Träningsdata vs Realtidsåterhämtning: Optimeringsstrategier
Jämför optimering av träningsdata och strategier för realtidsåterhämtning för AI. Lär dig när du ska använda finjustering vs RAG, kostnadsimplikationer och hybrida tillvägagångssätt för optimal AI-prestanda.
Publicerad den Jan 3, 2026.Senast ändrad den Jan 3, 2026 kl 3:24 am
Optimering av träningsdata och realtidsåterhämtning representerar fundamentalt olika metoder för att förse AI-modeller med kunskap. Optimering av träningsdata innebär att kunskap bäddas in direkt i modellens parametrar genom finjustering på domänspecifika datamängder, vilket skapar statisk kunskap som förblir oförändrad efter avslutad träning. Realtidsåterhämtning, däremot, håller kunskapen utanför modellen och hämtar relevant information dynamiskt vid inferens, vilket möjliggör tillgång till dynamisk information som kan förändras mellan förfrågningar. Den grundläggande skillnaden ligger i när kunskapen integreras i modellen: optimering av träningsdata sker före driftsättning, medan realtidsåterhämtning sker vid varje inferensanrop. Denna fundamentala skillnad påverkar alla aspekter av implementation, från infrastrukturkrav till noggrannhetskaraktäristik och regelefterlevnad. Att förstå denna skillnad är avgörande för organisationer som ska välja vilken optimeringsstrategi som passar deras specifika användningsfall och begränsningar.
Hur optimering av träningsdata fungerar
Optimering av träningsdata fungerar genom att systematiskt justera modellens interna parametrar genom exponering för kuraterade, domänspecifika datamängder under finjusteringsprocessen. När en modell upprepade gånger möter träningsdata, internaliserar den gradvis mönster, terminologi och domänkunskap genom backpropagation och gradientuppdateringar som formar modellens inlärningsmekanismer. Denna process gör det möjligt för organisationer att koda in specialiserad kunskap—oavsett om det är medicinsk terminologi, juridiska ramar eller egen affärslogik—direkt i modellens vikter och fördomar. Den resulterande modellen blir mycket specialiserad för sitt måldomän och uppnår ofta prestanda jämförbar med mycket större modeller; forskning från Snorkel AI har visat att finjusterade mindre modeller kan prestera lika bra som modeller 1 400 gånger större. Viktiga egenskaper för optimering av träningsdata inkluderar:
Permanent kunskapsintegration: När modellen är tränad blir kunskapen en del av modellen och kräver inga externa uppslag
Minskad inferenslatens: Ingen återhämtningskostnad vid prediktion, vilket möjliggör snabbare svarstider
Konsekvent stil och formatering: Modeller lär sig domänspecifika kommunikationsmönster och konventioner
Kapacitet för offline-drift: Modeller fungerar självständigt utan externa datakällor
Höga initiala beräkningskostnader: Kräver betydande GPU-resurser och förberedelse av märkta träningsdata
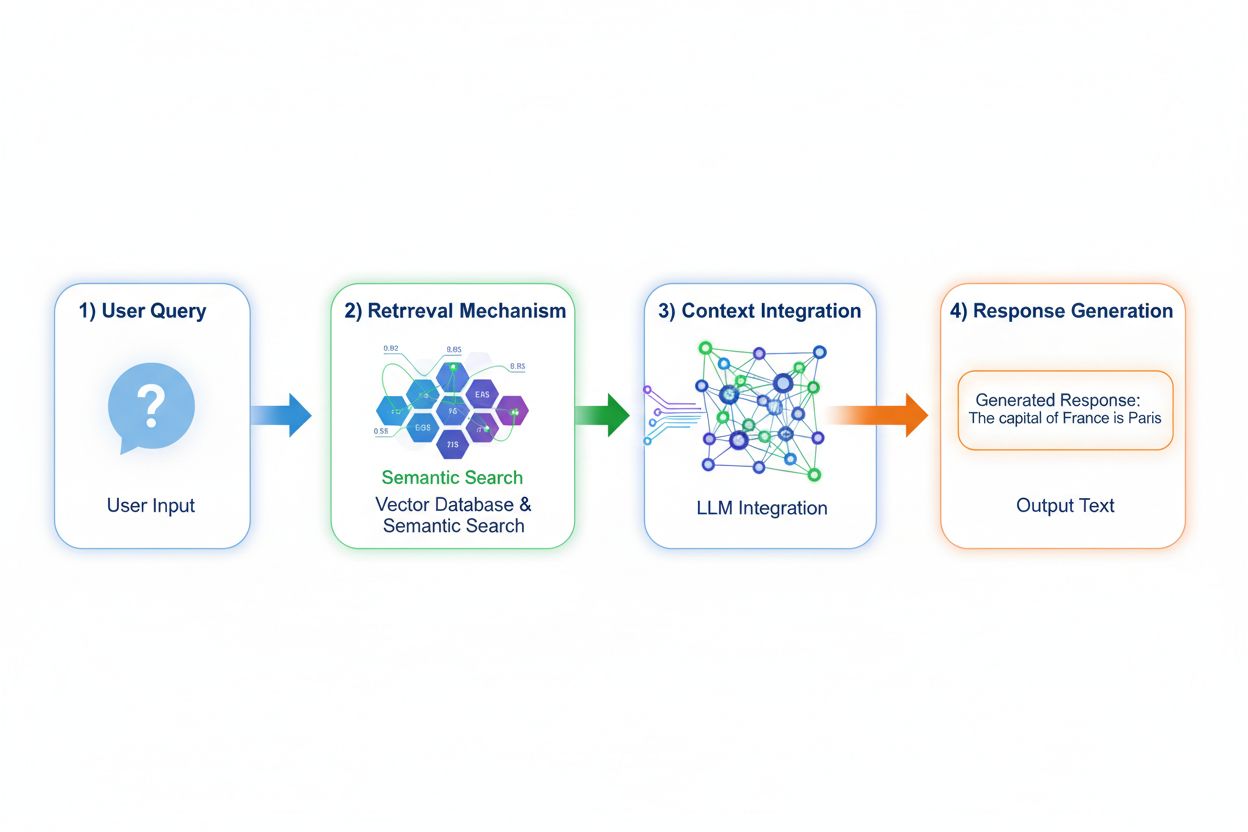
Retrieval Augmented Generation (RAG) förändrar i grunden hur modeller får tillgång till kunskap genom att implementera en fyrstegsprocess: frågekodning, semantisk sökning, kontextrankning och generering med grundning. När en användare skickar in en fråga, omvandlar RAG den först till en tät vektorrepresentation med inbäddningsmodeller, och söker sedan i en vektordatabas innehållande indexerade dokument eller kunskapskällor. Återhämtningssteget använder semantisk sökning för att hitta kontextuellt relevanta passager istället för enkel sökordsbaserad matchning och rangordnar resultaten efter relevanspoäng. Slutligen genererar modellen svar medan den upprätthåller explicita referenser till hämtade källor, och grundar sitt utdata på faktisk data snarare än inlärda parametrar. Denna arkitektur gör det möjligt för modeller att få tillgång till information som inte existerade vid träningstillfället, vilket gör RAG särskilt värdefullt för applikationer som kräver aktuell information, egen data eller ofta uppdaterade kunskapsbaser. RAG-mekanismen förvandlar i praktiken modellen från ett statiskt kunskapslager till en dynamisk informationssyntetiserare som kan införliva ny data utan omträning.
