
Ska du blockera eller tillåta AI-crawlers? Beslutsramverk
Lär dig hur du fattar strategiska beslut om att blockera AI-crawlers. Utvärdera innehållstyp, trafikkällor, intäktsmodeller och konkurrensposition med vårt omfa...
11 min läsning
Lär dig hur du implementerar selektiv blockering av AI-crawlers för att skydda ditt innehåll från träningsbotar samtidigt som synligheten i AI-sökresultat bibehålls. Tekniska strategier för publicister.
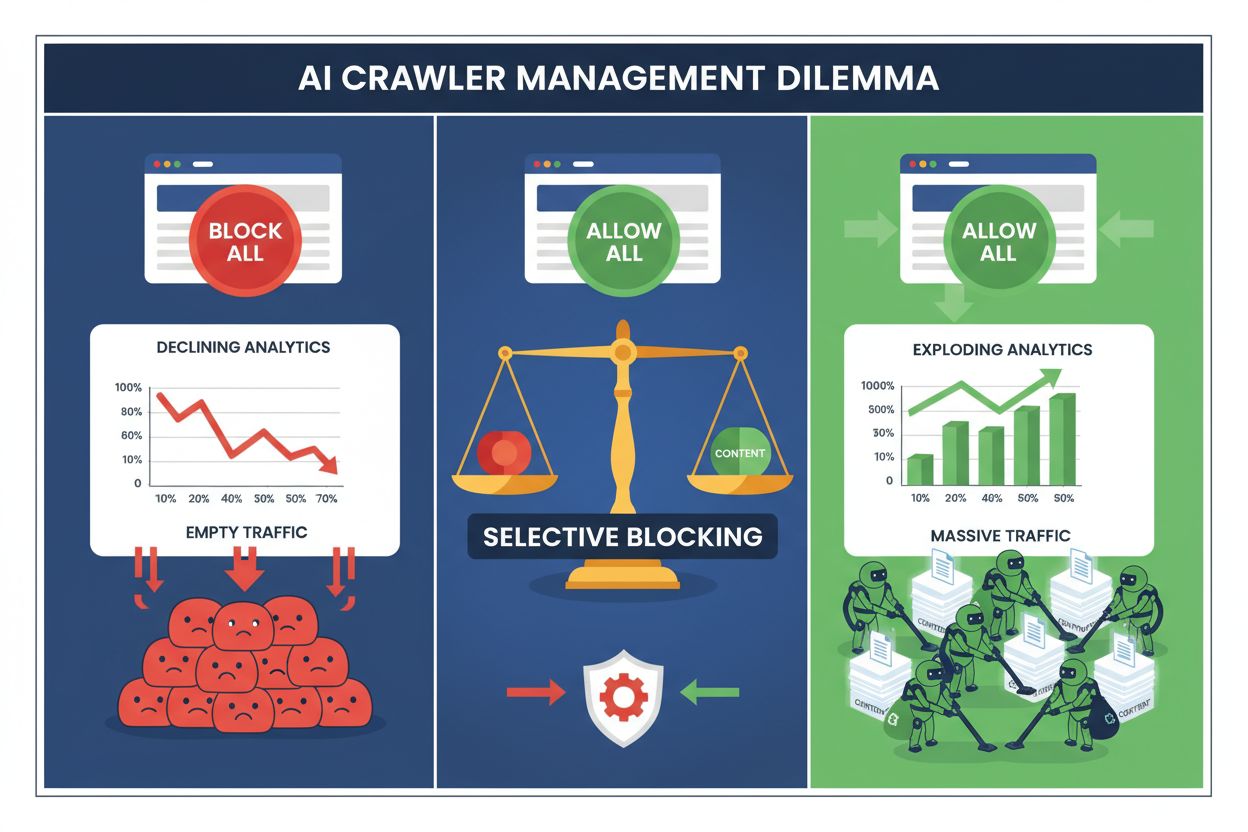
Publicister står idag inför ett omöjligt val: blockera alla AI-crawlers och förlora värdefull sökmotortrafik, eller tillåta alla och se sitt innehåll driva träningsdatamängder utan ersättning. Den generativa AI:ns framväxt har skapat ett uppdelat crawler-ekosystem där samma robots.txt-regler tillämpas godtyckligt på både sökmotorer som driver intäkter och tränings-crawlers som extraherar värde. Denna paradox har tvingat framåtblickande publicister att utveckla selektiva strategier för crawler-kontroll som skiljer mellan olika typer av AI-botar baserat på deras faktiska påverkan på affärsresultat.
