
Differentierad åtkomst för sökrobotar
Lär dig hur du selektivt tillåter eller blockerar AI-robotar utifrån affärsmål. Implementera differentierad robotåtkomst för att skydda innehåll samtidigt som s...
8 min läsning

Lär dig hur du använder robots.txt för att styra vilka AI-botar som får tillgång till ditt innehåll. Komplett guide till att blockera GPTBot, ClaudeBot och andra AI-crawlers med praktiska exempel och konfigurationsstrategier.
Landskapet för webbskrapning har förändrats fundamentalt de senaste två åren och rört sig bortom den välbekanta världen av sökmotorindexering in i AI-modellträningens komplexa domän. Medan Googles Googlebot länge varit en förutsägbar besökare på publicisters sajter, anländer nu en ny generation crawlers med dramatiskt annorlunda intentioner och konsumtionsmönster. OpenAI:s GPTBot uppvisar en crawl-to-refer-kvot på cirka 1 700:1, vilket betyder att den crawlar 1 700 sidor för varje hänvisning tillbaka till din sajt, medan Anthropics ClaudeBot ligger på ännu mer extrema 73 000:1—i skarp kontrast till Googles 14:1 där crawleraktivitet faktiskt leder till meningsfull trafik. Denna fundamentala skillnad innebär ett akut affärsbeslut för innehållsskapare: om dessa botar får fri tillgång tränas AI-modeller på ditt innehåll som konkurrerar med din trafik och dina intäkter, medan din sajt får minimal ersättning eller trafik tillbaka. Publicister måste nu aktivt avgöra om AI-botars värdeerbjudande stämmer överens med deras affärsmodell, vilket gör robots.txt-konfigurationen till en strategisk affärsprioritet snarare än enbart en teknisk angelägenhet.
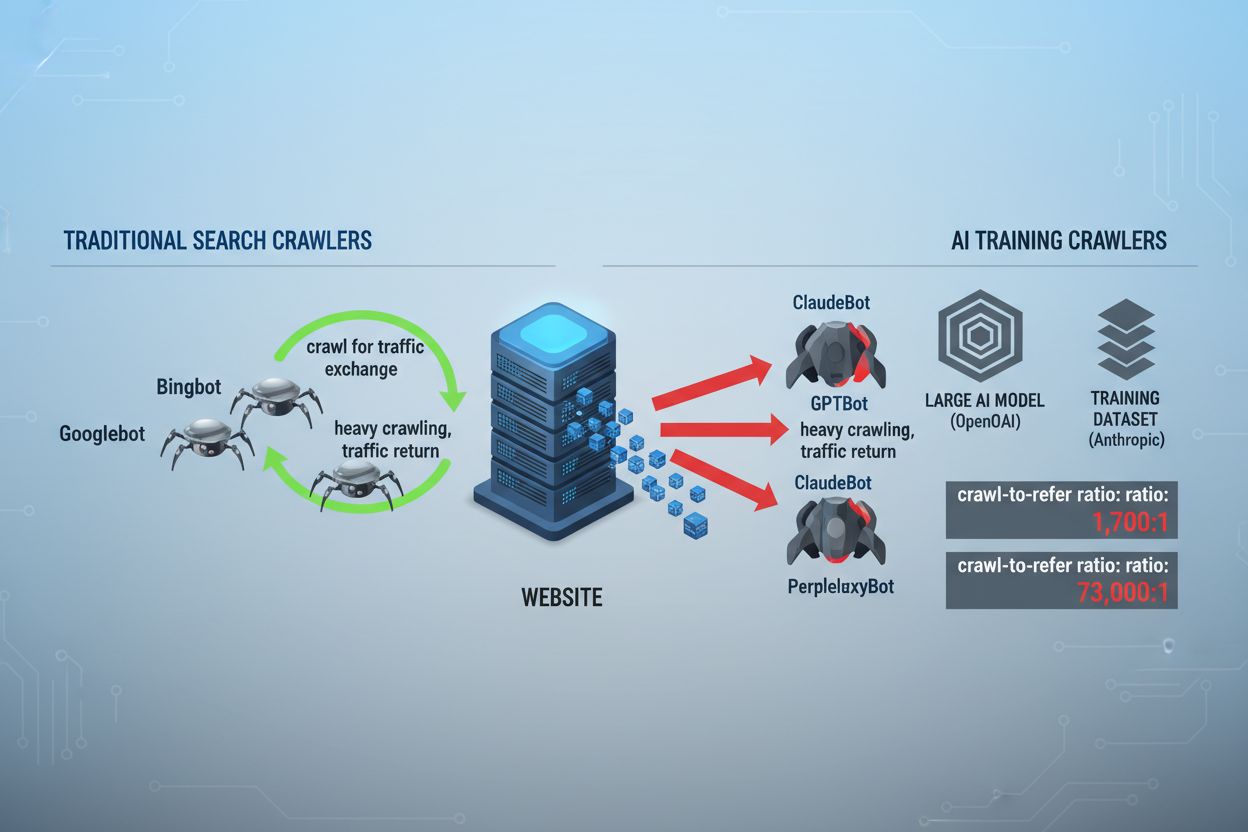
AI-crawlers verkar inom tre distinkta kategorier, som alla har olika syften och kräver olika blockeringsstrategier. Träningscrawlers är utformade för att hämta stora mängder innehåll för att träna grundläggande AI-modeller—dessa inkluderar OpenAI:s GPTBot, Anthropics ClaudeBot, Googles Google-Extended, Perplexitys PerplexityBot, Metas Meta-ExternalAgent, Apples Applebot-Extended och nya aktörer som Amazonbot, Bytespider och cohere-ai. Sökcrawlers däremot är byggda för AI-drivna sökupplevelser och leder typiskt trafik tillbaka till publicister; dessa inkluderar OpenAI:s OAI-SearchBot, Anthropics Claude-Web och Perplexitys sökfunktionalitet. Användarinitierade agenter utgör en tredje kategori där innehåll hämtas på begäran när en användare explicit efterfrågar information, såsom ChatGPT-User eller Claude-Web-interaktioner som initieras direkt av slutanvändaren. Att