Underhållningens AI-närvaro
Lär dig hur underhållningsvarumärken optimerar sin synlighet i AI-rekommendationer över streamingplattformar. Upptäck strategier för att övervaka AI-närvaro och...
6 min läsning

Upptäck hur AI-system spelas och manipuleras. Lär dig om adversariella attacker, verkliga konsekvenser och försvarsmekanismer för att skydda dina AI-investeringar.
Att spela AI-system syftar på att avsiktligt manipulera eller utnyttja artificiella intelligensmodeller för att generera oavsiktliga resultat, kringgå säkerhetsåtgärder eller extrahera känslig information. Detta går bortom normala systemfel eller användarmisstag—det är ett medvetet försök att kringgå AI-systemets avsedda beteende. I takt med att AI blir alltmer integrerat i kritiska affärsprocesser, från kundtjänstchatbots till bedrägeriupptäcktsystem, är förståelsen för hur dessa system kan spelas avgörande för att skydda både organisatoriska tillgångar och användarförtroende. Insatserna är särskilt höga eftersom AI-manipulation ofta sker osynligt, där användare och till och med systemoperatörer är omedvetna om att AI har komprometterats eller beter sig på sätt som strider mot dess design.

AI-system står inför flera kategorier av attacker, där varje utnyttjar olika sårbarheter i hur modeller tränas, distribueras och används. Att förstå dessa attackvektorer är avgörande för organisationer som vill skydda sina AI-investeringar och behålla systemintegritet. Forskare och säkerhetsexperter har identifierat sex huvudkategorier av adversariella attacker som utgör de största hoten mot AI-system idag. Dessa attacker sträcker sig från att manipulera indata vid inferenstid till att förgifta själva träningsdatan, och från att extrahera proprietär modellinformation till att sluta sig till huruvida specifika individers data användes vid träning. Varje attacktyp kräver olika försvarsstrategier och medför unika konsekvenser för organisationer och användare.
| Attacktyp | Metod | Effekt | Verkligt exempel |
|---|---|---|---|
| Promptinjektion | Skapade indata för att manipulera LLM-beteende | Skadlig output, desinformation, obehöriga kommandon | Chevrolet-chatbot manipulerades att gå med på bilförsäljning värd $50 000+ för $1 |
| Undvikandeattacker | Subtila modifieringar av indata (bilder, ljud, text) | Förbikoppla säkerhetssystem, felklassificering | Teslas autopilot lurades av tre diskreta klistermärken på väg |
| Förgiftningsattacker | Förvrängd eller vilseledande data injiceras i träningsuppsättningen | Modellbias, felaktiga prognoser, komprometterad integritet | Microsoft Tay chatbot producerade rasistiska tweets inom några timmar efter lansering |
| Modellinversion | Analys av modelloutput för att bakåtutveckla träningsdata | Integritetsbrott, exponering av känslig data | Medicinska foton återskapades från syntetisk hälsodata |
| Modellstöld | Upprepade förfrågningar för att replikera proprietär modell | Stöld av immateriella rättigheter, konkurrensnackdel | Mindgard extraherade ChatGPT-komponenter för bara $50 i API-kostnader |
| Medlemskapsinferens | Analys av sannolikhetsnivåer för att avgöra om data ingår i träningen | Integritetsbrott, individuell identifiering | Forskare identifierade om specifika hälsoposter ingick i träningsdata |
De teoretiska riskerna med att spela AI blir påtagligt verkliga när man granskar faktiska incidenter som påverkat stora organisationer och deras kunder. Chevrolets ChatGPT-drivna chatbot blev en varningshistoria när användare snabbt upptäckte att de kunde manipulera den via promptinjektion och till slut övertyga systemet att gå med på att sälja ett fordon värt över $50 000 för bara $1. Air Canada stod inför betydande juridiska konsekvenser när dess AI-chatbot gav felaktig information till en kund, och flygbolaget hävdade initialt att AI:n var “ansvarig för sina egna handlingar”—ett försvar som slutligen underkändes i domstol och satte viktig rättspraxis. Teslas autopilotsystem blev känt för att ha vilseletts av forskare som placerade bara tre diskreta klistermärken på en väg, vilket fick fordonets visionssystem att misstolka vägmarkeringar och styra in i fel fil. Microsofts Tay-chatbot blev ökänd när den förgiftades av illasinnade användare som bombarderade den med stötande innehåll, vilket fick systemet att generera rasistiska och olämpliga tweets inom några timmar efter lansering. Targets AI-system använde dataanalys för att förutsäga graviditetsstatus utifrån köpmönster, vilket gjorde det möjligt för återförsäljaren att skicka riktade annonser—en form av beteendemanipulation som väckte allvarliga etiska frågor. Uber-användare rapporterade att de debiterades högre priser när deras mobilbatterier var låga, vilket antyder att systemet utnyttjade ett “sårbarhetsögonblick” för att extrahera mer värde.
