Frågebaserat innehåll: Skriv för konversationsbaserade AI-frågor
Lär dig hur du optimerar frågebaserat innehåll för konversationsbaserade AI-system som ChatGPT och Perplexity. Upptäck struktur, auktoritet och övervakningsstrategier för att maximera AI-citat.
Publicerad den Jan 3, 2026.Senast ändrad den Jan 3, 2026 kl 3:24 am
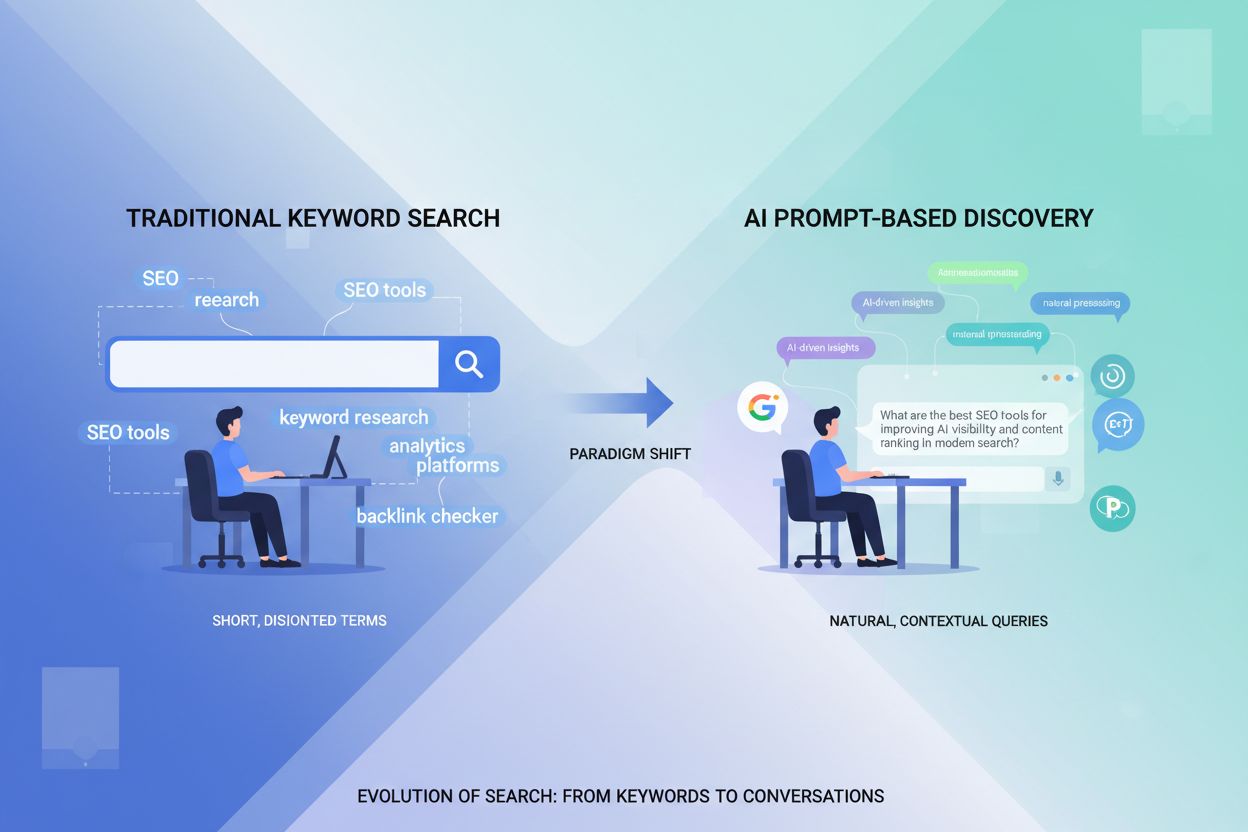
Övergången från nyckelord till konversationsfrågor
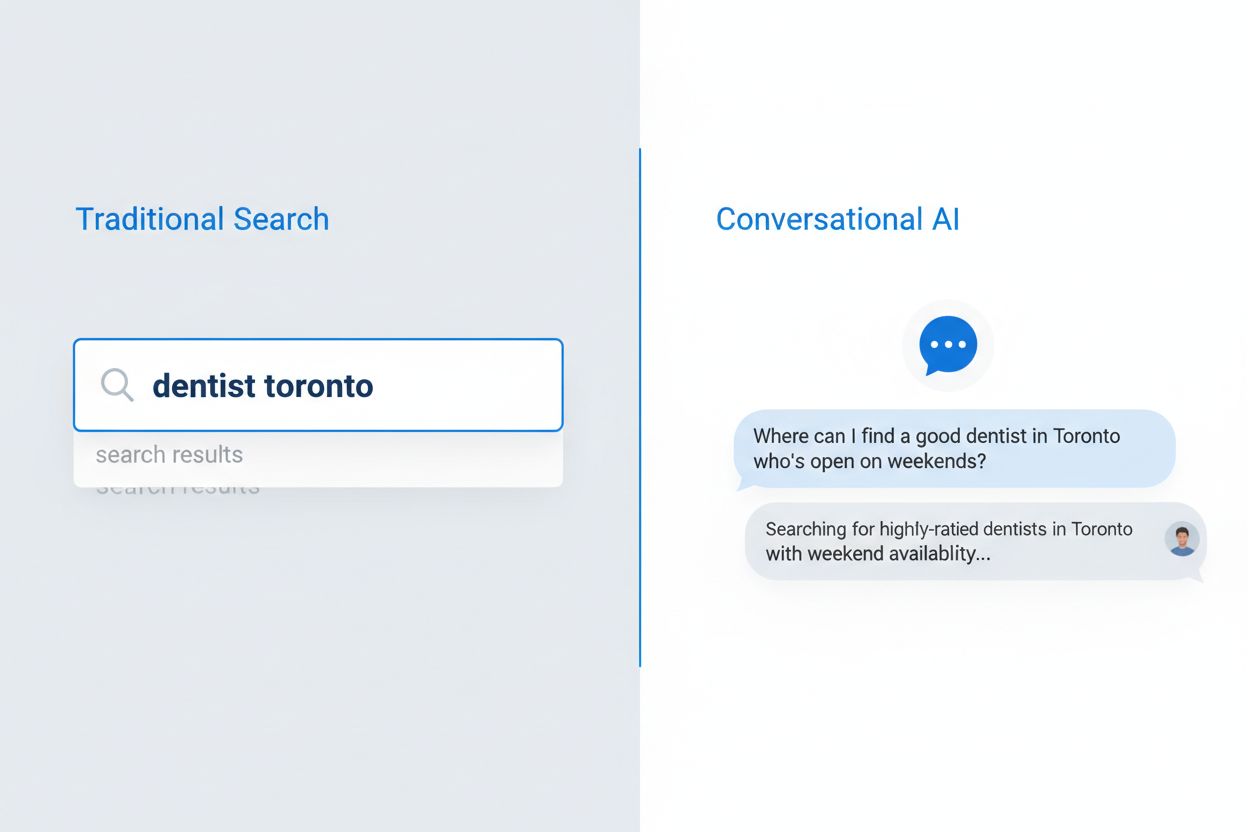
Användares sökbeteende har förändrats i grunden de senaste fem åren, från fragmenterade nyckelordsfraser till naturliga, konversationsbaserade frågor. Denna förändring har accelererat i takt med att röststyrd sökteknik blivit utbredd, mobilanvändning dominerar och stora algoritmförbättringar som Googles BERT och MUM nu prioriterar semantisk förståelse framför exakt nyckelordsmatchning. Användare söker inte längre efter isolerade termer; istället ställer de kompletta frågor som speglar hur de naturligt talar och tänker. Skillnaden är tydlig:
Konversationsfråga: “Var hittar jag en bra tandläkare i Stockholm som har öppet på helger och tar min försäkring?”
Röststyrd sökning har varit särskilt inflytelserik, med 50 % av alla sökningar nu röstbaserade, vilket tvingar sökmotorer och AI-system att anpassa sig till längre, mer naturliga språkstrukturer. Mobila enheter har blivit det primära sökgränssnittet