
Vad är vektorsökning och hur fungerar det?
Lär dig hur vektorsökning använder maskininlärningsinbäddningar för att hitta liknande objekt baserat på betydelse snarare än exakta nyckelord. Förstå vektordat...
7 min läsning

Lär dig hur vektorembeddningar gör det möjligt för AI-system att förstå semantisk betydelse och matcha innehåll med sökfrågor. Utforska teknologin bakom semantisk sökning och AI-innehållsmatchning.

Vektorembeddningar är den numeriska grunden som driver moderna artificiella intelligenssystem och omvandlar rådata till matematiska representationer som maskiner kan förstå och bearbeta. I grunden omvandlar embeddningar text, bilder, ljud och andra innehållstyper till talarrayer—vanligtvis med dussintals till tusentals dimensioner—som fångar den semantiska betydelsen och kontextuella relationer inom den datan. Denna numeriska representation är avgörande för hur AI-system utför innehållsmatchning, semantisk sökning och rekommendationsuppgifter, vilket gör det möjligt för maskiner att förstå inte bara vilka ord eller bilder som finns, utan vad de faktiskt betyder. Utan embeddningar skulle AI-system ha svårt att förstå nyanserade relationer mellan begrepp, vilket gör dem till en nödvändig infrastruktur för alla moderna AI-applikationer.
Omvandlingen från rådata till vektorembeddningar åstadkoms genom sofistikerade neurala nätverksmodeller som tränats på massiva datamängder för att lära sig meningsfulla mönster och samband. När du matar in text i en embeddningsmodell passerar den genom flera lager av neurala nätverk som successivt extraherar semantisk information och till slut producerar en vektor med fast storlek som fångar innehållets essens. Populära embeddningsmodeller som Word2Vec, GloVE och BERT använder olika tillvägagångssätt—Word2Vec använder grunda neurala nätverk optimerade för hastighet, GloVE kombinerar global matrisfaktorisering med lokala kontextfönster, medan BERT utnyttjar transformerarkitektur för att förstå tvåvägskontext.
| Modell | Datatyp | Dimensioner | Primärt användningsområde | Viktig fördel |
|---|---|---|---|---|
| Word2Vec | Text (ord) | 100-300 | Ordsamband | Snabb, effektiv |
| GloVE | Text (ord) | 100-300 | Semantiska relationer | Kombinerar global och lokal kontext |
| BERT | Text (meningar/dokument) | 768-1024 | Kontextuell förståelse | Tvåvägskontext |
| Sentence-BERT | Text (meningar) | 384-768 | Meningslikhet | Optimerad för semantisk sökning |
| Universal Sentence Encoder | Text (meningar) | 512 | Flerspråkiga uppgifter | Språkoberoende |
Dessa modeller producerar högdimensionella vektorer (ofta 300 till 1 536 dimensioner), där varje dimension fångar olika aspekter av betydelse, från grammatiska egenskaper till konceptuella relationer. Skönheten med denna numeriska representation är att den möjliggör matematiska operationer—du kan addera, subtrahera och jämföra vektorer för att upptäcka samband som skulle vara osynliga i råtext. Denna matematiska grund gör semantisk sökning och intelligent innehållsmatchning möjlig i stor skala.
Den verkliga styrkan med embeddningar framträder genom semantisk likhet, förmågan att känna igen att olika ord eller fraser i vektorrummet i grunden kan betyda samma sak. När embeddningar skapas effektivt klustras semantiskt liknande begrepp naturligt i det högdimensionella rummet—“kung” och “drottning” ligger nära varandra, likaså “bil” och “fordon”, även om de är olika ord. För att mäta denna likhet använder AI-system avståndsmått som cosinuslikhet (mäter vinkeln mellan vektorer) eller skalärprodukt (mäter storlek och riktning), vilka kvantifierar hur nära två embeddningar är varandra. Till exempel skulle en sökfråga om “biltransport” ha hög cosinuslikhet med dokument om “bilresor”, vilket gör att systemet kan matcha innehåll baserat på betydelse snarare än exakt nyckelords-matchning. Denna semantiska förståelse är det som skiljer modern AI-sökning från enkel nyckelords-matchning och möjliggör system som förstår användarintention och levererar genuint relevanta resultat.
