Anatomin av ett AI-genererat svar: Var citat förekommer
Lär dig hur AI-modeller genererar svar och placerar citat. Upptäck var ditt innehåll visas i ChatGPT, Perplexity och Google AI-svar, och hur du optimerar för AI-synlighet.
Publicerad den Jan 3, 2026.Senast ändrad den Jan 3, 2026 kl 3:24 am
Anatomin av ett AI-genererat svar: Var citat förekommer
AI-genererade svar har blivit den främsta upptäcktsmetoden för miljoner användare och omformar i grunden hur information flödar över internet. Enligt färsk forskning ökade AI-användningen bland forskare till 84 % år 2025, med 62 % som specifikt använder AI-verktyg för forskning och publikationer – en dramatisk ökning från endast 57 % total AI-användning år 2024. Ändå är de flesta innehållsskapare omedvetna om att citatplacering i dessa AI-genererade svar inte är slumpmässig; den följer en sofistikerad teknisk arkitektur som avgör vilka källor som får synlighet och vilka som förblir osynliga. Att förstå var och varför citat dyker upp är nu avgörande för alla som vill behålla synlighet i ett AI-drivet upptäcktslandskap.
Modell-nativ syntes vs Retrieval-Augmented Generation
Skillnaden mellan modell-nativ syntes och Retrieval-Augmented Generation (RAG) formar i grunden hur citat syns i AI-svar. Modell-nativ syntes bygger helt på kunskap som kodats in under träningen, medan RAG dynamiskt hämtar externa källor för att förankra svaren i aktuell information. Denna skillnad har djupgående konsekvenser för citatplacering och synlighet.
Egenskap
Modell-nativ syntes
RAG
Definition
Svar genererade enbart från träningsdata
Svar förankrade i realtids-hämtade källor
Hastighet
Snabbare (ingen hämtning krävs)
Långsammare (kräver hämtning)
Noggrannhet
Risk för hallucinationer och föråldrad info
Högre noggrannhet med aktuella källor
Citatkapacitet
Begränsade eller inga citat
Rika, spårbara citat
Användningsområden
Allmän kunskap, kreativa uppgifter
Nyheter, forskning, faktakoll, proprietär data
RAG-baserade system som Perplexity och Googles AI Overviews producerar naturligt fler citat eftersom de måste referera sina hämtade källor, medan modell-nativa tillvägagångssätt som traditionella ChatGPT-svar kan citera mer sällan. Att förstå vilken metod en plattform använder hjälper innehållsskapare att förutse sannolikheten för citat och optimera därefter.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