AI-crawler-landskapet delas upp i två tydliga kategorier med mycket olika syften och affärskonsekvenser. Tränings-crawlers – som drivs av företag som OpenAI, Anthropic och Google – är utformade för att ta in stora mängder textdata för att bygga och förbättra stora språkmodeller, medan sökcrawlers indexerar innehåll för återvinning och upptäckt. Träningsbotar står för cirka 80 % av all AI-relaterad botaktivitet, men de genererar noll direktintäkter för publicister, medan sökcrawlers som Googlebot och Bingbot driver miljontals besök och annonsvisningar årligen. Skillnaden är viktig eftersom en enskild tränings-crawler kan förbruka bandbredd motsvarande tusentals mänskliga användare, medan sökcrawlers är optimerade för effektivitet och vanligtvis respekterar hastighetsbegränsningar.
| Botnamn | Operatör | Huvudsyfte | Trafikpotential |
|---|---|---|---|
| GPTBot | OpenAI | Modellträning | Ingen (datautvinning) |
| Claude Web Crawler | Anthropic | Modellträning | Ingen (datautvinning) |
| Googlebot | Sökindexering | 243,8M besök (april 2025) | |
| Bingbot | Microsoft | Sökindexering | 45,2M besök (april 2025) |
| Perplexity Bot | Perplexity AI | Sök + träning | 12,1M besök (april 2025) |
Datan talar sitt tydliga språk: ChatGPT:s crawler skickade ensam 243,8 miljoner besök till publicister i april 2025, men dessa besök genererade noll klick, noll annonsvisningar och noll intäkter. Samtidigt omvandlades Googlebots trafik till faktisk användarengagemang och intäktsmöjligheter. Att förstå denna skillnad är första steget mot att införa en selektiv blockeringsstrategi som skyddar ditt innehåll och samtidigt bevarar din söksynlighet.
Totalblockering av alla AI-crawlers är ekonomiskt självdestruktivt för de flesta publicister. Medan tränings-crawlers extraherar värde utan ersättning, förblir sökcrawlers en av de mest tillförlitliga trafik-källorna i ett allt mer fragmenterat digitalt landskap. Det ekonomiska argumentet för selektiv blockering vilar på flera nyckelfaktorer:
Publicister som implementerat selektiva blockeringar rapporterar att de bibehåller eller förbättrar söktrafiken samtidigt som de minskar obehörig innehållsextraktion med upp till 85 %. Den strategiska metoden erkänner att alla AI-crawlers inte är lika och att en nyanserad policy bättre tjänar affärsintresset än en totalblockering.
Robots.txt är fortfarande den primära mekanismen för att kommunicera crawler-tillstånd, och filen är förvånansvärt effektiv för att särskilja olika bottyper när den är rätt konfigurerad. Denna enkla textfil, placerad i webbplatsens rotkatalog, använder user-agent-direktiv för att ange vilka crawlers som får komma åt vilket innehåll. För selektiv AI-crawler-kontroll kan du tillåta sökmotorer samtidigt som du blockerar tränings-crawlers med kirurgisk precision.