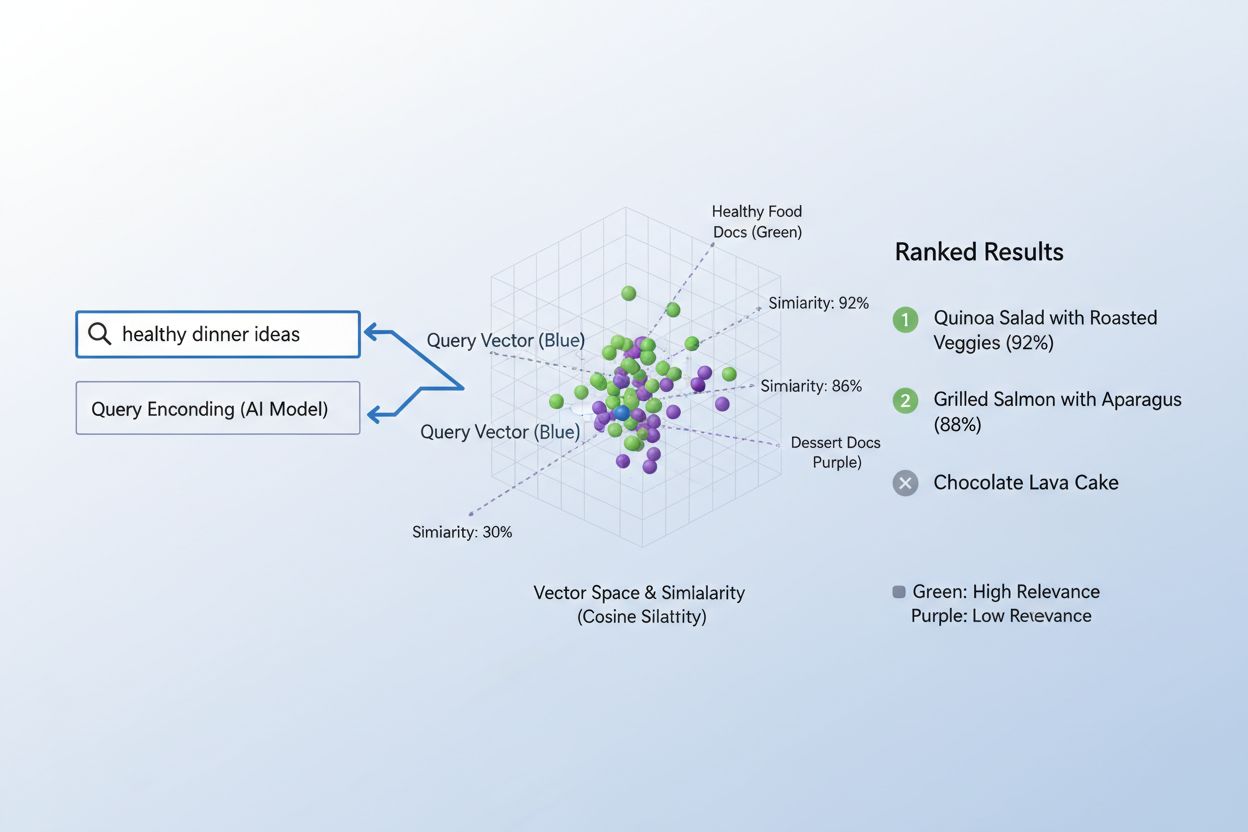
Processen att matcha innehåll med sökfrågor med hjälp av embeddningar följer ett elegant tvåstegsflöde som driver allt från sökmotorer till rekommendationssystem. Först omvandlas både användarens sökfråga och det tillgängliga innehållet oberoende till embeddningar med samma modell—en fråga som “bästa praxis för maskininlärning” blir en vektor, liksom varje artikel, dokument eller produkt i systemets databas. Därefter beräknar systemet likheten mellan sökfråge-embeddningen och varje innehållsembeddning, vanligtvis med cosinuslikhet, vilket ger ett poängvärde för hur relevant varje innehåll är för frågan. Dessa likhetspoäng rangordnas, och det innehåll med högst poäng presenteras för användaren som de mest relevanta resultaten. I ett verkligt sökmotorscenario, när du söker efter “hur man tränar neurala nätverk”, kodar systemet din fråga, jämför den mot miljontals dokumentembeddningar och returnerar artiklar om djupinlärning, modelloptimering och träningsmetoder—alltsammans utan att kräva exakta nyckelords-matchningar. Denna matchningsprocess sker på millisekunder, vilket gör det praktiskt för realtidsapplikationer som betjänar miljontals användare samtidigt.
