Informationsdensitet
Lär dig vad informationsdensitet är och hur det ökar sannolikheten för AI-citering. Upptäck praktiska tekniker för att optimera innehåll för AI-system som ChatG...
14 min läsning

Lär dig hur du skapar informationsrikt innehåll som AI-system föredrar. Bemästra hypotesen om enhetlig informationsdensitet och optimera ditt innehåll för AI Overviews, LLM:er och bättre citeringar.
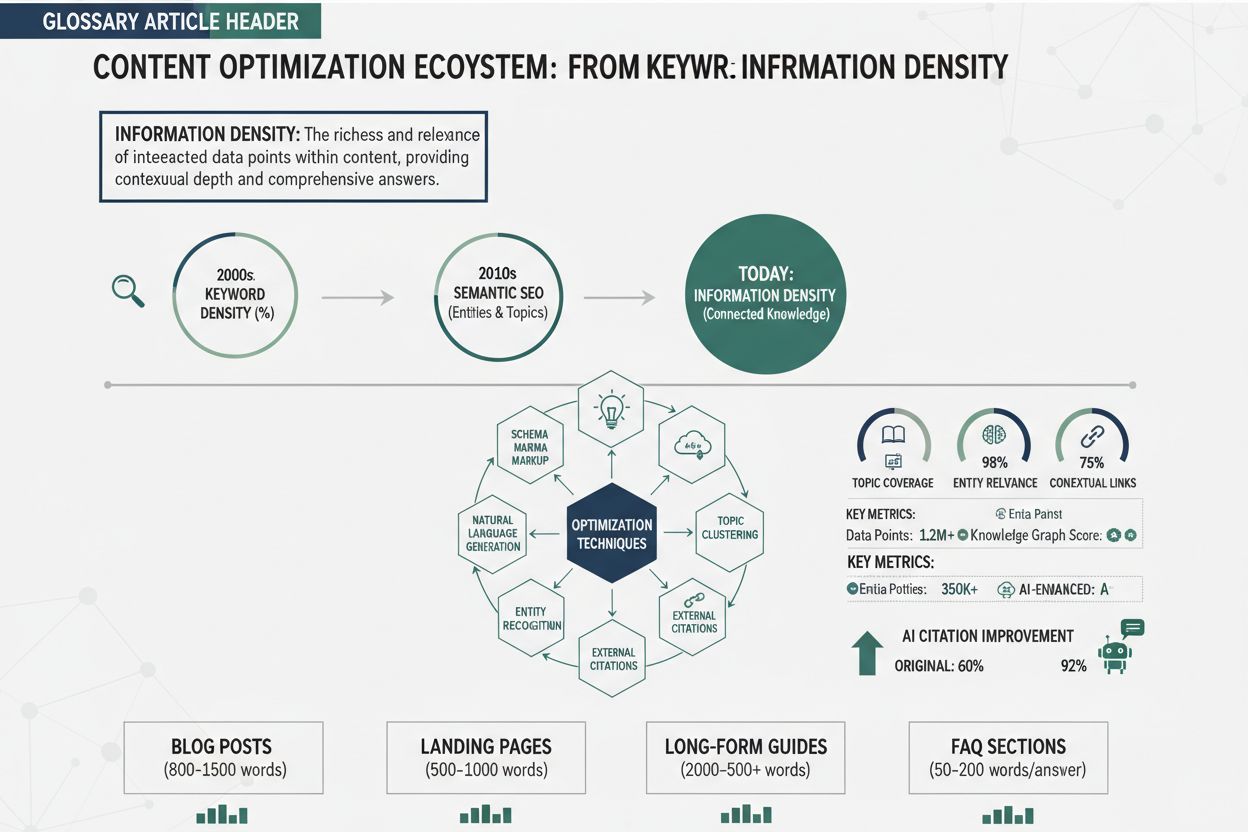
Informationsdensitet syftar på koncentrationen av meningsfulla, handlingsbara insikter i ett givet innehåll—i grunden hur mycket värde som ryms i varje ord, mening eller stycke. Detta koncept har blivit allt viktigare i AI-drivna söktider, särskilt med framväxten av stora språkmodeller (LLM:er) och AI Overviews. Hypotesen om enhetlig informationsdensitet (UID), en lingvistisk princip som stöds av ny forskning på ArXiv, antyder att både människor och AI-system bearbetar information mer effektivt när den kognitiva belastningen är jämnt fördelad genom innehållet snarare än koncentrerad i vissa delar. För AI-system som utvärderar innehåll påverkar informationsdensiteten direkt hur sannolikt det är att ditt innehåll väljs ut, citeras och rankas i AI-sökresultat. När du skapar värdefyllt innehåll skriver du inte bara för mänskliga läsare—du optimerar för hur LLM:er extraherar, syntetiserar och refererar till information från ditt arbete.