Här är ett praktiskt exempel som blockerar tränings-crawlers men tillåter sökmotorer:
# Blockera OpenAI:s GPTBot
User-agent: GPTBot
Disallow: /
# Blockera Anthropics Claude crawler
User-agent: Claude-Web
Disallow: /
# Blockera andra tränings-crawlers
User-agent: CCBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
# Tillåt sökmotorer
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
User-agent: *
Disallow: /admin/
Disallow: /private/
Denna metod ger tydliga instruktioner till välbeteende crawlers samtidigt som din sajt fortsätter vara upptäckbar i sökresultat. Dock är robots.txt i grunden en frivillig standard – den bygger på att crawler-operatörer respekterar dina direktiv. För publicister som är oroade över efterlevnad krävs ytterligare tillämpningslager.
Robots.txt kan inte garantera efterlevnad eftersom cirka 13 % av AI-crawlers ignorerar robots.txt-direktiv helt, antingen av slarv eller avsikt. Servernivå-tillämpning via webbservern eller applikationslagret ger ett tekniskt skydd som förhindrar obehörig åtkomst oavsett crawlerns beteende. Denna metod blockerar förfrågningar på HTTP-nivå innan de förbrukar nämnvärda serverresurser eller bandbredd.
Att implementera blockering på servernivå med Nginx är enkelt och mycket effektivt:
# I din Nginx server block
location / {
# Blockera tränings-crawlers på servernivå
if ($http_user_agent ~* (GPTBot|Claude-Web|CCBot|anthropic-ai|Omgili)) {
return 403;
}
# Blockera efter IP-intervall vid behov (för crawlers som spoofar user agents)
if ($remote_addr ~* "^(192\.0\.2\.|198\.51\.100\.)") {
return 403;
}
# Fortsätt med normal begäran
proxy_pass http://backend;
}
Denna konfiguration returnerar ett 403 Forbidden-svar till blockerade crawlers, vilket förbrukar minimala serverresurser och tydligt kommunicerar att åtkomst nekas. I kombination med robots.txt skapar servernivå-tillämpning ett tvåstegsskydd som fångar både kompatibla och icke-kompatibla crawlers. Bypass-frekvensen på 13 % sjunker till nära noll när servernivåregler tillämpas korrekt.
Content Delivery Networks och Web Application Firewalls ger ett ytterligare skyddslager som fungerar innan förfrågningar når din ursprungsserver. Tjänster som Cloudflare, Akamai och AWS WAF låter dig skapa regler som blockerar specifika user agents eller IP-intervall vid kanten, vilket förhindrar att illasinnade eller oönskade crawlers förbrukar din infrastruktur. Dessa tjänster underhåller uppdaterade listor över kända träningscrawler-IP-intervall och user agents och blockerar dem automatiskt utan manuell konfiguration.
CDN-nivåkontroller har flera fördelar jämfört med servernivå-tillämpning: de minskar belastningen på ursprungsservern, möjliggör geografisk blockering och erbjuder realtidsanalys av blockerade förfrågningar. Många CDN-leverantörer erbjuder nu AI-specifika blockeringsregler som standardfunktioner, då de känner till publicisters oro över obehörig datautvinning för AI-träning. För publicister som använder Cloudflare ger aktivering av “Block AI Crawlers” i säkerhetsinställningarna ett klick-skydd mot stora tränings-crawlers samtidigt som tillgång för sökmotorer bibehålls.
Effektiv selektiv blockering kräver ett systematiskt angreppssätt för att klassificera crawlers utifrån deras affärsvärde och trovärdighet. Istället för att behandla alla AI-crawlers lika bör publicister införa en trestegsmall som reflekterar det faktiska värdet och risken varje crawler innebär. Denna ram möjliggör nyanserade beslut som balanserar innehållsskydd med affärsmöjligheter.
