
Entity Recognition
Entity Recognition är en AI NLP-förmåga som identifierar och kategoriserar namngivna entiteter i text. Lär dig hur det fungerar, dess tillämpningar inom AI-över...
9 min läsning

Utforska hur AI-system känner igen och bearbetar entiteter i text. Lär dig om NER-modeller, transformerarkitekturer och verkliga tillämpningar av entitetsförståelse.
Entitetsförståelse har blivit en hörnsten inom moderna AI-system och gör det möjligt för maskiner att identifiera och förstå nyckelaktörer, platser och begrepp i ostrukturerad text. Från att driva sökmotorer som förstår användarens avsikt till att möjliggöra chattbottar som kan svara på komplexa frågor om specifika personer och organisationer, utgör entitetsigenkänning grunden för meningsfull människa-dator-interaktion. Denna tekniska förmåga är avgörande inom många branscher—finansiella institutioner använder den för regelefterlevnad, sjukvårdssystem använder den för patientjournalhantering och e-handelsplattformar är beroende av den för att förstå produktomnämnanden och kundfeedback. Att förstå hur AI-system extraherar och tolkar entiteter är viktigt för alla som bygger eller implementerar NLP-applikationer i produktionsmiljöer.
Named Entity Recognition (NER) är NLP-uppgiften att identifiera och klassificera namngivna entiteter—specifika, meningsbärande informationsenheter—inuti text till fördefinierade kategorier. Dessa entiteter representerar de konkreta subjekt som bär semantisk tyngd i språket: personer som agerar, organisationer som fattar beslut, platser där händelser sker, tidsuttryck som förankrar händelser i tiden, monetära värden som kvantifierar transaktioner och produkter som köps och säljs. Entitetsklassificering är viktig eftersom den gör om råtext till strukturerad kunskap som maskiner kan resonera kring och agera utifrån; utan den kan ett system inte särskilja mellan “Apple företaget” och “äpple frukten”, eller förstå att “John Smith” och “J. Smith” syftar på samma person. Förmågan att klassificera entiteter korrekt möjliggör vidare applikationer som kunskapsgrafsbygge, informationsutvinning, frågesvar och relationsidentifiering.
| Entity Type | Definition | Example |
|---|---|---|
| PERSON | Individuella människor | “Steve Jobs,” “Marie Curie” |
| ORGANIZATION | Företag, institutioner, grupper | “Microsoft,” “United Nations,” “Harvard University” |
| LOCATION | Geografiska platser och regioner | “New York,” “Amazon River,” “Silicon Valley” |
| DATE | Tidsuttryck och perioder | “15 januari 2024,” “nästa tisdag,” “Q3 2023” |
| MONEY | Monetära värden och valutor | “$50 miljoner,” “€100,” “5000 yen” |
| PRODUCT | Varor, tjänster och skapelser | “iPhone 15,” “Windows 11,” “ChatGPT” |
Moderna AI-system bearbetar entiteter genom en sofistikerad flerstegs-pipeline som börjar med tokenisering, där råtext delas upp i diskreta tokens som fungerar som grundläggande enheter för vidare bearbetning. Varje token omvandlas sedan till en numerisk representation via word embeddings—täta vektorer som fångar semantisk innebörd—vilka matas in i neurala nätverksarkitekturer designade för att förstå kontext och relationer. Transformerbaserade modeller, som blivit dominerande inom modern NLP, bearbetar hela sekvenser parallellt istället för sekventiellt, vilket gör att de kan fånga långväga beroenden och komplexa kontextuella relationer som är avgörande för korrekt entitetsförståelse. Self-attention-mekanismen i Transformers gör att varje token dynamiskt kan väga vikten av alla andra tokens i sekvensen, och skapar därmed rika kontextuella representationer där ett ords betydelse formas av dess omgivning; det är därför “bank” förstås olika i “river bank” jämfört med “savings bank”. Förtränade språkmodeller som BERT och GPT lär sig allmänna språkliga mönster från enorma textkorpusar innan de finjusteras för entitetsigenkänning, vilket gör att de kan utnyttja inlärda representationer av syntax, semantik och världskunskap. Slutsteget i system för entitetsigenkänning använder ofta sekvensmärkning—vanligen med Conditional Random Field (CRF) eller ett enkelt klassificeringshuvud—som tilldelar entitetsetiketter till varje token baserat på de kontextuella representationer nätverket lärt sig. Denna arkitektur gör det möjligt för AI-system att förstå inte bara vilka entiteter som finns, utan också hur de relaterar till varandra och vilka roller de har i textens bredare kontext.