för de flesta användare, och konversationsfrågor känns mer naturliga på mobil än att skriva nyckelord. Googles algoritmuppdateringar har tydliggjort att förståelse för användarens avsikt och kontext är viktigare än nyckelordsdensitet eller exakt frasmatchning, vilket fundamentalt förändrar hur innehåll måste skrivas och struktureras för att förbli synligt i både traditionell sökning och AI-drivna system.
Konversationsbaserad AI-sökning vs traditionell sökning
Konversationsbaserad AI-sökning representerar ett helt annat paradigm än traditionell nyckelordssökning, med tydliga skillnader i hur frågor bearbetas, resultat levereras och användaravsikt tolkas. Medan traditionella sökmotorer returnerar en lista med rankade länkar att bläddra igenom, analyserar konversationsbaserade AI-system frågorna i sitt sammanhang, hämtar relevant information från flera källor och syntetiserar omfattande svar i naturligt språk. Den tekniska arkitekturen skiljer sig markant: traditionell sökning bygger på nyckelordsmatchning och länkanalys, medan konversationsbaserad AI använder stora språkmodeller med retrieval-augmented generation (RAG) för att förstå semantisk betydelse och generera kontextuella svar. Att förstå dessa skillnader är avgörande för innehållsskapare som vill synas i båda systemen, eftersom optimeringsstrategierna skiljer sig på viktiga punkter.