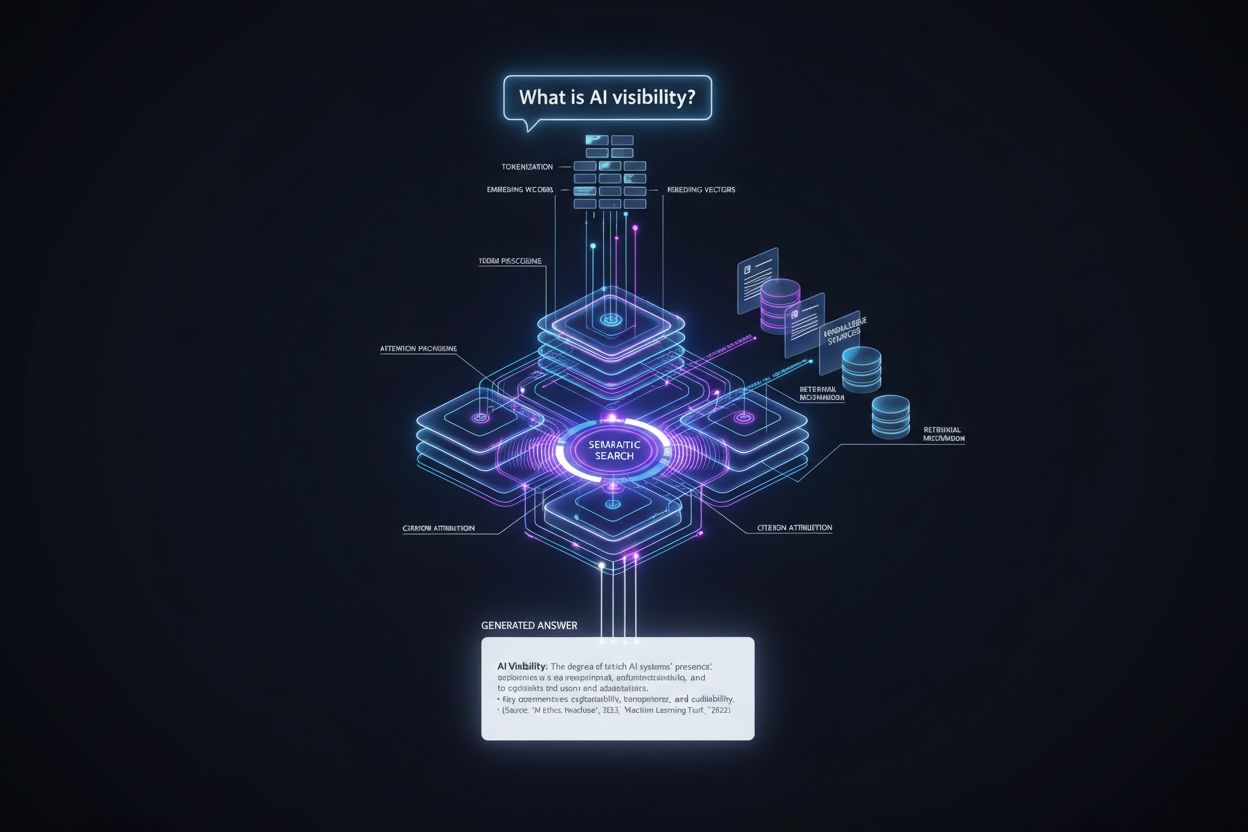
Vägen från användarfråga till citerat svar följer en exakt teknisk pipeline som avgör citatplacering i flera steg. Så här ser processen ut:
Frågebearbetning: Användarens fråga tokeniseras – delas upp i diskreta enheter som modellen förstår – och analyseras för syfte, entiteter och semantisk betydelse via inbäddningsvektorer.
Informationshämtning: Systemet söker i sin kunskapsbas (träningsdata, indexerade dokument eller realtidskällor) med semantisk sökning, matchar frågans betydelse snarare än exakta nyckelord, och returnerar kandidatkällor rangordnade efter relevans.
Kontextuppbyggnad: Hämtad information organiseras i ett kontextfönster – mängden text modellen kan bearbeta samtidigt – där de mest relevanta källorna placeras framträdande för att påverka uppmärksamhetsmekanismer.
Tokingenerering: Modellen genererar svaret en token i taget och använder självuppmärksamhet för att avgöra vilka tidigare genererade token och källinformation som ska påverka varje ny token, vilket skapar sammanhängande, kontextuellt förankrade svar.
Citatattribution: Under tokensgenerering spårar modellen vilka källdokument som påverkat specifika påståenden, tilldelar trovärdighetspoäng och avgör om den ska inkludera explicita citat baserat på säkerhetsnivå och plattformsregler.
Utleverans av svar: Det slutliga svaret formateras enligt plattformens specifikationer – inline-citat, fotnoter, källpaneler eller hover-over-länkar – och levereras till användaren med metadata om källans auktoritet och relevans.
Citatplacering på stora plattformar
Citatplacering varierar drastiskt mellan AI-plattformar och skapar olika synlighetsmöjligheter för innehållsskapare. Så här hanterar de stora plattformarna citat:
ChatGPT: Citat visas i en separat “Källor”-panel under svaret, vilket kräver att användaren aktivt klickar för att se dem. Källorna är vanligtvis begränsade till 3-5 länkar och prioriterar domäner med hög auktoritet.
