Stack Overflow och AI-citat: Synlighet för den tekniska gemenskapen
Upptäck hur Stack Overflow-innehåll formar AI-svar och lär dig strategier för att maximera din utvecklarsynlighet i ChatGPT, Gemini och andra AI-plattformar.
Publicerad den Jan 3, 2026.Senast ändrad den Jan 3, 2026 kl 3:24 am
Stack Overflows 50 miljoner frågor och svar har blivit en hörnsten i utvecklingen av stora språkmodeller. De största AI-företagen, inklusive OpenAI, Google och Meta, har integrerat Stack Overflow-data i sina träningsdatamängder eftersom utvecklarkunskap representerar något av det mest högkvalitativa, granskade tekniska innehållet som finns tillgängligt på internet. Att utveckla avancerade AI-system kostar hundratals miljoner dollar, och en stor del av den kostnaden kommer från att skaffa och bearbeta träningsdata. Historiskt sett har AI-företag hämtat dessa data gratis, men Stack Overflows VD Prashanth Chandrasekar tillkännagav 2023 att plattformen skulle börja ta betalt av stora AI-utvecklare för åtkomst till sitt innehåll, i erkännande av att kunskap som skapats av gemenskapen bör kompenseras. Denna förändring speglar en bredare rörelse i branschen där plattformar med värdefull data kräver rättvis ersättning från företag som tjänar på deras innehåll.
Attribuering och Creative Commons-licensiering
Stack Overflow-innehåll är licensierat under Creative Commons Attribution-ShareAlike 4.0 (CC BY-SA), vilket juridiskt kräver att alla som använder innehållet ger attribuering till de ursprungliga författarna. Detta licensramverk är icke-förhandlingsbart för Stack Overflow, eftersom plattformen anser att attribuering är grunden för utvecklarnas förtroende för AI-genererat innehåll. När AI-företag tränar modeller på Stack Overflow-data utan korrekt attribuering bryter de tekniskt sett mot Creative Commons-licensen, vilket är anledningen till att Stack Overflow nu kräver att alla API-partners inkluderar krav på attribuering i sina kontrakt. Vikten av detta kan inte överskattas: enligt Stack Overflows utvecklarundersökning 2024 anger 65 % av utvecklarna att utebliven eller felaktig attribuering är en av de största etiska problemen med AI-verktyg.
Stack Overflows strategi för AI-licensiering skiljer mellan gratis- och kommersiella användningsfall. Plattformen fortsätter att erbjuda fri åtkomst till sitt API och datautdrag för icke-kommersiella syften, utbildningsbruk och open source-projekt, och bevarar sitt åtagande gentemot utvecklargemenskapen. Däremot måste företag som utvecklar stora språkmodeller för kommersiella syften förhandla om licensavtal med Stack Overflow, där prissättningen baseras på faktorer som modellens omfattning, användningsvolym och genererad intäkt. Stack Overflows VD Chandrasekar betonade att företaget endast söker ersättning från organisationer som utvecklar LLM:er för “stora, kommersiella syften”, inte från enskilda utvecklare eller små projekt. Denna dubbla licensmodell gör det möjligt för Stack Overflow att skapa nya intäktsströmmar samtidigt som man skyddar intressena hos sina gemenskapsmedlemmar, varav många bidrar med innehåll utan förväntan på direkt betalning. Företaget har också åtagit sig att återinvestera licensintäkter i gemenskapsverktyg och funktioner, och skapar därmed en hållbar modell där utvecklarbidrag direkt finansierar förbättringar av plattformen.