förstå denna taxonomi är avgörande, eftersom din blockeringsstrategi bör spegla dina affärsprioriteringar—du kanske välkomnar sökcrawlers som driver trafik men blockerar träningscrawlers som konsumerar innehåll utan ersättning. Varje större AI-företag har sitt eget flöde av specialiserade crawlers, och skillnaden mellan dem avgörs ofta av vilken user agent-sträng de använder, vilket gör korrekt identifiering och riktad blockering avgörande för en effektiv robots.txt-konfiguration.
| Företag | Träningscrawler | Sökcrawler | Användarinitierad agent |
|---|---|---|---|
| OpenAI | GPTBot | OAI-SearchBot | ChatGPT-User |
| Anthropic | ClaudeBot, anthropic-ai | Claude-Web | claude-web |
| Google-Extended | — | (Använder standard Googlebot) | |
| Perplexity | PerplexityBot | PerplexityBot | Perplexity-User |
| Meta | Meta-ExternalAgent | — | Meta-ExternalFetcher |
| Apple | Applebot-Extended | — | Applebot |
Att upprätthålla en korrekt och aktuell lista över AI-botars user agents är avgörande för en effektiv robots.txt-konfiguration, men detta landskap förändras snabbt när nya modeller lanseras och företag justerar sina crawlingstrategier. De viktigaste träningscrawlers du bör känna till är GPTBot (OpenAI:s huvudsakliga träningscrawler), ClaudeBot (Anthropics träningscrawler), anthropic-ai (Anthropics alternativa identifierare), Google-Extended (Googles AI-träningstoken), PerplexityBot (Perplexitys crawler), Meta-ExternalAgent (Metas träningscrawler), Applebot-Extended (Apples AI-träningsvariant), CCBot (Common Crawls bot), Amazonbot (Amazons crawler), Bytespider (ByteDances crawler), cohere-ai (Cohere:s träningsbot), DuckAssistBot (DuckDuckGos AI-assistent-crawler) och YouBot (You.com:s crawler). Sökfokuserade crawlers som typiskt ger trafik inkluderar OAI-SearchBot, Claude-Web och PerplexityBot i sökläge. Den kritiska utmaningen är att denna lista inte är statisk—nya AI-företag dyker regelbundet upp, existerande företag lanserar nya crawlers för nya produkter och user agent-strängar förändras eller utökas ibland. Publicister bör behandla sin robots.txt-konfiguration som ett levande dokument som kräver kvartalsvisa översyner och uppdateringar, gärna med prenumeration på branschresurser eller genom att övervaka sina serverloggar efter okända user agents som kan indikera nya AI-crawlers på sajten. Om du inte håller din user agent-lista aktuell kan det innebära att du av misstag tillåter nya träningscrawlers du ville blockera eller blockerar legitima sökcrawlers som kan ge värdefull trafik.
