entitám. Dotazovaním znalostných grafov pri disambiguácii môžu systémy získať metadáta, popisy a informácie o vzťahoch, ktoré pomáhajú presnejšie riešiť nejednoznačnosť.
Disambiguácia entít sa stala nevyhnutnou v mnohých odvetviach a aplikáciách, ktoré ťažia z presnej identifikácie a citovania entít.
Vyhľadávače: Google, Bing a ďalšie vyhľadávače sa silno spoliehajú na disambiguáciu entít, aby poskytli relevantné výsledky. Keď používateľ vyhľadáva „Apple“, vyhľadávač musí určiť, či má na mysli Apple Inc., ovocie alebo inú entitu s týmto menom. Vyhľadávače využívajú kontext dopytu, históriu používateľa a znalostné grafy na disambiguáciu a poskytnutie najrelevantnejších výsledkov. Preto sa medzi výsledkami na „Apple“ zvyčajne objavuje ako prvá technologická spoločnosť — systém sa naučil, že to je najčastejšie zamýšľaná entita.
Médiá a vydavateľstvo: Spravodajské organizácie a obsahové platformy používajú disambiguáciu entít na zlepšenie objaviteľnosti obsahu a prepojenie súvisiacich článkov. Ak je v článku spomenutá „Apple“, systém môže automaticky prepojiť na záznam Apple Inc. v znalostnej báze, čím poskytne čitateľom dodatočný kontext a súvisiace články. Zlepšuje to angažovanosť používateľov a porozumenie širším súvislostiam správ.
Zdravotníctvo: Zdravotnícke zariadenia používajú disambiguáciu entít na presnú identifikáciu liekov, chorôb a lekárskych zákrokov v pacientských záznamoch a klinickej literatúre. Disambiguácia názvov liekov je obzvlášť kritická — „aspirín“ môže označovať generický liek, konkrétnu značku alebo dávkovú variantu. Presná disambiguácia zabezpečí, že odborníci majú prístup k správnym informáciám a záznamy pacientov sú správne organizované.
Finančné služby: Investičné spoločnosti a finanční analytici používajú disambiguáciu entít na sledovanie zmienok o spoločnostiach v správach, výkazoch a trhových dátach. Pri analýze trhového vystavenia je potrebné presne identifikovať všetky zmienky o konkrétnej spoločnosti z rôznych zdrojov. Disambiguácia entít zabezpečí, že odkazy na „Apple“ sú správne priradené Apple Inc. a nie iným entitám, čo umožňuje presné hodnotenie rizika a analýzu portfólia.
E-commerce: Online predajcovia používajú disambiguáciu entít na priradenie zmienok o produktoch k skutočným produktom v katalógu. Keď zákazník vyhľadáva „Apple laptop“, systém musí disambiguovať „Apple“ ako spoločnosť a priradiť relevantné produkty. To zlepšuje presnosť vyhľadávania a pomáha zákazníkom rýchlejšie nájsť, čo hľadajú.
AmICited.com aplikuje princípy disambiguácie entít na monitorovanie, ako AI systémy ako ChatGPT, Perplexity a Google AI Overviews spracúvajú zmienky o značkách. Sledovaním toho, či systémy správne disambiguujú značkové entity a presne ich citujú, AmICited pomáha značkám porozumieť svojej viditeľnosti a reprezentácii v AI-generovanom obsahu.
Znalostné grafy sa stali základom moderných systémov disambiguácie entít, pretože poskytujú štruktúrované reprezentácie entít a ich vzťahov. Znalostný graf je v podstate databáza entít (uzly) a ich vzťahov (hrany). Každý uzol entity obsahuje metadáta, ako je názov, popis, typ a vlastnosti entity. Napríklad v znalostnom grafe môže mať entita „Apple Inc.“ vlastnosti ako „založená v roku 1976“, „sídlo v Cupertine“, „odvetvie: technológie“ a vzťahy ako „založil Steve Jobs“ či „produkuje iPhone“.
Keď systém na disambiguáciu entít narazí na nejednoznačnú zmienku, môže sa dotazovať na znalostný graf a získať bohaté informácie o kandidátskych entitách. Tieto informácie pomáhajú systému prijímať informovanejšie rozhodnutia pri disambiguácii. Napríklad ak systém disambiguuje „Apple“ a v okolí je zmienka o „Steve Jobs“, môže si v znalostnom grafe overiť, že Steve Jobs je úzko spojený s Apple Inc., čo je najpravdepodobnejšia entita. Znalostné grafy ako Wikidata a Wikipedia poskytujú verejne dostupné informácie o entitách, ktoré mnohé AI systémy používajú počas inferencie. Proprietárne znalostné grafy vyvíjané spoločnosťami ako Google, Microsoft a ďalší poskytujú dodatočné doménovo špecifické informácie. Integrácia znalostných grafov so strojovým učením výrazne zlepšila presnosť disambiguácie entít, pretože systémy teraz dokážu kombinovať naučené vzory so štruktúrovanými faktami.