Jämförelse av prestanda och noggrannhet
Noggrannhet och hallucinationsprofil för dessa tillvägagångssätt skiljer sig avsevärt på sätt som påverkar verklig användning. Optimering av träningsdata ger modeller med djup domänförståelse men begränsad förmåga att erkänna kunskapsgränser; när en finjusterad modell stöter på frågor utanför sin träningsdistribution kan den självsäkert generera trovärdig men felaktig information. RAG minskar hallucinationer avsevärt genom att grunda svaren i hämtade dokument—modellen kan inte hävda information som inte finns i dess källmaterial, vilket skapar naturliga begränsningar för fabricering. RAG introducerar dock andra risker för noggrannhet: om återhämtningssteget misslyckas med att hitta relevanta källor eller rangordnar irrelevanta dokument högt, genererar modellen svar baserat på dålig kontext. Datats färskhet blir avgörande för RAG-system; optimering av träningsdata fångar en statisk ögonblicksbild av kunskapen vid träningstillfället, medan RAG kontinuerligt speglar aktuellt tillstånd för källdokumenten. Källhänvisning är ytterligare en skillnad: RAG möjliggör per automatik citering och verifiering av påståenden, medan finjusterade modeller inte kan peka ut specifika källor för sin kunskap, vilket försvårar faktakontroll och regelefterlevnad.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Kostnads- och infrastrukturimplikationer
De ekonomiska profilerna för dessa tillvägagångssätt skapar olika kostnadsstrukturer som organisationer måste utvärdera noggrant. Optimering av träningsdata kräver betydande beräkningskostnader i förväg: GPU-kluster som körs i dagar eller veckor för att finjustera modeller, dataannoteringstjänster för att skapa märkta träningsdata och ML-ingenjörskompetens för att designa effektiva träningspipelines. När modellen är tränad är driftskostnaderna relativt låga eftersom inferens bara kräver vanlig modellserverinfrastruktur utan externa uppslag. RAG-system vänder på denna kostnadsstruktur: lägre initiala träningskostnader eftersom ingen finjustering sker, men löpande infrastrukturskostnader för underhåll av vektordatabaser, inbäddningsmodeller, återhämtningsservrar och dokumentindexering. Viktiga kostnadsfaktorer inkluderar:
Finjustering: GPU-timmar ($10,000-$100,000+ per modell), dataannotering ($0,50-$5 per exempel), ingenjörstid
RAG-infrastruktur: Licenser för vektordatabaser, servering av inbäddningsmodeller, lagring och indexering av dokument, optimering av återhämtningslatens
Skalbarhet: Finjusterade modeller skalar linjärt med inferensvolymen; RAG-system skalar med både inferensvolym och storlek på kunskapsbasen
Säkerhets- och regelefterlevnadsaspekterna skiljer sig betydligt mellan dessa tillvägagångssätt och påverkar organisationer inom reglerade branscher. Finjusterade modeller skapar dataskyddsutmaningar eftersom träningsdata bäddas in i modellens vikter; att extrahera eller revidera vilken kunskap modellen innehåller kräver avancerade tekniker, och integritetsproblem uppstår när känslig träningsdata påverkar modellens beteende. Regelefterlevnad med förordningar som GDPR blir komplext eftersom modellen i praktiken “minns” träningsdata på sätt som är svåra att ta bort eller ändra. RAG-system erbjuder en annan säkerhetsprofil: kunskapen finns i externa, reviderbara datakällor istället för modellparametrar, vilket möjliggör tydliga säkerhetskontroller och åtkomstbegränsningar. Organisationer kan implementera detaljerade behörigheter på återhämtningskällor, spåra vilka dokument modellen hade tillgång till för varje svar och snabbt ta bort känslig information genom att uppdatera källdokument utan omträning. RAG innebär dock säkerhetsrisker kring skydd av vektordatabaser, säkerhet för inbäddningsmodeller och att säkerställa att återhämtade dokument inte läcker känslig information. Hälsoorganisationer som omfattas av HIPAA och europeiska företag som lyder under GDPR föredrar ofta RAG:s öppenhet och spårbarhet, medan organisationer som prioriterar modellportabilitet och offline-drift föredrar finjusteringens självförsörjande tillvägagångssätt.