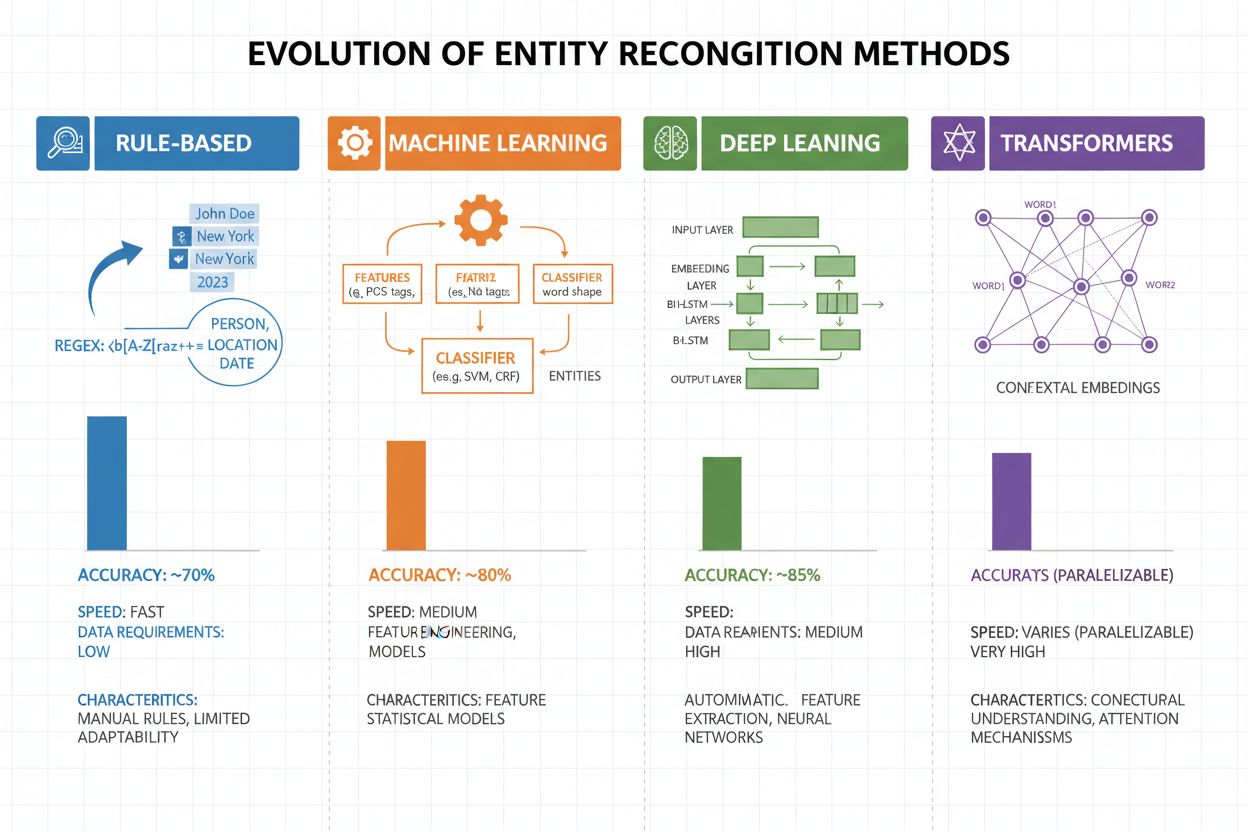
Entitetsigenkänning har utvecklats kraftigt de senaste två decennierna, från enkla regelbaserade metoder till avancerade neurala arkitekturer. Tidiga system förlitade sig på handgjorda regler och ordlistor, där reguljära uttryck och mönstermatchning användes för att identifiera entiteter—metoder som var tolkningsbara och krävde lite träningsdata men hade dålig generalisering och hög underhållskostnad. Med maskininlärning kom supervised-metoder som Support Vector Machines (SVM) och Conditional Random Fields (CRF), vilka lärde sig från annoterad data med feature engineering och förbättrade noggrannheten avsevärt, även om de fortfarande behövde experter för att skapa meningsfulla features. Deep learning-metoder, särskilt LSTM och BiLSTM, automatiserade feature extraction genom att lära in representationer direkt från råtext och nådde betydligt högre noggrannhet utan manuell feature engineering, men krävde större mängder annoterad data. Transformerbaserade modeller som BERT och RoBERTa revolutionerade området genom att utnyttja self-attention för att fånga långväga beroenden och kontextuella nyanser, nå state-of-the-art-resultat (BERT nådde 90,9% F1 på CoNLL-2003) och möjliggöra transfer learning från massiva förtränade modeller. Komplexitets- och noggrannhetsbalansen har därmed förändrats dramatiskt: även om regelbaserade system fortfarande är värdefulla för resursbegränsade miljöer och mycket nischade domäner, dominerar transformer-modeller numera där det finns tillräckliga resurser och annoterad data, medan lättare alternativ som DistilBERT erbjuder ett mellanting för produktionssystem med latenskrav.