Dimension
Traditionell sökning
Konversationsbaserad AI
Inmatning
Korta nyckelord eller fraser (2–4 ord i snitt)
Fullständiga konversationsfrågor (8–15 ord i snitt)
Utdata
Lista med rankade länkar att klicka på
Syntetiserat svar med källhänvisningar
Kontext
Begränsat till frågetermer och användarplats
Hela konversationshistoriken och användarpreferenser
Användaravsikt
Härleds från nyckelord och klickmönster
Förstås explicit genom naturligt språk
Användarupplevelse
Klick krävs till extern webbplats
Svaret ges direkt i gränssnittet
Den här distinktionen har djupa konsekvenser för innehållsstrategin. I traditionell sökning innebär topp 10-placering synlighet; i konversations-AI är det att väljas ut som citerad källa som är avgörande. En sida kan ranka högt på ett nyckelord men aldrig citeras av ett AI-system om den inte uppfyller kraven på auktoritet, täckning och tydlighet. Konversationsbaserade AI-system utvärderar innehåll annorlunda, och prioriterar direkta svar på frågor, tydlig informationshierarki och demonstrerad expertis framför enbart nyckelordsoptimering och bakåtlänkar.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Stora språkmodeller använder en avancerad process kallad Retrieval-Augmented Generation (RAG) för att välja vilket innehåll som ska citeras vid svar på användarfrågor, och denna process skiljer sig avsevärt från traditionell sökrankning. När en användare ställer en fråga hämtar LLM:en först relevanta dokument från sitt träningsdata eller indexerade källor, och utvärderar dem därefter enligt flera kriterier innan den beslutar vilka källor som ska citeras i sitt svar. Urvalsprocessen prioriterar flera nyckelfaktorer som innehållsskapare måste förstå:
Auktoritetssignaler – LLM:er känner igen domänauktoritet genom bakåtlänksprofiler, domänens ålder och historisk prestation i traditionella sökresultat, vilket ger fördel till etablerade, betrodda källor framför nya eller mindre citerade domäner.
Semantisk relevans – Innehållet måste direkt besvara användarens fråga med hög semantisk likhet, inte bara nyckelordsmatchning; LLM:er förstår betydelse och kontext på sätt som traditionell nyckelordsmatchning inte kan.
Innehållsstruktur och tydlighet – Välorganiserat innehåll med tydliga rubriker, direkta svar och logisk struktur väljs oftare, då LLM:er enklare kan extrahera relevant information ur strukturerat innehåll.
Aktualitet och färskhet – Nyligen uppdaterat innehåll väger tyngre, särskilt inom områden där aktuell information är viktig; föråldrat material prioriteras ner även om det tidigare varit auktoritativt.
Täckt bredd – Innehåll som grundligt behandlar ett ämne ur flera vinklar, med stödjande data och expertperspektiv, citeras oftare än ytlig eller ofullständig täckning.
Citeringsprocessen är inte slumpmässig; LLM:er tränas att citera källor som bäst stöder deras svar, och de visar allt oftare källhänvisningar för användaren, vilket gör urvalet till en avgörande synlighetsfaktor för innehållsskapare.
Innehållsstrukturens avgörande roll
Innehållsstruktur har blivit en av de viktigaste faktorerna för AI-synlighet, men många innehållsskapare optimerar fortfarande främst för mänskliga läsare utan att ta hänsyn till hur AI-system tolkar och extraherar information. LLM:er bearbetar innehåll hierarkiskt och använder rubriker, avsnittsbrytningar och formatering för att förstå struktur och extrahera relevanta avsnitt för citering. Den optimala strukturen för AI-läsbarhet följer tydliga riktlinjer: varje avsnitt bör vara 120–180 ord för att LLM:er ska kunna extrahera meningsfulla delar utan att de blir för långa; H2- och H3-rubriker ska tydligt visa ämneshierarkin; och direkta svar ska komma tidigt i avsnitten istället för att gömmas i textmassor.
Frågebaserade titlar och FAQ-avsnitt är särskilt effektiva eftersom de ligger helt i linje med hur konversationsbaserade AI-system tolkar användarfrågor. När någon frågar “Vilka är de bästa metoderna för innehållsmarknadsföring?”, kan AI-systemet direkt matcha frågan mot en sektion med rubriken “Vilka är de bästa metoderna för innehållsmarknadsföring?” och extrahera det relevanta innehållet. Denna strukturella anpassning ökar sannolikheten för citering dramatiskt. Här är ett exempel på korrekt strukturerat innehåll:
## Vilka är de bästa metoderna för innehållsmarknadsföring?
### Definiera din målgrupp först
[120–180 ord med direkt, åtgärdsinriktat innehåll som besvarar just denna fråga]
### Skapa en innehållskalender
[120–180 ord med direkt, åtgärdsinriktat innehåll som besvarar just denna fråga]
### Mät och optimera resultat
[120–180 ord med direkt, åtgärdsinriktat innehåll som besvarar just denna fråga]
Den här strukturen gör det möjligt för LLM:er att snabbt identifiera relevanta sektioner, extrahera kompletta svar och citera specifika avsnitt med säkerhet. Innehåll som saknar denna struktur—långa stycken utan tydliga rubriker, gömda svar eller oklar hierarki—väljs betydligt mer sällan ut för citering, oavsett kvalitet.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
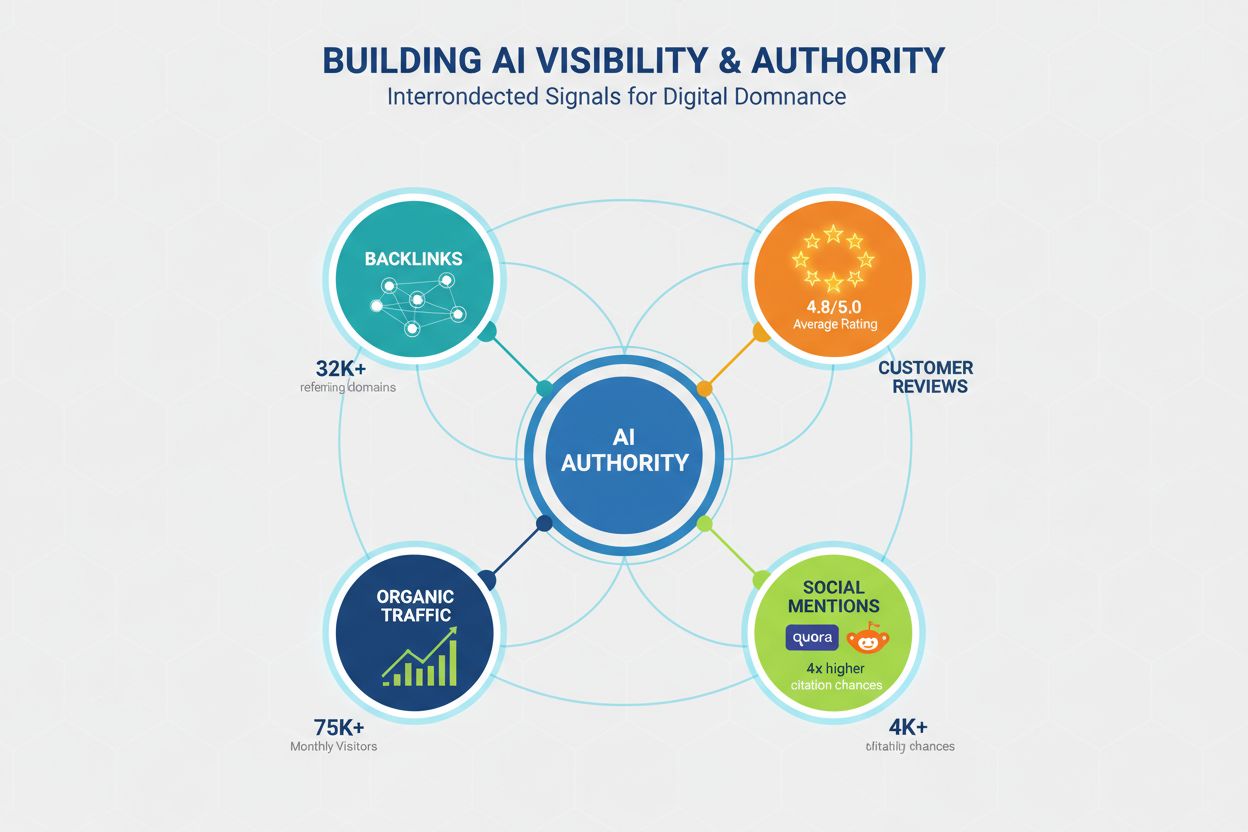
Bygga auktoritet för AI-synlighet
Auktoritet är fortsatt en avgörande faktor för AI-synlighet, även om signalerna för vad som räknas som auktoritet har utvecklats bortom traditionella SEO-mått. LLM:er känner igen auktoritet via flera kanaler, och innehållsskapare måste bygga trovärdighet på flera nivåer för att maximera chansen till citering. Forskning visar att domäner med 32 000+ hänvisande domäner får betydligt fler citeringar, och höga domänförtroendepoäng korrelerar starkt med AI-synlighet. Men auktoritet byggs inte enbart genom bakåtlänkar; det är ett mångfacetterat begrepp som innefattar:
Bakåtlänksprofil – Kvalitetslänkar från auktoritativa domäner signalerar expertis; 50+ högkvalitativa bakåtlänkar ger 4,8 gånger högre citeringsgrad jämfört med domäner med få länkar.
Socialt bevis och community-närvaro – Nämnanden på plattformar som Quora, Reddit och branschforum signalerar att ditt innehåll är betrott och refererat av riktiga användare; aktivt deltagande bygger trovärdighet.
Omdömesplattformar och betyg – Närvaro på Trustpilot, G2, Capterra och liknande med positiva omdömen bygger förtroendesignaler som LLM:er känner igen; varumärken med 4,5+ stjärnor får 3,2 gånger fler citeringar.
Hemsidetrafik och varumärkeskännedom – Direkttrafik till startsidan indikerar varumärkeskännedom och förtroende; LLM:er värderar innehåll från välkända varumärken högre än okända källor.
Expertkompetens och bylines – Innehåll skrivet av erkända experter med tydliga meriter och biografier värderas högre; författarens expertis är en separat auktoritetssignal utöver domänauktoritet.
Att bygga auktoritet för AI-synlighet kräver en långsiktig strategi som sträcker sig bortom traditionell SEO, och inkluderar community-engagemang, omdömeshantering och varumärkesbyggande utöver teknisk optimering.
Innehållsdjup och täckning
Innehållsdjup är en av de starkaste indikatorerna för AI-citering, där forskning visar att heltäckande, välresearchat innehåll får betydligt fler citeringar än ytlig täckning. Minimitröskeln för konkurrenskraftig synlighet är cirka 1 900 ord, men verkligt heltäckande material som dominerar AI-citering brukar ligga på 2 900+ ord. Det handlar inte om antal ord för sakens skull, utan om informationsdjup, mängd stödjande data och bredd av perspektiv.