Praktiskt beslutsramverk
Att välja mellan dessa tillvägagångssätt kräver utvärdering av specifika organisatoriska begränsningar och användningsfallsegenskaper. Organisationer bör prioritera finjustering när kunskap är stabil och osannolikt att förändras ofta, när inferenslatens är avgörande, när modeller måste fungera offline eller i isolerade miljöer, eller när konsekvent stil och domänspecifik formatering är viktig. Realtidsåterhämtning blir att föredra när kunskap förändras regelbundet, när källhänvisning och spårbarhet är viktiga för regelefterlevnad, när kunskapsbasen är för stor för att effektivt kodas i modellparametrar, eller när organisationer behöver uppdatera information utan att omträna modellen. Specifika användningsfall illustrerar dessa skillnader:
Finjustering: Kundservicebotar för stabil produktinformation, specialiserade medicinska diagnosassistenter, juridisk dokumentanalys för etablerad praxis
RAG: Nyhetssammanfattningssystem som kräver aktuell information, kundsupport med ofta uppdaterade produktkataloger, forskningsassistenter med tillgång till dynamisk vetenskaplig litteratur
Beslutsramverk: Utvärdera kunskapsstabilitet, krav på regelefterlevnad, latens, uppdateringsfrekvens och infrastrukturkapacitet
Hybrida tillvägagångssätt och kombinerade strategier
Hybrida tillvägagångssätt kombinerar finjustering och RAG för att få fördelar av båda strategierna samtidigt som individuella begränsningar mildras. Organisationer kan finjustera modeller på domänens grunder och kommunikationsmönster samtidigt som de använder RAG för att få tillgång till aktuell, detaljerad information—modellen lär sig hur man resonerar om en domän samtidigt som den hämtar vilka specifika fakta som ska ingå. Denna kombinerade strategi är särskilt effektiv för applikationer som kräver både specialiserad expertis och aktuell information: en finansiell rådgivningsbot finjusterad på investeringsprinciper och terminologi kan hämta realtidsdata om marknader och företagsfinanser via RAG. Hybrida implementationer i verkligheten inkluderar hälsosystem som finjusteras på medicinsk kunskap och protokoll medan de hämtar patientdata via RAG, samt juridiska forskningsplattformar som finjusteras på juridiskt resonemang medan de hämtar aktuell rättspraxis. Synergieffekterna inkluderar minskade hallucinationer (grundning i hämtade källor), förbättrad domänförståelse (från finjustering), snabbare inferens på vanliga frågor (cachad finjusterad kunskap) och flexibilitet att uppdatera specialiserad information utan omträning. Allt fler organisationer tillämpar denna optimering i takt med att datorkapaciteten ökar och verkliga applikationers komplexitet kräver både djup och aktualitet.
Övervakning av AI-svar och citeringsspårning
Förmågan att övervaka AI-svar i realtid blir allt viktigare när organisationer implementerar dessa optimeringsstrategier i stor skala, särskilt för att förstå vilket tillvägagångssätt som ger bäst resultat för specifika användningsfall. AI-övervakningssystem spårar modellutdata, återhämtningskvalitet och användarnöjdhetsmått, vilket gör att organisationer kan mäta om finjusterade modeller eller RAG-system bäst tjänar deras applikationer. Citeringsspårning avslöjar avgörande skillnader mellan tillvägagångssätten: RAG-system genererar naturligt citeringar och källhänvisningar, vilket skapar ett revisionsspår över vilka dokument som påverkat varje svar, medan finjusterade modeller inte har någon inbyggd mekanism för svarsövervakning eller attribuering. Denna skillnad är mycket viktig för varumärkessäkerhet och konkurrensanalys—organisationer behöver förstå hur AI-system citerar deras konkurrenter, refererar till deras produkter eller attribuerar information till källor. Verktyg som AmICited.com löser detta genom att övervaka hur AI-system citerar varumärken och företag över olika optimeringsstrategier och möjliggör realtidsuppföljning av citeringsmönster och frekvens. Genom att implementera omfattande övervakning kan organisationer mäta om deras valda optimeringsstrategi (finjustering, RAG eller hybrid) faktiskt förbättrar citeringsnoggrannheten, minskar hallucinationer om konkurrenter och upprätthåller korrekt attribuering till auktoritativa källor. Detta datadrivna förhållningssätt till övervakning möjliggör kontinuerlig förfining av optimeringsstrategier baserat på faktisk prestanda snarare än teoretiska förväntningar.
