
AI-crawlers förklarade: GPTBot, ClaudeBot och fler
Förstå hur AI-crawlers som GPTBot och ClaudeBot fungerar, deras skillnader från traditionella sökmotor-crawlers och hur du optimerar din webbplats för synlighet...
12 min läsning

Lär dig hur AI-crawlers påverkar serverresurser, bandbredd och prestanda. Upptäck verkliga statistik, strategier för att mildra påverkan och infrastrukturlösningar för att effektivt hantera bot-belastning.
AI-crawlers har blivit en betydande kraft inom webbtrafik, där stora AI-företag använder sofistikerade botar för att indexera innehåll för träning och hämtning. Dessa crawlers arbetar i stor skala och genererar ungefär 569 miljoner förfrågningar per månad över webben och förbrukar över 30TB bandbredd globalt. De främsta AI-crawlers är GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity AI), Google-Extended (Google) och Amazonbot (Amazon), var och en med särskilda crawlmönster och resurskrav. Att förstå dessa crawlers beteende och karaktäristika är avgörande för webbplatsadministratörer för att hantera serverresurser korrekt och fatta informerade beslut om åtkomstpolicyer.
| Crawler-namn | Företag | Syfte | Förfrågningsmönster |
|---|---|---|---|
| GPTBot | OpenAI | Träningsdata för ChatGPT och GPT-modeller | Aggressiva, högfrekventa förfrågningar |
| ClaudeBot | Anthropic | Träningsdata för Claude AI-modeller | Måttlig frekvens, respektfull crawling |
| PerplexityBot | Perplexity AI | Realtidssökning och svarsgenerering | Måttlig till hög frekvens |
| Google-Extended | Utökad indexering för AI-funktioner | Kontrollerad, följer robots.txt | |
| Amazonbot | Amazon | Produkt- och innehållsindexering | Variabel, handelsfokuserad |
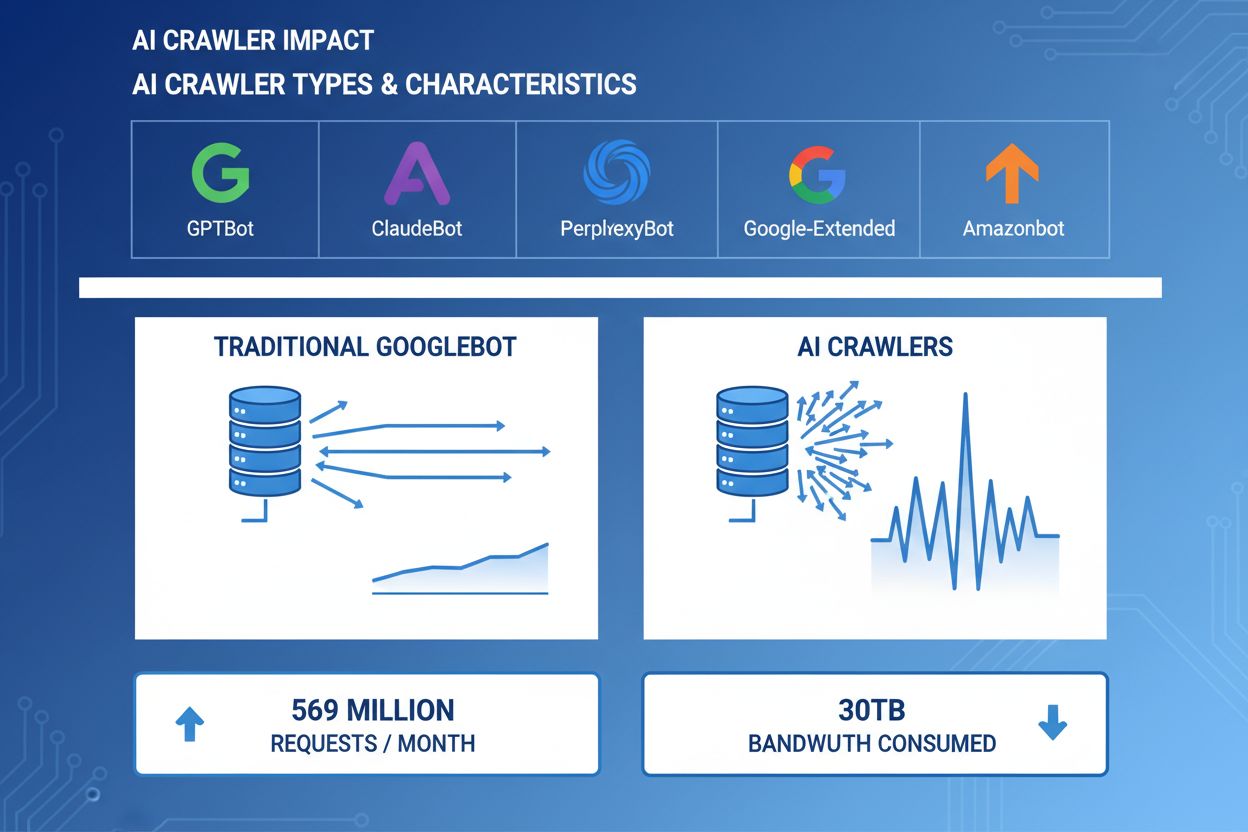
AI-crawlers förbrukar serverresurser på flera nivåer och skapar mätbara effekter på infrastrukturens prestanda. CPU-användning kan öka med 300% eller mer vid intensiv crawleraktivitet, då servrar behandlar tusentals samtidiga förfrågningar och tolkar HTML-innehåll. Bandbreddsförbrukning är en av de mest uppenbara kostnaderna, där en populär