Olika typer av embeddningar tjänar olika syften beroende på vad du försöker matcha eller förstå. Ordemeddningar fångar betydelsen av enskilda ord och fungerar bra för uppgifter som kräver detaljerad semantisk förståelse, medan meningsembeddningar och dokumentembeddningar sammanfattar betydelsen över längre textstycken, vilket gör dem idealiska för att matcha hela sökfrågor mot fullständiga artiklar eller dokument. Bildembeddningar representerar visuellt innehåll numeriskt, vilket gör det möjligt för system att hitta visuellt liknande bilder eller matcha bilder mot textbeskrivningar, medan användar- och produkt-embeddningar fångar beteendemönster och egenskaper och driver rekommendationssystem som föreslår objekt baserat på användarpreferenser. Valet mellan dessa embeddningstyper innebär avvägningar: ordembeddningar är beräkningsmässigt effektiva men tappar kontext, medan dokumentembeddningar bevarar hela betydelsen men kräver mer processorkraft. Domänspecifika embeddningar, finjusterade på specialiserade datamängder som medicinsk litteratur eller juridiska dokument, överträffar ofta allmänna modeller för branschspecifika applikationer, även om de kräver ytterligare träningsdata och datorkraft.
I praktiken driver embeddningar några av de mest inflytelserika AI-applikationer vi använder dagligen, från de sökresultat du ser till de produkter som rekommenderas för dig online. Semantiska sökmotorer använder embeddningar för att förstå sökintention och lyfta fram relevant innehåll oavsett exakta nyckelord, medan rekommendationssystem hos Netflix, Amazon och Spotify utnyttjar användar- och objektsembeddningar för att förutsäga vad du vill titta på, köpa eller lyssna på härnäst. Innehållsmoderationssystem använder embeddningar för att upptäcka skadligt innehåll genom att jämföra användargenererade inlägg mot embeddningar av kända policyöverträdelser, medan frågesvarsystem matchar användarfrågor med relevanta kunskapsartiklar genom att hitta semantiskt liknande innehåll. Personaliseringstjänster använder embeddningar för att förstå användarpreferenser och skräddarsy upplevelser, och avvikelsedetekteringssystem identifierar ovanliga mönster genom att känna igen när nya datapunkter ligger långt från förväntade embeddningskluster. På AmICited använder vi embeddningar för att övervaka hur AI-system används över internet, matcha användarfrågor och innehåll för att spåra var AI-genererat eller AI-assisterat innehåll förekommer, hjälpa varumärken att förstå sitt AI-avtryck och säkerställa korrekt attribuering.
Att implementera embeddningar effektivt kräver noggrann uppmärksamhet på flera tekniska faktorer som påverkar både prestanda och kostnad. Modellval är avgörande—du måste balansera den semantiska kvaliteten på embeddningar mot beräkningskraven, där större modeller som BERT ger rikare representationer men kräver mer processorkraft än lättare alternativ. Dimensionalitet innebär en central avvägning: högre dimensioner fångar mer nyans men förbrukar mer minne och saktar ner likhetsberäkningar, medan lägre dimensioner är snabbare men kan förlora viktig semantisk information. För att hantera storskalig matchning effektivt används specialiserade indexeringsstrategier som FAISS (Facebook AI Similarity Search) eller Annoy (Approximate Nearest Neighbors Oh Yeah), vilka gör det möjligt att hitta liknande embeddningar på millisekunder istället för sekunder genom att organisera vektorer i trädstrukturer eller lokalitetssensitiva hashfunktioner. Finjustering av embeddningsmodeller på domänspecifik data kan dramatiskt förbättra relevans för specialiserade applikationer, men kräver märkta träningsdata och ytterligare beräkningsresurser. Organisationer måste ständigt balansera hastighet mot noggrannhet, beräkningskostnad mot semantisk kvalitet, och allmänna modeller mot specialiserade alternativ utifrån sina specifika användningsfall och begränsningar.
