Konkurrenters citeringskällor
Lär dig vad konkurrenters citeringskällor är och hur du analyserar vilka innehållstillgångar som driver konkurrenters AI-synlighet i ChatGPT, Perplexity och Goo...
11 min läsning
Lär dig varför citationskvalitet är viktigare än volym. Upptäck hur du mäter och optimerar AI-nämningar, länkar och inbäddningar för maximal affärsnytta.
De flesta varumärken är besatta av citeringsvolym – hur många gånger deras varumärke förekommer i AI-svar – men missar den avgörande insikten att alla citeringar inte är lika mycket värda. En citering som är dold i en sektion “se fler källor” genererar mindre än 2% klickfrekvens, medan samma citering som visas framträdande i ett AI-svar ger 15-25% CTR – en tiofaldig skillnad som de flesta övervakningsverktyg helt ignorerar. Om du spårar citeringsantal utan att mäta kvalitet, flyger du i blindo när det gäller vad som faktiskt driver trafik och konverteringar från AI-plattformar.
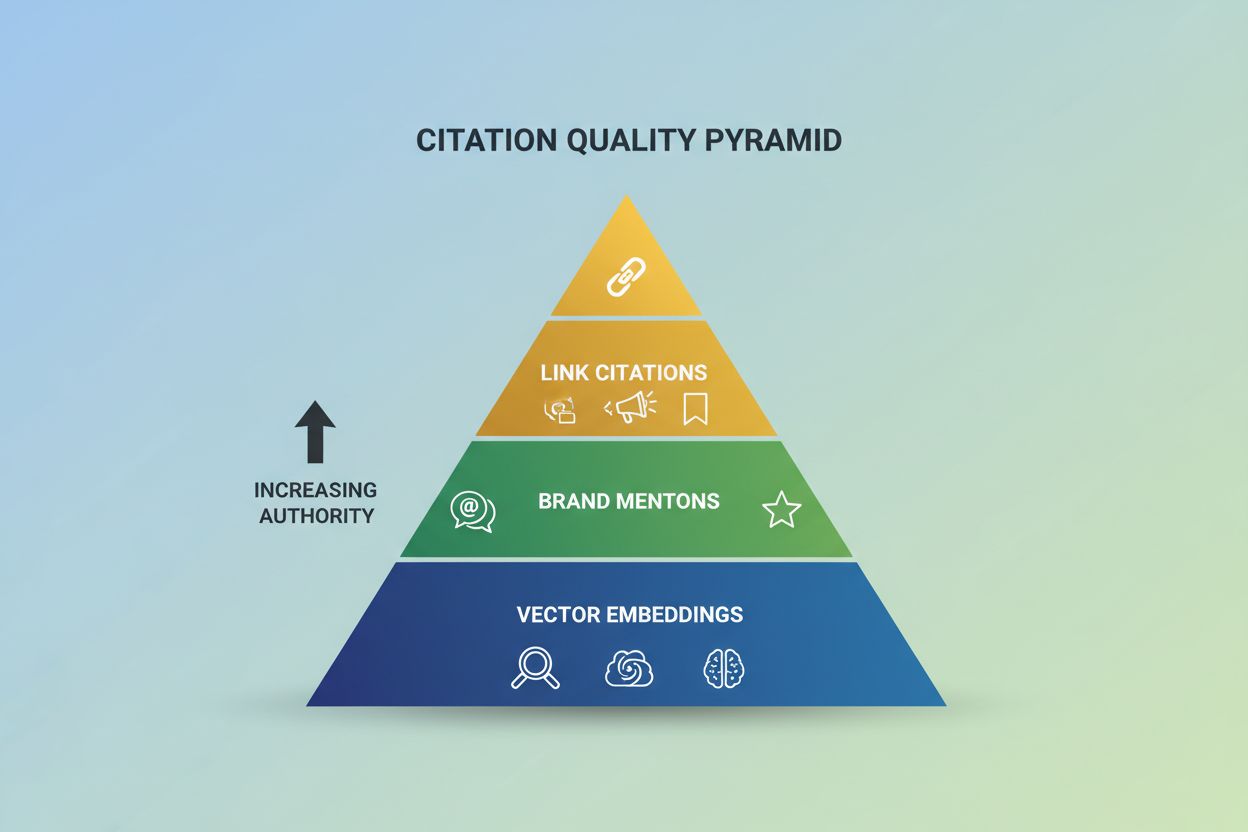
AI-citationskvalitet verkar över tre distinkta dimensioner som samverkar i svargenereringskedjan, och förståelsen av varje är avgörande för strategisk optimering. Vektor-inbäddningar avgör om ditt innehåll ens hämtas som en kandidatkälla, varumärkesnämningar signalerar auktoritet och bygger kännedom när AI-system nämner ditt varumärke vid namn, och länkciteringar driver direkttrafik när AI-plattformar tillskriver innehåll till din webbplats med klickbara URL:er. Forskning visar att hämtkvalitet (inbäddningar) står för 60-70% av variationsgraden i citeringar, medan auktoritetssignaler och attributmarkeringar påverkar resterande 30-40% – vilket betyder att om ditt innehåll inte hämtas från början hjälper ingen mängd E-E-A-T-optimering för att få dig citerad.