webbplats kan servera gigabyte data till crawlers dagligen. Minnesanvändningen ökar markant när servrar upprätthåller anslutningspooler och buffrar stora datamängder för bearbetning. Databasfrågor mångdubblas när crawlers begär sidor som utlöser dynamisk innehållsgenerering och skapar ytterligare I/O-belastning. Disk-I/O blir en flaskhals när servern måste läsa från lagring för att svara på crawlerförfrågningar, särskilt för webbplatser med stora innehållsbibliotek.
| Resurs | Påverkan | Verkligt exempel |
|---|---|---|
| CPU | 200-300% toppar vid intensiv crawling | Serverns belastningssnitt stiger från 2.0 till 8.0 |
| Bandbredd | 15-40% av total månadsförbrukning | 500GB-sajt som levererar 150GB till crawlers per månad |
| Minne | 20-30% ökning i RAM-förbrukning | 8GB server kräver 10GB under crawleraktivitet |
| Databas | 2-5x ökning i frågebelastning | Svarstider ökar från 50ms till 250ms |
| Disk-I/O | Ihållande höga läsoperationer | Diskanvändning hoppar från 30% till 85% |
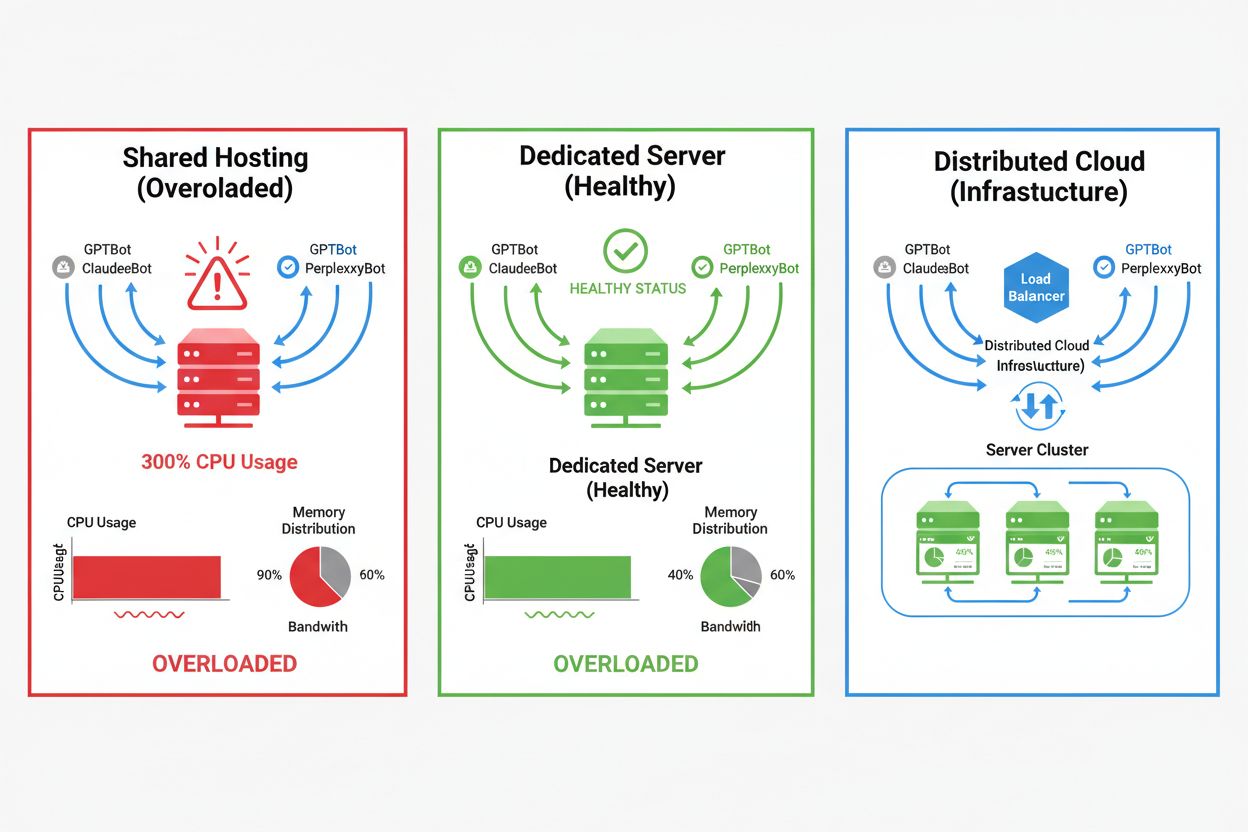
Påverkan från AI-crawlers varierar kraftigt beroende på din hostingmiljö, där delad hosting drabbas hårdast. I delade hosting-scenarier uppstår det så kallade “noisy neighbor syndrome” – när en webbplats på en delad server lockar till sig tung crawlertrafik, förbrukar den resurser som annars skulle vara tillgängliga för övriga webbplatser, vilket försämrar prestandan för alla användare. Dedikerade servrar och molninfrastruktur erbjuder bättre isolering och resursgaranti, vilket gör det möjligt att absorbera crawlertrafik utan att påverka andra tjänster. Men även dedikerad infrastruktur kräver noggrann övervakning och skalning för att hantera den samlade lasten från flera AI-crawlers samtidigt.
Viktiga skillnader mellan hostingmiljöer:
Den ekonomiska effekten av AI-crawlertrafik sträcker sig bortom rena bandbreddskostnader och omfattar både direkta och dolda utgifter som kan påverka din lönsamhet avsevärt. Direkta kostnader inkluderar ökade bandbreddskostnader från din hostingleverantör, vilket kan innebära hundratals eller tusentals kronor extra per månad beroende på trafikvolym och crawlerintensitet. Dolda kostnader uppstår genom ökade infrastrukturkrav – du kan behöva uppgradera till högre hostingnivåer, implementera extra cachelager eller investera i CDN-tjänster enbart för att hantera crawlertrafik. ROI-beräkningen blir komplex när man beaktar att AI-crawlers ger minimalt direkt värde till ditt företag samtidigt som de förbrukar resurser som kunde gynna betalande kunder eller förbättra användarupplevelsen. Många webbplatsägare upptäcker att kostnaderna för att tillåta crawlertrafik överstiger potentiella fördelar från AI-modellträning eller synlighet i AI-drivna sökresultat.
AI-crawlertrafik försämrar direkt användarupplevelsen för legitima besökare genom att förbruka serverresurser som annars skulle serva mänskliga användare snabbare. Core Web Vitals-metriker försämras mätbart, där Largest Contentful Paint (LCP) ökar med 200-500ms och Time to First Byte (TTFB) försämras med 100-300ms under perioder av hög crawleraktivitet. Denna prestandaförsämring leder till kaskadeffekter: långsammare sidladdning minskar engagemanget, ökar avvisningsfrekvensen och minskar slutligen konverteringsgraden för e-handel och leadgenereringssajter. Sökresultaten påverkas även, eftersom Googles rankningsalgoritm inkluderar Core Web Vitals som rankningsfaktor, vilket skapar en ond cirkel där crawlertrafik indirekt skadar din SEO-prestanda. Användare som upplever långsam laddning lämnar oftare din sajt och besöker konkurrenter, vilket direkt påverkar intäkter och varumärkesuppfattning.
Effektiv hantering av AI-crawlertrafik börjar med omfattande övervakning och detektion, så att du kan förstå omfattningen av problemet innan du inför lösningar. De flesta webbservrar loggar user-agent-strängar som identifierar vilken crawler som gör varje förfrågan, vilket utgör grunden för trafikanalys och filtreringsbeslut. Serverloggar, analysplattformar och specialiserade övervakningsverktyg kan tolka dessa user-agent-strängar för att identifiera och kvantifiera crawlertrafikmönster.
