
AI Crawler Access Audit: Ser Rätt Botar Ditt Innehåll?
Lär dig hur du granskar AI-crawlers åtkomst till din webbplats. Upptäck vilka botar som kan se ditt innehåll och åtgärda hinder som förhindrar AI-synlighet i Ch...
8 min läsning

Lär dig hur du blockerar eller tillåter AI-crawlers som GPTBot och ClaudeBot med robots.txt, serverbaserad blockering och avancerade skyddsmetoder. Komplett teknisk guide med exempel.
Det digitala landskapet har fundamentalt förändrats från traditionell sökmotoroptimering till hantering av en helt ny kategori automatiserade besökare: AI-crawlers. Till skillnad från vanliga sökbotar som driver trafik tillbaka till din webbplats via sökresultat, konsumerar AI-träningscrawlers ditt innehåll för att bygga stora språkmodeller utan att nödvändigtvis ge någon hänvisningstrafik tillbaka. Denna skillnad har djupgående konsekvenser för publicister, innehållsskapare och företag som är beroende av webtrafik som intäktskälla. Insatserna är höga—att kontrollera vilka AI-system som får åtkomst till ditt innehåll påverkar direkt din konkurrensfördel, dataintegritet och resultat.
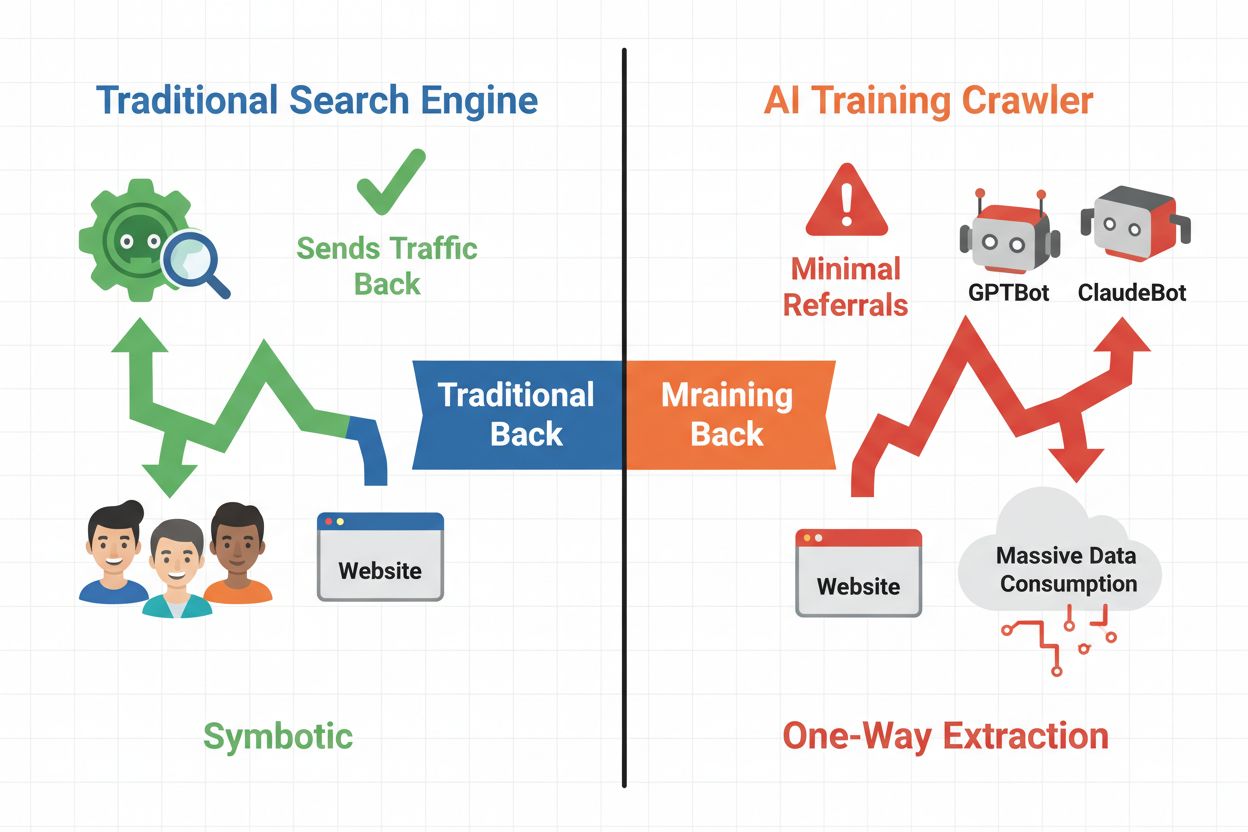
