
PerplexityBot
Lär dig mer om PerplexityBot, Perplexitys webbspindel som indexerar innehåll för dess AI-svarsmotor. Förstå hur den fungerar, robots.txt-efterlevnad och hur du ...
7 min läsning

Komplett guide till PerplexityBot crawler – förstå hur den fungerar, hantera åtkomst, övervaka citeringar och optimera för synlighet i Perplexity AI. Lär dig om stealth crawling och bästa praxis.
PerplexityBot är den officiella webcrawlern utvecklad av Perplexity AI, avsedd att indexera och visa webbplatser i Perplexitys AI-drivna sökresultat. Till skillnad från vissa AI-robotar som samlar in data för att träna stora språkmodeller har PerplexityBot ett tydligt syfte: att upptäcka, genomsöka och länka till webbplatser som ger relevanta svar på användarfrågor. Crawlern använder en tydligt definierad user-agent-sträng (Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)) och publicerar sina IP-adressintervall offentligt, vilket gör det möjligt för webbplatsägare att identifiera och hantera crawlertrafik. Att förstå vad PerplexityBot gör är avgörande för webbplatsägare som vill kontrollera sitt innehålls synlighet i Perplexitys svarsmotor och samtidigt vara transparenta om hur deras webbplatser besöks.

PerplexityBot fungerar som en standardwebcrawler och skannar kontinuerligt internet för att upptäcka och indexera webbsidor. När den hittar en webbplats läser den robots.txt-filen för att förstå vilket innehåll den får komma åt, och genomsöker sedan systematiskt sidor för att extrahera och indexera deras innehåll. Denna indexerade information används i Perplexitys sökalgoritm, som använder den för att ge citerade svar på användarfrågor. Perplexity driver dock faktiskt två olika crawlers med olika syften, var och en med sin egen user-agent och beteendemönster. Att förstå skillnaden mellan dessa crawlers är avgörande för webbplatsägare som vill finjustera sina åtkomstpolicys.
| Funktion | PerplexityBot | Perplexity-User |
|---|---|---|
| Syfte | Indexerar webbplatser för sökresultat och citeringar | Hämtar specifika sidor i realtid när användaren får svar |
| User-Agent-sträng | PerplexityBot/1.0 | Perplexity-User/1.0 |
| robots.txt-följsamhet | Följer robots.txt disallow-direktiv | Ignorerar i regel robots.txt (användarinitierade förfrågningar) |
| IP-intervall | Publiceras på perplexity.com/perplexitybot.json | Publiceras på perplexity.com/perplexity-user.json |
| Frekvens | Kontinuerlig, schemalagd crawling | Vid behov, triggas av användarfrågor |
| Användningsfall | Bygger sökindex | Hämtar aktuell information för svar |
Skillnaden mellan dessa två crawlers är viktig eftersom de kan hanteras separat via robots.txt-regler och brandväggskonfigurationer. PerplexityBots regelbundna indexeringscrawl respekterar dina robots.txt-direktiv, medan Perplexity-User kan kringgå dem eftersom den hämtar innehåll som svar på en specifik användarförfrågan. Båda crawlers publicerar sina IP-adressintervall offentligt, vilket gör det möjligt för webbplatsägare att implementera precisa brandväggsregler om de vill blockera eller tillåta specifik crawlertrafik.
År 2025 publicerade Cloudflare en detaljerad undersökning som visade att Perplexity använde odeklarerade crawlers för att kringgå webbplatsrestriktioner. Enligt deras upptäckter, när Perplexitys deklarerade crawlers (PerplexityBot och Perplexity-User) blockerades via robots.txt eller brandväggsregler, använde företaget ytterligare crawlers med generiska webbläsar-user-agenter (som Chrome på macOS) och roterande IP-adresser från olika ASNs (Autonomous System Numbers) för att fortsätta komma åt begränsat innehåll. Detta beteende står i direkt kontrast till webbstandarder för crawling enligt RFC 9309, som betonar transparens och respekt för webbplatsägares preferenser. Undersökningen testade detta genom att skapa helt nya domäner med explicita robots.txt-disallow-regler, men Perplexity gav ändå detaljerad information om deras innehåll, vilket antyder användning av odeklarerade datakällor eller stealth crawling-tekniker.
Detta står i stark kontrast till hur OpenAI hanterar crawlerhantering. OpenAI:s GPTBot identifierar sig tydligt, följer robots.txt-direktiv och slutar genomsöka när den blockeras – vilket visar att transparent, etiskt crawlerbeteende är både möjligt och praktiskt. Cloudflares upptäckter väckte stor oro kring om Perplexitys uttalade åtagande att respektera webbplatsägares preferenser verkligen är äkta, särskilt för webbplatsägare som uttryckligen vill förhindra att deras innehåll indexeras eller citeras av AI-system. För webbplatsägare som är oroliga för innehållskontroll och transparens, belyser denna kontrovers vikten av att övervaka crawlerbeteende och använda flera skyddslager (robots.txt, WAF-regler och IP-blockering) för att upprätthålla sina preferenser.