Transformerbaserade modeller har fundamentalt förändrat entitetsigenkänning genom att ersätta sekventiell bearbetning med parallella self-attention-mekanismer som beaktar alla tokens i en mening samtidigt, vilket möjliggör rikare kontextförståelse än tidigare arkitekturer. BERT och dess varianter (RoBERTa, DistilBERT, ALBERT) drar nytta av bidirektionell förträning på massiva oannoterade textmängder och lär sig universella språkrepresentationer som fångar både syntaktisk och semantisk information innan de finjusteras på NER-uppgifter med relativt små annoterade dataset. Paradigmet för förträning och finjustering är särskilt kraftfullt för entitetsigenkänning: modeller förtränade på miljarder tokens utvecklar robusta representationer av språkstruktur och entitetsmönster, som sedan kan anpassas till specifika domäner med bara tusentals annoterade exempel, vilket minskar datakravet jämfört med att träna från grunden. Transformermodeller utmärker sig genom sin multi-head attention-mekanism, där olika attention-heads kan specialisera sig på olika typer av entitetsrelationer—vissa fokuserar på syntaktiska gränser medan andra fångar semantiska kopplingar mellan entiteter och deras kontext. Flerspråkig entitetsigenkänning har revolutionerats av modeller som mBERT och XLM-RoBERTa, förtränade på 100+ språk samtidigt, vilket möjliggör zero-shot och few-shot-transfer till lågresursspråk och tvärspråklig entitetslänkning. Nya modeller som GLiNER (Generalist Language Model for Instruction-based Named Entity Recognition) tar utvecklingen vidare genom att möjliggöra instruktionbaserad entitetsigenkänning, där modeller kan identifiera godtyckliga entitetstyper specificerade i naturliga språkprompter utan uppgiftsspecifik finjustering—ett steg mot mer flexibla och generaliserbara entitetsförståelsesystem.