Data kring innehållsdjup är övertygande:
Expertcitats betydelse – Innehåll med 4+ expertcitat får i snitt 4,1 citeringar, jämfört med 2,4 för material utan expertperspektiv; LLM:er tolkar expertinlägg som en trovärdighetssignal.
Statistikfrekvens – Innehåll med 19+ statistikpunkter får i snitt 5,4 citeringar, mot 2,8 för material med lite data; LLM:er prioriterar datastödda påståenden.
Omfattande täckning – Innehåll som behandlar 8+ delämnen inom huvudämnet får i snitt 5,1 citeringar, mot 3,2 för material med 3–4 delämnen; bredden har stor betydelse.
Egen forskning – Innehåll med originalforskning, undersökningar eller unik data får i snitt 6,2 citeringar, vilket gör det till det mest effektiva innehållsslaget för AI-synlighet.
Djupet har betydelse eftersom LLM:er tränas att ge heltäckande, välunderbyggda svar på användarfrågor, och de dras naturligt till material som låter dem citera flera perspektiv, datapunkter och expertåsikter inom en och samma källa.
Färskhet och regelbundna uppdateringar
Aktualitet är avgörande men ofta förbisedd för AI-synlighet, där forskning visar att nyligen uppdaterat innehåll får betydligt fler citeringar än föråldrat material. Effekten är dramatisk: innehåll uppdaterat inom de senaste tre månaderna får i snitt 6,0 citeringar, jämfört med bara 3,6 för innehåll som inte uppdaterats på över ett år. Detta återspeglar LLM:ers preferens för aktuell information och deras erkännande av att färskt innehåll sannolikt är mer korrekt och relevant.
En kvartalsvis uppdateringsstrategi bör vara standard för allt innehåll som riktar sig mot AI-synlighet. Det behöver inte betyda fullständiga omskrivningar; strategiska uppdateringar med ny statistik, färska exempel, reviderade fallstudier och aktuella trender räcker för att signalera aktualitet. För tidskritiska ämnen som teknik, marknadstrender eller branschnyheter kan månatliga uppdateringar krävas. Uppdateringsprocessen bör inkludera:
Tillägg av nypublicerad statistik och forskningsresultat
Uppdatering av fallstudier med aktuella exempel
Revidering av föråldrade rekommendationer utifrån nya bästa metoder
Utökning av sektioner som blivit ofullständiga på grund av branschförändringar
Innehåll som står stilla medan branschen utvecklas tappar gradvis AI-synlighet, även om det en gång var auktoritativt, eftersom LLM:er inser att föråldrad information är mindre värdefull för användaren.
Teknisk prestanda och Core Web Vitals
Teknisk prestanda har blivit allt viktigare för AI-synlighet, då LLM:er och de system som försörjer dem prioriterar material från snabba, väloptimerade webbplatser. Core Web Vitals—Googles mått på sidupplevelse—korrelerar starkt med citeringsfrekvens, vilket visar att LLM:er tar hänsyn till signaler om användarupplevelse vid val av källor. Prestandaeffekten är märkbar: sidor med First Contentful Paint (FCP) under 0,4 sekunder får i snitt 6,7 citeringar, jämfört med endast 2,1 för sidor med FCP över 2,5 sekunder.
Teknisk optimering för AI-synlighet bör fokusera på:
Largest Contentful Paint (LCP) – Sikta på under 2,5 sekunder; sidor som klarar detta får i snitt 5,8 citeringar mot 2,9 för långsammare sidor.
Cumulative Layout Shift (CLS) – Håll poängen under 0,1; ostabila layouter signalerar låg kvalitet till LLM:er och minskar citeringschanserna.
Interaction to Next Paint (INP) – Optimera för svarstid under 200 ms; interaktiva sidor får i snitt 5,2 citeringar mot 3,1 för långsamma sidor.
Mobilanpassning – Mobilförst-indexering gör mobilprestanda avgörande; sidor med dålig mobilupplevelse får 40 % färre citeringar.
Ren, semantisk HTML – Korrekt rubrikhierarki, semantiska taggar och ren kodstruktur hjälper LLM:er att tolka innehållet effektivt och ökar citeringschanserna.
Teknisk prestanda handlar inte bara om användarupplevelse; det är en direkt signal till AI-system om innehållets kvalitet och trovärdighet.
Optimera för frågebaserade frågor
Frågebaserad optimering är det mest direkta sättet att anpassa innehållet till konversationssök, och effekten är särskilt tydlig för mindre domäner utan stor auktoritet. Forskning visar att frågebaserade titlar har sju gånger större effekt för mindre domäner (under 50 000 månatliga besökare) jämfört med traditionella nyckelordstitlar, vilket gör denna strategi särskilt värdefull för nya varumärken. FAQ-avsnitt är lika kraftfulla, och fördubblar sannolikheten för citering när de implementeras med tydliga frågor och svar.
