
AI-crawlers förklarade: GPTBot, ClaudeBot och fler
Förstå hur AI-crawlers som GPTBot och ClaudeBot fungerar, deras skillnader från traditionella sökmotor-crawlers och hur du optimerar din webbplats för synlighet...
12 min läsning

Upptäck de avgörande skillnaderna mellan AI-träningscrawlare och sökmotorcrawlare. Lär dig hur de påverkar din innehållssynlighet, dina optimeringsstrategier och AI-citeringar.
Sökmotorcrawlare som Googlebot och Bingbot är ryggraden i traditionella sökmotorers funktion. Dessa automatiserade botar navigerar systematiskt på webben, upptäcker och indexerar innehåll för att avgöra vad som visas i sökmotorernas resultatlistor (SERP). Googlebot, som drivs av Google, är den mest kända och aktiva sökmotorcrawlarn, följt av Bingbot från Microsoft och YandexBot från Yandex. Dessa crawlare har sofistikerade möjligheter som gör att de kan köra JavaScript, rendera dynamiskt innehåll och förstå komplexa webbplatsstrukturer. De besöker webbplatser ofta baserat på faktorer som sidans auktoritet, innehållets färskhet och uppdateringshistorik, där sidor med hög auktoritet får fler besök. Sökmotorcrawlarnas primära mål är att indexera innehåll för rankningsändamål, vilket innebär att de utvärderar sidor utifrån relevans, kvalitet och signaler om användarupplevelse.
| Crawler-typ | Primärt syfte | JavaScript-stöd | Krypfrekvens | Mål |
|---|---|---|---|---|
| Googlebot | Indexera för sökrankning | Ja (med begränsningar) | Frekvent, baserat på auktoritet | Ranking & synlighet |
| Bingbot | Indexera för sökrankning | Ja (med begränsningar) | Regelbunden, baserat på innehållsuppdateringar | Ranking & synlighet |
| YandexBot | Indexera för sökrankning | Ja (med begränsningar) | Regelbunden, baserat på sidans signaler | Ranking & synlighet |
AI-träningscrawlare representerar en fundamentalt annorlunda kategori av webb-botar designade för att samla in data till träning av stora språkmodeller (LLM) snarare än för sökindexering. GPTBot, som drivs av OpenAI, är den mest framträdande AI-träningscrawlaren, tillsammans med ClaudeBot från Anthropic, PetalBot från Huawei och Common Crawl’s CCBot. Till skillnad från sökmotorcrawlare som syftar till att ranka innehåll fokuserar AI-träningscrawlare på att samla in högkvalitativ, kontextuellt rik information för att förbättra AI-modellernas kunskapsbas och svarsgenereringsförmåga. Dessa crawlare arbetar vanligtvis mer sällan än sökmotorcrawlare, och besöker ofta en webbplats endast en gång varannan vecka eller månad, där de prioriterar innehållskvalitet före volym. Denna distinktion är avgörande: medan ditt innehåll kan vara noggrant indexerat av Googlebot för söksynlighet kan det endast vara delvis eller sällan krypat av GPTBot för AI-träning.
| Crawler-typ | Primärt syfte | JavaScript-stöd | Krypfrekvens | Mål |
|---|---|---|---|---|
| GPTBot | Samla data för LLM-träning | Nej | Sällan, selektivt | Träningsdatakvalitet |
| ClaudeBot | Samla data för LLM-träning | Nej | Sällan, selektivt | Träningsdatakvalitet |
| PetalBot | Samla data för LLM-träning | Nej | Sällan, selektivt | Träningsdatakvalitet |
| CCBot | Samla data för Common Crawl | Nej | Sällan, selektivt | Träningsdatakvalitet |
De tekniska skillnaderna mellan sök- och AI-träningscrawlare skapar betydande konsekvenser för innehållssynlighet. Den viktigaste skillnaden är JavaScript-körning: sökmotorcrawlare som Googlebot kan köra JavaScript (dock med vissa begränsningar), vilket gör att de kan se dynamiskt renderat innehåll. AI-träningscrawlare däremot kör inte JavaScript alls—de tolkar endast rå HTML vid första sidladdningen. Denna fundamentala skillnad innebär att innehåll som laddas dynamiskt via klientbaserade skript är helt osynligt för AI-crawlare. Dessutom följer sökmotorcrawlare krypbudgets och prioriterar sidor baserat på webbplatsarkitektur och interna länkar, medan AI-crawlare använder mer selektiva, kvalitetsdrivna krypmönster. Sökmotorcrawlare följer generellt robots.txt noggrant, medan vissa AI-crawlare historiskt varit mindre transparenta med sin efterlevnad. Krypfrekvensen skiljer sig dramatiskt: sökmotorcrawlare besöker aktiva sidor flera gånger per vecka eller till och med dagligen, medan AI-träningscrawlare kan besöka endast en gång varannan vecka eller månad. Dessutom är sökmotorcrawlare utformade för att förstå rankningssignaler och användarupplevelsemått, medan AI-crawlare fokuserar på att extrahera ren, välstrukturerad text för modellträning.
