
Ako funguje Retrieval-Augmented Generation: Architektúra a proces
Zistite, ako RAG kombinuje LLM s externými zdrojmi dát na generovanie presných AI odpovedí. Porozumiete päťstupňovému procesu, komponentom a významu pre AI syst...
9 min čítania

RAG pipeline (retrieval-augmented generation) je pracovný postup, ktorý umožňuje AI systémom vyhľadávať, hodnotiť a citovať externé zdroje pri generovaní odpovedí. Spája vyhľadávanie dokumentov, sémantické hodnotenie a generovanie cez veľké jazykové modely (LLM) na poskytovanie presných, kontextovo relevantných odpovedí založených na reálnych dátach. RAG systémy znižujú halucinácie tým, že pred generovaním odpovedí konzultujú externé znalostné databázy, vďaka čomu sú nevyhnutné pre aplikácie vyžadujúce faktickú presnosť a uvedenie zdrojov.
RAG pipeline (retrieval-augmented generation) je pracovný postup, ktorý umožňuje AI systémom vyhľadávať, hodnotiť a citovať externé zdroje pri generovaní odpovedí. Spája vyhľadávanie dokumentov, sémantické hodnotenie a generovanie cez veľké jazykové modely (LLM) na poskytovanie presných, kontextovo relevantných odpovedí založených na reálnych dátach. RAG systémy znižujú halucinácie tým, že pred generovaním odpovedí konzultujú externé znalostné databázy, vďaka čomu sú nevyhnutné pre aplikácie vyžadujúce faktickú presnosť a uvedenie zdrojov.
RAG pipeline (retrieval-augmented generation) je AI architektúra, ktorá spája vyhľadávanie informácií s generovaním cez veľký jazykový model (LLM) s cieľom produkovať presnejšie, kontextuálne relevantné a overiteľné odpovede. Namiesto spoliehania sa iba na trénovacie dáta LLM, RAG systémy dynamicky získavajú relevantné dokumenty alebo dáta z externých znalostných databáz ešte pred generovaním odpovedí, čím výrazne znižujú halucinácie a zvyšujú faktickú presnosť. Pipeline pôsobí ako most medzi statickými trénovacími dátami a aktuálnymi informáciami, čo AI systémom umožňuje odkazovať na súčasné, doménovo špecifické či proprietárne obsahy. Tento prístup sa stal nevyhnutným pre organizácie vyžadujúce odpovede podložené citáciami, súlad s požiadavkami na presnosť a transparentnosť AI-generovaného obsahu. RAG pipeline sú obzvlášť cenné pri monitorovaní AI systémov, kde je vysledovateľnosť a atribúcia zdrojov kľúčovou požiadavkou.
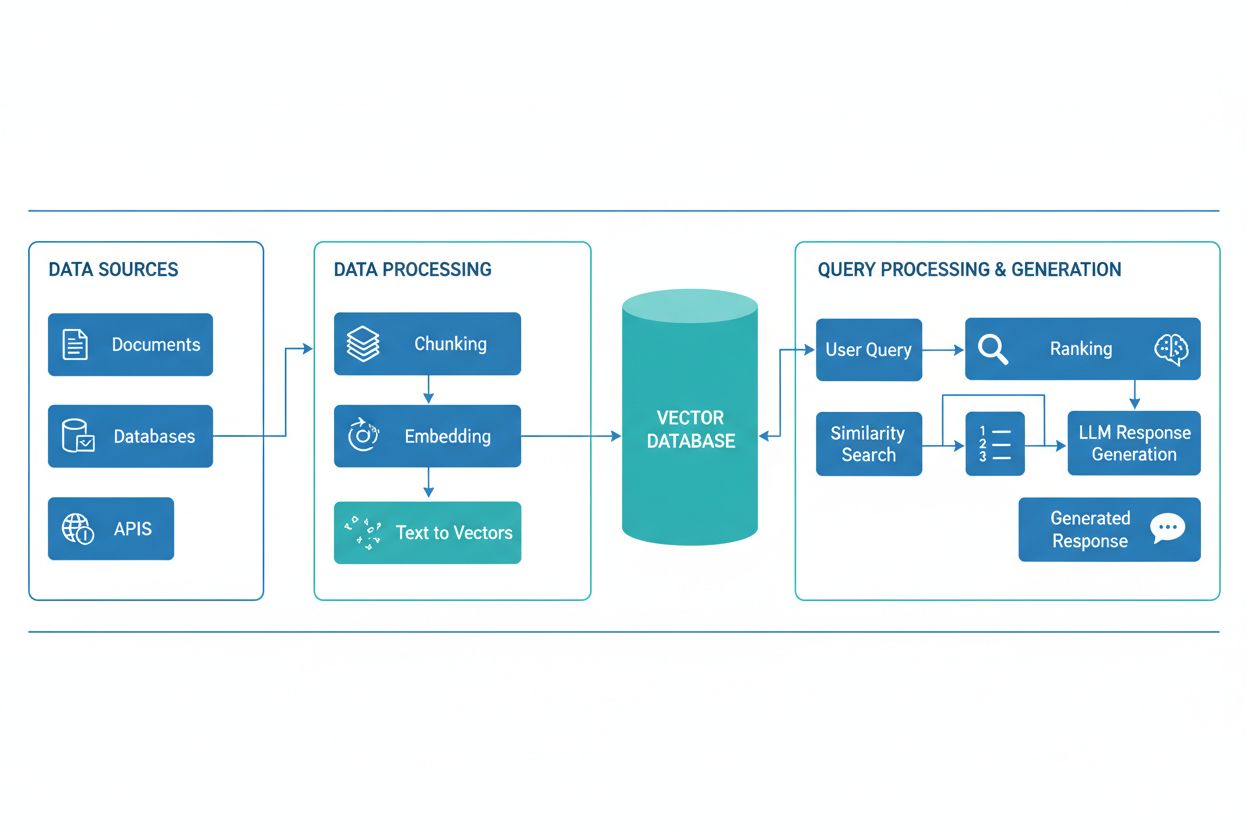
