
Målinriktning på LLM-källsidor för bakåtlänkar
Lär dig identifiera och rikta in dig på LLM-källsidor för strategiska bakåtlänkar. Upptäck vilka AI-plattformar som citerar källor mest och optimera din länkstr...
9 min läsning

Upptäck hur stora språkmodeller väljer och citerar källor genom bevisviktning, entitetsigenkänning och strukturerad data. Lär dig den sju-fasiga citeringsprocessen och optimera ditt innehåll för AI-synlighet.
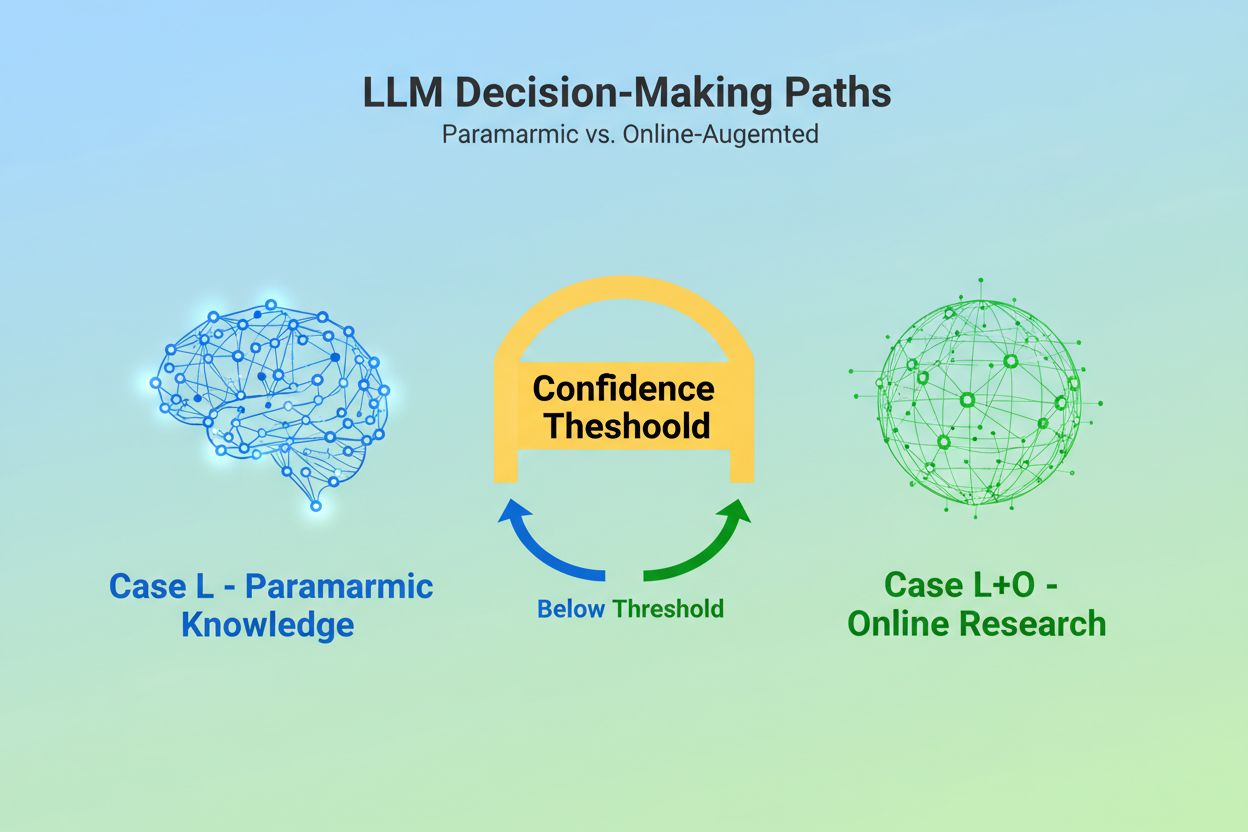
När en stor språkmodell tar emot en fråga ställs den inför ett grundläggande beslut: ska den enbart förlita sig på kunskap inbäddad under träningen, eller ska den söka på webben efter aktuell information? Detta binära val—det som forskare kallar Case L (endast träningsdata) kontra Case L+O (träningsdata plus onlineforskning)—avgör om en LLM ens kommer att citera några källor. I Case L-läge hämtar modellen uteslutande från sin parametriska kunskapsbas, en kondenserad representation av mönster inlärda under träning som vanligtvis speglar information från flera månader till över ett år innan modellens lansering. I Case L+O-läge aktiverar modellen en förtroendetröskel som utlöser extern forskning och öppnar det som forskare kallar “kandidatytan” av URL:er och källor. Denna beslutspunkt är osynlig för de flesta övervakningsverktyg, men det är här hela citeringsmekanismen börjar—för utan att sökfasen utlöses kan inga externa källor utvärderas eller citeras.