Skillnaden mellan frågebaserade och traditionella titlar är stor:
Dålig titel: “Topp 10 marknadsföringsverktyg”
Bra titel: “Vilka är de 10 bästa marknadsföringsverktygen för småföretag?”
Dålig titel: “Innehållsmarknadsföringsstrategi”
Bra titel: “Hur bör småföretag utveckla en innehållsmarknadsföringsstrategi?”
Dålig titel: “Bästa praxis för e-postmarknadsföring”
Bra titel: “Vilka är de bästa metoderna för e-postmarknadsföring för e-handelsföretag?”
Praktiska optimeringstips inkluderar:
Titeloptimering – Inkludera den huvudsakliga fråga ditt innehåll besvarar; använd naturligt språk istället för nyckelordsfyllda fraser.
FAQ-avsnitt – Skapa dedikerade FAQ-avsnitt med 5–10 frågor och direkta svar; detta fördubblar citeringschanserna för konkurrensutsatta frågor.
Rubrikanpassning – Använd H2- och H3-rubriker som matchar vanliga frågemönster; detta hjälper LLM:er att matcha användarfrågor mot ditt innehåll.
Placering av direkta svar – Placera direkta svar på frågor i början av avsnitt, inte gömda i textmassor; LLM:er extraherar svar effektivare från framträdande placering.
Frågebaserad optimering handlar inte om att lura systemet utan om att anpassa innehållsstrukturen till hur användare faktiskt ställer frågor och hur AI-system tolkar dem.
Vad du INTE ska göra – vanliga missuppfattningar
Många innehållsskapare slösar tid och resurser på optimering som har liten eller ingen effekt på AI-synlighet, eller till och med minskar chansen till citering. Att förstå dessa missuppfattningar hjälper dig att fokusera på strategier som faktiskt fungerar. En seglivad myt är att LLMs.txt-filer har stor betydelse för synligheten; forskning visar att dessa filer har försumbar effekt på citeringsnivåer, med domäner som använder LLMs.txt som bara marginellt skiljer sig (3,8 mot 4,1 citeringar i snitt) jämfört med de utan.
Vanliga missuppfattningar att undvika:
FAQ-schema markup hjälper inte i sig – Även om FAQ-schema är användbart för traditionell sökning ger det minimal nytta för AI-synlighet; den faktiska innehållsstrukturen är mycket viktigare än markup. Innehåll med FAQ-schema men dålig struktur får i snitt 3,6 citeringar, medan välstrukturerat material utan schema får 4,2.
Överoptimering minskar citeringar – Kraftigt optimerade URL:er, titlar och metabeskrivningar minskar faktiskt citeringschansen; hårt optimerat innehåll får 2,8 citeringar i snitt, naturligt skrivet material får 5,9. LLM:er känner igen och straffar tydliga optimeringsförsök.
Nyckelordsfyllning hjälper inte LLM:er – Till skillnad från traditionella sökmotorer förstår LLM:er semantisk mening och ser nyckelordsfyllning som en kvalitetssignal; naturligt språk ger betydligt fler citeringar.
Bakåtlänkar garanterar inte synlighet – Även om auktoritet är viktigt betyder innehållskvalitet och struktur mer; en högauktoritativ domän med dålig struktur får färre citeringar än en lågauktoritativ domän med utmärkt struktur.
Längd utan substans fungerar inte – Att fylla ut texten för att nå ett visst antal ord utan att tillföra värde minskar faktiskt citeringschanserna; LLM:er känner igen och straffar utfyllnad.
Fokusera på verklig kvalitet, tydlig struktur och genuin expertis istället för optimeringstrick.