Trots stora framsteg står system för entitetsigenkänning inför ihållande utmaningar i verkliga tillämpningar, där tvetydighet och kontextkänslighet hör till de svåraste—ordet “Apple” kräver förståelse om det syftar på frukten eller teknikföretaget utifrån kontexten, och även de mest avancerade modeller har svårt med sådan semantisk disambiguering i brusig eller tvetydig text. Okända (OOV) entiteter är en annan grundläggande utmaning: modeller tränade på standarddataset kanske aldrig stöter på ovanliga entiteter, egennamn från nya domäner eller felstavade varianter, vilket gör att de kan felklassificera eller missa dessa entiteter helt. Domänanpassning är fortsatt problematiskt eftersom modeller tränade på nyhetskorpusar (som CoNLL-2003) ofta presterar dåligt på biomedicinsk, juridisk eller social mediatext där entitetsfördelning och språkmönster skiljer sig avsevärt, vilket kräver kostsam ominlärning och finjustering för varje ny domän. Gränsidentifieringsfel—när systemet korrekt identifierar att en entitet finns men placerar start- eller slutpunkt fel—är särskilt vanliga vid flerdelade entiteter och nästlade strukturer, exempelvis att särskilja “New York City” från “New York” eller hantera entiteter som “Chief Executive Officer of Apple Inc.” Flerspråkiga komplexiteter förvärrar utmaningarna, eftersom olika språk har olika versalregler, morfologiska strukturer och namngivningsmönster, vilket gör att modeller tränade på engelska ofta misslyckas på språk med andra språkliga egenskaper. Databrist för specialiserade domäner som sällsynta sjukdomsnamn, nya teknologier eller företagsinterna begrepp skapar en flaskhals där kostnaden för manuell annotering blir för stor, vilket tvingar praktiker att välja mellan lägre noggrannhet eller stora investeringar i domänspecifik datainsamling.
Entitetsförståelse har blivit oumbärlig inom alla branscher och förändrar hur organisationer utvinner värde från ostrukturerad text. Inom informationsutvinning och kunskapsgrafsbygge möjliggör entitetsigenkänning automatisk befolkning av strukturerade databaser från dokument, och driver sökmotorer och rekommendationssystem som förstår relationer mellan personer, platser och begrepp. Sjukvårdsorganisationer använder entitetsförståelse för att identifiera läkemedelsnamn, doseringar, symptom och patientdemografi från kliniska anteckningar, vilket förbättrar beslutsstöd och möjliggör farmakovigilanssystem som upptäcker biverkningar i stor skala. Finansiella institutioner använder entitetsigenkänning för att extrahera aktiesymboler, monetära värden och marknadshändelser från nyhetsflöden och rapporter, så att algoritmiska handelssystem och riskplattformar kan reagera på marknadsinformation i realtid. Legal tech-företag tillämpar entitetsförståelse för automatisk identifiering av parter, datum, skyldigheter och ansvarsklausuler i avtal, vilket minskar juristers dokumentgranskning från veckor till timmar. Kundservice- och chatbotplattformar använder entitetsigenkänning för att extrahera användarintentioner och relevant kontext—som ordernummer, produktnamn och ärendetyper—vilket möjliggör bättre ärenderouting och snabbare lösning. E-handelsplattformar använder entitetsförståelse för att identifiera produktnamn, varumärken, egenskaper och specifikationer från kundrecensioner och sökfrågor, vilket förbättrar produktsökning och personalisering. Rekommendationssystem för innehåll använder entitetsigenkänning för att förstå vilka entiteter användare interagerar med, och möjliggör mer avancerad filtrering och rekommendationer som ökar engagemang och intäkter.