Perplexity: Citat är inbäddade inline genom hela svaret med upphöjda siffror och en komplett källista längst ner. Varje påstående är spårbart, vilket gör den till den mest citat-transparenta plattformen.
Google Gemini: Citat visas som inline-länkar i svaret, med en sektion “Källor” som listar allt refererat material. Integrationen med Googles kunskapsgraf påverkar vilka källor som väljs.
Claude: Citat presenteras i fotnot-stil med klamrar, så att användare kan se källor utan att lämna svarflödet. Claude betonar källdiversitet och trovärdighet.
DeepSeek: Citat visas som inline-hyperlänkar med minimal visuell åtskillnad, vilket speglar ett mer integrerat tillvägagångssätt där källor vävs sömlöst in i texten.
Dessa skillnader innebär att en källa som citeras av Perplexity kan få direkt trafik, medan samma källa som citeras av ChatGPT kan förbli osynlig om inte användaren klickar på källpanelen. Plattformsunika citatmönster påverkar direkt trafik och synlighet.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Hämtning och citatplacering
Det är i hämtningen som beslut om citatplacering fattas, långt innan svaret genereras. Semantisk sökning omvandlar både användarfrågan och indexerade dokument till vektorinbäddningar – numeriska representationer som fångar betydelse istället för nyckelord. Systemet beräknar sedan likhetspoäng mellan frågeinbäddningen och dokumentinbäddningarna för att identifiera vilka källor som är semantiskt närmast användarens avsikt.
Rankningsalgoritmer ordnar därefter dessa kandidater efter flera signaler: relevanspoäng, domänauktoritet, innehållets aktualitet, användarengagemang och strukturerad datakvalitet. Källor som rankas högst i detta hämtsteg har större sannolikhet att inkluderas i kontextfönstret som matas till genereringsmodellen, och blir därför oftare citerade. Det är därför en väloptimerad, semantiskt tydlig artikel från en auktoritativ domän hämtas och citeras oftare än en dåligt strukturerad artikel från en nyare domän, även om båda innehåller korrekt information. Hämtsteget avgör i princip citatpoolen innan genereringen ens börjar.
Hur innehållsstruktur påverkar sannolikheten för citat
Innehållsstruktur är inte bara en UX-fråga – det påverkar direkt om AI-system kan extrahera, förstå och citera ditt innehåll. AI-modeller är beroende av formateringssignaler för att identifiera informationsgränser och relationer. Här är strukturelementen som maximerar sannolikheten för citat:
Svarsförst-struktur: Börja med det direkta svaret på vanliga frågor så att AI-system snabbt kan identifiera och extrahera den mest relevanta informationen utan att behöva gå igenom inledande material.
Tydliga rubriker: Använd beskrivande H2- och H3-rubriker som tydligt anger ämnet för varje sektion och hjälper AI-system att förstå innehållsorganisationen och extrahera relevanta delar för specifika frågor.
Optimal styckeslängd: Håll styckena till 3–5 meningar för att göra det lättare för AI-system att identifiera enskilda påståenden och tillskriva dem till specifika källor utan tvetydighet.
Listor och tabeller: Strukturerad data i punktlistor och tabeller är lättare för AI-system att tolka och citera än prosa, eftersom individuella påståenden och deras gränser är tydliga.
Entitetstydlighet: Nämn personer, organisationer, produkter och begrepp explicit istället för att använda pronomen, så att AI-system förstår exakt vad varje påstående avser och kan citera korrekt.
Schema-markering: Implementera strukturerad data (Schema.org) för att ge explicit metadata om innehållstyp, författare, publiceringsdatum och påståenden, vilket ger AI-system ytterligare signaler för utvärdering och citat.
Innehåll som följer dessa strukturella principer citeras 2–3 gånger oftare än dåligt strukturerat innehåll, oavsett kvalitet, eftersom det helt enkelt är lättare för AI-system att extrahera och tillskriva.