Napriek pokroku narážajú systémy disambiguácie entít na niekoľko pretrvávajúcich výziev, ktoré obmedzujú ich presnosť a použiteľnosť.
Polysémia a nejednoznačnosť: Mnohé názvy entít majú viacero legitímnych významov a samotný kontext nemusí stačiť na ich rozlíšenie. „Bank“ môže označovať finančnú inštitúciu alebo breh rieky. „Crane“ môže byť vták alebo stavebný stroj. Niektoré názvy entít sú natoľko nejednoznačné, že aj ľudia majú problém určiť zamýšľaný význam bez ďalšieho kontextu. AI systémy sa musia naučiť rozpoznať, keď kontext nestačí, a tieto prípady korektne spracovať.
Nové a vznikajúce entity: Znalostné bázy a trénovacie dáta starnú, keď vznikajú nové entity. Keď sa založí nová firma alebo uvedie nový produkt, systémy disambiguácie entít o nich nemusia v znalostných báze mať informácie. Zero-shot entity linking – schopnosť disambiguovať entity, ktoré neboli v trénovacích dátach – ostáva náročným problémom. Systémy musia vedieť rozpoznať, že ide o novú entitu, a spracovať ju správne namiesto nesprávneho priradenia k existujúcej podobnej entite.
Variácie mien a preklepy: Entity často vystupujú pod viacerými názvami, skratkami a variáciami. „United States“, „USA“, „U.S.“ a „America“ všetky označujú rovnakú entitu. Preklepy a chyby komplikujú disambiguáciu ešte viac. Systémy musia tieto variácie rozpoznať a správne priradiť k základnej entite. To je zvlášť náročné pri obsahu vytváranom používateľmi, kde sú časté preklepy.
Neúplné alebo zastarané údaje: Znalostné bázy môžu obsahovať neúplné informácie o entitách alebo sa môžu údaje stať zastaranými, keď sa entity vyvíjajú. Sídlo firmy sa môže zmeniť, vedenie môže odísť alebo firmu môže niekto kúpiť. Ak sa znalostná báza neaktualizuje včas, systémy môžu pri rozhodovaní používať zastarané informácie.
Škálovateľnosť a výkon: Spracovanie veľkých objemov textu s vysokou presnosťou disambiguácie entít vyžaduje značné výpočtové zdroje. Disambiguácia v reálnom čase pre aplikácie v masovom meradle je výpočtovo náročná. Systémy musia vyvažovať presnosť s rýchlosťou a nákladmi, čo často znamená kompromisy, ktoré znižujú kvalitu disambiguácie.
Pre značky a tvorcov obsahu je pochopenie disambiguácie entít zásadné pre zabezpečenie presnej reprezentácie v AI-generovanom obsahu. Ako AI systémy čoraz viac ovplyvňujú spôsob objavovania a konzumácie informácií, značky musia aktívne pristupovať k tomu, aby boli správne disambiguované a citované.
Stratégie predbežnej disambiguácie: Značky môžu implementovať stratégie, ktoré uľahčia AI systémom správnu disambiguáciu ich entít. To zahŕňa vytváranie jasných, rozpoznateľných digitálnych signálov, ktoré AI systémom umožnia jednoznačne identifikovať značku. Kľúčovou stratégiou je implementácia štruktúrovaných dát pomocou Schema.org značkovania a formátu JSON-LD na webových stránkach značky. Tieto štruktúrované dáta AI systémom explicitne poskytujú informácie o identite značky, vrátane oficiálneho názvu, popisu, loga, sídla a ďalších rozlišovacích znakov. Keď AI systémy narazia na názov značky, môžu sa na tieto štruktúrované dáta odvolať na potvrdenie správnej entity.
Optimalizácia znalostných grafov: Značky by mali zabezpečiť silnú prítomnosť v hlavných znalostných grafoch, ako sú Wikidata a Wikipedia. To znamená vytvoriť alebo udržiavať presné články na Wikipédii, zabezpečiť, aby záznamy vo Wikidate boli kompletne a aktuálne vyplnené, a budovať väzby medzi entitou značky a súvisiacimi entitami. Čím komplexnejšia a presnejšia je prítomnosť značky v znalostných grafoch, tým viac informácií majú AI systémy k dispozícii pre disambiguáciu.