Viktiga detektionsmetoder och verktyg:
Första försvarslinjen mot överdriven AI-crawlertrafik är att implementera en välkonfigurerad robots.txt-fil som explicit styr crawleråtkomst till din webbplats. Denna enkla textfil, placerad i webbplatsens rotkatalog, gör det möjligt att förbjuda specifika crawlers, begränsa crawl-frekvens och styra crawlers till en sitemap med endast det innehåll du vill ha indexerat. Begränsning av förfrågningsfrekvens på applikations- eller servernivå ger ytterligare skydd, genom att strypa förfrågningar från specifika IP-adresser eller user-agents för att förhindra resursutarmning. Dessa strategier är icke-blockerande och reversibla, vilket gör dem lämpliga som startpunkt innan mer aggressiva åtgärder vidtas.
# robots.txt - Blockera AI-crawlers men tillåt legitima sökmotorer
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: CCBot
Disallow: /
# Tillåt Google och Bing
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Crawl-delay för alla andra botar
User-agent: *
Crawl-delay: 10
Request-rate: 1/10s
Web Application Firewalls (WAF) och Content Delivery Networks (CDN) ger sofistikerat, företagsklassat skydd mot oönskad crawlertrafik genom beteendeanalys och intelligent filtrering. Cloudflare och liknande CDN-leverantörer erbjuder inbyggda bot-hanteringsfunktioner som kan identifiera och blockera AI-crawlers utifrån beteendemönster, IP-rykte och förfrågningskaraktäristik utan att manuell konfiguration krävs. WAF-regler kan konfigureras för att utmana misstänkta förfrågningar, begränsa specifika user-agents eller blockera trafik från kända crawler-IP-intervall helt och hållet. Dessa lösningar arbetar vid edge och filtrerar skadlig trafik innan den når din ursprungsserver, vilket dramatiskt minskar belastningen på din infrastruktur. Fördelen med WAF- och CDN-lösningar är deras förmåga att anpassa sig till nya crawlers och förändrade angreppsmönster utan manuella uppdateringar av din konfiguration.
Att avgöra om du ska blockera AI-crawlers kräver noggrant övervägande av kompromissen mellan att skydda serverresurser och att behålla synlighet i AI-drivna sökresultat och applikationer. Om du blockerar alla AI-crawlers förlorar du möjligheten att ditt innehåll syns i ChatGPT-sök, Perplexity AI-svar eller andra AI-drivna upptäcktsmekanismer, vilket kan minska hänvisningstrafik och varumärkessynlighet. Omvänt innebär att tillåta obegränsad crawleråtkomst att betydande resurser förbrukas och användarupplevelsen försämras utan mätbara fördelar för ditt företag. Den optimala strategin beror på din specifika situation: högtrafikerade webbplatser med gott om resurser kan välja att tillåta crawlers, medan resurssvaga sajter bör prioritera användarupplevelsen genom att blockera eller strypa crawleråtkomst. Strategiska beslut bör grunda sig på din bransch, målgrupp, innehållstyp och affärsmål snarare än en universell lösning.
För webbplatser som väljer att tillåta AI-crawlertrafik ger infrastrukturskalning möjlighet att bibehålla prestanda samtidigt som den ökade belastningen absorberas. Vertikal skalning – uppgradering till servrar med mer CPU, RAM och bandbredd – är en enkel men dyr lösning som till slut når fysiska begränsningar. Horisontell skalning – att distribuera trafik över flera servrar med lastbalanserare – ger bättre långsiktig skalbarhet och motståndskraft. Molnplattformar som AWS, Google Cloud och Azure erbjuder autoskalningsfunktioner som automatiskt tilldelar extra resurser vid trafiktoppar och skalar ned under lugna perioder för att minimera kostnader. Content Delivery Networks (CDN) kan cacha statiskt innehåll vid edge-noder, vilket minskar belastningen på ursprungsservern och förbättrar prestandan för både användare och crawlers. Databasoptimering, frågecachning och förbättringar på applikationsnivå kan också minska resursförbrukningen per förfrågan och öka effektiviteten utan ytterligare infrastruktur.
Löpande övervakning och optimering är avgörande för att bibehålla optimal prestanda i mötet med ihållande AI-crawlertrafik. Specialiserade verktyg ger insikt i crawleraktivitet, resurskonsumtion och prestandamått, vilket möjliggör datadrivna beslut kring crawlerhanteringsstrategier. Omfattande övervakning från början gör det möjligt att fastställa baslinjer, identifiera trender och mäta effekten av motåtgärder över tid.