Utvecklarsynlighet i AI-sökresultat
Stack Overflow-innehåll förekommer nu framträdande i AI-genererade svar på stora plattformar som ChatGPT, Google Gemini, Perplexity och Microsoft Copilot. Googles Gemini Cloud Assist attribuerar uttryckligen Stack Overflow-svar när kodlösningar tillhandahålls, och visar den ursprungliga frågan, svaret och författarinformationen direkt i AI-svaret. OpenAIs ChatGPT visar Stack Overflow-länkar i konversationer om kodningsämnen, och SearchGPT—OpenAIs sökprototyp—inkluderar Stack Overflow-resultat både i konversationssvar och sökresultatslistor. Denna synlighet är avgörande för utvecklare eftersom den genererar trafik tillbaka till deras svar och etablerar dem som erkända experter inom sitt område. Dock ger inte alla AI-plattformar lika mycket attribuering, och utvecklare har ofta svårt att förstå vilka av deras svar som citeras, hur ofta och i vilket sammanhang över olika AI-system.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Förtroendekrisen i AI-genererat innehåll
Stack Overflows utvecklarundersökning 2024 visar på en växande klyfta mellan AI-användning och förtroende: medan 76 % av utvecklarna använder eller planerar att använda AI-verktyg (upp från 70 % 2023), har AI:s popularitet minskat från 77 % till 72 %. Endast 43 % av utvecklarna litar på noggrannheten i AI-verktyg, och undersökningen identifierade tre kritiska etiska frågor som utvecklare prioriterar:
Desinformationsrisk: 79 % av utvecklarna är oroade över AI:s potentiella spridning av desinformation
Attribuering och erkännande: 65 % oroar sig för utebliven eller felaktig attribuering av datakällor
Partiskhet och representation: 50 % oroar sig för partiskhet som inte representerar olika perspektiv
Detta förtroendetapp påverkar direkt hur AI-företag hanterar datainsamling och modellträning. Utvecklare kräver i allt högre grad att AI-system citerar sina källor, erkänner gemenskapsbidrag och upprätthåller noggrannhetsstandarder som speglar Stack Overflows granskade innehåll. Trycket att bygga pålitliga AI-system har skapat en brådska kring datainköp med fokus på högkvalitativ träningsdata, vilket gör Stack Overflows verifierade, gemenskapskuraterade kunskap mer värdefull än någonsin.
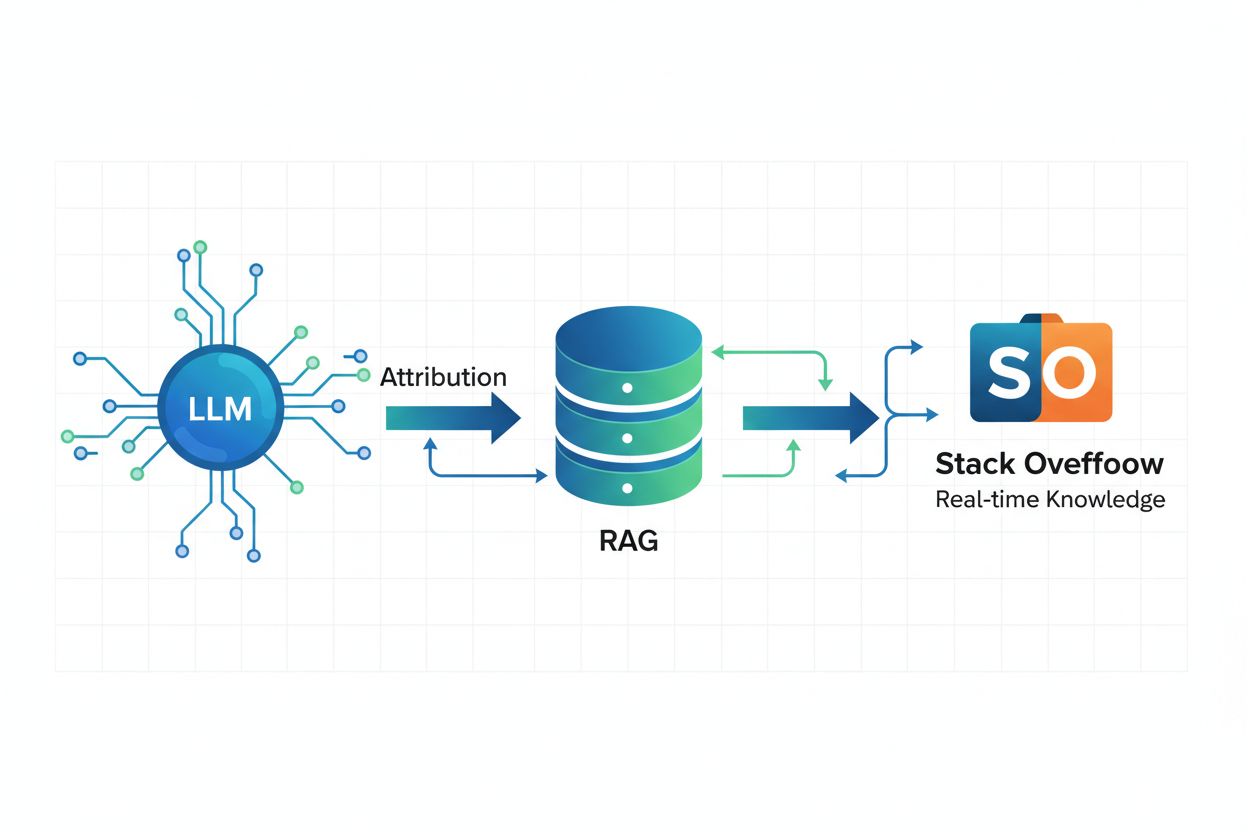
Retrieval Augmented Generation (RAG) och attribuering
Retrieval Augmented Generation (RAG) är ett AI-ramverk som kombinerar stora språkmodeller med traditionella informationsåtervinningssystem för att tillhandahålla aktuella, korrekta och korrekt attribuerade svar. Istället för att enbart lita på träningsdata frusna vid en viss tidpunkt gör RAG det möjligt för AI-system att hämta realtidsinformation från externa källor som Stack Overflow, vilket säkerställer att svaren återspeglar den senaste kunskapen och bästa praxis. Alla Stack Overflows OverflowAPI-partners har implementerat RAG för att möjliggöra korrekt attribuering, vilket innebär att när ett AI-system genererar ett svar med Stack Overflow-innehåll kan det identifiera och citera de specifika inlägg som påverkat svaret. Denna teknik är särskilt kraftfull för ämnesspecifik kunskap där noggrannhet och aktualitet spelar roll—till exempel säkerställer du genom att mata AI-systemet med specifika exempel från din kodbas att genererad C#-kod följer ditt teams riktlinjer och konventioner. RAG minskar risken för hallucinationer genom att förankra AI-svar i betrodda, verifierade fakta som användare uttryckligen identifierar, vilket gör det till den tekniska grunden för ansvarsfull AI-utveckling.