| Citationsdimension | Definition | Affärspåverkan |
|---|---|---|
| Vektor-inbäddningar | Semantisk representation i hämtssystem | Avgör om innehållet beaktas (60-70% av variationen) |
| Varumärkesnämningar | Referenser utan länkar | Bygger auktoritet och varumärkeskännedom |
| Länkciteringar | Tillskrivna källor med URL:er | Driver trafik och konverteringar |
Varje dimension kräver olika mätmetoder och optimeringsstrategier, men de flesta organisationer fokuserar uteslutande på länkciteringar och ignorerar den grundläggande rollen hos inbäddningar och varumärkesbyggande kraften i nämningar.

Data är entydiga: tio högkvalitativa citeringar från auktoritativa kontexter överträffar 100 lågkvalitativa nämningar när det gäller affärsresultat. Organisationer som gick från volymfokuserade till kvalitetsfokuserade citeringsstrategier såg 8,3x fler kvalificerade leads, 340% högre konverteringsgrad och 247% ökning av AI-driven trafik – mått som traditionell citeringsräkning helt missar. Bara variationen i placeringsposition skapar enorma skillnader i prestanda: framhävda citeringar i AI Overviews ger 15-25% klickfrekvens, medan citeringar som är gömda i expanderbara sektioner ger mindre än 2% CTR. Denna 10x-variation innebär att förbättrad citationskvalitet från ett genomsnitt på 45/100 till 65/100 ger mer affärsvärde än att öka citeringsvolymen med 50%, men de flesta varumärken fortsätter jaga volymmått som inte korrelerar med intäkter.
Att mäta nämningskvalitet systematiskt kräver en strukturerad test- och poängsättningsmetodik som går långt bortom enkel räkning. Börja med att identifiera 50–100 högt avsedda sökfrågor relevanta för ditt område – inkludera informationssökningar (“vad är X”), jämförelsefrågor (“X vs Y”), hur-gör-man-frågor (“hur gör man X”) och kommersiella sökningar (“bästa X för Y”) – och fråga ut dessa på större AI-plattformar varje månad och notera om ditt varumärke nämns, i vilket sammanhang, sentiment (positivt, neutralt, negativt) och positionering (huvudkälla, stödreferens, alternativ eller förbigående nämning). Utveckla ett viktat poängsystem som speglar affärsvärde:
En nämning som får 70+ poäng indikerar hög kvalitet – dessa är auktoritativa referenser i relevanta kontexter som stärker varumärkespositioneringen. Följ genomsnittligt kvalitetsbetyg för nämningar över tid, inte bara nämningsvolym; en förbättring från 45 till 65 i genomsnittlig kvalitet innebär verkliga framsteg även om volymen är konstant.
Länkciteringar är guldstandarden för många organisationer eftersom de kombinerar varumärkesexponering med direkttrafikmöjlighet, men citationskvaliteten varierar kraftigt beroende på placering, kontext, ankaretext och anpassning till användarintention. Utveckla ett poängsystem som speglar både synlighet och trafikpotential: placeringsframträdande (framhävd citering ovanför viket = 35 poäng, inline-citering i huvudsvaret = 25 poäng, stödkällförteckning = 15 poäng, expanderbar “se fler”-sektion = 8 poäng), kontextanpassning (direktsvar på fråga = 25 poäng, relevant stödjande detalj = 18 poäng, relaterad men indirekt = 10 poäng, svag relevans = 5 poäng), ankaretextkvalitet (beskrivande, intentionsbaserat ankare = 20 poäng, varumärkesnamn som ankare = 15 poäng, generiskt ankare som “källa” = 8 poäng, endast URL = 5 poäng), och sökintentsmatchning (perfekt anpassning = 20 poäng, bra matchning = 15 poäng, delvis matchning = 10 poäng, dålig matchning = 5 poäng). Citeringar med 75+ är premiumplaceringar som sannolikt driver meningsfull trafik och konverteringar, medan citeringar under 50 kanske tekniskt sett finns men ger minimalt affärsvärde. Följ både volymen av länkciteringar och fördelningen av kvalitetsbetyg – 100 lågkvalitativa citeringar är mycket mindre värda än 20 högkvalitativa.