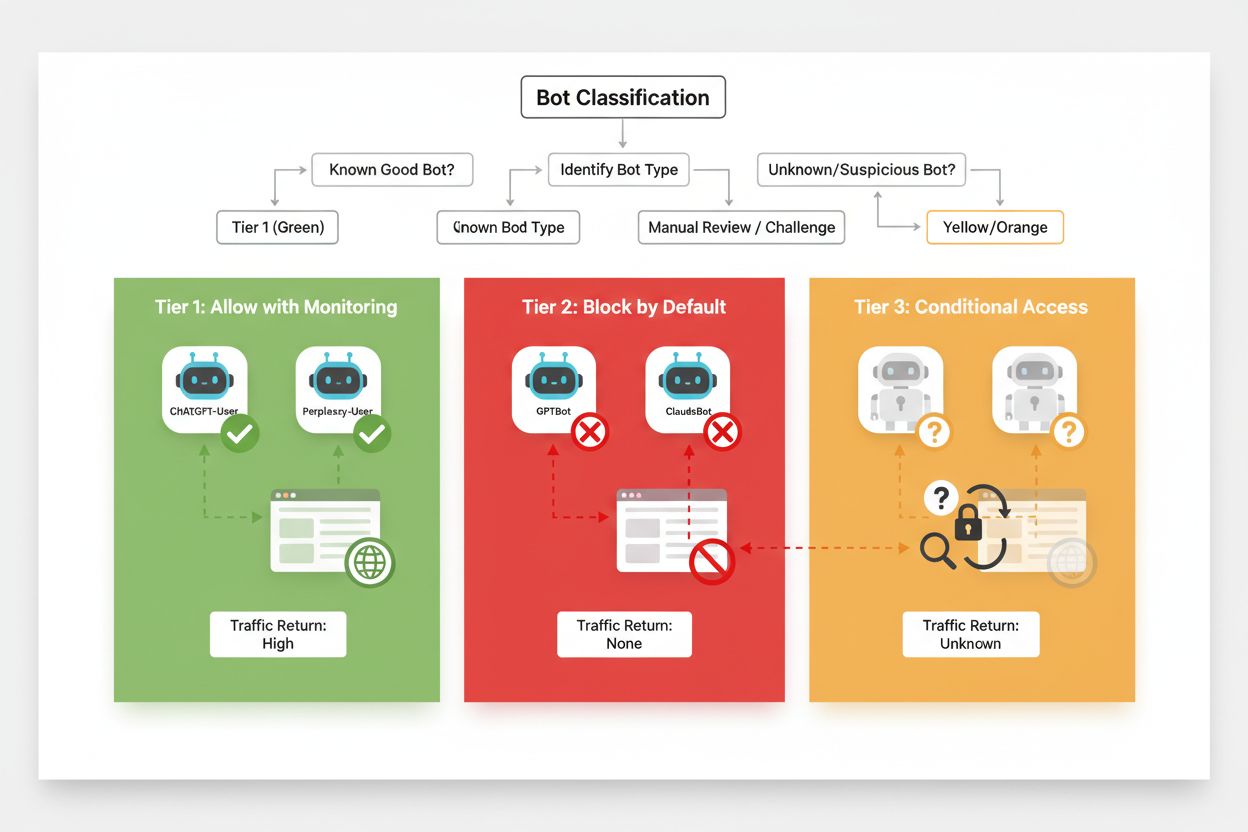
| Nivå | Klassificering | Exempel | Åtgärd |
|---|---|---|---|
| Nivå 1: Intäktsgeneratorer | Sökmotorer och högtrafikerade hänvisningskällor | Googlebot, Bingbot, Perplexity Bot | Tillåt all åtkomst; optimera för crawlbart innehåll |
| Nivå 2: Neutrala/Oprövade | Nya eller växande crawlers med oklar avsikt | Mindre AI-startups, forskningsbotar | Övervaka noga; tillåt med hastighetsbegränsning |
| Nivå 3: Värdeutvinnare | Tränings-crawlers utan direkt nytta | GPTBot, Claude-Web, CCBot | Blockera helt; tillämpa på flera nivåer |
Att implementera denna ram kräver kontinuerlig research kring nya crawlers och deras affärsmodeller. Publicister bör regelbundet granska sina accessloggar för att identifiera nya botar, undersöka operatörernas användarvillkor och ersättningspolicys samt justera klassificeringarna därefter. En crawler som börjar som nivå 3 kan flyttas till nivå 2 om operatören börjar erbjuda intäktsdelning, medan en tidigare betrodd crawler kan nedgraderas om den börjar bryta mot hastighetsbegränsningar eller robots.txt-direktiv.