LLM:er utvärderar innehållsdensitet genom flera sofistikerade mekanismer som går långt bortom enkla ordantal eller nyckelordsfrekvens. Dessa system analyserar innehållsmått med hjälp av entropibaserade beräkningar som mäter hur mycket information som förmedlas i förhållande till den totala textlängden, och undersöker vad forskare kallar “stegnivåuniformitet”—hur jämnt informationen är fördelad över sekventiella delar av ditt innehåll. När en LLM bearbetar din artikel beräknar den informationsvinsten vid varje token och bedömer om du levererar konsekvent värde eller om vissa delar är redundanta, irrelevanta eller lågvärdiga. Olika utvärderingsramverk prioriterar olika aspekter av innehållskvalitet, vilket illustreras i jämförelsen nedan:
| Mått | Vad det mäter | AI-relevans | Bäst för |
|---|---|---|---|
| BLEU Score | Precision i ordmatchning | Lägre relevans för densitet | Utvärdering av maskinöversättning |
| ROUGE Score | Återkallelse av innehållsöverlap | Måttlig relevans | Kvalitet på sammanfattning |
| Perplexity | Förutsägbarhet i textsekvenser | Hög relevans | LLM:s självförtroendevärdering |
| Informationsdensitet | Meningsfullt innehåll per längdenhet | Högsta relevans | AI-citering och urval |
Att förstå dessa LLM-utvärderingsramverk hjälper dig att inse att AI-system inte bara letar efter heltäckande innehåll—de letar efter innehåll som bibehåller konsekvent informationsvärde genomgående, och undviker den vanliga fallgropen med utfyllnad eller överflödigt material som urvattnar budskapet.
Skillnaden mellan tätt innehåll och glest innehåll formar i grunden hur AI-system interagerar med ditt material. Tätt innehåll ger högt informationsvärde med minimalt fluff, medan glest innehåll innehåller betydande mängder repetition, utfyllnad eller lågkvalitativa utläggningar. Tänk på dessa nyckelskillnader:
Ett praktiskt exempel: en gles artikel om AI-innehållsoptimering kan ägna tre stycken åt att förklara vad AI är, sedan tre till varför innehåll är viktigt, innan optimeringsteknikerna slutligen tas upp. En tät innehålls-version skulle utgå från baskunskap, integrera kontext naturligt och ägna proportionerligt utrymme åt handfasta strategier. AI-system uppmärksammar och belönar denna effektivitet eftersom det visar att författaren har tillräckligt djup ämneskunskap för att kommunicera kortfattat.