Vektor-inbäddningar är den mest tekniska och minst synliga citationsdimensionen, men de avgör i grunden om ditt innehåll överhuvudtaget kommer i fråga för nämningar eller länkar. När användare gör förfrågningar till AI-system med Retrieval-Augmented Generation (RAG) börjar processen med att omvandla frågan till en vektor-inbäddning, söka i en vektordatabas efter semantiskt liknande innehållsinbäddningar och hämta de källor som är mest lika (vanligen 5–20 dokument) – om ditt innehåll inte hämtas i detta initiala skede når det aldrig faserna för auktoritetsbedömning eller citeringsurval. Vektor-inbäddningar representerar text som högdimensionella numeriska matriser (ofta 768 eller 1536 dimensioner) som kodar semantisk betydelse, där liknande begrepp har liknande vektorer mätta med cosinuslikhetspoäng från –1 till 1, där 1 är identisk betydelse och 0 ingen relation; forskning visar att hämtkvalitet korrelerar starkt med semantisk likhet över 0,75 för domänspecifika frågor. För att mäta din inbäddningskvalitet, generera inbäddningar för ditt innehåll och typiska användarfrågor med OpenAI:s text-embedding-3-modeller, Googles Vertex AI-inbäddningar eller open source-modeller som sentence-transformers, beräkna cosinuslikhet och identifiera vilka innehåll som når hög likhet (0,75+) för prioriterade frågor och vilka som inte når upp till tröskelvärden för hämtning (under 0,60). De flesta organisationer saknar teknisk infrastruktur för direkt inbäddningsanalys, men proxy-mått ger användbara insikter: analysera ditt innehållsbibliotek för fokuserad, konsekvent terminologi kring kärnbegrepp kontra ämnesdrift, utvärdera om din organisation och nyckelbegrepp är tydligt definierade med konsekventa namngivningar, bedöm om du täcker kärnämnen heltäckande kontra ytlig behandling, och granska interna länkningar – tät, logisk internlänkning mellan relaterade begrepp stärker de ämnessignaler som inbäddningsmodeller använder för att förstå innehållsfokus.
Effektiv utvärdering av citationskvalitet kräver integrerad mätning över alla tre dimensioner, där varje lager bygger på det föregående: starka inbäddningar möjliggör hämtning, hämtning möjliggör nämningsövervägande och nämningar med korrekt attribution blir länkciteringar. Bygg ett kvartalsvis mätframework som följer utvecklingen inom alla dimensioner genom att fastställa grundläggande mätvärden för 50–100 kärnfrågor, spåra månatliga förändringar i citeringsvolym och kvalitetsbetyg, beräkna kvalitetsbetyg för varje citeringstyp med dina viktade ramverk och benchmarka mot konkurrenter för att identifiera luckor och möjligheter. Din dashboard bör visa fyra nyckelmått: Vektorkvalitet (semantiska likhetspoäng, ämneskonsistens, entitetskärpa – sikta på 0,75+ likhet för kärnfrågor), Nämningskvalitet (nämningsfrekvens, genomsnittligt kvalitetsbetyg, sentimentsfördelning – sikta på 30%+ nämningsfrekvens och 65+ i snittkvalitet), Länkkvalitet (citeringsvolym, kvalitetsbetygsfördelning, uppskattad CTR – målet 20+ citeringar och 70+ i snittkvalitet), och Affärspåverkan (AI-driven trafik, varumärkessökvolym, konverteringsgrad – målet 15%+ trafik från AI-citeringar). När resurserna är begränsade, prioritera förbättringar utifrån nuvarande flaskhals: om inbäddningskvaliteten är svag, börja där eftersom ingen mängd E-E-A-T-arbete hjälper om innehållet inte hämtas; om inbäddningskvaliteten är stark men nämningsfrekvensen låg, fokusera på auktoritetssignaler och innehållsdjup; om nämningar är starka men länkciteringar släpar, lägg fokus på teknisk attributmarkering och schemaimplementering.