Framtiden för embeddningar går mot större sofistikering, effektivitet och integration med bredare AI-system, vilket lovar ännu kraftfullare innehållsmatchning och förståelse. Multimodala embeddningar som samtidigt bearbetar text, bilder och ljud är på frammarsch och gör det möjligt för system att matcha över olika innehållstyper—hitta bilder som är relevanta för textfrågor eller tvärtom—och öppnar helt nya möjligheter för innehållsupptäckt och förståelse. Forskare utvecklar allt effektivare embeddningsmodeller som levererar jämförbar semantisk kvalitet med betydligt färre parametrar, vilket gör avancerad AI tillgänglig även för mindre organisationer och edge-enheter. Integrationen av embeddningar med stora språkmodeller skapar system som inte bara kan matcha innehåll semantiskt utan också förstå kontext, nyans och intention på en aldrig tidigare skådad nivå. I takt med att AI-system blir allt vanligare på internet blir förmågan att spåra, övervaka och förstå hur innehåll matchas och används allt viktigare—det är här plattformar som AmICited utnyttjar embeddningar för att hjälpa organisationer övervaka sitt varumärkesnärvaro, följa AI-användningsmönster och säkerställa att deras innehåll attribueras och används på rätt sätt. Konvergensen av bättre embeddningar, effektivare modeller och sofistikerade övervakningsverktyg skapar en framtid där AI-system är mer transparenta, ansvarstagande och i linje med mänskliga värderingar.
En vektorembeddning är en numerisk representation av data (text, bilder, ljud) i ett högdimensionellt utrymme som fångar semantisk betydelse och relationer. Den omvandlar abstrakt data till talarrayer som maskiner kan bearbeta och analysera matematiskt.
Embeddningar omvandlar abstrakt data till siffror som maskiner kan bearbeta, vilket gör det möjligt för AI att identifiera mönster, likheter och relationer mellan olika delar av innehåll. Denna matematiska representation gör att AI-system kan förstå betydelse snarare än att bara matcha nyckelord.
Nyckelords-matchning letar efter exakta ord, medan semantisk likhet förstår betydelse. Detta gör att system kan hitta relaterat innehåll även utan identiska ord—till exempel matchas 'bil' med 'automobil' baserat på semantisk relation snarare än exakt textmatchning.
Ja, embeddningar kan representera text, bilder, ljud, användarprofiler, produkter och mer. Olika embeddningsmodeller är optimerade för olika datatyper, från Word2Vec för text till CNN:er för bilder till spektrogram för ljud.
AmICited använder embeddningar för att förstå hur AI-system semantiskt matchar och refererar till ditt varumärke över olika AI-plattformar och svar. Detta hjälper till att spåra ditt innehålls närvaro i AI-genererade svar och säkerställer korrekt attribuering.
Viktiga utmaningar inkluderar att välja rätt modell, hantera beräkningskostnader, hantera högdimensionell data, finjustera för specifika domäner och balansera hastighet mot noggrannhet i likhetsberäkningar.
Embeddningar möjliggör semantisk sökning, som förstår användarens avsikt och returnerar relevanta resultat baserat på betydelse snarare än bara nyckelordsmatchning. Detta gör att söksystem kan hitta innehåll som är konceptuellt relaterat även om det inte innehåller exakta söktermer.
Stora språkmodeller använder embeddningar internt för att förstå och generera text. Embeddningar är grundläggande för hur dessa modeller bearbetar information, matchar innehåll och genererar kontextuellt lämpliga svar.
Vektorembeddningar driver AI-system som ChatGPT, Perplexity och Google AI Overviews. AmICited spårar hur dessa system citerar och refererar till ditt innehåll, vilket hjälper dig att förstå ditt varumärkes närvaro i AI-genererade svar.
Lär dig hur vektorsökning använder maskininlärningsinbäddningar för att hitta liknande objekt baserat på betydelse snarare än exakta nyckelord. Förstå vektordat...
Diskussion i communityt om vektorsökning och hur den driver AI:s upptäckt av innehåll. Riktiga erfarenheter från tekniska marknadsförare om att optimera innehål...

Vektorsökning använder matematiska vektorrepresentationer för att hitta liknande data genom att mäta semantiska relationer. Lär dig hur inbäddningar, avståndsmå...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.