Övervaka din utvecklarsynlighet
Utvecklare som bidrar till Stack Overflow bör aktivt övervaka hur deras innehåll visas i AI-genererade svar på olika plattformar. Verktyg som AmICited.com, XFunnel, Profound och andra erbjuder nu synlighetsspårning som är särskilt utformad för att visa utvecklare var deras svar citeras, hur ofta och i vilket sammanhang över ChatGPT, Gemini, Perplexity och andra AI-system. Viktiga mätvärden att följa inkluderar citeringsfrekvens (hur ofta ditt innehåll refereras), sentiment (om omnämnandet är positivt eller neutralt), plattformsfördelning (vilka AI-system citerar dig mest) och källattribution (om korrekt erkännande ges). Genom att övervaka dessa mätvärden kan utvecklare identifiera vilka av deras svar som ger störst värde för AI-systemen, förstå vilka ämnen som är mest efterfrågade och anpassa sin bidragsstrategi därefter. Dessutom hjälper synlighetsuppföljning utvecklare att upptäcka felaktiga eller ofullständiga citeringar, så att de kan uppdatera sina ursprungliga svar eller kontakta AI-företag för att begära rättelser. Detta proaktiva synsätt förvandlar passivt innehållsbidrag till en aktiv strategi för att bygga auktoritet och inflytande inom det AI-drivna informationslandskapet.
Bästa praxis för närvaro i gemenskapen
För att maximera synligheten i AI-sökresultat och säkerställa att dina Stack Overflow-bidrag citeras korrekt, fokusera på att skapa omfattande, väl dokumenterade svar som täcker hela frågan med tydliga förklaringar och fungerande kodexempel. Håll dina svar aktuella genom att regelbundet granska och uppdatera dem i takt med att teknologier förändras, eftersom AI-system prioriterar färskare innehåll—i genomsnitt är innehåll som citeras i AI-resultat 25,7 % färskare än det som rankas i Google. Bygg auktoritet genom att konsekvent tillhandahålla högkvalitativa svar inom flera relaterade ämnen, då utvecklare i topp 25 % för webbomnämnanden får 10 gånger fler AI-citeringar än andra. Engagera dig i det bredare utvecklarekosystemet genom att delta i diskussioner, besvara uppföljningsfrågor och hjälpa andra gemenskapsmedlemmar att förbättra sina bidrag. Tänk slutligen på hur dina svar kan användas av AI-system: strukturera dina svar med tydliga rubriker, inkludera relevanta kodavsnitt och ge kontext om när och varför specifika tillvägagångssätt är lämpliga, vilket gör ditt innehåll mer användbart både för mänskliga läsare och AI-system som behöver extrahera och attribuera information korrekt.
Vanliga frågor
Hur används Stack Overflow-data vid AI-träning?
Stack Overflows 50 miljoner frågor och svar ingår i stora språkmodeller eftersom de representerar högkvalitativt, granskad tekniskt innehåll. AI-företag som OpenAI, Google och Meta använder dessa data för att träna sina modeller att bättre förstå och generera kod och tekniska lösningar. Historiskt sett har dessa data hämtats gratis, men Stack Overflow kräver nu att kommersiella AI-utvecklare licensierar datan genom betalda avtal.
Vad är skillnaden mellan gratis och betald Stack Overflow API-åtkomst?