Att bestämma om du ska tillåta PerplexityBot på din webbplats kräver att du väger flera viktiga faktorer. Å ena sidan ger tillåtelse till crawlern betydande fördelar: ditt innehåll kan citeras i Perplexitys svar, vilket potentiellt kan driva trafik från användare som ser din webbplats nämnas i AI-genererade svar. Å andra sidan finns legitima oro kring bandbreddsanvändning, innehållsscraping och förlust av kontroll över hur din information används. Beslutet beror i slutändan på dina affärsmål, din innehållsstrategi och din bekvämlighet med att AI-system får åtkomst till dina data.
Viktiga överväganden för att tillåta PerplexityBot:
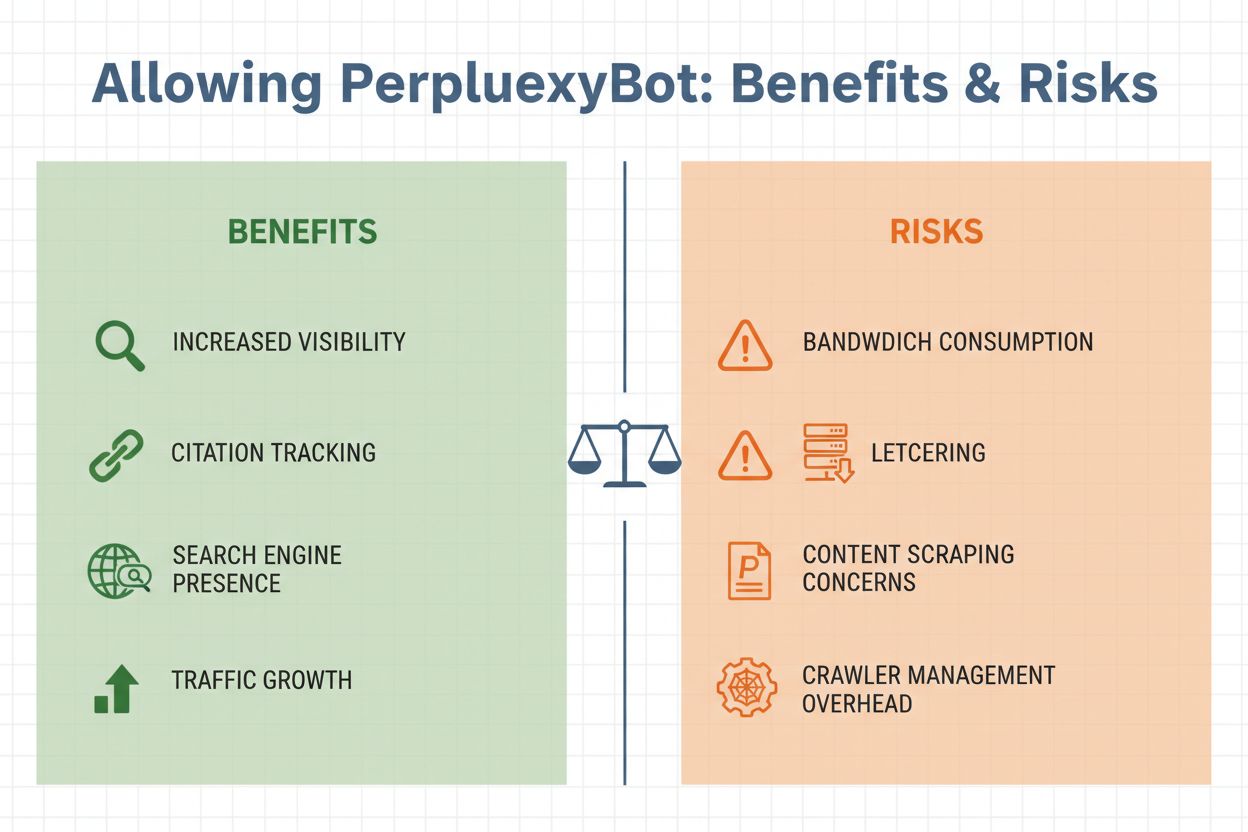
Att hantera åtkomst för PerplexityBot är enkelt och kan göras på flera sätt beroende på din tekniska infrastruktur och dina specifika krav. Det vanligaste sättet är att använda din robots.txt-fil, som ger tydliga instruktioner till alla välbetalda crawlers om vilket innehåll de får komma åt.