Selektiv blockering är ingen engångskonfiguration – det kräver löpande övervakning och justering i takt med att crawlerekosystemet utvecklas. Publicister bör införa omfattande loggning och analys för att spåra vilka crawlers som kommer åt deras innehåll, hur mycket bandbredd de förbrukar och om de respekterar satta begränsningar. Dessa data ligger till grund för strategiska beslut om vilka crawlers som ska tillåtas, blockeras eller hastighetsbegränsas.
Analys av accessloggar avslöjar crawler-beteenden som informerar policyjusteringar:
# Identifiera alla AI-crawlers som besöker din sajt
grep -i "bot\|crawler" /var/log/nginx/access.log | \
awk '{print $12}' | sort | uniq -c | sort -rn | head -20
# Beräkna bandbredd som förbrukas av specifika crawlers
grep "GPTBot" /var/log/nginx/access.log | \
awk '{sum+=$10} END {print "GPTBot bandbredd: " sum/1024/1024 " MB"}'
# Övervaka 403-svar till blockerade crawlers
grep " 403 " /var/log/nginx/access.log | grep -i "bot" | wc -l
Regelbunden analys av dessa data – helst varje vecka eller månad – visar om din blockeringsstrategi fungerar som tänkt, om nya crawlers har dykt upp och om tidigare blockerade crawlers ändrat beteende. Denna information återkopplas till klassificeringsramen och säkerställer att dina policies förblir i linje med affärsmål och teknisk verklighet.
Publicister som inför selektiv blockering av crawlers gör ofta misstag som undergräver strategin eller skapar oönskade bieffekter. Att förstå dessa fallgropar hjälper dig undvika kostsamma fel och implementera en mer effektiv policy från början.
Blockera alla crawlers urskillningslöst: Det vanligaste felet är att använda alltför breda blockeringsregler som slår mot både sökmotorer och tränings-crawlers, vilket förstör söksynligheten i ett försök att skydda innehållet.
Att enbart lita på robots.txt: Att anta att robots.txt i sig förhindrar obehörig åtkomst bortser från att 13 % av crawlers ignorerar den helt, vilket lämnar ditt innehåll sårbart för bestämd datautvinning.
Att inte övervaka och justera: Att införa en statisk blockeringspolicy och aldrig se över den innebär att du missar nya crawlers, inte anpassar dig till ändrade affärsmodeller och potentiellt blockerar fördelaktiga crawlers som förbättrat sina rutiner.
Blockera endast utifrån user agent: Sofistikerade crawlers spoofar eller roterar ofta user agents, vilket gör user agent-baserad blockering ineffektiv utan kompletterande IP-baserade regler och hastighetsbegränsning.
Att ignorera hastighetsbegränsning: Även tillåtna crawlers kan förbruka onödigt mycket bandbredd om de inte hastighetsbegränsas, vilket försämrar prestandan för mänskliga användare och onödigt sliter på infrastrukturen.
Framtiden för relationen mellan publicister och AI-crawlers kommer troligen att innebära mer sofistikerad förhandling och kompensationsmodeller snarare än enkel blockering. Tills branschstandarder etableras är dock selektiv crawler-kontroll det mest praktiska sättet att skydda innehåll och samtidigt bibehålla söksynligheten. Publicister bör se sin blockeringsstrategi som en dynamisk policy som utvecklas i takt med crawler-ekosystemet och regelbundet omvärderar vilka crawlers som förtjänar åtkomst baserat på deras affärspåverkan och förtroendegrad.