RAG pipeline pozostáva z viacerých prepojených komponentov, ktoré spolupracujú na získaní relevantných informácií a generovaní podložených odpovedí. Architektúra zvyčajne zahŕňa vrstvu na spracovanie a prípravu surových dát (document ingestion), vektorovú databázu alebo znalostnú bázu na ukladanie embeddingov a indexovaného obsahu, vyhľadávací mechanizmus na identifikáciu relevantných dokumentov podľa dopytu používateľa, systém hodnotenia na uprednostnenie najrelevantnejších výsledkov a generovací modul poháňaný LLM, ktorý syntetizuje získané informácie do zmysluplných odpovedí. Medzi ďalšie komponenty patria moduly na spracovanie a predspracovanie dopytov (query processing), embedding modely na prevod textu do číselných reprezentácií a spätnoväzbová slučka na neustále zlepšovanie presnosti vyhľadávania. Orchestrácia týchto komponentov určuje celkovú efektivitu a účinnosť RAG systému.
| Komponent | Funkcia | Kľúčové technológie |
|---|---|---|
| Ingestovanie dokumentov | Spracovanie a príprava surových dát | Apache Kafka, LangChain, Unstructured |
| Vektorová databáza | Ukladanie embeddingov a indexovaného obsahu | Pinecone, Weaviate, Milvus, Qdrant |
| Vyhľadávací engine | Identifikácia relevantných dokumentov | BM25, Dense Passage Retrieval (DPR) |
| Hodnotiaci systém | Uprednostňovanie výsledkov vyhľadávania | Cross-encoders, LLM-based reranking |
| Generačný modul | Syntéza odpovedí z kontextu | GPT-4, Claude, Llama, Mistral |
| Spracovanie dopytov | Normalizácia a porozumenie vstupu používateľa | BERT, T5, vlastné NLP pipeline |
RAG pipeline funguje v dvoch odlišných fázach: fáze vyhľadávania a fáze generovania. Počas vyhľadávacej fázy systém prevedie dopyt používateľa na embedding pomocou toho istého modelu, aký spracoval dokumenty v znalostnej báze, a následne prehľadá vektorovú databázu, aby identifikoval najviac sémanticky podobné dokumenty alebo pasáže. Táto fáza zvyčajne vracia zoradený zoznam kandidátskych dokumentov, ktoré môžu byť ďalej upresnené cez algoritmy na prehodnocovanie (reranking) založené na cross-encoderoch alebo skórovaní LLM. Počas fázy generovania sú najlepšie vyhľadané dokumenty naformátované do kontextového okna a spolu s pôvodným dopytom odovzdané LLM, ktorý následne generuje odpovede zakotvené v reálnych zdrojoch. Tento dvojfázový prístup zaručuje, že odpovede sú nielen kontextovo vhodné, ale aj vysledovateľné až ku konkrétnym zdrojom, čo je ideálne pre aplikácie vyžadujúce citácie a zodpovednosť. Kvalita výsledného výstupu závisí kriticky od relevancie vyhľadaných dokumentov a schopnosti LLM koherentne syntetizovať informácie.