Informationsdensitet har blivit en avgörande rankingsignal i AI-drivna sökmiljöer och påverkar direkt om ditt innehåll syns i AI Overviews och hur ofta det får citeringar från AI-system. Forskning från BrightEdge:s analys av AI-algoritmer visar att innehåll som väljs ut för AI Overviews uppvisar cirka 40 % högre informationsdensitet jämfört med innehåll som inte blir utvalt, vilket antyder att AI-system aktivt prioriterar täta, värdefulla texter när de syntetiserar svar. Sambandet mellan informationsdensitet och citeringsfrekvens är särskilt viktigt ur AmICited.com:s perspektiv: när AI-system som Perplexity eller Googles AI Overviews behöver referenser, citerar de i första hand innehåll som levererar koncentrerat värde, eftersom detta minskar behovet av flera källor för att ge ett heltäckande svar på en fråga. Innehåll med hög informationsdensitet tenderar också att rankas bättre eftersom det tillgodoser användarens intention mer fullständigt—AI-system känner igen att tätt innehåll ger mer genomarbetade svar och minskar sannolikheten att användaren behöver söka ytterligare källor. Vidare utvärderar algoritmer för AI Overviews specifikt om innehållet kan summeras och syntetiseras effektivt, och tätt innehåll är i grunden mer sammanfattningsbart eftersom det innehåller färre överflödiga delar att filtrera bort vid syntesen.
Att skapa värdefyllt innehåll kräver medvetna strukturella och redaktionella val som prioriterar informationsleverans framför ordantal. Börja med en kompromisslös granskning av ditt befintliga innehåll: identifiera varje mening som inte för ditt huvudargument framåt eller tillför handlingsvärde, och eliminera den eller integrera den i omgivande meningar som tjänar flera syften. Använd strukturerade innehållsformat—numrerade listor, jämförelsetabeller, hierarkiska rubriker och definitionsavsnitt—som gör att både läsare och AI-system snabbt kan extrahera nyckelinformation utan att behöva tolka långa narrativ. Tillämpa principen “en idé per stycke” och säkerställ att varje avsnitt har ett tydligt syfte och inte urvattnar budskapet med sidospår; detta stödjer UID-hypotesen genom att fördela kognitiv belastning jämnt. När du förklarar komplexa begrepp, använd progressiv fördjupning: introducera den viktigaste informationen först och bygg sedan på med detaljer, exempel och nyanser—detta tillvägagångssätt gynnar både mänskliga läsare och LLM:er som kan extrahera innehåll på olika detaljnivåer. Infoga specifika datapunkter, statistik och konkreta exempel snarare än abstrakta generaliseringar; “cirka 40 % högre informationsdensitet” är mer värdefullt för AI-system än “avsevärt högre densitet”. Slutligen, optimera din innehållsoptimering genom att behandla informationsdensitet som en huvudfaktor vid sidan om traditionella SEO-mått—granska utkast och ställ dig frågan om varje avsnitt kan kondenseras, kombineras eller tas bort utan att förlora väsentligt värde.
Att mäta informationsdensitet kräver förståelse för både teoretiska ramverk och praktiska verktyg som finns tillgängliga för innehållsskapare. Det mest direkta tillvägagångssättet är att beräkna informationsdensitetspoäng med hjälp av entropibaserade mått: dividera innehållets totala informationsinnehåll (mätt i bit eller med semantisk analys) med det totala ordantalet för att bestämma hur mycket meningsfull information du levererar per textenhet. Flera verktyg kan hjälpa till med denna bedömning: plattformar för naturlig språkbehandling kan analysera semantisk mångfald och konceptfördelning, läsbarhetsverktyg kan identifiera mönster av upprepning och egna skript med Python-bibliotek som NLTK kan beräkna entropimått för ditt innehåll. Ett praktiskt exempel: om en artikel på 2 000 ord innehåller cirka 150 distinkta semantiska begrepp med jämn fördelning, har den högre informationsdensitet än en artikel på 2 000 ord med endast 80 distinkta begrepp koncentrerade till första halvan. Du kan också använda proxy-mått som förhållandet mellan unika termer och totalord, genomsnittlig informationsvinst per stycke eller antal handlingsbara slutsatser per 500 ord—dessa är inte perfekta mått men ger användbara indikatorer. BrightEdge:s forskning föreslår att du övervakar hur ofta ditt innehåll citeras av AI-system som en konkret validering av informationsdensiteten; om ditt innehåll konsekvent syns i AI Overviews och får citeringar träffar du troligen rätt täthetsnivå.