AI-crawlers delas in i tre tydliga kategorier, var och en med olika syften och trafikpåverkan. Träningscrawlers används av AI-företag för att bygga och förbättra sina språkmodeller, ofta i stor skala och med minimal återkopplingstrafik. Sök- och citeringscrawlers indexerar innehåll för AI-drivna sökmotorer och citeringssystem, och ger ofta viss hänvisningstrafik tillbaka till publicister. Användarinitierade crawlers hämtar innehåll på begäran när användare interagerar med AI-applikationer, vilket representerar en mindre men växande kategori. Att förstå dessa kategorier hjälper dig att fatta informerade beslut om vilka crawlers du ska tillåta eller blockera utifrån din affärsmodell.
| Crawler-typ | Syfte | Trafikpåverkan | Exempel |
|---|---|---|---|
| Träning | Bygga/förbättra LLM:er | Minimal till ingen | GPTBot, ClaudeBot, Bytespider |
| Sök/Citering | Indexera för AI-sök & citeringar | Måttlig hänvisningstrafik | Googlebot-Extended, Perplexity |
| Användarinitierad | Hämtar på begäran för användare | Låg men konsekvent | ChatGPT-plugins, Claude browsing |
AI-crawler-ekosystemet inkluderar crawlers från världens största teknikföretag, alla med olika user agents och syften. OpenAIs GPTBot (user agent: GPTBot/1.0) crawlar för att träna ChatGPT och andra modeller, medan Anthropics ClaudeBot (user agent: Claude-Web/1.0) har liknande syften för Claude. Googles Googlebot-Extended (user agent: Mozilla/5.0 ... Googlebot-Extended) indexerar innehåll för AI Overviews och Bard, medan Metas Meta-ExternalFetcher crawlar för deras AI-initiativ. Andra viktiga aktörer inkluderar:
Varje crawler arbetar i olika skala och respekterar blockeringsdirektiv i varierande grad.
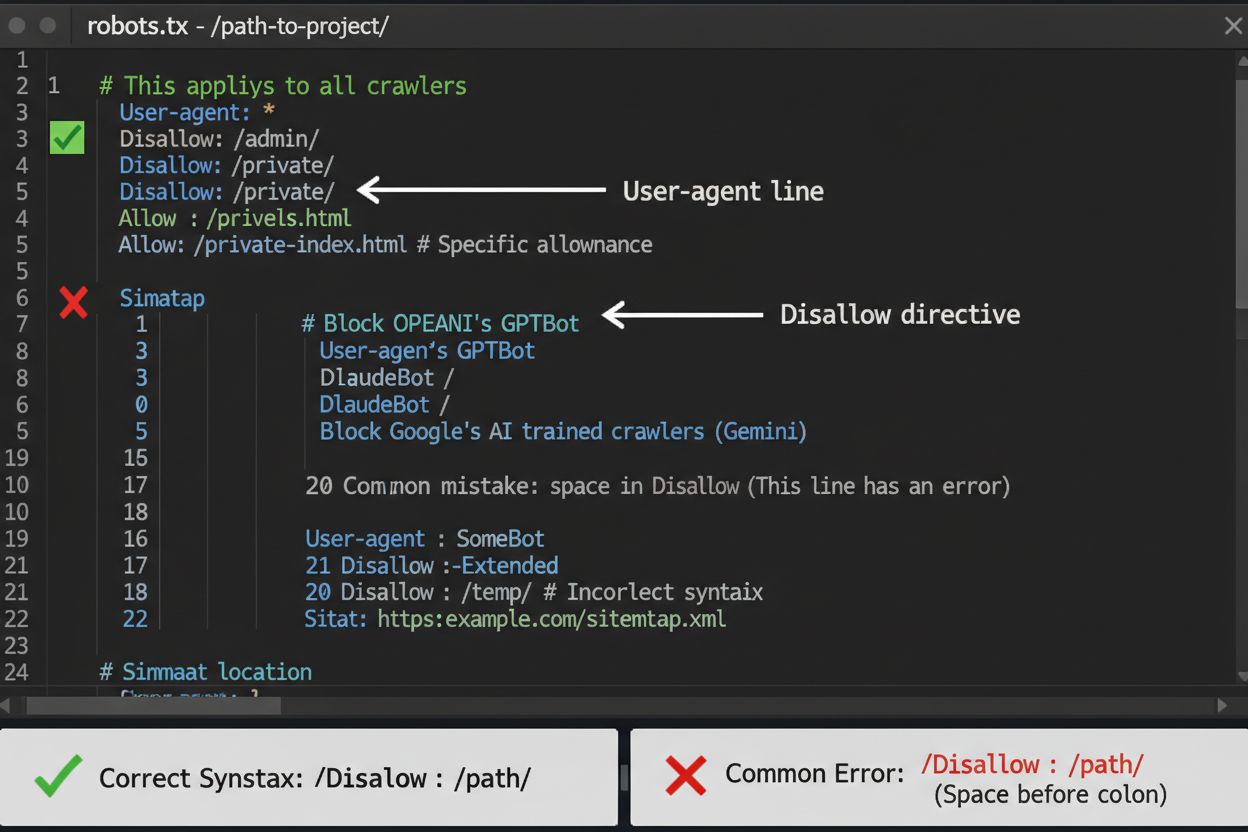
robots.txt-filen är ditt första försvarslinje för att kontrollera AI-crawler-åtkomst, men det är viktigt att förstå att den är rådgivande och inte juridiskt bindande. Filen ligger i roten av din domän (t.ex. dinsajt.se/robots.txt) och använder enkel syntax för att instruera crawlers vilka områden de ska undvika. För att blockera alla AI-crawlers helt, lägg till följande regler:
User-agent: GPTBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Googlebot-Extended
Disallow: /
User-agent: Meta-ExternalFetcher
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
Om du föredrar selektiv blockering—tillåter sökcrawlers men blockerar träningscrawlers—använd denna metod:
User-agent: GPTBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Googlebot-Extended
Disallow: /news/
Allow: /
Ett vanligt misstag är att använda alltför breda regler som Disallow: * vilket kan förvirra parsers, eller att glömma att specificera enskilda crawlers när du bara vill blockera vissa. Stora företag som OpenAI, Anthropic och Google respekterar generellt robots.txt-direktiv, även om vissa crawlers som Perplexity har dokumenterats ignorera dessa regler helt.