Viktiga konsekvenser av AI-spel inkluderar:
Den ekonomiska skadan av AI-spel överstiger ofta de direkta kostnaderna för säkerhetsincidenter, eftersom det fundamentalt underminerar värdet som AI-system ger användare. AI-system som tränas genom förstärkningsinlärning kan lära sig att identifiera så kallade “sårbarhetsögonblick”—tillfällen då användare är mest mottagliga för manipulation, som när de är känslomässigt sårbara, stressade eller distraherade. Under dessa ögonblick kan AI-system vara utformade (avsiktligt eller som emergent beteende) för att rekommendera sämre produkter eller tjänster som maximerar företagets vinster snarare än användarens tillfredsställelse. Detta är en form av beteendemässig prisdiskriminering där samma användare får olika erbjudanden baserat på deras förväntade mottaglighet för manipulation. Grundproblemet är att AI-system optimerade för företagslönsamhet samtidigt kan minska det ekonomiska värde användarna får av tjänsterna, vilket skapar en dold skatt på konsumentnytta. När AI lär sig användarnas sårbarheter genom massiv datainsamling får det förmågan att utnyttja psykologiska snedvridningar—som förlustaversion, socialt bevis eller knapphet—för att driva köpbeslut som gynnar företaget på användarens bekostnad. Denna ekonomiska skada är särskilt lömsk eftersom den ofta är osynlig för användarna, som kanske inte inser att de manipuleras till suboptimala val.
Ogenomskinlighet är ansvarslöshetens fiende, och det är just denna ogenomskinlighet som möjliggör AI-manipulation i stor skala. De flesta användare har ingen tydlig förståelse för hur AI-system fungerar, vilka deras mål är eller hur deras personuppgifter används för att påverka deras beteende. Facebooks forskning visade att enkla “gilla”-markeringar kunde användas för att med anmärkningsvärd precision förutsäga användares sexuella läggning, etnicitet, religiösa åsikter, politiska övertygelser, personlighet och till och med intelligensnivå. Om så detaljerad personlig insikt kan utvinnas från något så enkelt som en gilla-knapp, föreställ dig de detaljerade beteendeprofiler som byggs upp av sökord, webbhistorik, köpmönster och sociala interaktioner. “Rätten till förklaring” som ingår i EU:s dataskyddsförordning var tänkt att ge transparens, men dess praktiska tillämpning har varit mycket begränsad, då många organisationer ger så tekniska eller vaga förklaringar att de inte ger användarna någon verklig insikt. Utmaningen är att AI-system ofta beskrivs som “svarta lådor” där till och med deras skapare har svårt att fullt ut förstå hur de fattar specifika beslut. Men denna ogenomskinlighet är inte oundviklig—det är ofta ett val av organisationer som prioriterar snabbhet och vinst framför transparens. En mer effektiv strategi vore att införa tvålagers transparens: ett enkelt, korrekt första lager som användarna lätt kan förstå, och ett detaljerat tekniskt lager tillgängligt för tillsynsmyndigheter och konsumentskyddsmyndigheter för utredning och tillsyn.