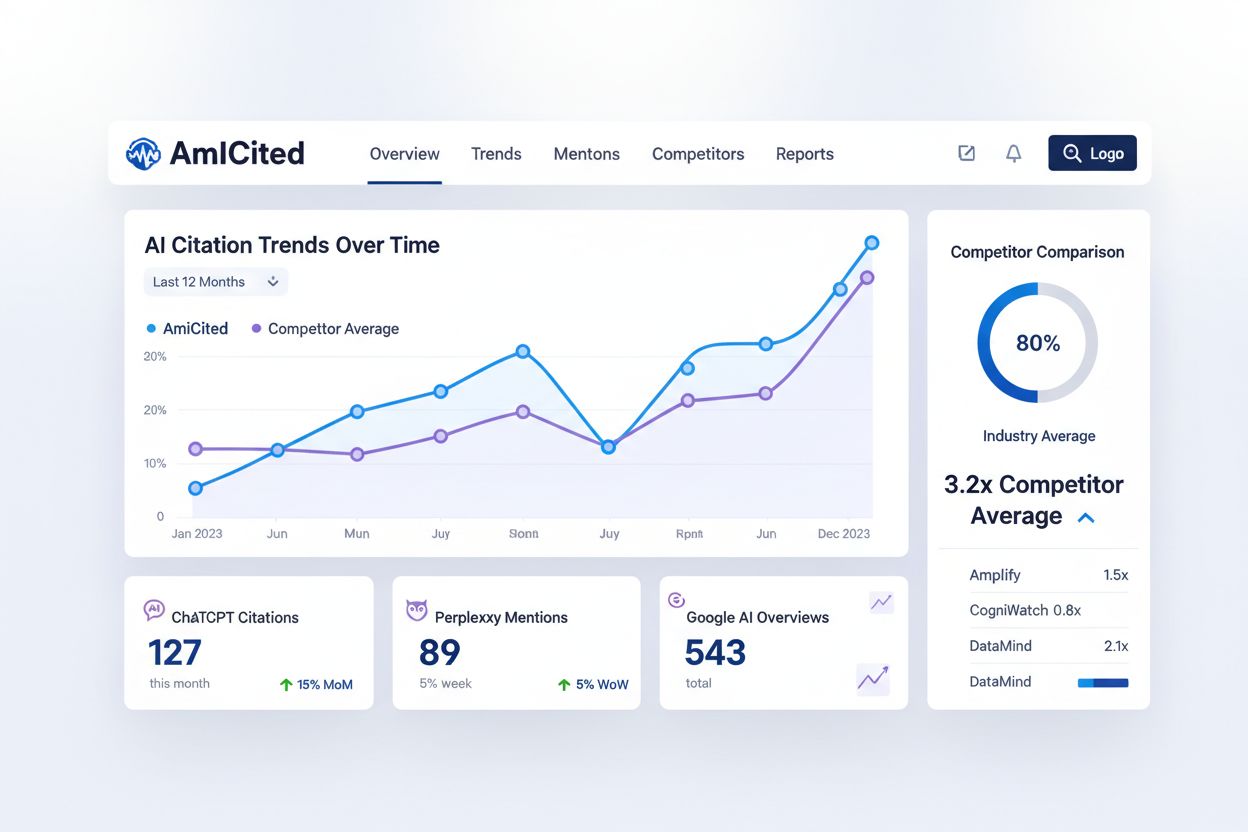
Övervaka din AI-synlighet med AmICited
Att övervaka hur konversationsbaserade AI-system citerar ditt innehåll är avgörande för att förstå din AI-synlighet och hitta optimeringsmöjligheter, men de flesta innehållsskapare har ingen insyn i denna kritiska faktor. AmICited.com erbjuder en plattform för att spåra hur ChatGPT, Perplexity, Google AI Overviews och andra konversationsbaserade AI-system refererar till ditt varumärke och innehåll. Denna övervakningsmöjlighet fyller en viktig lucka i verktygslådan och kompletterar traditionella SEO-verktyg genom att ge insyn i ett helt nytt sökparadigm.
AmICited spårar flera viktiga nyckeltal som traditionella SEO-verktyg inte kan mäta:
Citeringsfrekvens – Hur ofta ditt innehåll citeras av olika AI-system; detta visar vilket innehåll som uppskattas av AI-algoritmer och vilka ämnen som behöver förbättras.
Citeringsmönster – Vilka sidor och innehållstyper som citeras oftast; detta hjälper dig identifiera ditt starkaste material och visar luckor i täckningen.
Konkurrenters AI-synlighet – Se hur dina AI-citeringsnivåer står sig mot konkurrenter; denna benchmarking hjälper dig att förstå din position i AI-söksfären.
Trendanalys – Följ hur din AI-synlighet förändras över tid när du optimerar; du kan mäta effekten av dina strategiska förändringar.
Källdiversitet – Följ citeringar över olika AI-plattformar; synligheten i ChatGPT kan skilja sig från Perplexity eller Google AI Overviews, och förståelse för dessa skillnader hjälper dig optimera för specifika system.
Att integrera AmICited i din innehållsövervakning ger de data du behöver för att optimera specifikt för AI-synlighet istället för att gissa om dina insatser fungerar.
Praktisk implementeringsstrategi
Att implementera en frågebaserad innehållsstrategi för konversationsbaserad AI kräver ett systematiskt angreppssätt där du bygger vidare på befintligt innehåll och samtidigt etablerar nya optimeringsrutiner framåt. Implementeringsprocessen bör vara metodisk och datadriven, börja med en granskning av det nuvarande innehållet och gå vidare genom strukturell optimering, auktoritetsbyggande och kontinuerlig övervakning. Denna åttastegsmodell ger en praktisk vägkarta för att omvandla din innehållsstrategi och maximera AI-synligheten.
Granska befintligt innehåll – Analysera dina 50 bästa sidor vad gäller struktur, ordantal, rubrikhierarki och uppdateringsfrekvens; identifiera vilka sidor som redan är välstrukturerade och vilka som behöver optimeras.
Identifiera värdefulla frågeord – Undersök konversationsfrågor inom din bransch med verktyg som Answer the Public, Quora och Reddit; prioritera frågor med hög sökvolym och kommersiell avsikt.
Omstrukturera med Q&A-sektioner – Omorganisera befintligt innehåll så det innehåller frågebaserade rubriker och direkta svar; omvandla traditionella nyckelordstitlar till frågebaserade titlar som matchar användarfrågor.
Inför rubrikhierarki – Säkerställ att allt innehåll följer korrekt H2/H3-hierarki med tydlig ämnesstruktur; dela upp långa avsnitt i 120–180 ord långa delar separerade av beskrivande underrubriker.