| Funktion | Sökmotorcrawlare | AI-träningscrawlare |
|---|---|---|
| JavaScript-körning | Ja (med begränsningar) | Nej |
| Krypfrekvens | Hög (flera gånger/vecka) | Låg (en gång varannan vecka) |
| Innehållstolkning | Fullständig sidrendering | Endast rå HTML |
| Robots.txt-följsamhet | Strikt | Varierande |
| Fokus på krypbudget | Auktoritetsbaserad prioritering | Kvalitetsbaserat urval |
| Dynamisk innehållshantering | Kan rendera och indexera | Missar helt |
| Primärt mål | Ranking & söksynlighet | Insamling av träningsdata |
| Timeout-tolerans | Längre (tillåter komplex rendering) | Snäv (1–5 sekunder) |
Oförmågan hos AI-crawlare att köra JavaScript skapar en kritisk synlighetslucka som påverkar många moderna webbplatser. När en webbplats är beroende av JavaScript för att ladda innehåll dynamiskt—såsom produktbeskrivningar, kundrecensioner, prisinformation eller bilder—blir det innehållet osynligt för AI-crawlare. Detta är särskilt problematiskt för single page applications (SPA) byggda med React, Vue eller Angular, där det mesta av innehållet laddas klientbaserat efter att den ursprungliga HTML:en har levererats. Exempelvis kan en e-handelssida visa produktens tillgänglighet och pris via JavaScript, vilket gör att GPTBot bara ser en tom sida eller ett grundläggande HTML-skelett. På samma sätt kommer webbplatser som använder latladdning för bilder eller oändlig scroll för innehåll att få dessa element helt missade av AI-crawlare. Affärspåverkan är betydande: om dina produktdetaljer, kundomdömen eller nyckelinnehåll är dold bakom JavaScript kommer AI-system som ChatGPT och Perplexity inte ha tillgång till den informationen när de genererar svar. Detta skapar en situation där ditt innehåll kan ranka högt i Google men vara helt frånvarande i AI-genererade svar, vilket effektivt gör dig osynlig för en växande grupp användare som förlitar sig på AI för informationsupptäckt.