Processen för citatattribution
När källor har hämtats och sammanställts i kontextfönstret utvärderar modellen varje källa genom flera trovärdighetsfilter innan den avgör om den ska citeras. Källtrovärdighetsutvärdering tar hänsyn till domänauktoritet (mätt genom länkprofiler, domänålder och varumärkeskännedom), författarens expertis (upptäcks via bylines, författarbiografier och kompetenssignaler) samt tematisk relevans (om källans huvudsakliga fokus stämmer överens med frågan).
Relevanspoäng mäter hur direkt källan besvarar den specifika frågan, där exakta svar får högre poäng än indirekt information. Aktualitetsfaktorer påverkar om nyare källor föredras framför äldre – kritiskt för nyheter, forskning och snabbrörliga ämnen. Auktoritetssignaler inkluderar citat från andra auktoritativa källor, omnämnande i akademiska databaser och närvaro i kunskapsgrafer. Metadata utgörs av titel-taggar, metabeskrivningar och strukturerad data som explicit kommunicerar innehållets syfte och trovärdighet. Slutligen ger strukturerad data (Schema.org-markering) explicita trovärdighetssignaler som modellen direkt kan tolka, inklusive författaruppgifter, publiceringsdatum, recensionsbetyg och faktakollstatus. Källor med omfattande schema-markering citeras pålitligare eftersom modellen får maskinläsbar bekräftelse på deras påståenden.
Vanliga mönster för citatplacering
AI-plattformar använder olika citatstilar som påverkar hur synliga dina citat är för användarna. Här är de vanligaste mönstren:
Inline-citat (Perplexity-stil):
“Enligt ny forskning ökade AI-användningen bland forskare till 84 % år 2025[1], med 62 % som specifikt använder AI-verktyg för forskningsuppgifter[2].”
Slut-på-stycke-citat (Claude-stil):
“AI-användningen bland forskare ökade till 84 % år 2025, med 62 % som specifikt använder AI-verktyg för forskningsuppgifter. [Källa: Wiley Research Report, 2025]”
Fotnot-citat (Akademisk metod):
“AI-användningen bland forskare ökade till 84 % år 2025¹, med 62 % som specifikt använder AI-verktyg för forskningsuppgifter².”
Källistor (ChatGPT-stil):
Svarstext utan inline-citat, följt av en separat “Källor”-sektion med 3–5 länkar.
Hover-over-citat (Framväxande mönster):
Understruken text som visar källinformation när användaren hovrar, vilket minimerar visuell oreda men bibehåller spårbarhet.
Varje stil skapar olika användarbeteenden: inline-citat leder till omedelbara klick, källistor kräver aktiv handling, och hover-over-citat balanserar synlighet och estetik. Sannolikheten att ditt innehåll citeras varierar mellan plattformarna, vilket gör övervakning på flera plattformar nödvändigt.
Affärseffekter av citatplacering
Att förstå mekaniken bakom citatplacering leder direkt till mätbara affärsresultat. Trafikpåverkan är omedelbar: källor som citeras inline av Perplexity får 3–5 gånger mer hänvisningstrafik än källor som bara syns i ChatGPT:s källpanel, eftersom användare är mer benägna att klicka på citat de ser under läsning. Förhållandet mellan synlighet och klickfrekvens är inte linjärt – att bli citerad är bara värdefullt om användaren faktiskt klickar, vilket beror på placering, plattform och kontext.