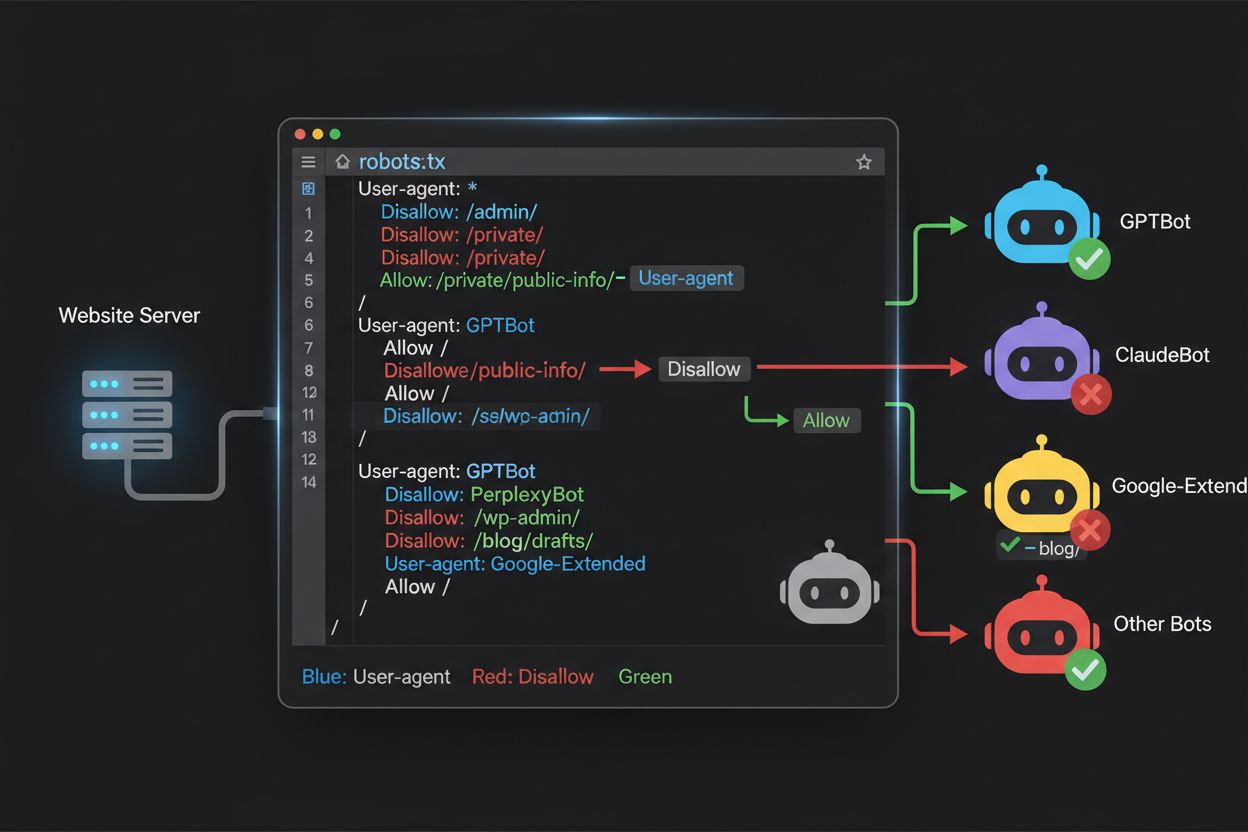
Robots.txt-filen, som ligger i din domänrot (dindomän.se/robots.txt), använder en enkel syntax för att kommunicera crawlpreferenser till botar som följer protokollet. Varje regel börjar med ett User-Agent-direktiv som specificerar vilken bot regeln gäller, följt av en eller flera Disallow-direktiv som anger vilka sökvägar boten inte får komma åt. För att blockera alla större AI-träningscrawlers samtidigt som du tillåter traditionella sökmotorer, skapar du separata User-Agent-block för varje träningscrawler du vill exkludera: GPTBot, ClaudeBot, anthropic-ai, Google-Extended, PerplexityBot, Meta-ExternalAgent, Applebot-Extended med flera, var och en med “Disallow: /” som hindrar dem från att crawla något innehåll på din sajt. Samtidigt ser du till att legitima sökcrawlers som Googlebot, Bingbot och sökfokuserade varianter som OAI-SearchBot inte blockeras, så att de kan fortsätta indexera ditt innehåll och driva trafik. En korrekt konfigurerad robots.txt-fil bör också innehålla en Sitemap-referens som pekar på din XML-sitemap, vilket hjälper sökmotorer att hitta och indexera ditt innehåll effektivt. Rätt konfiguration är avgörande—ett enda syntaxfel, felplacerat tecken eller felaktig user agent-sträng kan göra din hela blockeringsstrategi verkningslös, så att oönskade crawlers får åtkomst till ditt innehåll samtidigt som legitima trafikkällor kan blockeras. Att testa din konfiguration innan driftsättning är därför inte valfritt utan nödvändigt för att säkerställa att din robots.txt fungerar som avsett.
# Blockera AI-träningscrawlers
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: cohere-ai