Stack Overflow erbjuder gratis API-åtkomst för icke-kommersiella syften, utbildningsbruk och open source-projekt. Företag som utvecklar stora språkmodeller för kommersiella syften måste dock förhandla om betalda licensavtal. Prissättningen baseras på faktorer som modellens omfattning, användningsvolym och genererad intäkt, vilket säkerställer att gemenskapens bidrag kompenseras korrekt.
Hur kan jag försäkra mig om att mina Stack Overflow-svar citeras av AI?
Skapa omfattande, väl dokumenterade svar med tydliga förklaringar och fungerande kodexempel. Håll dina svar aktuella genom att uppdatera dem i takt med att teknologier utvecklas, eftersom AI-system prioriterar färskare innehåll. Bygg auktoritet genom att konsekvent tillhandahålla högkvalitativa svar inom flera ämnen och strukturera dina svar med tydliga rubriker och relevanta kodavsnitt som AI-system enkelt kan extrahera och attribuera.
Vad är RAG och varför är det viktigt för attribuering?
Retrieval Augmented Generation (RAG) är ett AI-ramverk som kombinerar språkmodeller med informationsåtervinningssystem för att tillhandahålla aktuella, korrekta och korrekt attribuerade svar. RAG gör det möjligt för AI-system att hämta realtidsinformation från källor som Stack Overflow och citera de specifika inlägg som påverkat svaret, vilket säkerställer korrekt attribuering och minskar risken för hallucinationer.
Hur övervakar jag min synlighet i AI-sökresultat?
Verktyg som AmICited.com, XFunnel, Profound och andra erbjuder synlighetsspårning som är särskilt utformad för att visa utvecklare var deras svar citeras i ChatGPT, Gemini, Perplexity och andra AI-system. Dessa verktyg spårar citeringsfrekvens, sentiment, plattformsfördelning och källattribution, vilket hjälper dig att förstå vilka av dina svar som ger mest värde till AI-systemen.
Vilka etiska frågor finns med att AI använder gemenskapsinnehåll?
Enligt Stack Overflows utvecklarundersökning 2024 har utvecklare tre huvudsakliga etiska farhågor: risk för desinformation (79 % oroade), utebliven eller felaktig attribuering (65 % oroade) och partiskhet som inte representerar olika perspektiv (50 % oroade). Dessa farhågor driver behovet av korrekt licensiering, krav på attribuering och högkvalitativ träningsdata från verifierade källor som Stack Overflow.
Hur skyddar Stack Overflows licensiering utvecklare?
Stack Overflow-innehåll är licensierat under Creative Commons Attribution-ShareAlike 4.0 (CC BY-SA), vilket juridiskt kräver att alla som använder innehållet ger attribuering till de ursprungliga författarna. Stack Overflow kräver nu att alla API-partners inkluderar krav på attribuering i sina avtal, vilket säkerställer att utvecklare får korrekt erkännande när deras svar används av AI-system.
Vilka verktyg kan jag använda för att spåra AI-citeringar av mitt innehåll?
Flera verktyg finns tillgängliga för att spåra AI-citeringar, inklusive AmICited.com (specialiserat på AI-övervakning), XFunnel (övervakning för företags-LLM), Profound (avancerad GEO-spårning), Semrush AI Toolkit, BrightEdge och andra. Dessa verktyg hjälper dig att spåra vilka AI-plattformar som citerar dig, hur ofta, i vilket sammanhang och om korrekt attribuering ges.
Övervaka din Stack Overflow-synlighet i AI-sökning
Följ hur din tekniska expertis citeras i ChatGPT, Gemini, Perplexity och andra AI-plattformar. Få insikter i realtid om din utvecklarsynlighet och optimera din närvaro i gemenskapen.
Kan du faktiskt påverka vad AI lär sig om ditt varumärke under träning? Är detta ens möjligt?
Diskussion i communityn om att påverka AI:s träningsdata om ditt varumärke. Äkta insikter om hur innehållsskapande påverkar vad AI-system lär sig och minns om f...
Wikipedias roll i AI-träningsdata: Kvalitet, påverkan och licensiering
Upptäck hur Wikipedia fungerar som ett avgörande AI-träningsdataset, dess påverkan på modellernas noggrannhet, licensavtal och varför AI-företag är beroende av ...
Hur du avanmäler dig från AI-träning på stora plattformar
Komplett guide för att avanmäla dig från AI-träning och datainsamling på ChatGPT, Perplexity, LinkedIn och andra plattformar. Lär dig steg-för-steg hur du skydd...
8 min läsning
Cookie-samtycke Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.