Ekosystém RAG zahŕňa široké spektrum špecializovaných nástrojov a frameworkov určených na zjednodušenie tvorby a nasadzovania pipeline. Moderné RAG implementácie využívajú viacero kategórií technológií:
Tieto nástroje možno kombinovať modulárne, čo organizáciám umožňuje budovať RAG systémy prispôsobené ich konkrétnym požiadavkám a infraštruktúrnym obmedzeniam.
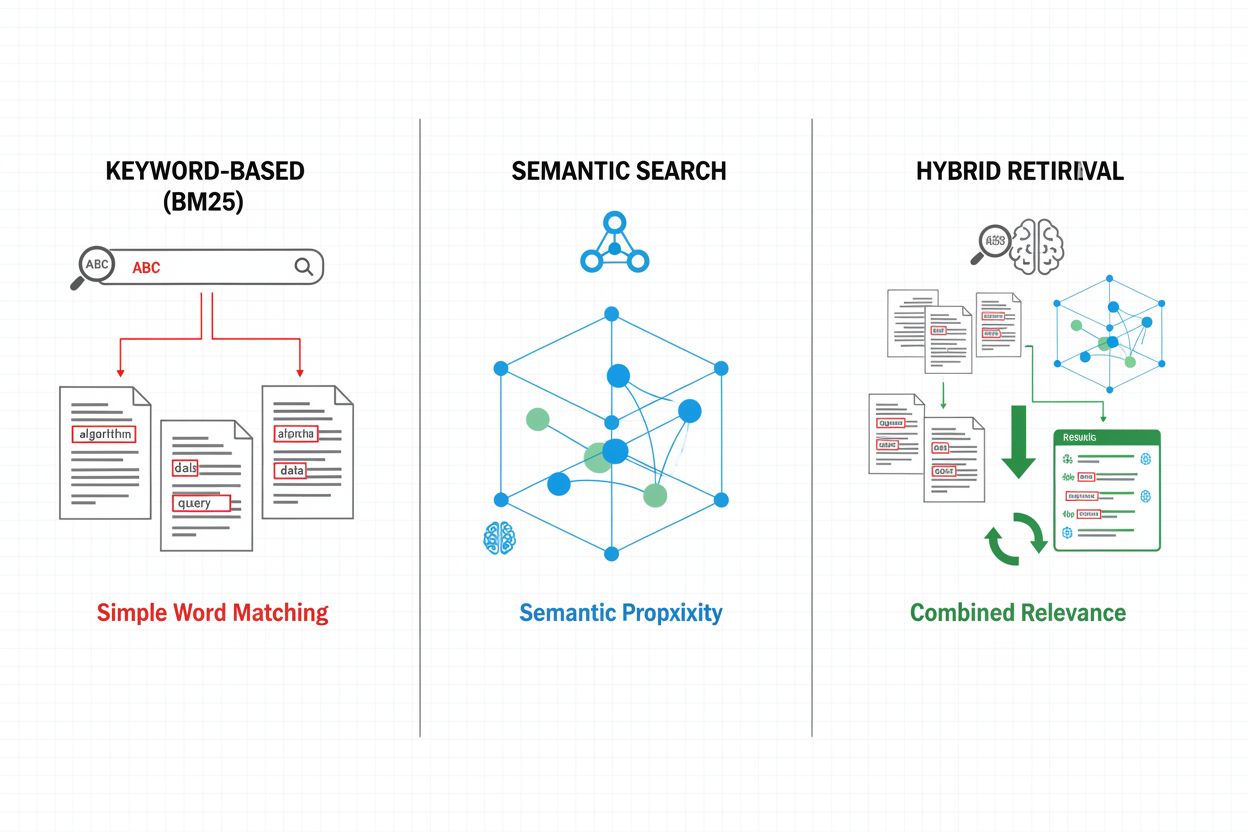
Vyhľadávacie mechanizmy tvoria základ efektivity RAG pipeline – vyvíjali sa od jednoduchých prístupov založených na kľúčových slovách až po sofistikované sémantické vyhľadávanie. Tradičné vyhľadávanie podľa kľúčových slov s využitím algoritmov BM25 je výpočtovo efektívne a účinné pre presné zhodné prípady, no má problém so sémantickým porozumením a synonymami. Dense Passage Retrieval (DPR) a ďalšie neurónové metódy riešia tieto obmedzenia tým, že kódujú dopyty aj dokumenty do hustých vektorových embeddingov, čo umožňuje sémantické párovanie na úrovni významu, nie len povrchových kľúčových slov. Hybridné vyhľadávanie kombinuje silné stránky oboch prístupov (kľúčové slová + sémantika) na zlepšenie recall aj presnosti naprieč rôznymi typmi dopytov. Pokročilé vyhľadávacie mechanizmy zahŕňajú rozširovanie dopytu (query expansion), kde je dopyt rozšírený o príbuzné pojmy alebo preformulovania pre zachytenie relevantnejších dokumentov. Reranking vrstvy ďalej spresňujú výsledky použitím výpočtovo náročnejších modelov, ktoré hodnotia kandidátske dokumenty na základe hlbšieho sémantického porozumenia alebo špecifických kritérií úlohy. Výber vyhľadávacieho mechanizmu významne ovplyvňuje ako presnosť získaného kontextu, tak výpočtové náklady pipeline, preto je potrebné starostlivo zvážiť kompromisy medzi rýchlosťou a kvalitou.