För att tillåta PerplexityBot i din robots.txt-fil:
User-agent: PerplexityBot
Allow: /
För att blockera PerplexityBot i din robots.txt-fil:
User-agent: PerplexityBot
Disallow: /
Om du vill blockera PerplexityBot från specifika kataloger men tillåta åtkomst till andra kan du använda mer granulära regler:
User-agent: PerplexityBot
Disallow: /admin/
Disallow: /private/
Allow: /public/
För ett mer robust skydd, särskilt om du är orolig för stealth crawling, implementera brandväggsregler på Web Application Firewall (WAF)-nivå. Cloudflare WAF-användare kan skapa egna regler för att blockera PerplexityBot genom att kombinera user-agent och IP-adressmatchning:
AWS WAF-användare bör skapa IP-uppsättningar med de publicerade PerplexityBot IP-intervallen från https://www.perplexity.com/perplexitybot.json, och sedan skapa regler som matchar både IP-uppsättningen och PerplexityBots user-agent-sträng. Använd alltid de officiella IP-intervallen som publiceras av Perplexity, eftersom de uppdateras regelbundet och är den auktoritativa källan för legitim crawlertrafik.
När du har bestämt din policy för PerplexityBot hjälper övervakning av faktisk crawleraktivitet dig att verifiera att dina regler fungerar korrekt och förstå effekten på din infrastruktur. Du kan identifiera PerplexityBot-förfrågningar i dina serverloggar genom att leta efter den utmärkande user-agent-strängen: PerplexityBot/1.0 eller den generiska webbläsar-user-agenten om stealth crawling förekommer. De flesta webbanalysplattformar och verktyg för serverlogganalys gör det möjligt att filtrera trafik efter user-agent, vilket gör det enkelt att isolera PerplexityBot-förfrågningar och analysera deras mönster.
Viktiga mätvärden att övervaka är frekvensen av crawlerbesök, vilka sidor som besöks och den bandbredd som används. Om du märker ovanliga mönster – såsom snabb crawling av känsliga sidor eller förfrågningar från IP-adresser som inte finns i Perplexitys publicerade intervall – kan det tyda på stealth crawling. Utöver grundläggande trafikövervakning ger specialiserade verktyg som AmICited.com djupare insikter i hur ditt innehåll faktiskt citeras över AI-plattformar inklusive Perplexity. AmICited spårar omnämnanden av ditt varumärke och innehåll i AI-genererade svar, vilket gör det möjligt att mäta den verkliga effekten av att tillåta PerplexityBot och förstå vilka av dina sidor som är mest värdefulla för AI-system. Dessa data hjälper dig att fatta informerade beslut om framtida crawlerhanteringspolicyer och strategier för innehållsoptimering.
Effektiv hantering av PerplexityBot kräver en balanserad strategi som skyddar dina intressen samtidigt som du erkänner värdet av AI-drivna möjligheter till synlighet. För det första, fastställ en tydlig policy baserad på dina affärsmål: avgör om den potentiella trafiken och varumärkesexponeringen från Perplexity-citeringar väger tyngre än din oro för bandbredd och innehållskontroll. Dokumentera detta beslut i din robots.txt-fil och kommunicera det till ditt team så att alla förstår din strategi för crawlerhantering.
För det andra, implementera lager av skydd om du väljer att blockera PerplexityBot. Lita inte enbart på robots.txt, eftersom kontroversen kring stealth crawling visar att vissa crawlers kan ignorera dessa direktiv. Kombinera robots.txt-regler med WAF-regler och IP-blockering för ett djupgående försvar. För det tredje, håll dig informerad om crawlerbeteenden genom att regelbundet övervaka dina loggar och följa branschdiskussioner om AI-crawleretik och transparens. Landskapet utvecklas snabbt och nya crawlers eller taktiker kan dyka upp som kräver policyanpassningar.
Slutligen, använd övervakningsverktyg strategiskt för att mäta den faktiska effekten av dina beslut. Verktyg som AmICited.com ger synlighet i hur AI-system citerar ditt innehåll, vilket hjälper dig att förstå om tillåtelse av PerplexityBot ger de synlighetsfördelar du förväntade dig. Om du tillåter crawlern hjälper dessa data dig att optimera ditt innehåll för AI-citering. Om du blockerar den bekräftar övervakningen att dina blockeringar är effektiva och att ditt innehåll inte visas i Perplexity-resultat på andra sätt.
PerplexityBot verkar i en konkurrensutsatt miljö av AI-crawlers där varje aktör har olika syften och transparensnivåer. GPTBot, som drivs av OpenAI, är allmänt erkänd som en förebild för transparent crawlerbeteende – den identifierar sig tydligt, följer robots.txt-direktiv och slutar genomsöka när den blockeras. Googles crawlers för AI Overviews och andra AI-funktioner upprätthåller på liknande sätt transparens och respekterar webbplatsägares preferenser. Till skillnad från detta representerar Perplexitys stealth crawling-beteende, såsom dokumenterat av Cloudflare, en oroande avvikelse från dessa standarder.