De mest framgångsrika publicisterna kommer vara de som implementerar lager av skydd – genom att kombinera robots.txt-direktiv, servernivå-tillämpning, CDN-kontroller och löpande övervakning till en heltäckande strategi. Detta skyddar mot både kompatibla och icke-kompatibla crawlers, samtidigt som den sökmotortrafik som driver intäkter och användarengagemang bibehålls. I takt med att AI-företag alltmer erkänner värdet av publicisters innehåll och börjar erbjuda ersättning eller licensmodeller, kan den ram du bygger idag enkelt anpassas till nya affärsmodeller samtidigt som du behåller kontrollen över dina digitala tillgångar.
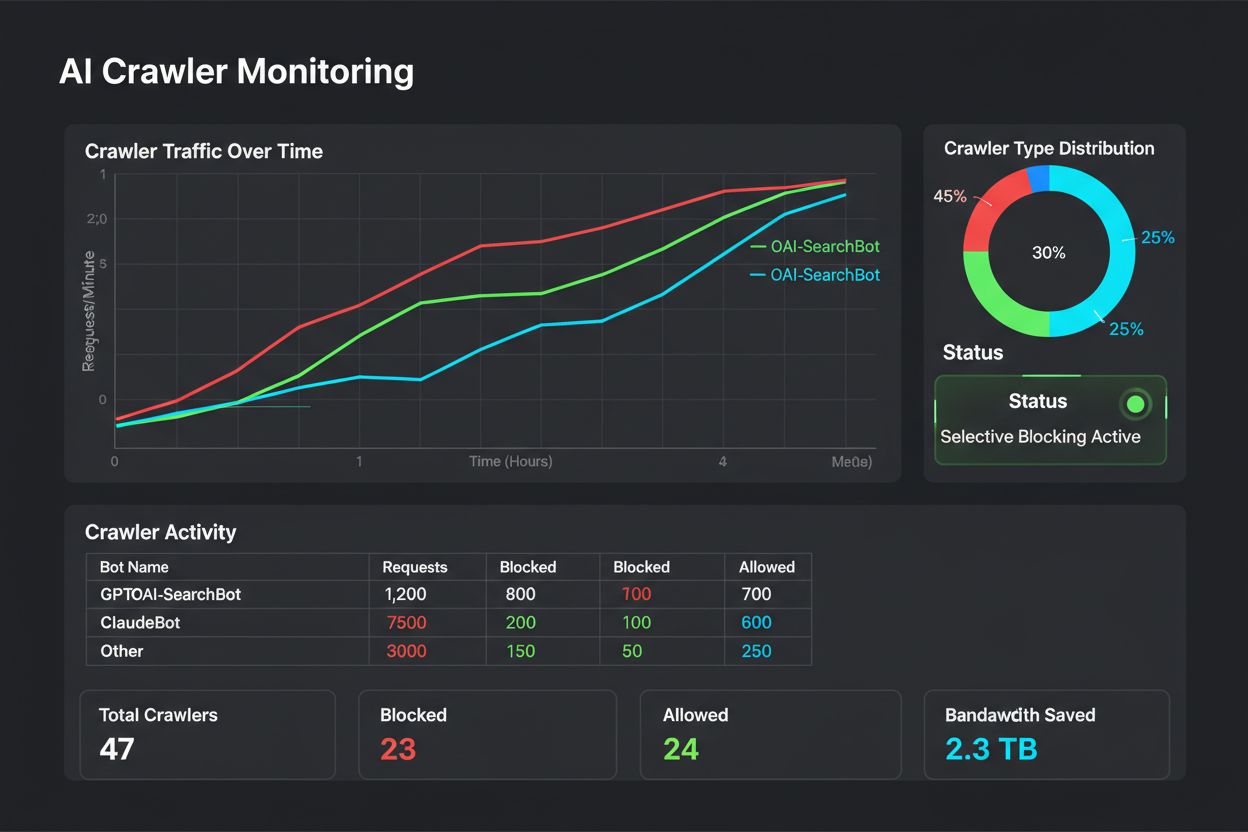
Tränings-crawlers som GPTBot och ClaudeBot samlar in data för att bygga AI-modeller utan att ge trafik tillbaka till din sajt. Sökmotor-crawlers som OAI-SearchBot och PerplexityBot indexerar innehåll för AI-sökmotorer och kan ge betydande hänvisningstrafik tillbaka till din sajt. Att förstå denna skillnad är avgörande för att implementera en effektiv selektiv blockeringsstrategi.