Kontextová obsahová stratégia: Značky môžu vytvárať obsah, ktorý poskytuje jasný kontext o ich identite a odlišuje ich od iných entít s podobným menom. Obsah, ktorý explicitne uvádza odvetvie značky, produkty, zakladateľov a jedinečnú hodnotovú ponuku, pomáha AI systémom pochopiť rozlišovacie znaky značky. Tento kontextový obsah sa stáva súčasťou tréningových dát a kontextu, ktorý AI systémy využívajú pri disambiguácii.
Monitorovanie citácií: Nástroje ako AmICited.com umožňujú značkám monitorovať, ako AI systémy disambiguujú a citujú ich značku na rôznych platformách. Sledovaním toho, či ChatGPT, Perplexity, Google AI Overviews a ďalšie systémy správne identifikujú a citujú značku, môžu značky identifikovať zlyhania disambiguácie a podniknúť nápravné kroky. Toto monitorovanie je zásadné pre pochopenie viditeľnosti značky v ére generatívnej AI.
Optimalizácia pre generatívne enginy (GEO): S rastúcim významom disambiguácie entít pre AI viditeľnosť by značky mali zahrnúť optimalizáciu entít do širšej stratégie Generative Engine Optimization. To zahŕňa zaistenie, že entita značky je jasne definovaná, dobre zdokumentovaná a ľahko rozlíšiteľná od konkurencie. GEO zahŕňa nielen tradičné SEO, ale aj optimalizáciu pre spôsob, akým AI systémy rozumejú a reprezentujú značky.
Disambiguácia entít sa vyvíja spolu s pokrokom AI technológií a novými výzvami. Niekoľko trendov formuje budúcnosť tejto kľúčovej schopnosti.
Viacjazyčná disambiguácia entít: Ako sa AI systémy globalizujú, schopnosť disambiguovať entity naprieč jazykmi je čoraz dôležitejšia. Meno osoby môže byť v rôznych jazykoch napísané rôzne a na rovnakú entitu sa môže v rôznych jazykoch odkazovať rôznymi menami. Vyvíjajú sa pokročilé viacjazyčné modely, ktoré zvládnu disambiguáciu entít cez jazykové bariéry, čo umožní skutočne globálne AI systémy.
Disambiguácia v reálnom čase v rámci veľkých jazykových modelov: Moderné veľké jazykové modely ako GPT-4 a Claude čoraz viac začleňujú real-time disambiguáciu entít počas generovania textu. Namiesto spoliehania sa len na trénovacie dáta môžu tieto modely počas inferencie dotazovať znalostné grafy a externé databázy na overenie informácií o entitách a zabezpečenie presnej disambiguácie. Táto schopnosť zlepšuje presnosť citácií a znižuje halucinácie.
Zlepšené zero-shot učenie: Budúce systémy disambiguácie entít pravdepodobne dosiahnu lepší výkon pri entitách, ktoré neboli v trénovacích dátach. Pokroky vo few-shot a zero-shot učení umožnia systémom efektívnejšie disambiguovať nové entity, znižovať potrebu častého pretrénovania a prispôsobiť sa novým entitám.
Integrácia s Retrieval-Augmented Generation (RAG): Systémy, ktoré kombinujú jazykové modely s vyhľadávaním informácií, sú čoraz populárnejšie. Tieto systémy môžu počas generovania textu vyhľadávať relevantné informácie o entitách v znalostných bázach, čím zlepšujú presnosť disambiguácie aj kvalitu citácií. Táto integrácia predstavuje významný pokrok v zabezpečení presnosti AI citácií.
Štandardizácia a interoperabilita: S rastúcim významom disambiguácie entít pre AI systémy pravdepodobne vzniknú priemyselné štandardy na reprezentáciu a disambiguáciu entít. Tieto štandardy umožnia lepšiu interoperabilitu medzi systémami a znalostnými bázami, čo AI systémom uľahčí konzistentný prístup a využívanie informácií o entitách naprieč platformami.
Disambiguácia entít sa zmenila z okrajovej NLP úlohy na kľúčovú schopnosť pre zabezpečenie toho, aby AI systémy správne rozumeli a reprezentovali informácie. Ako AI stále viac ovplyvňuje spôsob objavovania a konzumácie informácií, význam presnej disambiguácie entít bude len narastať. Pre značky, tvorcov obsahu a organizácie je pochopenie a optimalizácia pre disambiguáciu entít nevyhnutná na udržanie viditeľnosti a zabezpečenie presnej reprezentácie v ére generatívnej AI.