Disallow: /
User-agent: DuckAssistBot
Disallow: /
User-agent: YouBot
Disallow: /
# Tillåt traditionella sökmotorer
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Sitemap-referens
Sitemap: https://yoursite.com/sitemap.xml
Många publicister står inför ett mer nyanserat beslut: de vill synas i AI-drivna sökresultat och få trafiken dessa plattformar genererar, men förhindra att deras innehåll används för att träna grundläggande AI-modeller som konkurrerar med deras affär. Denna selektiva blockering kräver att man skiljer på sökcrawlers och träningscrawlers från samma företag—till exempel tillåta OpenAI:s OAI-SearchBot (som driver ChatGPT:s sökfunktion och ger trafik) men blockera GPTBot (som tränar underliggande modellen). På samma sätt kan du tillåta PerplexityBots sökcrawler men blockera dess träningsoperationer, eller tillåta Claude-Web för användarinitierade sökningar men blockera ClaudeBots träningsaktiviteter. Affärslogiken är tydlig: sökcrawlers har vanligtvis mycket lägre crawl-to-refer-kvoter eftersom de är designade för att driva trafik tillbaka till din sajt, medan träningscrawlers konsumerar innehåll i massiv skala med minimal nytta för dig. Denna strategi kräver noggrann konfiguration och kontinuerlig övervakning, eftersom företag ibland ändrar sina crawlerstrategier eller introducerar nya user agents som suddar ut gränsen mellan sök och träning. Publicister som vill använda denna strategi bör regelbundet granska sina serverloggar för att verifiera att avsedda crawlers får åtkomst medan blockerade crawlers exkluderas, och justera robots.txt-konfigurationen när AI-landskapet förändras och nya aktörer tillkommer.