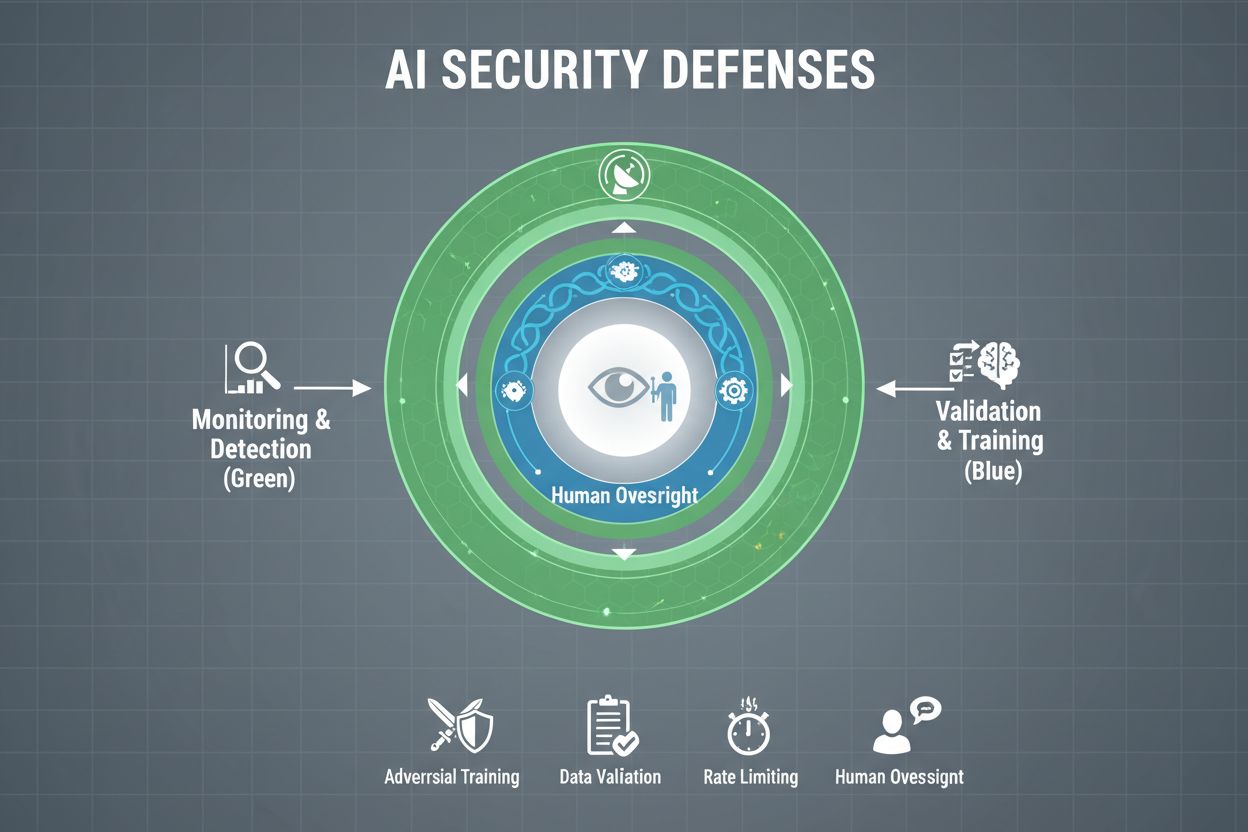
Organisationer som på allvar vill skydda sina AI-system från spel måste införa flera lager av försvar, med insikten att ingen enskild lösning ger fullständigt skydd. Adversariell träning innebär att AI-modeller avsiktligt utsätts för konstruerade adversariella exempel under utvecklingen, så att de lär sig känna igen och avvisa manipulerande indata. Datavalideringskedjor använder automatiserade system för att upptäcka och eliminera skadlig eller förvrängd data innan den når modellen, med anomalidetekteringsalgoritmer som identifierar misstänkta mönster som kan tyda på förgiftningsförsök. Output-förvanskning minskar mängden information som finns tillgänglig via modellförfrågningar—till exempel genom att bara returnera klassetiketter istället för sannolikhetspoäng—vilket gör det svårare för angripare att bakåtutveckla modellen eller extrahera känslig information. Förfrågningsbegränsning begränsar antalet förfrågningar en användare kan göra, vilket försvårar för angripare som försöker med modelextaktion eller medlemskapsinferens. Anomalidetekteringssystem övervakar modellbeteende i realtid och flaggar ovanliga mönster som kan tyda på adversariell manipulation eller systemkompromettering. Red teaming-övningar innebär att externa säkerhetsexperter anlitas för att aktivt försöka spela systemet och identifiera sårbarheter innan illasinnade aktörer gör det. Kontinuerlig övervakning säkerställer att systemen övervakas efter misstänkt aktivitet, ovanliga förfrågningssekvenser eller output som avviker från förväntat beteende.
Den mest effektiva försvarsstrategin kombinerar dessa tekniska åtgärder med organisatoriska rutiner. Differentiell integritetsteknik tillför noggrant kalibrerat brus till modelloutputen, vilket skyddar individuella datapunkter samtidigt som den övergripande modellnyttan bibehålls. Mänskliga tillsynsmekanismer säkerställer att kritiska beslut som fattas av AI-system granskas av kvalificerad personal som kan identifiera när något verkar fel. Dessa försvar fungerar bäst när de implementeras som en del av en omfattande strategi för AI Security Posture Management som katalogiserar alla AI-tillgångar, kontinuerligt övervakar dem för sårbarheter och upprätthåller detaljerade loggar över systembeteende och åtkomstmönster.