RAG pipeline prinášajú výrazné výhody oproti prístupom založeným len na LLM, najmä pre aplikácie vyžadujúce presnosť, aktuálnosť a vysledovateľnosť. Zakotvením odpovedí v získaných dokumentoch RAG systémy dramaticky znižujú halucinácie – prípady, keď LLM generujú vierohodne znejúce, ale fakticky nesprávne informácie – vďaka čomu sú vhodné pre oblasti s vysokými nárokmi na presnosť ako zdravotníctvo, právo či finančné služby. Možnosť odkazovať na externé znalostné databázy umožňuje poskytovať aktuálne informácie bez potreby preučenia modelov, vďaka čomu môžu organizácie udržiavať odpovede vždy čerstvé. RAG pipeline podporujú doménovú špecializáciu začlenením proprietárnych dokumentov, interných znalostných báz a špecifickej terminológie, čím zabezpečujú relevantnejšie a kontextovo vhodné odpovede. Vyhľadávacia zložka poskytuje transparentnosť a auditovateľnosť explicitným zobrazením, ktoré zdroje ovplyvnili každú odpoveď – to je kľúčové pre compliance a dôveru používateľov. Efektivita nákladov sa zvyšuje využívaním menších, úspornejších LLM, ktoré dokážu generovať kvalitné odpovede pri správne poskytnutom kontexte, čo znižuje výpočtovú záťaž oproti veľkým modelom. Tieto výhody robia RAG mimoriadne hodnotným pre organizácie implementujúce AI monitoring, kde sú presnosť citácií a viditeľnosť obsahu zásadné.