# Tillåt AI-sökcrawlers
User-agent: OAI-SearchBot
Allow: /
User-agent: Perplexity-User
Allow: /
User-agent: ChatGPT-User
Allow: /
# Blockera träningscrawlers
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
Även erfarna webbansvariga gör ofta konfigurationsfel som helt underminerar deras robots.txt-strategi och lämnar innehållet sårbart för just de crawlers man ville blockera. Ett vanligt misstag är att skapa fristående User-Agent-rader utan tillhörande Disallow-direktiv—t.ex. att skriva “User-Agent: GPTBot” på en rad och sedan börja en ny regel utan att specificera vad GPTBot inte ska komma åt, vilket lämnar boten helt oblockerad. Ett annat misstag gäller felaktig filplacering, namn eller skiftlägeskänslighet; filen måste heta exakt “robots.txt” (gemener), ligga i domänroten och levereras med HTTP-statuskod 200—om den placeras i en undermapp eller heter “Robots.txt” eller “robots.TXT” är den osynlig för crawlers. Det tredje misstaget är att infoga tomma rader inom en regelblock, vilket många robots.txt-tolkare tolkar som att regeln avslutas, så att efterföljande direktiv ignoreras eller feltillämpas. Det fjärde misstaget gäller skiftlägeskänslighet i URL-sökvägar; user agent-namn är inte skiftlägeskänsliga, men sökvägar i Disallow-direktiv är det, så “Disallow: /Admin” blockerar inte “/admin” eller “/ADMIN”. Det femte misstaget är felaktig användning av wildcards—asterisken (*) matchar valfri teckenföljd, men många använder den felaktigt genom att skriva “Disallow: .pdf” när de borde skriva “Disallow: /.pdf” eller “Disallow: /*pdf” för att matcha filändelser korrekt. Dessutom gör vissa publicister regler som är för komplexa, med motsägelsefulla Disallow-direktiv, eller glömmer att ta hänsyn till URL-parametrar och query strings, vilket kan leda till att legitimt innehåll blockeras eller att oönskat innehåll förblir tillgängligt. Att testa din konfiguration med dedikerade robots.txt-validerare innan driftsättning kan fånga dessa fel innan de påverkar sajtens crawlbarhet.
Vanliga misstag att undvika:
Google-Extended är ett unikt fall i robots.txt-konfiguration eftersom det fungerar som en kontrolltoken snarare än en traditionell crawler, och att förstå denna skillnad är avgörande för att fatta rätt blockeringsbeslut. Till skillnad från Googlebot, som crawlar din sajt för Google Sök, är Google-Extended en signal som styr om ditt innehåll får användas för att träna Googles Gemini AI-modeller och driva Googles AI Overviews-funktion i sökresultaten. Att blockera Google-Extended förhindrar att ditt innehåll används i Gemini-träning och AI Overview-generering, men påverkar inte din synlighet i vanliga Google Sök-resultat—Googlebot fortsätter indexera ditt innehåll som vanligt. Avvägningen är betydande: att blockera Google-Extended innebär att ditt innehåll inte syns i AI Overviews, som blir alltmer framträdande i Google Sök och kan driva betydande trafik, men det skyddar ditt innehåll från att användas för att träna en konkurrerande AI-modell. Omvänt betyder att tillåta Google-Extended att ditt innehåll kan synas i AI Overviews (och potentiellt driva trafik), men också att det bidrar till Geminis träningsdata, vilket på sikt kan konkurrera med ditt eget innehåll eller affärsmodell. Publicister bör noggrant överväga sin situation—nyhetsorganisationer och innehållsskapare som är beroende av direkttrafik kan gynnas av att blockera Google-Extended, medan andra kanske välkomnar synligheten och trafikmöjligheten i AI Overviews. Detta beslut bör fattas medvetet snarare än slentrianmässigt, eftersom det har stor betydelse för din långsiktiga synlighet och trafikmönster i Googles sökekosystem.