Det mest förekommande felet vid strävan efter informationsdensitet är överoptimering, där skapare försöker maximera densiteten så aggressivt att innehållet blir svårläst eller förlorar nödvändig kontext och förklaring. Detta visar sig ofta som nyckelordsstoppning förklädd till densitetsoptimering—att trycka in många måltermer i meningar där de inte hör hemma, vilket faktiskt minskar informationsvärdet och leder till AI-straff. Ett annat viktigt misstag är att skapa informationsöverflöd genom att försöka täcka för många ämnen i ett och samma verk; detta bryter mot UID-hypotesen genom att koncentrera för hög kognitiv belastning i vissa delar medan andra blir glesa. Dålig strukturell organisation är ytterligare en vanlig fallgrop: även informationsrikt innehåll tappar effekt om det inte är organiserat hierarkiskt med tydliga samband, vilket tvingar både läsare och AI att arbeta hårdare för att utvinna värde. Vissa skapare förväxlar också densitet med korthet och producerar innehåll som visserligen är kort men saknar tillräckligt djup för att tillfredsställa användarens intention eller ge AI nödvändigt sammanhang för korrekt syntes och citering. Slutligen, att inte bibehålla jämn informationsfördelning genom hela innehållet skapar ojämn kognitiv belastning—till exempel att ladda alla statistik och data i inledningen och sedan bara erbjuda narrativ förklaring, bryter mot UID-principen och minskar den totala effekten hos AI-system.
Principerna för informationsdensitet gäller alla innehållsformat, men optimal densitetsnivå och genomförandestrategi varierar avsevärt beroende på innehållstyp. Blogginlägg gynnas oftast av måttlig till hög informationsdensitet med strategisk användning av exempel och förklaringar som gör täta begrepp tillgängliga; ett tekniskt blogginlägg kan hålla 70–80 % informationsdensitet medan ett inlägg för nybörjare kanske ligger på 50–60 % för att säkerställa förståelse. Teknisk dokumentation kräver högsta möjliga informationsdensitet då läsare förväntar sig koncentrerat värde och minimalt fluff—dokumentation som når 85 % eller högre informationsdensitet presterar oftast bättre i AI-system eftersom den är mer sammanfattningsbar och citerbar. Produktsidor kräver en annan balans där informationsdensitet och övertygande inslag samt användarupplevelse vägs mot varandra; du vill få in värde i funktionsbeskrivningar och fördelar, men alltför hög densitet kan överväldiga potentiella kunder och minska konverteringsgraden. Nyhetsartiklar och journalistiskt innehåll har andra förutsättningar där berättande och kontext ibland kräver lägre informationsdensitet, även om AI-system fortfarande föredrar nyheter som levererar fakta effektivt utan överdriven kommentar. Forskningsartiklar och whitepapers kan hålla mycket hög informationsdensitet eftersom publiken förväntar sig tekniskt djup, även om även akademiskt innehåll gynnas av tydlig struktur och strategisk användning av sammanfattningar för att upprätthålla UID-principer. Att förstå dessa variationer gör att du kan optimera informationsdensiteten korrekt utifrån din specifika innehållstyp och samtidigt behålla effektivitet för både människor och AI-system.
När AI-system blir mer sofistikerade kommer informationsdensitet troligen att bli en ännu viktigare signal för ranking och citering, särskilt när konkurrensen om att synas i AI Overviews ökar. Forskning antyder att framtida LLM:er kommer att utveckla alltmer nyanserade metoder för att utvärdera informationskvalitet och densitet, sannolikt bortom enkla entropiberäkningar och mot mer sofistikerad semantisk analys som belönar inte bara koncentrerad information utan även optimal struktur för syntes och citering. AI-sökningens utveckling kommer förmodligen att gynna skapare som förstår att AI-utveckling inte handlar om att lura algoritmer utan om att genuint tillgodose användarens intention mer effektivt—tätt, välstrukturerat innehåll tjänar detta syfte naturligt genom att ge AI-systemen rikare material att arbeta med. Innehållsskapare bör förbereda sig för en framtid där innehållsstrategi lägger allt större vikt vid kvalitet framför kvantitet, där en artikel på 1 500 ord med exceptionell informationsdensitet överträffar en på 5 000 ord med måttlig densitet, och där förmåga att kommunicera komplexa idéer koncist blir en konkurrensfördel. Organisationer som övervakar sin närvaro i AI Overviews och följer citeringsfrekvens via plattformar som AmICited.com får ett tydligt försprång eftersom de kan se direkt hur förändringar i informationsdensitet påverkar deras synlighet i AI-drivna sökresultat. De skapare och organisationer som redan nu satsar på att förstå och optimera för informationsdensitet kommer att stå bäst rustade när AI-sök blir det dominerande sättet att upptäcka innehåll online.