I samma ögonblick som en LLM beslutar att söka efter externa källor går den in i den mest avgörande fasen för urval av citeringar: bevisviktning. Det är här skillnaden mellan enbart en nämning och en auktoritativ rekommendation avgörs. Modellen räknar inte bara hur många gånger en källa förekommer eller hur högt den rankas i sökresultat; istället utvärderar den den strukturella integriteten hos själva beviset. Den bedömer dokumentarkitektur—om källor innehåller tydliga datarelationer, återkommande identifierare och refererade länkar—och tolkar dessa som tecken på trovärdighet. Modellen konstruerar det som forskare kallar ett “bevisgraf”, där noder representerar entiteter och kanter dokumentrelationer. Varje källa vägs inte bara på innehållsrelevans utan också på hur konsekvent fakta bekräftas i flera dokument, hur ämnesrelevant informationen är och hur auktoritativ domänen verkar vara. Denna multidimensionella utvärdering skapar det som kallas en evidensmatris, en omfattande bedömning som avgör vilka källor som är tillräckligt tillförlitliga för att citeras. Avgörande är att denna fas verkar i resonemangslagret hos LLM:en, vilket gör den osynlig för traditionella GEO-övervakningsverktyg som bara mäter hämtade signaler.
Strukturerad data—särskilt JSON-LD, Schema.org-märkning och RDFa—verkar som en multiplikator i bevisviktningen. Källor som implementerar korrekt strukturerad data får 2-3 gånger högre vikt i evidensmatrisen jämfört med ostrukturerat innehåll. Det beror inte på att LLM:er föredrar snyggt formaterad data; det är för att strukturerad data möjliggör entitetslänkning, processen att koppla nämningar mellan dokument genom maskinläsbara identifierare som @id, sameAs och Q-ID (Wikidata-identifierare). När en LLM stöter på en källa med ett Q-ID för en organisation kan den omedelbart verifiera denna entitet i flera dokument och skapa det som forskare kallar “cross-document entity coreference”. Denna verifieringsprocess ökar dramatiskt förtroendet för källans tillförlitlighet.
| Dataformat | Citeringsnoggrannhet | Entitetslänkning | Verifiering över dokument |
|---|---|---|---|
| Ostrukturerad text | 62% | Ingen | Manuell tolkning |
| Enkel HTML-märkning | 71% | Begränsad | Partiell matchning |
| RDFa/Microdata | 81% | Bra | Mönsterbaserad |
| JSON-LD med Q-ID | 94% | Utmärkt | Verifierade länkar |
| Knowledge Graph-format | 97% | Perfekt | Automatisk verifiering |
Effekten av strukturerad data verkar på två tidsaxlar. Tillfälligt, när en LLM söker online, läser den JSON-LD och Schema.org-märkning i realtid och införlivar omedelbart denna strukturerade information i bevisviktningen för det aktuella svaret. Beständigt integreras strukturerad data som är konsekvent över tid i modellens parametriska kunskapsbas under framtida träningscykler, vilket formar hur modellen känner igen och utvärderar entiteter även utan onlineforskning. Denna dubbla mekanism innebär att varumärken som implementerar korrekt strukturerad data säkrar både omedelbar citeringssynlighet och långsiktig auktoritet i modellens interna kunskapsutrymme.