Att testa din robots.txt-konfiguration innan den tas i bruk är helt avgörande, då fel kan få långtgående konsekvenser för både din synlighet i sök och din innehållsskyddstrategi. Google Search Console erbjuder en inbyggd robots.txt-tester där du kan verifiera om specifika user agents får åtkomst till specifika URL:er på din sajt—du kan ange en user agent-sträng som “GPTBot” och en URL-sökväg, och Google visar om boten får tillgång eller blockeras enligt din nuvarande konfiguration. Merkle Robots.txt Tester erbjuder liknande funktionalitet med ett användarvänligt gränssnitt och detaljerade förklaringar om hur dina regler tolkas. TechnicalSEO.com erbjuder ytterligare ett gratis testverktyg som validerar din robots.txt-syntax och visar exakt hur olika botar behandlas. För mer omfattande övervakning har Knowatoa AI Search Console specialiserade verktyg för att spåra AI-crawleraktivitet och validera din konfiguration mot de specifika botar du försöker blockera. Din valideringsprocess bör inkludera att ladda upp din robots.txt till en testmiljö först, sedan verifiera att viktiga sidor du vill hålla öppna inte blockeras av misstag, att AI-botar du vill blockera verkligen utesluts, samt att övervaka dina serverloggar efter oväntad crawleraktivitet. Testfasen bör också inkludera att kontrollera att din Sitemap-referens är korrekt och att sökmotorer fortfarande kan komma åt ditt innehåll normalt—du vill blockera AI-träningscrawlers utan att oavsiktligt blockera legitim söktrafik. Först efter noggrann testning bör du publicera din konfiguration, och även då bör du fortsätta övervaka loggarna första veckan för att upptäcka eventuella problem.
Testverktyg:
Även om robots.txt är ett bra första försvarslager är det viktigt att förstå att det bygger på ärlighet—botar som respekterar protokollet följer dina direktiv, men illvilliga eller dåligt designade crawlers kan helt ignorera robots.txt och ändå hämta ditt innehåll. Branschdata visar att robots.txt effektivt stoppar cirka 40–60 % av oönskad crawlertrafik, vilket innebär att 40–60 % av botarna antingen ignorerar protokollet eller är utformade för att kringgå det. För publicister med behov av mer robust skydd krävs fler skyddslager. Cloudflares Web Application Firewall (WAF) låter dig skapa regler som blockerar trafik baserat på user agent-sträng, IP-adresser eller beteendemönster, vilket skyddar mot botar som ignorerar robots.txt. Serverbaserade verktyg som .htaccess (på Apache-servrar) eller motsvarande på Nginx kan blockera specifika user agents eller IP-intervall innan förfrågningar når din applikation. IP-blockering kan vara effektivt om du identifierar de IP-intervall som används av specifika crawlers, men kräver kontinuerligt underhåll då crawlerinfrastrukturen förändras. Fail2ban och liknande verktyg kan automatiskt blockera IP-adresser som uppvisar misstänkt beteende, t.ex. gör förfrågningar i omänsklig hastighet eller försöker nå känsliga sökvägar. Att införa dessa extra skydd kräver dock noggrann konfiguration—för aggressiv blockering kan utesluta legitim trafik, inklusive riktiga användare som surfar via VPN eller företagsproxy som delar IP med kända crawlers. Den mest effektiva metoden kombinerar robots.txt som första artiga begäran, user agent-blockering på servernivå för botar som ignorerar robots.txt, samt beteendeövervakning för att fånga mer avancerade crawlers som spoofar user agents eller använder distribuerade IP-adresser. Publicister bör införa dessa lager stegvis och testa varje för att säkerställa att de inte av misstag blockerar legitim trafik samtidigt som de når sina innehållsskyddsmål.
Att förstå vad som faktiskt besöker din sajt är avgörande för att verifiera att din robots.txt-konfiguration fungerar som avsett och för att identifiera nya crawlers som kan kräva blockering. Serverloggsanalys är den primära metoden för sådan övervakning—dina webbserverloggar (Apache access logs, Nginx-logs eller motsvarande) innehåller detaljerade poster om varje förfrågan mot din sajt, inklusive user agent-sträng, IP-adress, tidsstämpel och begärd resurs. Du kan använda kommandoradsverktyg som grep för att söka efter specifika user agents; till exempel “grep ‘GPTBot’ /var/log/apache2/access.log” visar alla förfrågningar från GPTBot, så att du kan verifiera om dina blockregler fungerar. Mer avancerad analys kan innebära att man parser loggar för att identifiera crawlrate för olika botar, vilka sidor de når och om de respekterar dina robots.txt-direktiv. Automatiserade övervakningslösningar kan kontinuerligt analysera loggar och varna när nya eller oväntade crawlers dyker upp, vilket är särskilt värdefullt med tanke på hur snabbt AI-crawlerlandskapet förändras. Vissa publicister använder logghanteringsplattformar som ELK Stack, Splunk eller molnbaserade lösningar för att centralisera och analysera crawleraktivitet över flera servrar. Det snabbt föränderliga AI-crawlerlandskapet innebär att övervakning inte är en engångsuppgift utan ett kontinuerligt ansvar—nya botar dyker regelbundet upp, existerande byter user agent-sträng och crawlerbeteende förändras när företag justerar sina strategier. Att etablera en rutin för regelbunden övervakning (veckovis eller månadsvis logggranskning) gör att du kan ligga steget före och justera robots.txt-profilen proaktivt, istället för att reaktivt upptäcka problem efter att de påverkat din sajt.