Framtida trender och framväxande mönster
Branschen utvecklas mot mer sofistikerade hybrida och adaptiva metoder som dynamiskt väljer mellan optimeringsstrategier baserat på frågans karaktär och kunskapskrav. Nya bästa praxis inkluderar implementering av retrieval-augmented finjustering, där modeller finjusteras på hur man effektivt använder hämtad information istället för att memorera fakta, samt adaptiva routingsystem som dirigerar frågor till finjusterade modeller för stabil kunskap och RAG-system för dynamisk information. Trender visar på ökad användning av specialiserade inbäddningsmodeller och vektordatabaser optimerade för specifika domäner, vilket möjliggör mer precis semantisk sökning och minskar återhämtningsbrus. Organisationer utvecklar mönster för kontinuerlig modellförbättring som kombinerar periodiska finjusteringsuppdateringar med realtids-RAG, vilket skapar system som förbättras över tid och samtidigt bibehåller tillgång till aktuell information. Utvecklingen av optimeringsstrategier återspeglar en bredare insikt om att ingen enskild metod optimalt tjänar alla användningsfall; framtidens system kommer troligen att implementera intelligenta urvalsmekanismer som dynamiskt väljer mellan finjustering, RAG och hybrida tillvägagångssätt baserat på frågekontext, kunskapsstabilitet, latenskrav och regelefterlevnad. När dessa teknologier mognar kommer konkurrensfördelen att förskjutas från att välja en metod till att skickligt implementera adaptiva system som utnyttjar styrkorna i varje strategi.
Vanliga frågor
Vad är den största skillnaden mellan optimering av träningsdata och realtidsåterhämtning?
Optimering av träningsdata bäddar in kunskap direkt i modellens parametrar genom finjustering, vilket skapar statisk kunskap som förblir oförändrad efter träning. Realtidsåterhämtning håller kunskapen extern och hämtar relevant information dynamiskt vid inferens, vilket möjliggör tillgång till dynamisk information som kan ändras mellan förfrågningar. Den grundläggande skillnaden är när kunskapen integreras: optimering av träningsdata sker före driftsättning, medan realtidsåterhämtning sker vid varje inferensanrop.
När ska jag använda finjustering istället för RAG?
Använd finjustering när kunskap är stabil och osannolikt att förändras ofta, när inferenslatens är avgörande, när modeller måste fungera offline eller när konsekvent stil och domänspecifik formatering är viktigt. Finjustering är idealiskt för specialiserade uppgifter såsom medicinsk diagnos, juridisk dokumentanalys eller kundservice med stabil produktinformation. Finjustering kräver dock betydande initiala datorkapaciteter och blir opraktiskt när information förändras ofta.
Kan jag kombinera optimering av träningsdata med realtidsåterhämtning?
Ja, hybrida tillvägagångssätt kombinerar finjustering och RAG för att få fördelar av båda strategierna. Organisationer kan finjustera modeller på domänens grunder samtidigt som de använder RAG för att få tillgång till aktuell, detaljerad information. Detta tillvägagångssätt är särskilt effektivt för applikationer som kräver både specialiserad expertis och aktuell information, såsom finansiella rådgivningsbotar eller hälsosystem som behöver både medicinsk kunskap och patient-specifik data.
Hur minskar RAG hallucinationer jämfört med finjustering?