Varje större AI-plattform visar tydliga citeringspreferenser som kräver skräddarsydda optimeringsstrategier, där forskning på 680 miljoner citeringar avslöjar dramatiskt olika källmönster. ChatGPT visar en stark förkärlek för auktoritativa kunskapsbaser, där Wikipedia står för 7,8% av alla citeringar och 47,9% av de tio mest citerade källorna – denna koncentration indikerar att ChatGPT prioriterar encyklopediskt, faktabaserat innehåll framför social diskurs och nya plattformar. Google AI Overviews har en mer balanserad strategi, med Reddit i topp på 2,2% av alla citeringar men bara 21% av de tio mest citerade, medan YouTube (18,8%), Quora (14,3%) och LinkedIn (13%) också syns ofta – denna fördelning visar att Google värdesätter både professionellt innehåll och community-diskussioner. Perplexity visar en unik community-drivna filosofi, där Reddit dominerar med 6,6% av alla citeringar och 46,7% av topp 10, följt av YouTube (13,9%) och Gartner (7%) – detta mönster visar att Perplexity prioriterar peer-to-peer-information och verkliga erfarenheter framför traditionella auktoritetssignaler. Dessa plattformsskillnader innebär att en universell citeringsstrategi misslyckas: varumärken bör fokusera på Wikipedia och auktoritativa källor för synlighet i ChatGPT, balansera professionellt innehåll med community-engagemang för Google AI Overviews och satsa mycket på Reddit-deltagande och användargenererat innehåll för Perplexity. Att förstå plattformsspecifika preferenser hjälper dig fördela innehålls- och PR-resurser strategiskt istället för att sprida insatserna jämnt över alla plattformar.
Att förbättra citationskvalitet kräver särskilda strategier för varje dimension av citationsstacken. För vektor-inbäddningar, stärk semantisk tydlighet med heltäckande ämneskluster som grundligt behandlar kärnbegrepp med konsekvent terminologi och tydlig hierarki; använd beskrivande rubriker, definitioner och entitetsreferenser som hjälper inbäddningsmodeller förstå innehållsfokus; undvik att blanda orelaterade ämnen på enskilda sidor eftersom semantisk drift skapar brusiga inbäddningar med dålig hämtning; implementera strategisk internlänkning mellan relaterade begrepp för att stärka ämnessignaler; citera auktoritativa källor för att ge sammanhang som inbäddningsmodeller använder för att förstå ditt innehålls domän och fokus; och håll innehållet aktuellt genom regelbundna uppdateringar, eftersom föråldrat innehåll kan ha inaktuella semantiska signaler. För varumärkesnämningar, bygg verifierbar ämnesauktoritet genom att stärka E-E-A-T-signaler med detaljerade författaruppgifter, organisatorisk transparens och konsekvent citering av auktoritativa källor; skapa heltäckande innehåll som till fullo möter användarens behov utan att AI-systemen tvingas syntetisera information från flera fragmenterade källor; publicera egen forskning och unika data som inte finns någon annanstans eftersom AI-system föredrar unikt, förstahandsmaterial; och delta aktivt i branschdiskussioner, forum och communities där ditt varumärke hör hemma. För länkciteringar, implementera omfattande schema-markering – särskilt Article, HowTo, FAQPage och Organization-schema – för att tydliggöra innehållets syfte och attribution; säkerställ rena URL-strukturer, snabba sidladdningar och mobiloptimering eftersom AI-system föredrar tekniskt robusta källor; skapa självständiga innehållsblock med tydliga rubriker som kan stå för sig själva när de extraheras till AI-svar; fokusera innehållsstrategin på guider och FAQ-format som naturligt lämpar sig för citering; och bygg författarsidor med uppgifter som verifierar expertis samt säkerställ att Kontakt-, Om- och Integritetssidor möter transparenskrav.