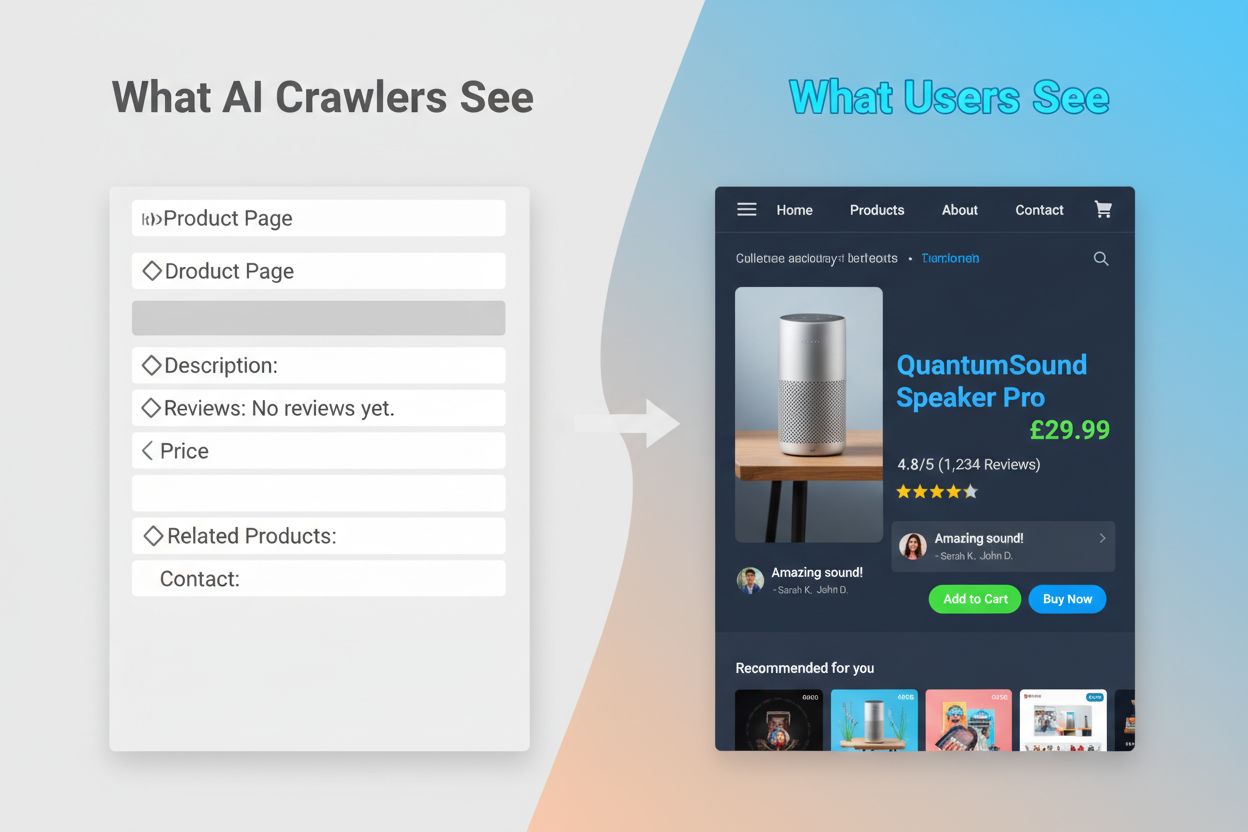
De praktiska konsekvenserna av dessa tekniska skillnader är djupgående och ofta missförstådda av webbplatsägare. Din webbplats kan uppnå utmärkta placeringar i Google samtidigt som den är nästan osynlig för ChatGPT, Perplexity och andra AI-system. Detta skapar en paradoxal situation där traditionell SEO-framgång inte garanterar AI-synlighet. När användare frågar ChatGPT om din bransch eller produkt kan AI-systemet citera dina konkurrenter istället för dig, helt enkelt för att deras innehåll var mer tillgängligt för AI-crawlare. Förhållandet mellan träningsdata och sökciteringar tillför ytterligare ett lager av komplexitet: innehåll som använts för att träna en AI-modell kan få företräde i modellens sökresultat, vilket innebär att blockering av AI-träningscrawlare potentiellt kan minska din synlighet i AI-drivna svar. För publicister och innehållsskapare innebär detta att det strategiska beslutet att tillåta eller blockera AI-crawlare får verkliga konsekvenser för framtida trafik. En webbplats som blockerar GPTBot för att skydda sitt innehåll från träning kan samtidigt minska sina chanser att synas i ChatGPT:s sökresultat. Omvänt ger tillåtelse till AI-crawlare att komma åt ditt innehåll träningsdata men garanterar inte citeringar eller trafik, vilket skapar ett verkligt strategiskt dilemma utan perfekt lösning.