Att implementera ett produktionsklart system för entitetsförståelse kräver noggrannhet vid datapreparering, modellval och utvärdering. Börja med högkvalitativt annoterad data: definiera tydliga entitetstyper, använd inter-annotator agreement-mått för att säkerställa konsekvens, och sträva efter minst 500–1000 annoterade exempel per entitetstyp, även om domänspecifika applikationer kan kräva mer. Modellval beror på dina begränsningar: regelbaserade system erbjuder tolkningsbarhet och låg latens för välavgränsade domäner, traditionella maskininlärningsmodeller (CRF, SVM) ger bra prestanda med måttlig datamängd, medan transformerbaserade modeller (BERT, RoBERTa) ger toppnoggrannhet men kräver mer resurser och data. Tränings- och finjusteringsstrategier bör inkludera data-augmentering för att hantera klassobalans, korsvalidering för att undvika överanpassning och noggrann justering av hyperparametrar som inlärningstakt och batchstorlek. Utvärdera systemet med precision (korrekt identifierade entiteter), recall (hittade entiteter av alla faktiska entiteter) och F1-score (harmoniskt medelvärde av båda), med separata mått för varje entitetstyp för att identifiera svaga områden. Implementeringsaspekter inkluderar latenskrav (batch- vs. realtidsbearbetning), skalbarhet och integration med befintliga datapipelines, medan övervakning efter driftsättning bör följa prestandadrift, falska positiva och användarfeedback för att trigga omträning.
Ekosystemet av verktyg för entitetsförståelse erbjuder lösningar för varje skala och användningsfall. Öppen källkod-bibliotek som spaCy erbjuder produktionsklara NER-pipelines med imponerande prestanda (89,22% F1-score på standardtester) och utmärkt dokumentation, perfekt för team med ML-kompetens; NLTK har utbildningsvärde och grundläggande NER-förmåga; Hugging Face Transformers ger tillgång till toppmoderna förtränade modeller som enkelt kan finjusteras för specifika domäner. Molnbaserade tjänster eliminerar infrastrukturproblem: Google Cloud Natural Language API, AWS Comprehend och IBM Watson NLP erbjuder förtränad entitetsigenkänning med stöd för flera språk och entitetstyper, automatiskt skalande och enkel integration med molndatapipelines. Specialiserade ramverk som Flair (byggt på PyTorch med utmärkt sekvensmärkning) och DeepPavlov (färdigtränade modeller för flera språk och domäner) riktar sig till forskare och team som behöver mer anpassning än allmänna bibliotek. Valet mellan att bygga egna lösningar och använda färdiga verktyg beror på datakänslighet (on-premise vs. moln), nödvändig noggrannhet, domänspecifika behov och teamets expertis: använd molntjänster för generella tillämpningar med standardentiteter, utnyttja öppen källkod för domänanpassning med intern data, och bygg egna modeller endast om existerande lösningar inte möter krav på noggrannhet eller latens.
Framtiden för entitetsförståelse formas av stora språkmodeller som ger oöverträffad flexibilitet och prestanda. Modeller som GPT-4 och Claude visar imponerande few-shot och zero-shot-förmåga för entitetsigenkänning, vilket gör att organisationer kan identifiera anpassade entitetstyper med bara några få exempel eller rentav naturliga språkbeskrivningar, vilket drastiskt minskar annoteringsbördan och snabbar på tiden till värde. Multimodal entitetsförståelse är ett växande område där text, bilder och strukturerad data kombineras för att känna igen entiteter i dokument, fakturor och webbsidor med rikare kontext, och möjliggör applikationer som automatiserad dokumentbearbetning och visuell sökning. Realtidsbearbetning tack vare modellkomprimering och edge-implementering gör avancerad entitetsigenkänning möjlig på mobiler och IoT, vilket öppnar nya applikationer inom AR, realtidsöversättning och autonoma system. Framsteg inom domänspecifik finjustering ger specialiserade modeller för biomedicin, juridik och finans som vida överträffar generalistmodeller, med tekniker som domänanpassad förträning och transfer learning som gör detta alltmer tillgängligt. När dessa teknologier mognar kommer entitetsförståelse bli ett osynligt grundlager i AI-system, och möjliggöra maskinell förståelse av världen med mänsklig semantik och öppna möjligheter vi bara skymtar idag.