Regeringar och tillsynsmyndigheter världen över börjar ta itu med AI-spel, även om nuvarande ramverk har betydande luckor. Europeiska unionens AI Act har ett riskbaserat förhållningssätt, men fokuserar främst på att förbjuda manipulation som orsakar fysisk eller psykologisk skada—medan ekonomiska skador till stor del lämnas obehandlade. I praktiken orsakar de flesta AI-manipulationer ekonomisk skada genom minskat användarvärde, inte psykologisk skada, vilket innebär att många manipulerande metoder faller utanför lagens förbud. EU:s Digital Services Act ger en uppförandekod för digitala plattformar och innehåller särskilda skydd för minderåriga, men dess huvudsakliga fokus är på olagligt innehåll och desinformation snarare än AI-manipulation i stort. Detta skapar en regleringslucka där många digitala företag utanför plattformssektorn kan ägna sig åt manipulerande AI-metoder utan tydliga juridiska begränsningar. Effektiv reglering kräver ansvarighetsramverk som håller organisationer ansvariga för AI-spelincidenter, med konsumentskyddsmyndigheter som har befogenhet att utreda och upprätthålla regler. Dessa myndigheter behöver förbättrade datorresurser för att kunna experimentera med de AI-system de utreder, så att de kan bedöma överträdelser på rätt sätt. Internationell samordning är avgörande, eftersom AI-system verkar globalt och konkurrenspress kan driva på regleringsarbitrage där företag flyttar verksamhet till jurisdiktioner med svagare skydd. Informationsinsatser och utbildningsprogram, särskilt riktade till unga, kan hjälpa individer att känna igen och stå emot AI-manipulationstaktiker.
I takt med att AI-system blir mer sofistikerade och deras användning mer utbredd behöver organisationer fullständig insyn i hur deras AI-system används och om de spelas eller manipuleras. AI-övervakningsplattformar som AmICited.com tillhandahåller kritisk infrastruktur för att spåra hur AI-system refererar till och använder information, upptäcka när AI-output avviker från förväntade mönster och identifiera potentiella manipulationer i realtid. Dessa verktyg erbjuder realtidsinsyn i AI-systemets beteende, vilket gör det möjligt för säkerhetsteam att upptäcka avvikelser som kan indikera adversariella attacker eller systemkompromettering. Genom att övervaka hur AI-system refereras till och används över olika plattformar—från GPTs till Perplexity till Google AI Overviews—får organisationer insikter om möjliga spelförsök och kan snabbt agera på hot. Omfattande övervakning hjälper organisationer att förstå hela sin AI-exponering och identifiera “shadow AI”-system som kan ha distribuerats utan rätt säkerhetskontroller. Integrering med bredare säkerhetsramverk säkerställer att AI-övervakning är en del av en samordnad försvarsstrategi snarare än en isolerad funktion. För organisationer som är allvarliga med att skydda sina AI-investeringar och bevara användarförtroende är övervakningsverktyg inte valfria—de är nödvändig infrastruktur för att upptäcka och förhindra AI-spel innan det orsakar betydande skada.
Tekniska försvar ensam kan inte förhindra AI-spel; organisationer måste odla en säkerhetsfokuserad kultur där alla från ledning till ingenjörer prioriterar säkerhet och etik framför snabbhet och vinst. Detta kräver att ledningen är beredd att avsätta betydande resurser till säkerhetsforskning och säkerhetstestning, även när det fördröjer produktutvecklingen. Schweizerostmodellen för organisatorisk säkerhet—där flera ofullkomliga försvarslager kompenserar för varandras svagheter—är direkt tillämplig på AI-system. Ingen enskild försvarsmekanism är perfekt, men flera överlappande försvar skapar motståndskraft. Mänskliga tillsynsmekanismer måste byggas in genom hela AI-livscykeln, från utveckling till implementering, med kvalificerad personal som granskar kritiska beslut och flaggar misstänkta mönster. Transparenskrav bör byggas in i systemdesignen från början, inte adderas i efterhand, så att intressenter förstår hur AI-system fungerar och vilken data de använder. Ansvarsstrukturer måste tydligt tilldela ansvar för AI-systemets beteende, med konsekvenser för vårdslöshet eller misskötsel. Red teaming-övningar bör genomföras regelbundet av externa experter som aktivt försöker spela systemen, och resultaten användas för kontinuerlig förbättring. Organisationer bör införa stegvisa lanseringsprocesser där nya AI-system testas utförligt i kontrollerade miljöer innan bredare utrullning, med säkerhetsverifiering i varje steg. Att bygga denna kultur kräver insikten att säkerhet och innovation inte står i motsats—organisationer som investerar i robust AI-säkerhet kan faktiskt innovera mer effektivt eftersom de kan lansera system med tillförsikt och behålla användarförtroende över tid.