Innan en LLM kan citera en källa måste den först förstå vad källan handlar om och vem den representerar. Detta är entitetsigenkänningens arbete, en process som transformerar luddigt mänskligt språk till maskinläsbara entiteter. När ett dokument nämner “Apple” måste LLM:en avgöra om det syftar på Apple Inc., frukten eller något helt annat. Modellen åstadkommer detta genom tränade entitetsmönster hämtade från Wikipedia, Wikidata och Common Crawl, kombinerat med kontextuell analys av omgivande text. I Case L+O-läge blir denna process mer sofistikerad: modellen verifierar entiteter mot extern strukturerad data, letar efter @id-attribut, sameAs-länkar och Q-ID som ger definitiv identifiering. Detta verifieringssteg är avgörande eftersom otydliga eller inkonsekventa entitetsreferenser förloras i modellens resonemangsbrus. Ett varumärke som använder inkonsekventa namnkonventioner, inte fastställer tydliga entitetsidentifierare eller inte implementerar Schema.org-märkning blir semantiskt otydligt för maskinen—och framstår som flera olika entiteter istället för en enda, sammanhållen källa. Däremot blir organisationer med stabila, konsekvent refererade entiteter över flera dokument igenkända som tillförlitliga noder i LLM:ens kunskapsgraf, vilket avsevärt ökar deras sannolikhet att bli citerade.
Vägen från fråga till citering följer en strukturerad sju-fasig process som forskare har kartlagt genom analys av LLM-beteende. Fas 0: Intenttolkning börjar när modellen tokeniserar användarinmatningen, gör semantisk analys och skapar en intent-vektor—en abstrakt representation av vad användaren faktiskt frågar efter. Denna fas avgör vilka ämnen, entiteter och relationer som ens är relevanta att överväga. Fas 1: Intern kunskapshämtning använder modellens parametriska kunskap och beräknar en förtroendepoäng. Om denna poäng överskrider en tröskel stannar modellen i Case L-läge; annars går den vidare till extern forskning. Fas 2: Fan-out-frågegeneration (endast Case L+O) skapar flera semantiskt varierade sökfrågor—vanligen 1–6 token vardera—utformade för att öppna kandidaturvalet så brett som möjligt. Fas 3: Bevisextraktion hämtar URL:er och utdrag från sökresultat, tolkar HTML och extraherar JSON-LD, RDFa och microdata. Det är här strukturerad data först blir synlig för citeringsmekanismen. Fas 4: Entitetslänkning identifierar entiteter i de hämtade dokumenten och verifierar dem mot externa identifierare, vilket skapar en tillfällig kunskapsgraf över relationer. Fas 5: Bevisviktning utvärderar bevisens styrka från alla källor med hänsyn till dokumentarkitektur, källdiversitet, bekräftelsefrekvens och koherens mellan källor. Fas 6: Resonemang & syntes kombinerar intern och extern evidens, löser motsägelser och avgör om varje källa förtjänar en nämning eller en rekommendation. Fas 7: Slutlig svarsuppbyggnad översätter det viktade beviset till naturligt språk och integrerar citeringar där det är lämpligt. Varje fas matar in i nästa, med återkopplingsslingor som gör att modellen kan förfina sin sökning eller omvärdera bevis om inkonsekvenser dyker upp.
Moderna LLM:er använder allt oftare Retrieval-Augmented Generation (RAG), en teknik som fundamentalt förändrar hur citeringar väljs och motiveras. Istället för att enbart förlita sig på parametrisk kunskap hämtar RAG-system aktivt relevanta dokument, extraherar evidens och grundar svaren i specifika källor. Detta omvandlar citering från en implicit biprodukt av träningen till en explicit, spårbar process. RAG-implementationer använder typiskt hybridsökning, där sökningar baserade på nyckelord kombineras med vektorsökning för att maximera återhämtning. När kandidatutdrag hämtats görs en semantisk rankning av resultaten baserat på betydelse snarare än bara nyckelordsöverensstämmelse, vilket säkerställer att de mest relevanta källorna hamnar överst. Denna explicita hämtning gör citeringsprocessen mer transparent och granskbar—varje citerad källa kan spåras tillbaka till specifika passager som motiverade dess inkludering. För organisationer som vill övervaka sin AI-synlighet är RAG-baserade system särskilt viktiga eftersom de skapar mätbara citeringsmönster. Verktyg som AmICited spårar hur RAG-system refererar till ditt varumärke på olika AI-plattformar och ger insikter om du syns som citerad källa eller bara som bakgrundsmaterial i evidenshämtningen.