I takt med att AI-system som ChatGPT, Perplexity och Google AI Overviews blir alltmer integrerade i hur information upptäcks och konsumeras, blir det avgörande att förstå hur dessa system känner igen och refererar till entiteter—inklusive ditt varumärke. Entitetsförståelse är mekanismen genom vilken AI-system identifierar och bearbetar omnämnanden av företag, produkter, personer och begrepp. När du övervakar hur AI-system förstår och refererar till ditt varumärke via entitetsigenkänning får du insikter om:
Detta är exakt vad AmICited övervakar—och spårar hur AI-system känner igen och refererar till ditt varumärke som en entitet på flera AI-plattformar. Genom att förstå entitetsigenkänning kan du bättre förstå hur AI-system uppfattar och kommunicerar om ditt företag.
Entitetsigenkänning (NER) identifierar och klassificerar entiteter i text (t.ex. "Apple" som ORGANISATION), medan entitetslänkning kopplar dessa entiteter till kunskapsbaser eller kanoniska referenser (t.ex. att länka "Apple" till Wikipedias sida för Apple Inc.). Entitetsigenkänning är första steget; entitetslänkning ger semantisk förankring.
State-of-the-art transformerbaserade modeller som BERT uppnår 90,9% F1-score på standardtester som CoNLL-2003. Dock varierar noggrannheten kraftigt mellan olika domäner—modeller tränade på nyheter presterar dåligt på biomedicinsk text eller sociala medier. Verklig noggrannhet beror mycket på domänanpassning och datakvalitet.
Ja, flerspråkiga modeller som mBERT och XLM-RoBERTa stöder 100+ språk samtidigt. Dock varierar prestandan mellan språk på grund av skillnader i versalregler, morfologi och tillgänglig träningsdata. Språkspecifika modeller presterar vanligtvis bättre än flerspråkiga för kritiska tillämpningar.
Regelbaserade system använder handgjorda mönster och ordlistor (snabba, tolkningsbara men känsliga). ML-baserade system lär sig från annoterad data (mer flexibla, bättre generalisering men kräver träningsdata och feature engineering). Moderna deep learning-metoder automatiserar feature extraction och uppnår överlägsen noggrannhet.
Regelbaserade system behöver bara mönsterdefinitioner. Traditionella ML-modeller kräver 300–500 annoterade exempel. Transformerbaserade modeller fungerar med 800+ exempel men drar nytta av transfer learning—förtränade modeller kan ge bra resultat med bara 100–200 domänspecifika exempel genom finjustering.
Viktiga utmaningar inkluderar: tvetydighet (samma ord betyder olika saker), okända entiteter, domänanpassning (modeller tränade på en domän misslyckas i en annan), fel i gränsidentifiering, flerspråkiga komplexiteter och dataskräck för specialiserade domäner. Dessa kräver noggrann systemdesign och domänspecifik trimning.
Kontext är avgörande—"bank" betyder olika i "river bank" kontra "savings bank". Moderna transformermodeller använder self-attention för att väga kontext från alla omgivande ord, vilket gör att de kan särskilja entiteter utifrån språklig och semantisk kontext. Bristande kontexthantering är en vanlig felkälla i entitetsigenkänning.
Framtida utveckling inkluderar: stora språkmodeller som möjliggör zero-shot entitetsigenkänning, multimodal förståelse som kombinerar text och bilder, realtidsbearbetning på edge-enheter och framsteg inom domänspecifik finjustering. Entitetsförståelse kommer bli ett osynligt grundlager som möjliggör maskinell förståelse av världen med mänsklig semantik.
AmICited spårar entitetsomnämnanden över AI-system som ChatGPT, Perplexity och Google AI Overviews. Förstå hur AI uppfattar och refererar till ditt varumärke i realtid.
Entity Recognition är en AI NLP-förmåga som identifierar och kategoriserar namngivna entiteter i text. Lär dig hur det fungerar, dess tillämpningar inom AI-över...

Lär dig hur du bygger entity-synlighet i AI-sök. Bemästra optimering av kunskapsgrafer, schema markup och entity SEO-strategier för att öka varumärkets närvaro ...

Lär dig hur entityoptimering hjälper ditt varumärke att bli igenkänt av LLM:er. Bemästra kunskapsgrafsoptimering, schema-markering och entity-strategier för AI-...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.