Att förstå vilka crawlare som besöker din webbplats och hur ofta de gör det är avgörande för att optimera din innehållsstrategi. Loggfilanalys är den primära metoden för att identifiera crawlaraktivitet, där du kan segmentera och tolka serverloggar för att se vilka botar som besökt din sida, hur ofta de gjorde det och vilka sidor de prioriterade. Genom att undersöka User-Agent-strängar i serverloggar kan du särskilja mellan Googlebot, GPTBot, OAI-SearchBot och andra crawlare, vilket avslöjar mönster i deras beteende. Nyckelvärden att övervaka är krypfrekvens (hur ofta varje crawlar besöker), krypdjup (hur många nivåer av din webbplatsstruktur som krypas) och krypbudget (totalt antal sidor som krypas under en viss tidsperiod). Verktyg som Google Search Console och Bing Webmaster Tools ger insikter om sökmotorcrawlarnas aktivitet, medan specialiserade lösningar som AmICited.com erbjuder omfattande övervakning av AI-crawlarbeteende över flera plattformar inklusive ChatGPT, Perplexity och Google AI Overviews. AmICited.com spårar specifikt hur AI-system refererar till ditt varumärke och innehåll, och ger insyn i vilka AI-plattformar som citerar dig och hur ofta. Att förstå dessa mönster hjälper dig att identifiera tekniska problem i tid, optimera din krypbudget och fatta välgrundade beslut kring crawlaråtkomst och innehållsoptimering.
Optimering för traditionella sökmotorcrawlare kräver fokus på etablerade tekniska SEO-grunder som säkerställer att ditt innehåll är upptäckbart och indexerbart. Följande strategier är avgörande för att upprätthålla stark söksynlighet:
Sökmotorer som Google fokuserar alltmer på krypeffektivitet, med Google-representanter som indikerar att Googlebot kommer att krypa mindre i framtiden. Detta innebär att din webbplats bör vara så strömlinjeformad och lättförståelig som möjligt, med tydliga hierarkier och effektiva interna länkar som leder crawlare direkt till dina viktigaste sidor.
Optimering för AI-träningscrawlare kräver ett annat tillvägagångssätt med fokus på innehållskvalitet, tydlighet och tillgänglighet snarare än rankningssignaler. Eftersom AI-crawlare prioriterar välstrukturerat, kontextuellt rikt innehåll bör din optimeringsstrategi betona omfattning och läsbarhet. Undvik JavaScript-beroende innehåll för kritisk information—säkerställ att produktdetaljer, priser, recensioner och nyckeldata finns i rå HTML där AI-crawlare kan komma åt dem. Skapa omfattande, djupgående innehåll som täcker ämnen grundligt och ger kontext som AI-modeller kan lära sig av. Använd tydlig formatering med rubriker, punktlistor och numrerade listor som delar upp texten och gör innehållet lätt att tolka. Skriv med semantisk tydlighet med raka formuleringar utan överdriven jargong som kan förvirra AI-modeller. Implementera korrekt rubrikhierarki (H1, H2, H3) för att hjälpa AI-crawlare förstå innehållsstruktur och relationer. Inkludera relevant metadata och schema-markup som ger kontext om ditt innehåll. Säkerställ snabba sidladdningstider eftersom AI-crawlare har snäva timeouts (vanligen 1–5 sekunder) och kan hoppa över långsamma sidor helt.
Den största skillnaden från sökoptimering är att AI-crawlare inte bryr sig om rankningssignaler, bakåtlänkar eller nyckelordstäthet. Istället värderar de innehåll som är tydligt, välorganiserat och informationsrikt. En sida som kanske inte rankar högt i Google kan vara mycket värdefull för AI-modeller om den innehåller omfattande och välstrukturerad information om ett ämne.
Landskapet för webb-crawling utvecklas snabbt, där AI-crawlare blir allt viktigare för innehållssynlighet och varumärkesmedvetenhet. I takt med att AI-drivna sökverktyg som ChatGPT, Perplexity och Google AI Overviews fortsätter att få fler användare blir möjligheten att upptäckas och citeras av dessa system lika kritisk som traditionella sökrankningar. Skillnaden mellan träningscrawlare och sökmotorcrawlare kommer sannolikt att bli mer nyanserad, med företag som eventuellt erbjuder tydligare uppdelning mellan datainsamling och sökåtergivning, likt OpenAI:s tillvägagångssätt med GPTBot och OAI-SearchBot. Webbplatsägare kommer att behöva utveckla strategier som balanserar traditionell SEO-optimering med AI-synlighet, med insikten att dessa är kompletterande snarare än konkurrerande mål. Uppkomsten av specialiserade övervakningsverktyg och lösningar kommer att göra det lättare att spåra crawlaraktivitet på både traditionella och AI-plattformar, vilket möjliggör datadrivna beslut kring crawlaråtkomst och innehållsoptimering. Tidiga användare som optimerar för både sök- och AI-crawlare nu får ett konkurrensmässigt försprång, och positionerar sitt innehåll för att upptäckas via flera kanaler i takt med att söklandskapet fortsätter att förändras. Framtiden för innehållssynlighet beror på att förstå och optimera för hela spektrumet av crawlare som upptäcker och använder ditt innehåll.