Ett B2B SaaS-bolag inom marknadsföringsteknologi införde en omfattande utvärdering av citationskvalitet efter att ha märkt att konkurrenter oftare förekom i AI-genererade rekommendationer, vilket gav en avgörande insikt som förändrade deras strategi. Deras första granskning visade stark länkciteringsvolym (85 citeringar över prioriterade frågor) men låga kvalitetsbetyg (genomsnitt 42/100) och svaga nämningsfrekvenser (12% över testade frågor) – analysen visade att deras innehåll hämtades (bra inbäddningskvalitet) och ibland citerades med länk (tillräcklig teknisk markup), men nämningar var sällsynta eftersom innehållet saknade djup och auktoritetssignaler. De fokuserade optimeringen på att stärka författaruppgifter med detaljerade biografier och publiceringshistorik, publicerade egen forskningsdata som konkurrenterna inte kunde replikera, och skapade heltäckande guider istället för tunna blogginlägg som blandade information från flera källor. Efter sex månaders kvalitetsfokuserad optimering ökade nämningsfrekvensen till 31% (en förbättring med 158%), länkciteringskvaliteten till 68/100 (en förbättring med 62%) och AI-driven trafik växte med 47% – men den verkliga lärdomen var att deras tekniska grund (inbäddningar och markup) redan var solid, vilket innebar att flaskhalsen låg i auktoritetssignaler snarare än teknisk implementation. Detta fall visar att mätning av citationskvalitet avslöjar specifika optimeringsmöjligheter som volymfokuserad spårning helt missar, och gör det möjligt för organisationer att satsa resurser där de ger mest effekt istället för att följa generella bästa praxis som inte löser deras verkliga flaskhalsar.
Citeringsvolym är det totala antalet nämningar eller länkar. Kvalitet mäter värdet av varje citering baserat på placering, kontext, sentiment och auktoritet. Tio högkvalitativa citeringar från auktoritativa källor ger mer värde än 100 lågkvalitativa nämningar. Kvalitet korrelerar direkt med affärsresultat som trafik och konverteringar.
Testa 50-100 relevanta sökfrågor över AI-plattformar varje månad. För varje citering, poängsätt baserat på: placeringsframträdande (0-35 poäng), kontextanpassning (0-25 poäng), ankaretextkvalitet (0-20 poäng) och sökintentsmatchning (0-20 poäng). Följ genomsnittliga poäng över tid. Citeringar med 75+ representerar premiumplaceringar som sannolikt driver meningsfull trafik.
Alla tre är viktiga i olika skeden. Inbäddningar avgör återhämtning (60-70 % av citationsvariansen). Nämningar bygger auktoritet och kännedom. Länkar driver trafik och konverteringar. Framgång kräver optimering av alla tre dimensioner med anpassade strategier för varje.
Varje plattform har olika träningsdata, algoritmer och designfilosofier. ChatGPT favoriserar auktoritativa källor som Wikipedia. Google AI Overviews balanserar professionellt och socialt innehåll. Perplexity prioriterar diskussioner i communityn. Optimera för varje plattforms preferenser snarare än att använda en universell strategi.
Genomför heltäckande granskningar kvartalsvis med månatliga stickprov på högt prioriterade ämnen. Följ ledande indikatorer veckovis: organisk trafik från AI, varumärkessökvolym och trender för citeringsfrekvens. Justera strategi baserat på förändringar i kvalitetsbetyg för att upptäcka tidiga nedgångar som kräver åtgärder.
Delvis. Förbättra befintligt innehåll med bättre struktur, schema-markering och författaruppgifter. Stärk E-E-A-T-signaler. Att skapa nytt, citeringsvärt innehåll (egen forskning, heltäckande guider) är dock det mest effektiva sättet att förbättra kvalitetspoängen.
För länkciteringar: 70+ är utmärkt. För nämningar: 60+ indikerar stark kontextuell relevans. För inbäddningar: 0,75+ semantisk likhet. Konkurrensutsatta branscher kräver högre trösklar. Fokusera på att förbättra 10-15 poäng per kvartal istället för att jaga perfektion.
AmICited.com spårar hur AI-system refererar till ditt varumärke över ChatGPT, Perplexity, Google AI Overviews och andra plattformar. Det mäter kvalitetsmått utöver volym, visar placering, sentiment, kontext och konkurrenspositionering för att hjälpa dig optimera strategiskt.
Sluta räkna nämningar och börja mäta det som verkligen spelar roll. AmICited.com spårar citationskvalitet över alla större AI-plattformar och visar dig exakt vilka nämningar som skapar värde och var du ska optimera härnäst.
Lär dig vad konkurrenters citeringskällor är och hur du analyserar vilka innehållstillgångar som driver konkurrenters AI-synlighet i ChatGPT, Perplexity och Goo...

Diskussion i communityn om hur AI-modeller bestämmer vad som ska citeras. Riktiga erfarenheter från SEOs som analyserar citeringsmönster hos ChatGPT, Perplexity...

Lär dig vad Citation Quality Score är och hur det mäter framträdande plats, kontext och sentiment i AI-citat. Upptäck hur du utvärderar citatskvalitet, implemen...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.