Napriek výhodám čelia RAG pipeline viacerým technickým a prevádzkovým výzvam, ktoré si vyžadujú dôsledné riadenie. Kvalita získaných dokumentov priamo určuje kvalitu odpovedí – chyby vo vyhľadávaní je veľmi ťažké neskôr napraviť (tzv. „garbage in, garbage out“), keď irelevantné či zastarané dokumenty v znalostnej báze preniknú až do finálnych odpovedí. Embedding modely môžu mať problém s doménovou terminológiou, zriedkavými jazykmi alebo vysoko technickým obsahom, čo vedie k slabému sémantickému párovaniu a prehliadaniu relevantných dokumentov. Výpočtové náklady vyhľadávania, generovania embeddingov a prehodnocovania môžu byť vo veľkom meradle značné, hlavne pri veľkých znalostných bázach alebo vysokom objeme dopytov. Obmedzenia kontextového okna v LLM obmedzujú množstvo vyhľadaných informácií, ktoré možno začleniť do promptu, preto je potrebný dôsledný výber a sumarizácia relevantných pasáží. Udržiavanie aktuálnosti a konzistencie znalostnej databázy predstavuje prevádzkové výzvy, hlavne v dynamických prostrediach s častými zmenami alebo viacerými zdrojmi. Hodnotenie výkonu RAG systému vyžaduje komplexné metriky nad rámec tradičnej presnosti – vrátane presnosti vyhľadávania, relevantnosti odpovedí a správnosti citácií, čo býva ťažké automatizovane vyhodnotiť.
RAG predstavuje jeden z viacerých prístupov na zlepšenie presnosti a relevantnosti LLM, pričom každý má svoje špecifické kompromisy. Fine-tuning znamená preučenie LLM na doménovo špecifických dátach, čím poskytuje hlbokú prispôsobiteľnosť modelu, ale vyžaduje značné výpočtové zdroje, anotované dáta a priebežnú údržbu pri zmene informácií. Prompt engineering optimalizuje inštrukcie a kontext poskytované LLM bez zásahu do modelu, ponúka flexibilitu a nízke náklady, ale je limitovaný trénovacími dátami a veľkosťou kontextu. In-context learning využíva málo príkladov priamo v promptoch na rýchlu adaptáciu modelu, no spotrebováva cenné kontextové tokeny a vyžaduje starostlivý výber príkladov. V porovnaní s týmito prístupmi ponúka RAG strednú cestu: poskytuje dynamický prístup k aktuálnym informáciám bez preučenia, zachováva transparentnosť cez explicitnú atribúciu zdrojov a dobre škáluje naprieč rôznymi doménami poznania. RAG však prináša aj dodatočnú zložitosť v podobe vyhľadávacej infraštruktúry a potenciálnych chýb vyhľadávania, zatiaľ čo fine-tuning poskytuje hlbšiu integráciu doménového poznania do správania modelu. Optimálny prístup často spočíva v kombinácii viacerých stratégií – napríklad používanie RAG s fine-tunovanými modelmi a starostlivo navrhnutými promptami na maximalizáciu presnosti a relevantnosti pre konkrétne použitie.
Implementácia produkčnej RAG pipeline vyžaduje systematické plánovanie v oblasti prípravy dát, návrhu architektúry a prevádzkových otázok. Proces začína prípravou znalostnej bázy: zberom relevantných dokumentov, čistením a štandardizáciou formátov a rozdeľovaním obsahu na vhodne veľké časti, ktoré vyvažujú zachovanie kontextu s presnosťou vyhľadávania. Následne organizácie vyberajú embedding modely a vektorové databázy podľa požiadaviek na výkon, latenciu a škálovateľnosť, pričom zohľadňujú dimenzionalitu embeddingov, priepustnosť dopytov a kapacitu úložiska. Vyhľadávací systém sa následne konfiguruje – vrátane výberu vyhľadávacích algoritmov (kľúčové slová, sémantika, hybrid), stratégií prehodnocovania a kritérií filtrovania výsledkov. Nasleduje integrácia s poskytovateľmi LLM, pričom sa definujú promptové šablóny na efektívne začlenenie získaného kontextu. Testovanie a hodnotenie sú kľúčové: vyžadujú metriky na hodnotenie kvality vyhľadávania (precision, recall, MRR), kvality generovania (relevantnosť, koherencia, faktickosť) a celkového výkonu systému. Pri nasadení je potrebné nastaviť monitorovanie presnosti vyhľadávania a generovania, implementovať spätnoväzobné slučky na identifikáciu a riešenie zlyhaní a zaviesť procesy na aktualizáciu a údržbu znalostnej bázy. Kontinuálna optimalizácia zahŕňa analýzu interakcií používateľov, identifikáciu opakujúcich sa zlyhaní a postupné vylepšovanie vyhľadávacích mechanizmov, stratégií prehodnocovania a prompt engineeringu na zvýšenie celkového výkonu systému.