Din robots.txt-konfiguration för AI-crawlers är i grunden ett intäktsbeslut och förtjänar samma strategiska övervägande som alla affärsbeslut med betydande ekonomisk påverkan. Om du ger träningscrawlers fri tillgång till ditt innehåll innebär det att AI-modeller tränade på dina data så småningom kan konkurrera med din trafik och dina intäktsströmmar—om din affärsmodell bygger på direkttrafik, sökbarhet eller annonsintäkter ger du i praktiken bort gratis träningsdata till företag som bygger konkurrerande produkter. Omvänt innebär total blockering av AI-crawlers att du förlorar potentiell synlighet i AI-drivna sökresultat och hänvisningstrafik från AI-assistenter, vilket utgör en växande andel av hur användare upptäcker innehåll. Den optimala strategin beror på din affärsmodell: annonsfinansierade publicister kan gynnas av att tillåta sökcrawlers (som ger trafik och annonsvisningar) men blockera träningscrawlers (som inte ger trafik). Prenumerationsbaserade publicister kan vara mer aggressiva och blockera de flesta AI-crawlers för att skydda sitt innehåll från att summeras eller repliceras av AI-system. Publicister som fokuserar på varumärkessynlighet och tankeledarskap kan välkomna AI-söksynlighet som en form av distribution. Det viktiga är att detta beslut fattas medvetet snarare än av gammal vana—många publicister har aldrig konfigurerat robots.txt för AI-crawlers och tillåter därmed alla botar som standard, vilket innebär att de gjort ett passivt val att bidra med innehåll till AI-träning utan att aktivt ha valt det. Överväg även att implementera schemamarkering som ger korrekt attribuering när ditt innehåll används av AI-system, vilket kan hjälpa till att driva trafik och erkännande tillbaka till din sajt även när innehållet refereras av AI-assistenter. Din robots.txt-konfiguration bör spegla din medvetna affärsstrategi och ses över och uppdateras regelbundet i takt med att AI-landskapet och dina egna affärsprioriteringar förändras.
AI-crawlerlandskapet utvecklas i en aldrig tidigare skådad takt, med nya företag som lanserar AI-produkter, existerande företag som introducerar nya crawlers och user agent-strängar som regelbundet ändras eller utökas. Din robots.txt-konfiguration får därför inte vara en engångsfil utan ett levande dokument som du granskar och uppdaterar minst varje kvartal. Skapa en process för att bevaka branschmeddelanden om nya AI-crawlers, prenumerera på relevanta nyhetsbrev eller bloggar som följer dessa händelser och revidera regelbundet dina serverloggar för att identifiera okända user agents som kan indikera nya crawlers på din sajt. När du upptäcker nya crawlers, undersök deras syfte och affärsmodell för att avgöra om de passar in i din innehållsskyddsstrategi och uppdatera robots.txt därefter. Utvärdera även effektiviteten i din konfiguration genom att följa upp mätvärden som crawlertrafikvolym, förhållandet mellan crawlerförfrågningar och användartrafik samt eventuella förändringar i din organiska synlighet eller hänvisningstrafik från AI-drivna sökresultat. Vissa publicister märker att deras initiala blockstrategi behöver justeras efter några månaders data—kanske inser de att blockering av en viss crawler fått oväntade konsekvenser, eller att tillåtna crawlers ger mer värdefull trafik än väntat. Var beredd att iterera din strategi utifrån verkliga resultat snarare än antaganden. Slutligen, kommunicera din robots.txt-strategi till relevanta intressenter inom organisationen—ditt SEO-team, innehållsteam och affärsledning bör alla förstå varför vissa crawlers blockeras eller tillåts, så att besluten förblir konsekventa och avsiktliga när organisationen utvecklas. Denna kontinuerliga uppmärksamhet på crawlerhantering gör att din innehållsskyddsstrategi förblir effektiv och i linje med dina affärsmål när AI-landskapet fortsätter att förvandlas.