Rozpoznávanie pomenovaných entít identifikuje, že sa v texte nachádza entita, a zaradí ju do kategórií ako osoba, organizácia alebo miesto. Disambiguácia entít ide ďalej a určuje, na ktorú konkrétnu entitu sa odkazuje, keď viacero entít zdieľa rovnaké meno. Napríklad NER identifikuje 'Apple' ako organizáciu, zatiaľ čo disambiguácia entít určí, či ide o Apple Inc., Apple Bank alebo inú entitu.
Disambiguácia entít zabezpečuje, aby AI systémy presne rozumeli, o ktorej entite sa diskutuje, a správne ju citovali. Podľa Stanford AI Index 2024 viac ako 18 % výstupov LLM, ktoré zahŕňajú značkové entity, obsahuje halucinácie alebo nesprávne priradenia. Presná disambiguácia entít zabraňuje AI systémom zamieňať jednu entitu s inou, čo je kľúčové pre udržiavanie dobrej reputácie značky a presnosti citácií.
Znalostné grafy poskytujú štruktúrované informácie o entitách a ich vzťahoch. Keď AI systém narazí na nejednoznačnú zmienku o entite, môže sa dotazovať na znalostný graf, aby získal metadáta, popisy a informácie o vzťahoch medzi kandidátskymi entitami. Tieto kontextové informácie pomáhajú systému prijímať lepšie rozhodnutia pri disambiguácii a vybrať správnu entitu.
Áno, vďaka prístupom zero-shot entity linking. Moderné systémy dokážu rozoznať, keď je entita nová, a správne ju spracovať, namiesto toho, aby ju nesprávne priradili k existujúcej entite. Napriek tomu ide o náročný problém a systémy pracujú lepšie, ak majú nové entity jasné kontextové signály, ktoré ich odlišujú od existujúcich entít.
Presná disambiguácia entít zabezpečuje, že vaša značka je v AI-generovaných odpovediach správne identifikovaná a citovaná. Keď AI systémy správne rozlíšia vašu značku, používatelia získavajú presné informácie o vašej organizácii, čo zlepšuje viditeľnosť a reputáciu značky. Zlá disambiguácia môže viesť k zámene vašej značky s konkurenciou alebo inými entitami, čím sa znižuje viditeľnosť a môže sa poškodiť reputácia.
Medzi hlavné výzvy patrí polysémia (viacero významov pre rovnaké meno), nové entity mimo tréningových dát, variácie mien a preklepy, neúplné alebo zastarané znalostné bázy a problémy so škálovateľnosťou. Niektoré mená entít sú navyše inherentne nejednoznačné a samotný kontext nemusí stačiť na určenie správnej entity.
Značky môžu implementovať štruktúrované dáta pomocou Schema.org značkovania, udržiavať presné záznamy na Wikipédii a Wikidate, vytvárať kontextový obsah, ktorý jasne odlišuje ich značku, a monitorovať, ako AI systémy disambiguujú ich značku pomocou nástrojov ako AmICited. Tieto stratégie pomáhajú AI systémom správne identifikovať a citovať vašu značku.
Kontext je kľúčový pre disambiguáciu entít. Okolitý text, súvisiace entity a sémantické vzťahy poskytujú signály, ktoré pomáhajú AI systémom určiť, na ktorú entitu sa odkazuje. Napríklad ak sa 'Apple' objaví v blízkosti 'Steve Jobs' a 'technológie', systém môže tento kontext využiť na správnu disambiguáciu ako Apple Inc. namiesto ovocia.
Sledujte presnosť disambiguácie entít naprieč AI platformami a zabezpečte, aby bola vaša značka v AI-generovaných odpovediach správne identifikovaná a citovaná.
Rozpoznávanie entít je schopnosť AI a NLP identifikovať a kategorizovať pomenované entity v texte. Zistite, ako funguje, jeho využitie v AI monitoringu a jeho ú...

Naučte sa, ako vybudovať a optimalizovať značkovú entitu pre rozpoznanie umelou inteligenciou. Implementujte schema markup, prepojenie entít a štruktúrované dát...

Preskúmajte, ako AI systémy rozpoznávajú a spracúvajú entity v texte. Zistite viac o modeloch NER, architektúrach transformerov a reálnych aplikáciách porozumen...
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.