RAG pipeline sú základom moderných AI monitorovacích platforiem, ako je AmICited.com, kde je sledovanie zdrojov a presnosti AI-generovaného obsahu nevyhnutné. Explicitným získavaním a citovaním zdrojových dokumentov vytvárajú RAG systémy auditovateľnú stopu, ktorá umožňuje monitorovacím platformám overovať tvrdenia, hodnotiť faktickú presnosť a identifikovať potenciálne halucinácie alebo nesprávne pripísania. Táto schopnosť citovania rieši zásadný problém transparentnosti AI: používatelia a audítori môžu odpovede spätne vystopovať k pôvodným zdrojom, čo umožňuje nezávislé overenie a buduje dôveru v AI-generovaný obsah. Pre tvorcov obsahu a organizácie využívajúce AI nástroje prináša monitorovanie cez RAG viditeľnosť toho, ktoré zdroje ovplyvnili konkrétne odpovede, čo podporuje súlad s požiadavkami na atribúciu a pravidlami správy obsahu. Vyhľadávacia zložka RAG pipeline generuje bohaté metadáta – vrátane skóre relevancie, poradia dokumentov a metrík istoty vyhľadávania – ktoré môžu monitorovacie systémy analyzovať na posúdenie spoľahlivosti odpovedí a identifikáciu situácií, keď AI pracuje mimo svojej znalostnej domény. Integrácia RAG s monitorovacími platformami umožňuje detekciu „odchýlky citácií“ (citation drift), teda prípadov, keď AI systémy postupne prechádzajú od autoritatívnych zdrojov k menej spoľahlivým, a podporuje vymáhanie politík kvality a diverzity zdrojov. Ako sa AI systémy čoraz viac integrujú do kľúčových pracovných procesov, kombinácia RAG pipeline s komplexným monitoringom vytvára mechanizmy zodpovednosti, ktoré chránia používateľov, organizácie aj širší informačný ekosystém pred AI-generovanými dezinformáciami.
RAG a fine-tuning sú komplementárne prístupy na zlepšenie výkonu veľkých jazykových modelov (LLM). RAG vyhľadáva externé dokumenty v čase dopytu bez toho, aby menil samotný model, čo umožňuje prístup k aktuálnym dátam a jednoduché aktualizácie. Fine-tuning znamená preučenie modelu na doménovo špecifických dátach, čo poskytuje hlbšiu prispôsobiteľnosť, no vyžaduje veľké výpočtové zdroje a manuálne aktualizácie pri zmene informácií. Mnohé organizácie využívajú oba prístupy súčasne pre optimálne výsledky.
RAG znižuje halucinácie tým, že zakotvuje odpovede veľkých jazykových modelov v získaných faktických dokumentoch. Namiesto spoliehania sa len na trénovacie dáta systém pred generovaním vyhľadá relevantné zdroje, čím modelu poskytuje konkrétne dôkazy na citovanie. Tento prístup zabezpečuje, že odpovede sú založené na reálnych informáciách a nie len na naučených vzoroch modelu, čo výrazne zvyšuje faktickú presnosť a znižuje falošné či zavádzajúce tvrdenia.