Ja, detta är kärnstrategin för selektiv kontroll av crawlers. Du kan använda robots.txt för att neka träningsbotar men tillåta sökbotar, och sedan upprätthålla detta med servernivå-kontroller för botar som ignorerar robots.txt. Denna metod skyddar ditt innehåll från obehörig träning samtidigt som synligheten i AI-sökresultat bibehålls.
De flesta större AI-företag hävdar att de följer robots.txt, men efterlevnaden är frivillig. Forskning visar att cirka 13 % av AI-botar ignorerar robots.txt-direktiv helt. Därför är servernivå-tillämpning avgörande för publicister som är seriösa med att skydda sitt innehåll från icke-kompatibla crawlers.
Betydande och växande. ChatGPT skickade 243,8 miljoner besök till 250 nyhets- och mediasajter i april 2025, en ökning med 98 % från januari. Att blockera dessa crawlers innebär att du förlorar denna nya trafik. För många publicister står AI-söktrafik nu för 5–15 % av all hänvisningstrafik.
Analysera dina serverloggar regelbundet med grep-kommandon för att identifiera bot-user agents, spåra crawl-frekvens och övervaka efterlevnaden av dina robots.txt-regler. Granska loggar minst en gång i månaden för att identifiera nya botar, ovanliga beteendemönster och om blockerade botar faktiskt håller sig borta. Dessa data informerar strategiska beslut om din crawler-policy.
Du skyddar ditt innehåll från obehörig träning men förlorar synlighet i AI-sökresultat, missar nya trafikströmmar och minskar potentiellt varumärkesomnämnanden i AI-genererade svar. Publicister som inför totalblockering ser ofta 40–60 % minskning i söksynlighet och missar möjligheter till varumärkesexponering via AI-plattformar.
Minst en gång i månaden, eftersom nya botar ständigt dyker upp och befintliga botar förändrar sitt beteende. AI-crawler-landskapet förändras snabbt, med nya aktörer som lanserar crawlers och befintliga som slår ihop eller byter namn på sina botar. Regelbundna översyner säkerställer att din policy förblir i linje med affärsmål och teknisk verklighet.
Det är antalet sidor som crawlas jämfört med besökare som skickas tillbaka till din sajt. Anthropic crawlar 38 000 sidor för varje besökare de skickar vidare, medan OpenAI har en kvot på 1 091:1 och Perplexity ligger på 194:1. Lägre kvoter indikerar bättre värde för att tillåta crawlern. Denna mätning hjälper dig avgöra vilka crawlers som förtjänar åtkomst baserat på deras faktiska affärspåverkan.
AmICited spårar vilka AI-plattformar som citerar ditt varumärke och innehåll. Få insikter om din AI-synlighet och säkerställ korrekt attribuering i ChatGPT, Perplexity, Google AI Overviews och fler.
Lär dig hur du fattar strategiska beslut om att blockera AI-crawlers. Utvärdera innehållstyp, trafikkällor, intäktsmodeller och konkurrensposition med vårt omfa...

Lär dig vilka AI-crawlers du ska tillåta eller blockera i din robots.txt. Omfattande guide som täcker GPTBot, ClaudeBot, PerplexityBot och 25+ AI-crawlers med k...

Lär dig hur du blockerar eller tillåter AI-crawlers som GPTBot och ClaudeBot med robots.txt, serverbaserad blockering och avancerade skyddsmetoder. Komplett tek...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.