Informationsdensitet avser koncentrationen av meningsfulla, handlingsbara insikter i ett innehåll—hur mycket värde som ryms i varje ord eller mening. AI-system utvärderar denna mätning för att avgöra vilket innehåll som ska citeras och lyftas fram i AI Overviews. Högre informationsdensitet leder vanligtvis till bättre synlighet i AI-sökresultat.
UID-hypotesen antyder att effektiv kommunikation upprätthåller ett stabilt informationsflöde genom hela innehållet. AI-system bearbetar innehåll mer effektivt när den kognitiva belastningen är jämnt fördelad istället för koncentrerad i enstaka sektioner. Denna princip påverkar direkt hur LLM:er väljer ut och citerar ditt innehåll.
Tätt innehåll levererar högt informationsvärde med minimalt 'utfyllnad', använder exakt språk och eliminerar upprepningar. Glest innehåll innehåller mycket repetition och lågkvalitativa utläggningar. AI-system föredrar tätt innehåll eftersom det är mer effektivt att syntetisera och citera, vilket minskar behovet av flera källor.
Du kan mäta informationsdensitet genom att beräkna förhållandet mellan meningsfull information och totala ordantalet med hjälp av entropibaserade mått. Praktiska metoder inkluderar att följa unika semantiska begrepp per ord, övervaka handlingsbara slutsatser per 500 ord eller se hur ofta AI-system citerar ditt innehåll i AI Overviews.
Ja, i hög grad. Forskning visar att innehåll som väljs ut för AI Overviews visar cirka 40 % högre informationsdensitet jämfört med icke-utvalt innehåll. AI-system citerar helst täta, värdefulla texter eftersom de ger heltäckande svar med färre källor.
Vanliga misstag är överoptimering som minskar läsbarheten, överanvändning av nyckelord som maskeras som densitet, informationsöverflöd genom att täcka för många ämnen, dålig struktur, att förväxla densitet med korthet och att misslyckas med att behålla en jämn informationsfördelning genom innehållet.
Krav på informationsdensitet varierar efter format: teknisk dokumentation gynnas av 85 % eller högre, blogginlägg fungerar bra på 70–80 %, produktsidor balanserar densitet och övertygelse på 50–70 %, och nyhetsartiklar kan ha lägre densitet på grund av berättande krav. Optimera densiteten utifrån din specifika innehållstyp.
När AI-system blir mer avancerade kommer informationsdensitet troligen att bli en ännu viktigare rankingsignal. Framtida LLM:er kommer sannolikt att utveckla mer nyanserade metoder för att utvärdera informationskvalitet, och gynna skapare som förstår att tätt, välstrukturerat innehåll naturligt tillgodoser användarens intentioner mer effektivt.
Följ hur AI-system som ChatGPT, Perplexity och Google AI Overviews citerar och refererar till ditt varumärke. Få insikter i realtid om din AI-synlighet och innehållsprestation.
Lär dig vad informationsdensitet är och hur det ökar sannolikheten för AI-citering. Upptäck praktiska tekniker för att optimera innehåll för AI-system som ChatG...

Lär dig vad innehållsomfattning betyder för AI-system som ChatGPT, Perplexity och Google AI Overviews. Upptäck hur du skapar kompletta, självständiga svar som A...
Förstå hur AI-modeller prioriterar innehållets färskhet. Lär dig citeringsmönster från ChatGPT, Perplexity och Google AI Overviews, branschvariationer och strat...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.