RAG minskar avsevärt hallucinationer genom att grunda svaren i hämtade dokument—modellen kan inte hävda information som inte finns i källmaterialet, vilket skapar naturliga begränsningar för fabricering. Finjusterade modeller kan däremot självsäkert generera trovärdigt men felaktig information när de möter frågor utanför sin träningsdistribution. RAG:s källhänvisning möjliggör också verifiering av påståenden, medan finjusterade modeller inte kan peka ut specifika källor för sin kunskap.
Vilka är kostnadsimplikationerna för varje tillvägagångssätt?
Finjustering kräver betydande initiala kostnader: GPU-timmar ($10,000-$100,000+ per modell), dataannotering ($0,50-$5 per exempel) och ingenjörstid. När modellen är tränad är driftskostnaderna relativt låga. RAG-system har lägre initiala kostnader men löpande infrastrukturskostnader för vektordatabaser, inbäddningsmodeller och hämtningsservrar. Finjusterade modeller skalar linjärt med inferensvolymen, medan RAG-system skalar med både inferensvolym och kunskapsbasens storlek.
Hur hjälper realtidsåterhämtning till med AI-citeringsspårning?
RAG-system genererar naturligt citeringar och källhänvisningar, vilket skapar ett revisionsspår över vilka dokument som påverkat varje svar. Detta är avgörande för varumärkessäkerhet och konkurrensanalys—organisationer kan spåra hur AI-system citerar deras konkurrenter och refererar till deras produkter. Verktyg som AmICited.com övervakar hur AI-system citerar varumärken över olika optimeringsstrategier och tillhandahåller realtidsuppföljning av citeringsmönster och frekvens.
Vilket tillvägagångssätt är bäst för branscher med höga regelefterlevnadskrav?
RAG är generellt bättre för branscher med höga regelefterlevnadskrav som sjukvård och finans. Kunskapen förblir i externa, reviderbara datakällor istället för modellparametrar, vilket möjliggör tydliga säkerhetskontroller och åtkomstbegränsningar. Organisationer kan implementera detaljerade behörigheter, granska vilka dokument modellen hade tillgång till och snabbt ta bort känslig information utan omträning. Hälso- och sjukvård som regleras av HIPAA och GDPR-företag föredrar ofta RAG:s transparens och spårbarhet.
Hur övervakar jag effektiviteten av min valda optimeringsstrategi?
Implementera AI-övervakningssystem som spårar modellutdata, återhämtningskvalitet och användarnöjdhetsmått. För RAG-system, övervaka återhämtningsprecision och citeringskvalitet. För finjusterade modeller, följ noggrannhet på domänspecifika uppgifter och hallucinationsfrekvens. Använd verktyg som AmICited.com för att övervaka hur dina AI-system citerar information och jämför prestanda mellan olika optimeringsstrategier baserat på faktiska resultat.
Övervaka hur AI-system citerar ditt varumärke
Spåra citeringar i realtid över GPTs, Perplexity och Google AI Overviews. Förstå vilka optimeringsstrategier dina konkurrenter använder och hur de refereras i AI-svar.
Träningsdata vs live-sök i AI – vad ska jag egentligen optimera för?
Diskussion i communityn om skillnaden mellan AI-träningsdata och live-sök (RAG). Praktiska strategier för att optimera innehåll för både statiska träningsdata o...
Träningsdata vs Livesökning: Hur AI-system får tillgång till information
Förstå skillnaden mellan AI-träningsdata och livesökning. Lär dig hur kunskapsstopp, RAG och hämtning i realtid påverkar AI-synlighet och innehållsstrategi....
Hur du optimerar ditt innehåll för AI-träningsdata och AI-sökmotorer
Lär dig hur du optimerar ditt innehåll för inkludering i AI-träningsdata. Upptäck bästa praxis för att göra din webbplats upptäckbar av ChatGPT, Gemini, Perplex...
9 min läsning
Cookie-samtycke Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.