Varumärkesauktoritet förstärks över tid: källor som konsekvent citeras av flera AI-plattformar bygger starkare auktoritetssignaler, vilket förbättrar deras ranking i traditionella sökningar och ökar sannolikheten för framtida AI-citat. Detta skapar en positiv spiral där citerat innehåll blir mer auktoritativt och får fler citat. Konkurrensfördel uppstår för varumärken som optimerar för AI-citat före konkurrenterna – de som tidigt implementerar schema och optimerar struktur får för tillfället en oproportionerligt stor andel av citaten. SEO-effekter sträcker sig bortom AI: innehåll som är optimerat för AI-citat presterar oftast bättre även i traditionell sökning, eftersom samma strukturella tydlighet och auktoritetssignaler gynnar båda systemen. AmICiteds värde blir tydligt: i ett AI-drivet upptäcktslandskap är att inte veta om du blir citerad lika kritiskt som att inte veta dina sökplaceringar – det är en blind fläck i din synlighetsstrategi.
Praktiska råd för innehållsskapare
Att optimera för AI-citat kräver specifika, handlingsbara förändringar i hur du skapar och strukturerar innehåll. Här är de mest effektiva taktikerna:
Strukturera för extraherbarhet: Använd tydliga rubriker, korta stycken och listor så att AI-system enkelt kan tolka och extrahera specifika påståenden utan tvetydighet.
Använd tydliga, citerbara fakta: Inled med specifika siffror, datum och namngivna entiteter istället för vaga generaliseringar. AI-system citerar konkreta påståenden hellre än abstrakta.
Implementera schema-markering: Lägg till Schema.org-markering för Article, NewsArticle eller ScholarlyArticle, inklusive författare, publiceringsdatum och påståendespecifik metadata som AI-system direkt kan tolka.
Upprätthåll entitetskonsistens: Använd samma namn på personer, organisationer och begrepp genom hela innehållet och undvik pronomen och förkortningar som skapar tvetydighet för AI.
Citera dina källor: När du citerar andra källor i ditt innehåll signalerar du till AI att ditt innehåll är väl underbyggt och trovärdigt, vilket ökar chansen att själv bli citerad.
Testa med AI-verktyg: Sök regelbundet på dina ämnen i ChatGPT, Perplexity, Gemini och Claude för att se om och hur ditt innehåll citeras.
Övervaka resultatet: Spåra vilka delar av ditt innehåll som citeras, av vilka plattformar och i vilket sammanhang, och använd denna data för att förfina din optimeringsstrategi.
Innehållsskapare som implementerar dessa taktiker ser citatfrekvensen öka med 40–60 % inom 3–6 månader, med motsvarande ökning i hänvisningstrafik och varumärkesauktoritet.
Övervakning och mätning av citat
Citatövervakning är inte längre valfritt – det är grundläggande infrastruktur för att förstå din synlighet i det AI-drivna upptäcktslandskapet. Varför övervakning är viktigt är enkelt: du kan inte optimera det du inte mäter, och citatmönster förändras när AI-system utvecklas och nya plattformar lanseras. Vilka mätvärden att följa inkluderar citatfrekvens (hur ofta du citeras), citatplacering (inline vs. källista), plattformsfördelning (vilka plattformar citerar dig mest), frågekontext (vilka ämnen utlöser dina citat) och trafikattribution (hur mycket trafik som kommer från AI-citat).
Identifiering av möjligheter kräver analys av citatgap: ämnen där konkurrenter citeras men inte du, plattformar där du är underrepresenterad, och innehållstyper som underpresterar. Denna analys avslöjar konkreta optimeringsmål – kanske saknar dina guider schema-markering, eller så dyker inte ditt forskningsinnehåll upp i Perplexity eftersom det inte är strukturerat för inline-extraktion.
AmICited löser övervakningsutmaningen genom att spåra dina citat i ChatGPT, Perplexity, Gemini, Claude och andra stora AI-plattformar i realtid. Istället för att manuellt söka dina ämnen gång på gång, övervakar AmICited automatiskt citatmönster, varnar dig för nya citat och ger konkurrensdata så att du kan jämföra din citatprestanda mot konkurrenter. För innehållsskapare, marknadsförare och SEO-proffs förvandlar AmICited citatövervakning från en manuell, tidskrävande process till ett automatiserat system som ger handlingsbara insikter. I ett AI-drivet upptäcktslandskap är det lika viktigt att veta var ditt innehåll citeras som att veta dina sökrankningar – och AmICited gör den synligheten möjlig i stor skala.