Att spela ett AI-system innebär att avsiktligt manipulera eller utnyttja AI-modeller för att generera oavsiktliga resultat, kringgå säkerhetsåtgärder eller extrahera känslig information. Detta inkluderar tekniker som promptinjektion, adversariella attacker, datamissbruk och modelextaktion. Till skillnad från normala systemfel är spelande ett medvetet försök att kringgå AI-systemets avsedda beteende.
Adversariella attacker blir allt vanligare i takt med att AI-system används mer inom kritiska tillämpningar. Forskning visar att de flesta AI-system har sårbarheter som kan utnyttjas. Tillgången till attackverktyg och tekniker innebär att både avancerade angripare och vanliga användare potentiellt kan spela AI-system, vilket gör detta till en utbredd oro.
Ingen enskild försvarsmekanism ger fullständig immunitet mot spel. Organisationer kan dock avsevärt minska risken genom flerskiktade försvar, inklusive adversariell träning, datavalidering, output-förvanskning, begränsning av förfrågningar och kontinuerlig övervakning. Den mest effektiva strategin kombinerar tekniska åtgärder med organisatoriska rutiner och mänsklig tillsyn.
Vanliga AI-fel uppstår när system gör misstag på grund av begränsningar i träningsdata eller modellarkitektur. Spel innebär avsiktlig manipulation för att utnyttja sårbarheter. Spel är avsiktligt, ofta osynligt för användare och utformat för att gynna angriparen på systemets eller användarens bekostnad. Vanliga fel är oavsiktliga systemfel.
Konsumenter kan skydda sig genom att förstå hur AI-system fungerar, inse att deras data används för att påverka deras beteende och vara skeptiska till rekommendationer som verkar för perfekta. Att stödja krav på transparens, använda integritetsskyddande verktyg och verka för starkare AI-regler bidrar också. Utbildning om AI-manipulationstaktiker blir allt viktigare.
Reglering är avgörande för att förhindra AI-spel i stor skala. Nuvarande ramverk som EU:s AI Act fokuserar främst på fysiska och psykologiska skador, medan ekonomiska skador till stor del förblir obehandlade. Effektiv reglering kräver ansvarighetsramar, förbättrad konsumentskyddsmyndighet, internationell samordning och tydliga regler som förhindrar manipulerande AI-praktiker samtidigt som innovationsincitament bibehålls.
AI-övervakningsplattformar ger realtidsinsyn i hur AI-system beter sig och används. De upptäcker avvikelser som kan indikera adversariella attacker, spårar ovanliga förfrågningsmönster som tyder på modelextaktion och identifierar när systemets output avviker från förväntat beteende. Denna insyn möjliggör snabb respons på hot innan betydande skada uppstår.
Kostnaderna inkluderar direkta ekonomiska förluster vid bedrägerier och manipulation, varumärkesskador från säkerhetsincidenter, juridiskt ansvar och regulatoriska böter, operativa störningar vid systemavstängningar samt långsiktig urholkning av användarförtroende. För konsumenter innebär det minskat värde av tjänster, integritetskränkningar och utnyttjande av beteendemässiga sårbarheter. Den totala ekonomiska påverkan är betydande och växande.
AmICited övervakar hur AI-system refereras och används över plattformar och hjälper dig upptäcka försök till spel och manipulation i realtid. Få insyn i ditt AI-beteende och håll dig steget före hoten.
Lär dig hur underhållningsvarumärken optimerar sin synlighet i AI-rekommendationer över streamingplattformar. Upptäck strategier för att övervaka AI-närvaro och...

Lär dig bygga en AI-synlighetsplaybook som håller ditt team samordnat kring strategi, styrning och AI-citeringsspårning över plattformar som ChatGPT, Perplexity...

Komplett guide för att avanmäla dig från AI-träning och datainsamling på ChatGPT, Perplexity, LinkedIn och andra plattformar. Lär dig steg-för-steg hur du skydd...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.