När robots.txt inte räcker finns flera starkare skyddsmetoder som ger ytterligare kontroll över AI-crawlers. IP-baserad blockering innebär att identifiera AI-crawlers IP-intervall och blockera dem på brandväggs- eller servernivå—detta är mycket effektivt men kräver löpande underhåll när IP-intervall ändras. Serverbaserad blockering via .htaccess-filer (Apache) eller Nginx-konfiguration ger mer detaljerad kontroll och är svårare att kringgå än robots.txt. För Apache-servrar, implementera denna blockregel:
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (GPTBot|Claude-Web|Bytespider|Amazonbot) [NC]
RewriteRule ^.*$ - [F,L]
</IfModule>
Metatag-blockering med <meta name="robots" content="noindex, noimageindex, nofollowbydefault"> förhindrar indexering men stoppar inte träningscrawlers. Kontroll av förfrågningshuvuden innebär att kontrollera om crawlers verkligen kommer från den angivna källan genom att verifiera omvänd DNS och SSL-certifikat. Använd serverbaserad blockering när du behöver absolut säkerhet att crawlers inte kommer åt ditt innehåll och kombinera flera metoder för maximalt skydd.
Att besluta om du ska blockera AI-crawlers innebär att väga flera motstridiga intressen. Att blockera träningscrawlers (GPTBot, ClaudeBot, Bytespider) förhindrar att ditt innehåll används för att träna AI-modeller, vilket skyddar din immateriella egendom och konkurrensfördel. Att tillåta sökcrawlers (Googlebot-Extended, Perplexity) kan däremot generera hänvisningstrafik och öka synligheten i AI-drivna sökresultat—en växande kanal för upptäckt. Avvägningen blir mer komplex när man beaktar att vissa AI-företag har dåliga crawl-till-hänvisningsförhållanden: Anthropics crawlers genererar ungefär 38 000 crawl-förfrågningar för varje enskild hänvisning, medan OpenAIs förhållande är ungefär 400:1. Serverbelastning och bandbredd är en annan faktor—AI-crawlers förbrukar betydande resurser och blockering kan minska infrastrukturkostnader. Ditt beslut bör stämma överens med din affärsmodell: nyhetsorganisationer och publicister kan dra nytta av hänvisningstrafik, medan SaaS-företag och skapare av proprietärt innehåll vanligtvis föredrar blockering.
Att implementera crawlerblockering är bara halva jobbet—du måste även verifiera att crawlers faktiskt respekterar dina direktiv. Serverlogganalys är ditt huvudsakliga verifieringsverktyg; granska dina accessloggar efter användaragentsträngar och IP-adresser från crawlers som försöker komma åt din webbplats efter blockering. Använd grep för att söka i loggarna:
grep -i "gptbot\|claude-web\|bytespider" /var/log/apache2/access.log | wc -l
Detta kommando räknar hur många gånger dessa crawlers har besökt din sajt. Testverktyg som curl kan simulera crawler-förfrågningar för att verifiera att dina blockregler fungerar korrekt:
curl -A "GPTBot/1.0" https://dinsajt.se/robots.txt
Övervaka dina loggar varje vecka under den första månaden efter att du infört blockeringar och därefter varje kvartal. Om du upptäcker crawlers som ignorerar din robots.txt, gå vidare till serverbaserad blockering eller kontakta crawleroperatörens abuse-team.
AI-crawler-landskapet utvecklas snabbt när nya företag lanserar AI-produkter och befintliga crawlers byter användaragentsträngar och IP-intervall. Kvartalsvisa granskningar av din blocklista säkerställer att du inte missar nya crawlers eller av misstag blockerar legitim trafik. Crawler-ekosystemet är fragmenterat och decentraliserat, vilket gör det omöjligt att skapa en helt permanent blocklista. Övervaka dessa resurser för uppdateringar:
Sätt kalenderpåminnelser för att granska din robots.txt och serverbaserade regler var 90:e dag, och prenumerera på säkerhetslistor som bevakar nya crawler-utrullningar.