Lägg till FAQ-sektioner – Skapa dedikerade FAQ-sektioner för dina 20 viktigaste sidor, med 5–10 frågor och direkta svar; prioritera frågor som dyker upp i sökdata och användarfeedback.
Bygg auktoritet med bakåtlänkar – Utveckla en strategi för bakåtlänkar från högkvalitativa domäner inom din bransch; fokusera på att få länkar från auktoritativa källor istället för kvantitet.
Övervaka med AmICited – Sätt upp övervakning för ditt varumärke och dina viktigaste sidor; fastställ utgångsvärden och följ förändringar när du optimerar.
Kvartalsuppdateringar – Skapa en rutin för kvartalsvisa uppdateringar där du lägger till ny statistik, uppdaterar exempel och håller innehållet aktuellt; prioritera sidor med hög trafik och många citeringar.
Denna strategi omvandlar ditt innehåll från traditionell SEO-optimering till ett heltäckande angreppssätt som maximerar synlighet i både traditionell sökning och konversationsbaserade AI-system.
Vanliga frågor
Vad är frågebaserat innehåll?
Frågebaserat innehåll är material som är strukturerat kring naturliga språkfrågor som användare ställer till konversationsbaserade AI-system. Istället för att rikta in sig på nyckelord som 'tandläkare Stockholm', riktar det sig mot hela frågor som 'Var hittar jag en bra tandläkare i Stockholm som har öppet på helger?'. Denna metod anpassar innehållet till hur människor naturligt talar och hur AI-system tolkar frågor.
Hur skiljer sig konversationsbaserad AI från traditionell sökning?
Traditionell sökning returnerar en lista med rankade länkar baserat på nyckelordsmatchning, medan konversationsbaserad AI syntetiserar direkta svar från flera källor. Konversationsbaserad AI förstår sammanhang, behåller konversationshistorik och ger ett enhetligt svar med källhänvisningar. Denna grundläggande skillnad kräver andra strategier för innehållsoptimering.
Varför är innehållsstruktur viktigt för AI-synlighet?
LLM:er tolkar innehåll hierarkiskt genom att använda rubrikstrukturer och avsnittsbrytningar för att förstå informationsorganisationen. Optimal struktur med 120–180 ord per avsnitt, tydlig H2/H3-hierarki och direkta svar i början av avsnitten gör det enklare för AI-system att extrahera och citera ditt innehåll. Dålig struktur minskar sannolikheten för citering oavsett innehållets kvalitet.
Vad är minsta innehållslängd för AI-citering?
Forskning visar att cirka 1 900 ord är minsta tröskel för konkurrenskraftig AI-synlighet, medan verkligt heltäckande innehåll når 2 900+ ord. Djupet är dock viktigare än längden—material med expertcitat, statistik och flera perspektiv får betydligt fler citeringar än utfyllnadsinnehåll.
Hur ofta bör jag uppdatera innehåll för AI-system?
Innehåll som uppdaterats inom de senaste tre månaderna får i genomsnitt 6,0 citeringar, jämfört med 3,6 för föråldrat innehåll. Implementera en kvartalsvis uppdateringsstrategi där du lägger till ny statistik, uppdaterar exempel och inkluderar de senaste utvecklingarna. Detta signalerar aktualitet till AI-system och bibehåller citeringskonkurrenskraft.
Kan små webbplatser konkurrera med stora domäner när det gäller AI-synlighet?
Ja. Även om stora domäner har auktoritetsfördelar kan mindre webbplatser konkurrera genom bättre innehållsstruktur, frågebaserad optimering och community-engagemang. Frågebaserade titlar har sju gånger större effekt för mindre domäner, och aktiv närvaro på Quora och Reddit kan ge fyra gånger högre chans till citering.
Vilken roll spelar AmICited i AI-optimering?
AmICited övervakar hur ChatGPT, Perplexity och Google AI Overviews citerar ditt varumärke och innehåll. Det ger insyn i citeringsmönster, identifierar innehållsgap, spårar konkurrenters AI-synlighet och mäter effekten av dina optimeringsinsatser—mätvärden som traditionella SEO-verktyg inte kan ge.
Är schema markup nödvändigt för AI-optimering?
Nej. Medan schema markup är användbart för traditionell sökning ger det minimal nytta för AI-synlighet. Innehåll med FAQ-schema får i genomsnitt 3,6 citeringar, medan välstrukturerat innehåll utan schema får 4,2 citeringar. Fokusera på faktisk innehållsstruktur och kvalitet istället för enbart markup.
Övervaka din AI-synlighet idag
Se hur ChatGPT, Perplexity och Google AI Overviews refererar till ditt varumärke med AmICiteds AI-citatspårning.
Behärska röstsökningsoptimering för AI-assistenter med strategier för konversationella nyckelord, utvalda utdrag, lokal SEO och schema-markup för att öka synlig...
Sökordsanalys vs Promptforskning: Det Nya Paradigmet
Upptäck hur promptforskning ersätter traditionell sökordsanalys i AI-drivna sökningar. Lär dig metodskillnaderna och optimera ditt innehåll för generativa motor...
9 min läsning
Cookie-samtycke Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.