Nej. Att blockera AI-träningscrawlers som GPTBot, ClaudeBot och CCBot påverkar inte dina Google- eller Bing-sökrankningar. Traditionella sökmotorer använder andra crawlers (Googlebot, Bingbot) som arbetar oberoende. Blockera endast dessa om du vill försvinna helt från sökresultaten.
Stora crawlers från OpenAI (GPTBot), Anthropic (ClaudeBot), Google (Google-Extended) och Perplexity (PerplexityBot) anger officiellt att de respekterar robots.txt-direktiv. Mindre eller mindre transparenta botar kan dock ignorera din konfiguration, vilket är anledningen till att lagerbaserade skyddsstrategier finns.
Det beror på din strategi. Att endast blockera träningscrawlers (GPTBot, ClaudeBot, CCBot) skyddar ditt innehåll från modellträning samtidigt som du låter sökfokuserade crawlers hjälpa dig att synas i AI-sökresultat. Fullständig blockering tar bort dig helt från AI-ekosystemen.
Gå igenom din konfiguration minst varje kvartal. AI-företag introducerar regelbundet nya crawlers. Anthropic slog ihop sina 'anthropic-ai'- och 'Claude-Web'-botar till 'ClaudeBot', vilket gav den nya boten tillfälligt obegränsad tillgång till webbplatser som inte uppdaterat sina regler.
Robots.txt är en fil i din domänrot som gäller för alla sidor, medan meta robots-taggar är HTML-direktiv på enskilda sidor. Robots.txt kontrolleras först och kan hindra crawlers från att ens komma åt en sida, medan meta-taggar endast läses om sidan öppnas. Använd båda för fullständig kontroll.
Ja. Du kan använda sökvägsspecifika Disallow-regler i robots.txt (t.ex. 'Disallow: /premium/' för att blockera endast premiuminnehåll) eller använda meta robots-taggar på enskilda sidor. Det gör att du kan skydda känsligt innehåll samtidigt som crawlers får tillgång till andra områden.
Om en bot ignorerar robots.txt behöver du ytterligare skyddsmetoder som blockering på servernivå (.htaccess), IP-blockering eller WAF-regler. Robots.txt stoppar ungefär 40–60 % av oönskade crawlers, så lagerbaserat skydd är viktigt för fullständigt försvar.
Använd testverktyg som Google Search Consoles robots.txt-tester, Merkle Robots.txt Tester eller TechnicalSEO.com för att validera din konfiguration. Övervaka dina serverloggar för crawl-aktivitet för att verifiera att blockerade botar utesluts och tillåtna botar får åtkomst till ditt innehåll.
Robots.txt är bara första steget. Använd AmICited för att spåra vilka AI-system som citerar ditt innehåll, hur ofta de refererar till dig och säkerställ korrekt attribuering över GPTs, Perplexity, Google AI Overviews och mer.
Lär dig hur du selektivt tillåter eller blockerar AI-robotar utifrån affärsmål. Implementera differentierad robotåtkomst för att skydda innehåll samtidigt som s...

Lär dig identifiera och övervaka AI-crawlers som GPTBot, ClaudeBot och PerplexityBot i dina serverloggar. Komplett guide med user-agent-strängar, IP-verifiering...

Fullständig referensguide till AI-crawlers och botar. Identifiera GPTBot, ClaudeBot, Google-Extended och 20+ andra AI-crawlers med user agents, crawl-hastighete...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.