Alla citeringar är inte lika mycket värda. En LLM kan nämna en källa som bakgrundsinformation medan den rekommenderar en annan som auktoritativ evidens—och denna skillnad bestäms helt av bevisviktningen, inte av hämtningens framgång. En källa kan visas i kandidatytan (Fas 2-3) men misslyckas med att nå rekommendationsstatus om dess evidenspoäng är otillräcklig. Denna separation mellan nämning och rekommendation är där traditionella GEO-mått brister. Standardövervakningsverktyg mäter fan-out—om ditt innehåll dyker upp i sökresultat—men de kan inte mäta om LLM:en faktiskt anser ditt innehåll tillräckligt trovärdigt för att rekommendera. En nämning kan låta som “Vissa källor antyder…” medan en rekommendation låter som “Enligt [Källa] visar evidensen…”. Skillnaden ligger i evidensmatrispoängen från Fas 5. Källor med konsekventa Q-ID, välstrukturerad dokumentarkitektur och bekräftelse i flera oberoende källor får rekommendationsstatus. Källor med oklara entitetsreferenser, dålig strukturell koherens eller isolerade påståenden förblir nämningar. För varumärken är denna skillnad avgörande: att bli hämtad är inte detsamma som att bli citerad som auktoritativ. Vägen från hämtning till rekommendation kräver semantisk tydlighet, strukturell integritet och evidenstäthet—faktorer som traditionell SEO-optimering inte adresserar.
Att förstå hur LLM:er väljer källor har omedelbara, konkreta implikationer för innehållsstrategi. För det första, implementera Schema.org-märkning konsekvent på din webbplats, särskilt för organisationsinformation, artiklar och viktiga entiteter. Använd JSON-LD-format med korrekta @id-attribut och sameAs-länkar till Wikidata, Wikipedia eller andra auktoritativa källor. Denna strukturerade data ökar direkt din evidensvikt i Fas 5. För det andra, etablera tydliga entitetsidentifierare för din organisation, produkter och nyckelbegrepp. Använd konsekventa namnkonventioner, undvik förkortningar som skapar oklarheter och länka relaterade entiteter genom hierarkiska relationer (isPartOf, about, mentions). För det tredje, skapa maskinläsbar evidens genom att publicera strukturerad data om dina påståenden, meriter och relationer. Skriv inte bara “Vi är den ledande leverantören av X”—strukturera detta påstående med stödjande data, citeringar och verifierbara relationer. För det fjärde, upprätthåll innehållskonsekvens mellan flera plattformar och över tid. LLM:er utvärderar evidenstäthet genom att kontrollera om påståenden bekräftas av oberoende källor; isolerade påståenden på en enda plattform väger lättare. För det femte, förstå att traditionella SEO-mått inte förutsäger AI-citering. Höga sökrankningar garanterar inte LLM-rekommendationer; fokusera istället på semantisk tydlighet och strukturell integritet. För det sjätte, övervaka dina citeringsmönster med verktyg som AmICited, som spårar hur olika AI-system refererar till ditt varumärke. Detta avslöjar om du uppnår nämnings- eller rekommendationsstatus och vilka typer av innehåll som utlöser citeringar. Slutligen, inse att AI-synlighet är en långsiktig investering. Strukturerad data du implementerar idag formar både omedelbar citeringssannolikhet (tillfällig effekt) och modellens interna kunskapsbas i framtida träningscykler (beständig effekt).