Vanliga frågor
Vad är skillnaden mellan modell-nativa och RAG-baserade svar?
Modell-nativa svar kommer från mönster som lärts in under träning, medan RAG hämtar aktuell data innan svar genereras. RAG ger vanligtvis bättre citat eftersom svaren grundas i specifika källor, vilket gör dem mer transparenta och spårbara för användare och innehållsskapare.
Varför citerar vissa AI-plattformar källor medan andra inte gör det?
Olika plattformar använder olika arkitekturer. Perplexity och Gemini prioriterar RAG med citat, medan ChatGPT som standard använder modell-nativ generering om inte webbläsning är aktiverad. Valet speglar varje plattforms designfilosofi och syn på transparens.
Hur påverkar innehållsstruktur om AI citerar ditt innehåll?
Tydligt, välstrukturerat innehåll med direkta svar, korrekta rubriker och schema-markering är lättare för AI-system att extrahera. Innehåll som inleds med svar och använder listor och tabeller citeras oftare eftersom det är lättare för AI att tolka och tillskriva.
Vilken roll spelar schema-markering för citatplacering?
Schema-markering hjälper AI-system att förstå innehållsstruktur och entitetsrelationer, vilket gör det lättare att korrekt tillskriva och citera ditt innehåll. Korrekt schema-implementering ökar sannolikheten för citat och hjälper AI-system att verifiera innehållets trovärdighet.
Kan jag optimera mitt innehåll för att synas i AI-genererade svar?
Ja. Fokusera på svarsförst-struktur, tydlig formatering, faktamässig korrekthet, trovärdiga källor och korrekt schema-implementering. Övervaka dina citat och iterera baserat på resultatdata för att kontinuerligt förbättra din AI-synlighet.
Hur spårar jag var mitt varumärke syns i AI-genererade svar?
Verktyg som AmICited övervakar dina varumärkesomnämnanden i ChatGPT, Perplexity, Google AI Overviews och andra plattformar, och visar exakt var och hur du citeras i AI-svar. Detta ger handlingsbara insikter för optimering.
Påverkar det mina sökrankningar att bli citerad av AI?
Även om AI-citat inte direkt påverkar Googles ranking, ökar de varumärkessynlighet och auktoritetssignaler. Att bli citerad av AI kan driva trafik och stärka din närvaro online, vilket ger indirekta SEO-fördelar.
Vad är relationen mellan traditionell SEO och AI-citatoptimering?
De kompletterar varandra. Traditionell SEO fokuserar på ranking i sökresultat, medan AI-citatoptimering fokuserar på att synas i AI-genererade svar. Båda är viktiga för omfattande synlighet i dagens upptäcktslandskap.
Övervaka din AI-synlighet på alla plattformar
Förstå exakt var ditt varumärke visas i AI-genererade svar. Spåra citat i ChatGPT, Perplexity, Google AI Overviews och fler med AmICited.
Vad avgör egentligen om AI citerar ditt innehåll? Försök att reverse-engineera citeringsalgoritmen
Diskussion i communityn om hur AI-modeller bestämmer vad som ska citeras. Riktiga erfarenheter från SEOs som analyserar citeringsmönster hos ChatGPT, Perplexity...
Vilka innehållsformat får flest AI-citat? Dataanalys
Upptäck vilka innehållsformat som citeras mest av AI-modeller. Analysera data från över 768 000 AI-citat för att optimera din innehållsstrategi för ChatGPT, Per...
Funktionsjämförelsesidor är plötsligt vårt mest citerade innehåll inom AI – är det fler som ser detta mönster?
Diskussion i communityn om varför jämförelseinnehåll presterar exceptionellt bra i AI-sökcitat. Riktig data och strategier för att skapa jämförelseinnehåll som ...
6 min läsning
Discussion
Comparison Content
+1
Cookie-samtycke Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.