Sökmotorcrawlare som Googlebot indexerar innehåll för sökrankning och kan köra JavaScript för att se dynamiskt innehåll. AI-träningscrawlare såsom GPTBot samlar in data för att träna LLM:er och kan vanligtvis inte köra JavaScript, vilket gör att de missar dynamiskt laddat innehåll. Denna grundläggande skillnad innebär att din webbplats kan rankas högt i Google men vara nästan osynlig för ChatGPT.
Ja, du kan använda robots.txt för att blockera specifika AI-crawlare som GPTBot samtidigt som du tillåter sökmotorcrawlare. Detta kan dock minska din synlighet i AI-genererade svar och sammanfattningar. Den strategiska avvägningen beror på om du prioriterar innehållsskydd framför potentiell AI-trafik.
AI-crawlare som GPTBot tolkar endast rå HTML vid den första sidladdningen och kör inte JavaScript. Innehåll som laddas dynamiskt via skript—såsom produktdetaljer, recensioner eller bilder—är helt osynligt för dem. Detta är en avgörande begränsning för moderna webbplatser som är beroende av klientbaserad rendering.
AI-träningscrawlare besöker vanligtvis mindre frekvent än sökmotorcrawlare, med längre intervall mellan besöken. De prioriterar innehåll med hög auktoritet och kan krypa en sida endast en gång varannan vecka eller månad. Detta sällsynta krypmönster speglar deras fokus på kvalitet framför kvantitet.
Produktdetaljer, kundrecensioner, latladdade bilder, interaktiva element (flikar, karuseller, modaler), prisinformation och allt innehåll som är dolt bakom JavaScript är mest sårbara. För e-handel och SPA-baserade webbplatser kan detta utgöra en betydande andel av det kritiska innehållet.
Säkerställ att nyckelinnehåll finns i rå HTML, förbättra sidans hastighet, använd tydlig struktur och formatering med korrekt rubrikhierarki, implementera schema-markup och undvik kritiskt innehåll som är beroende av JavaScript. Målet är att göra ditt innehåll tillgängligt för både traditionella och AI-crawlare.
Verktyg för analys av loggfiler, Google Search Console, Bing Webmaster Tools och specialiserade lösningar som AmICited.com kan hjälpa dig att spåra crawlarmönster. AmICited.com övervakar specifikt hur AI-system refererar till ditt varumärke över ChatGPT, Perplexity och Google AI Overviews.
Potentiellt ja. Även om blockering av träningscrawlare kan skydda ditt innehåll, kan det minska din synlighet i AI-drivna sökresultat och sammanfattningar. Dessutom förblir innehåll som redan har blivit krypat innan blockeringen i tränade modeller. Beslutet kräver en avvägning mellan innehållsskydd och potentiell förlust av AI-baserad upptäckt.
Spåra hur AI-system refererar till ditt varumärke över ChatGPT, Perplexity och Google AI Overviews. Få insikter i realtid om din AI-synlighet och optimera din innehållsstrategi.
Förstå hur AI-crawlers som GPTBot och ClaudeBot fungerar, deras skillnader från traditionella sökmotor-crawlers och hur du optimerar din webbplats för synlighet...

Fullständig referensguide till AI-crawlers och botar. Identifiera GPTBot, ClaudeBot, Google-Extended och 20+ andra AI-crawlers med user agents, crawl-hastighete...

Lär dig vilka AI-crawlers du ska tillåta eller blockera i din robots.txt. Omfattande guide som täcker GPTBot, ClaudeBot, PerplexityBot och 25+ AI-crawlers med k...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.