Samtidigt som blockering av AI-crawlers förhindrar dem från att komma åt ditt innehåll, adresserar AmICited den kompletterande utmaningen: att övervaka om AI-system citerar och refererar till ditt varumärke och innehåll i sina svar. AmICited spårar omnämnanden av din organisation i AI-genererade svar och ger insyn i hur ditt innehåll påverkar AI-modellers resultat och var ditt varumärke syns i AI-sökresultat. Detta skapar en heltäckande AI-strategi: du styr vad crawlers får åtkomst till via robots.txt och serverbaserad blockering, medan AmICited säkerställer att du förstår den vidare effekten av ditt innehåll på AI-system. Tillsammans ger dessa verktyg dig fullständig insyn och kontroll över din närvaro i AI-ekosystemet—från att förhindra oönskad träning på ditt data till att mäta de faktiska citeringar och referenser ditt innehåll genererar i AI-plattformar.
Nej. Att blockera AI-träningscrawlers som GPTBot, ClaudeBot och Bytespider påverkar inte dina Google- eller Bing-sökresultat. Traditionella sökmotorer använder andra crawlers (Googlebot, Bingbot) som arbetar oberoende. Blockera endast dessa om du vill försvinna helt från sökresultat.
Större crawlers från OpenAI (GPTBot), Anthropic (ClaudeBot), Google (Google-Extended) och Perplexity (PerplexityBot) uppger officiellt att de respekterar robots.txt-direktiv. Mindre eller mindre transparenta botar kan dock ignorera din konfiguration, vilket är anledningen till att lagerbaserade skyddsstrategier finns.
Det beror på din strategi. Om du endast blockerar träningscrawlers (GPTBot, ClaudeBot, Bytespider) skyddar du ditt innehåll från modellträning samtidigt som du tillåter sökfokuserade crawlers hjälpa dig att synas i AI-sökresultat. Fullständig blockering tar bort dig helt från AI-ekosystemen.
Granska din konfiguration minst varje kvartal. AI-företag introducerar regelbundet nya crawlers. Anthropic slog samman sina 'anthropic-ai'- och 'Claude-Web'-botar till 'ClaudeBot', vilket gav den nya boten tillfällig obegränsad åtkomst till webbplatser som inte hade uppdaterat sina regler.
Blockering förhindrar crawlers från att få åtkomst till ditt innehåll helt och hållet, vilket skyddar det från datainsamling för träning eller indexering. Att tillåta crawlers ger dem tillgång men kan innebära att ditt innehåll används för modellträning eller syns i AI-sökresultat med minimal hänvisningstrafik.
Ja, robots.txt är rådgivande snarare än juridiskt bindande. Välskötta crawlers från större företag respekterar i regel robots.txt-direktiv, men vissa crawlers ignorerar dem. För starkare skydd, implementera serverbaserad blockering via .htaccess eller brandväggsregler.
Kontrollera dina serverloggar efter användaragentsträngar för blockerade crawlers. Om du ser förfrågningar från crawlers du har blockerat, kanske de inte respekterar robots.txt. Använd testverktyg som Google Search Consoles robots.txt-tester eller curl-kommandon för att verifiera din konfiguration.
Att blockera träningscrawlers har vanligtvis minimal direkt påverkan på trafiken eftersom de ändå skickar lite hänvisningstrafik. Att blockera sökcrawlers kan däremot minska synligheten i AI-baserade upptäcktsplattformar. Övervaka din analys i 30 dagar efter att du har implementerat blockeringar för att mäta faktisk påverkan.
Även om du styr crawleråtkomst med robots.txt hjälper AmICited dig att spåra hur AI-system citerar och refererar till ditt innehåll i sina svar. Få fullständig insyn i din AI-närvaro.
Lär dig hur du granskar AI-crawlers åtkomst till din webbplats. Upptäck vilka botar som kan se ditt innehåll och åtgärda hinder som förhindrar AI-synlighet i Ch...

Fullständig referensguide till AI-crawlers och botar. Identifiera GPTBot, ClaudeBot, Google-Extended och 20+ andra AI-crawlers med user agents, crawl-hastighete...

Lär dig identifiera och övervaka AI-crawlers som GPTBot, ClaudeBot och PerplexityBot i dina serverloggar. Komplett guide med user-agent-strängar, IP-verifiering...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.