I takt med att LLM:er utvecklas blir citeringsmekanismerna alltmer sofistikerade och transparenta. Framtida modeller kommer sannolikt att implementera citeringsgrafer—tydliga kartor som visar inte bara vilka källor som citerades, utan hur de påverkade specifika påståenden i svaret. Vissa avancerade system experimenterar redan med sannolikhetsbaserade förtroendepoäng kopplade till citeringar, som visar hur säker modellen är på källans relevans och tillförlitlighet. En annan framväxande trend är människan-i-loopen-verifiering, där användare kan utmana citeringar och ge återkoppling som förfinar modellens bevisviktning för framtida frågor. Integreringen av strukturerad data i träningscykler innebär att organisationer som implementerar rätt semantisk infrastruktur idag i praktiken bygger sitt långsiktiga AI-auktoritet. Till skillnad från sökmotorrankningar, som kan fluktuera vid algoritmuppdateringar, skapar den beständiga effekten av strukturerad data en mer stabil grund för AI-synlighet. Detta skifte från traditionell synlighet (att hittas) till semantisk auktoritet (att bli betrodd) innebär en grundläggande förändring av hur varumärken bör arbeta med digital kommunikation. Vinnarna i detta nya landskap blir inte de med mest innehåll eller högst sökrankningar, utan de som strukturerar sin information på sätt som maskiner konsekvent kan förstå, verifiera och rekommendera.
Case L använder endast träningsdata från modellens parametriska kunskapsbas, medan Case L+O kompletterar detta med realtidswebbforskning. Modellens tröskel för förtroende avgör vilken väg som väljs. Denna skillnad är avgörande eftersom den bestämmer om externa källor överhuvudtaget kan utvärderas och citeras.
Bevisviktning avgör denna skillnad. Källor med strukturerad data, konsekventa identifierare och bekräftelse i flera dokument lyfts till 'rekommendationer' snarare än enbart nämningar. En källa kan visas i sökresultat men misslyckas med att uppnå rekommendationsstatus om dess evidenspoäng är otillräcklig.
Strukturerad data (JSON-LD, @id, sameAs, Q-ID) får 2-3 gånger högre vikt i evidensmatriser. Denna märkning möjliggör entitetslänkning och bekräftelse över flera dokument, vilket dramatiskt höjer källans tillförlitlighetspoäng. Källor med korrekt Schema.org-implementering är avsevärt mer benägna att citeras som auktoritativa.
Entitetsigenkänning är hur LLM:er identifierar och särskiljer olika entiteter (organisationer, personer, koncept). Klar entitetsidentifiering genom konsekvent namngivning och strukturerade identifierare förhindrar förväxling och ökar sannolikheten att bli citerad. Otydliga entitetsreferenser försvinner i modellens resonemangsprocess.
RAG-system hämtar och rankar aktivt källor i realtid, vilket gör urvalet av citeringar mer transparent och evidensbaserat än ren parametrisk kunskap. Denna explicita hämtning skapar mätbara citeringsmönster som kan följas och analyseras med övervakningsverktyg som AmICited.
Ja. Implementera Schema.org-märkning konsekvent, etablera tydliga entitetsidentifierare, skapa maskinläsbar evidens, upprätthåll innehållskonsekvens mellan plattformar och övervaka dina citeringsmönster. Dessa faktorer påverkar direkt om ditt innehåll når nämnings- eller rekommendationsstatus i LLM-svar.
Traditionell synlighet mäter räckvidd och ranking i sökresultat. AI-synlighet mäter om ditt innehåll erkänns som auktoritativ evidens i LLM:s resonemangsprocesser. Att bli hämtad är inte detsamma som att bli citerad som trovärdig—det senare kräver semantisk klarhet och strukturell integritet.
AmICited spårar hur AI-system refererar till ditt varumärke i GPT:er, Perplexity och Google AI Overviews. Det visar om du uppnår nämnings- eller rekommendationsstatus, vilka typer av innehåll som utlöser citeringar, och hur dina citeringsmönster skiljer sig mellan olika AI-plattformar.
Förstå hur LLM:er refererar till ditt varumärke i ChatGPT, Perplexity och Google AI Overviews. Spåra citeringsmönster och optimera för AI-synlighet med AmICited.
Lär dig identifiera och rikta in dig på LLM-källsidor för strategiska bakåtlänkar. Upptäck vilka AI-plattformar som citerar källor mest och optimera din länkstr...

Lär dig hur egen enkätdata och unika statistik blir citeringsmagneter för LLM:er. Upptäck strategier för att öka AI-synligheten och få fler citeringar från Chat...

Lär dig beprövade strategier för källhänvisning för att göra ditt innehåll LLM-tillförlitligt. Upptäck hur du får AI-citeringar från ChatGPT, Perplexity och Goo...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.