Vektorové embeddingy sú číselné reprezentácie textu, ktoré zachytávajú sémantický význam v mnohorozmernom priestore. Umožňujú RAG systémom vykonávať sémantické vyhľadávanie, teda nachádzať dokumenty s podobným významom, aj keď používajú iné slová. Embeddingy sú kľúčové, pretože umožňujú RAG prekročiť rámec porovnávania kľúčových slov a pochopiť konceptuálne vzťahy, čím zlepšujú relevanciu vyhľadaných výsledkov a umožňujú presnejšie generovanie odpovedí.
Áno, RAG pipeline môžu zahŕňať dáta v reálnom čase prostredníctvom kontinuálneho prísunu a indexácie. Organizácie si môžu nastaviť automatizované pipeline, ktoré pravidelne aktualizujú vektorovú databázu o nové dokumenty, čím zabezpečujú aktuálnosť znalostnej databázy. Táto schopnosť robí RAG ideálnym pre aplikácie vyžadujúce aktuálne informácie, ako je analýza správ, cenová inteligencia alebo monitoring trhu, bez potreby preučenia základného veľkého jazykového modelu.
Sémantické vyhľadávanie je technika vyhľadávania, ktorá nachádza dokumenty na základe podobnosti významu pomocou vektorových embeddingov. RAG je kompletný pipeline, ktorý kombinuje sémantické vyhľadávanie s generovaním cez veľký jazykový model na vytvorenie odpovedí zakotvených v získaných dokumentoch. Zatiaľ čo sémantické vyhľadávanie sa zameriava na hľadanie relevantných informácií, RAG pridáva generovanie, ktoré syntetizuje získaný obsah do zmysluplných odpovedí aj s citáciami.
RAG systémy využívajú viacero mechanizmov na výber zdrojov na citovanie. Používajú vyhľadávacie algoritmy na nájdenie relevantných dokumentov, modely na prehodnocovanie (reranking) na uprednostnenie najrelevantnejších výsledkov a overovacie procesy na zabezpečenie toho, že citácie naozaj podporujú dané tvrdenia. Niektoré systémy používajú prístup „citovať počas písania“, kde sa tvrdenia uvádzajú iba vtedy, ak sú podložené získanými zdrojmi, iné overujú citácie po generovaní a odstránia nepodložené tvrdenia.
Kľúčové výzvy zahŕňajú udržiavanie aktuálnosti a kvality znalostnej databázy, optimalizáciu presnosti vyhľadávania naprieč rôznorodým obsahom, riadenie výpočtových nákladov vo veľkom meradle, zvládanie doménovej terminológie, ktorú embedding modely nemusia dobre chápať, a hodnotenie výkonu systému pomocou komplexných metrík. Organizácie tiež musia riešiť limity kontextového okna veľkých jazykových modelov a zabezpečiť relevanciu získaných dokumentov, keď sa informácie časom menia.
AmICited sleduje, ako AI systémy ako ChatGPT, Perplexity a Google AI Overviews získavajú a citujú obsah prostredníctvom RAG pipeline. Platforma monitoruje, ktoré zdroje sú vybrané na citovanie, ako často sa vaša značka objavuje v AI odpovediach a či sú citácie presné. Táto viditeľnosť pomáha organizáciám pochopiť ich prítomnosť v AI sprostredkovanom vyhľadávaní a zabezpečiť správne pripísanie ich obsahu.
Sledujte, ako AI systémy ako ChatGPT, Perplexity a Google AI Overviews odkazujú na váš obsah. Získajte prehľad o RAG citáciách a monitorovaní AI odpovedí.
Zistite, ako RAG kombinuje LLM s externými zdrojmi dát na generovanie presných AI odpovedí. Porozumiete päťstupňovému procesu, komponentom a významu pre AI syst...
Zistite, čo je RAG (Retrieval-Augmented Generation) v AI vyhľadávaní. Objavte, ako RAG zlepšuje presnosť, znižuje halucinácie a poháňa ChatGPT, Perplexity a Goo...

Zistite, čo je Retrieval-Augmented Generation (RAG), ako funguje a prečo je dôležitý pre presné odpovede AI. Preskúmajte architektúru RAG, jeho výhody a podniko...
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.