Den avgörande skillnaden ligger i transparens och respekt för webbplatsägares preferenser. Välbetalda crawlers som GPTBot gör det enkelt för webbplatsägare att förstå vad de gör och erbjuder tydliga kontrollmekanismer. Perplexitys användning av odeklarerade crawlers och IP-rotation för att kringgå begränsningar underminerar detta förtroende. För webbplatsägare innebär detta att du bör vara mer försiktig med Perplexitys uttalade policyer och implementera starkare tekniska kontroller om du vill säkerställa att dina preferenser faktiskt respekteras. När AI-crawler-ekosystemet mognar, förvänta dig ökande press på företag som Perplexity att anta mer transparenta, etiska metoder som är i linje med etablerade webbstandarder och respekterar webbplatsägares självbestämmande.
PerplexityBot är Perplexity AI:s officiella webcrawler som är utformad för att indexera webbplatser och visa dem i Perplexitys AI-drivna sökresultat. Till skillnad från vissa AI-robotar som samlar in data för träning, upptäcker och länkar PerplexityBot specifikt till webbplatser som ger relevanta svar på användarfrågor. Den arbetar transparent med en publicerad user-agent-sträng och IP-adressintervall.
Nej. Enligt Perplexitys officiella dokumentation är PerplexityBot utformad för att visa och länka webbplatser i sökresultat på Perplexity. Den används inte för att genomsöka innehåll till AI-modeller eller för träningsändamål. Crawlerns enda funktion är att indexera innehåll för inkludering i Perplexitys svarsmotor.
Du kan blockera PerplexityBot med din robots.txt-fil genom att lägga till 'User-agent: PerplexityBot' följt av 'Disallow: /' för att förhindra all åtkomst. För starkare skydd, implementera WAF-regler på Cloudflare eller AWS WAF som blockerar förfrågningar som matchar PerplexityBots user-agent och IP-intervall. Tänk dock på att stealth crawling kan kringgå dessa kontroller.
Perplexity publicerar officiella IP-adressintervall för PerplexityBot på https://www.perplexity.com/perplexitybot.json och för Perplexity-User på https://www.perplexity.com/perplexity-user.json. Dessa intervall uppdateras regelbundet och bör vara den auktoritativa källan för dina brandväggs- och WAF-konfigurationer. Använd alltid de officiella slutpunkterna istället för att lita på föråldrade IP-listor.
PerplexityBot hävdar att den respekterar robots.txt-direktiv, men Cloudflares undersökning 2025 fann bevis på stealth crawling med okända user-agenter och roterande IP-adresser för att kringgå robots.txt-begränsningar. Medan den deklarerade PerplexityBot-crawlern bör följa dina robots.txt-regler, rekommenderas ytterligare WAF-skydd om du vill säkerställa att dina preferenser verkställs.
Bandbreddsanvändningen varierar beroende på din webbplats storlek och innehållsvolym. PerplexityBot utför kontinuerlig, schemalagd crawling likt Googles crawler. Webbplatser med hög trafik kan märka märkbar bandbreddskonsumtion. Du kan övervaka faktisk användning genom att filtrera dina serverloggar efter PerplexityBot-förfrågningar och analysera datavolymerna för att avgöra om det påverkar din infrastruktur.
Ja. Du kan manuellt söka på Perplexity efter frågor relaterade till ditt innehåll för att se om din webbplats citeras i svaren. För mer omfattande övervakning, använd verktyg som AmICited.com som spårar hur ditt varumärke och innehåll visas över AI-plattformar inklusive Perplexity och ger insikter i realtid om din AI-synlighet och citeringsmönster.
PerplexityBot är den schemalagda crawlern som kontinuerligt indexerar webbplatser för Perplexitys sökindex. Perplexity-User triggas vid behov när användare ställer frågor och Perplexity behöver hämta specifika sidor för realtidsinformation. PerplexityBot följer robots.txt, medan Perplexity-User generellt ignorerar den eftersom den svarar på användarförfrågningar. Båda har separata user-agent-strängar och IP-intervall.
Spåra hur Perplexity och andra AI-plattformar citerar ditt varumärke. Få insikter i realtid om din synlighet inom AI och optimera din innehållsstrategi för maximal effekt över generativa sökmotorer.
Lär dig mer om PerplexityBot, Perplexitys webbspindel som indexerar innehåll för dess AI-svarsmotor. Förstå hur den fungerar, robots.txt-efterlevnad och hur du ...

Förstå hur AI-crawlers som GPTBot och ClaudeBot fungerar, deras skillnader från traditionella sökmotor-crawlers och hur du optimerar din webbplats för synlighet...

Lär dig vad GPTBot är, hur det fungerar och om du bör tillåta eller blockera OpenAI:s webcrawler. Förstå effekten på din varumärkesexponering i AI-sökmotorer oc...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.