Viktiga övervakningsverktyg och metoder:
Landskapet för AI-crawlerhantering utvecklas ständigt, med nya standarder och branschinitiativ som formar samspelet mellan webbplatser och AI-företag. llms.txt-standarden representerar ett framväxande tillvägagångssätt för att ge AI-företag strukturerad information om innehållsanvändningsrättigheter och preferenser, vilket potentiellt erbjuder ett mer nyanserat alternativ än generellt blockering eller tillåtelse. Branschdiskussioner om ersättningsmodeller antyder att AI-företag i framtiden kan komma att betala webbplatser för tillgång till träningsdata, vilket fundamentalt kan förändra ekonomin kring crawlertrafik. Att framtidssäkra din infrastruktur kräver att du håller dig informerad om nya standarder, följer utvecklingen i branschen och behåller flexibilitet i dina crawlerhanteringspolicyer. Att bygga relationer med AI-företag, delta i branschdiskussioner och förespråka rättvisa ersättningsmodeller blir allt viktigare i takt med att AI blir mer centralt för webbupptäckt och innehållskonsumtion. De webbplatser som lyckas i detta föränderliga landskap är de som balanserar innovation med pragmatism – skyddar sina resurser men förblir öppna för legitima möjligheter till synlighet och partnerskap.
AI-crawlers (GPTBot, ClaudeBot) extraherar innehåll för LLM-träning utan att nödvändigtvis skicka trafik tillbaka. Sökmotorcrawlers (Googlebot) indexerar innehåll för sökbarhet och skickar oftast hänvisningstrafik. AI-crawlers agerar mer aggressivt med större batchförfrågningar och ignorerar ofta bandbreddsbesparande riktlinjer.
Verkliga exempel visar på 30TB+ per månad från enskilda crawlers. Förbrukningen beror på webbplatsens storlek, innehållsvolym och crawlerns frekvens. OpenAIs GPTBot genererade ensam 569 miljoner förfrågningar under en enda månad på Vercels nätverk.
Att blockera AI-träningscrawlers (GPTBot, ClaudeBot) påverkar inte Googles ranking. Däremot kan blockering av AI-sökcrawlers minska synligheten i AI-drivna sökresultat som Perplexity eller ChatGPT-sök.
Leta efter oförklarliga CPU-toppar (300%+), ökad bandbreddsanvändning utan fler mänskliga besökare, långsammare sidladdningstider samt ovanliga user-agent-strängar i serverloggar. Core Web Vitals-metriker kan också försämras avsevärt.
För webbplatser med betydande crawlertrafik ger dedikerad hosting bättre resursisolering, kontroll och förutsägbara kostnader. Delade hostingmiljöer lider av 'noisy neighbor syndrome' där en webbplats crawlertrafik påverkar alla värdade webbplatser.
Använd Google Search Console för Googlebot-data, serveraccessloggar för detaljerad trafikanalys, CDN-analysverktyg (Cloudflare) och specialiserade plattformar som AmICited.com för omfattande AI-crawlerövervakning och spårning.
Ja, via robots.txt-direktiv, WAF-regler och IP-baserad filtrering. Du kan tillåta fördelaktiga crawlers som Googlebot och blockera resurskrävande AI-träningscrawlers med användaragent-specifika regler.
Jämför servermetrik före och efter att du infört crawlerkontroller. Övervaka Core Web Vitals (LCP, TTFB), sidladdningstider, CPU-användning och användarupplevelsemått. Verktyg som Google PageSpeed Insights och serverövervakningsplattformar ger detaljerade insikter.
Få insikter i realtid om hur AI-modeller får tillgång till ditt innehåll och påverkar dina serverresurser med AmICiteds specialiserade övervakningsplattform.
Förstå hur AI-crawlers som GPTBot och ClaudeBot fungerar, deras skillnader från traditionella sökmotor-crawlers och hur du optimerar din webbplats för synlighet...

Lär dig identifiera och övervaka AI-crawlers som GPTBot, PerplexityBot och ClaudeBot i dina serverloggar. Upptäck user-agent-strängar, IP-verifieringsmetoder oc...

Lär dig hur du fattar strategiska beslut om att blockera AI-crawlers. Utvärdera innehållstyp, trafikkällor, intäktsmodeller och konkurrensposition med vårt omfa...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.