Vad är informationssökintention för AI? Definition och exempel
Lär dig vad informationssökintention betyder för AI-system, hur AI känner igen dessa frågor och varför förståelse för denna intention är viktig för synlighet i ...
11 min läsning
Lär dig hur stora språkmodeller tolkar användarintention bortom nyckelord. Upptäck frågeexpansion, semantisk förståelse och hur AI-system avgör vilket innehåll som citeras i svar.
Användarintention i AI-sök syftar på det underliggande målet eller syftet bakom en fråga, snarare än bara de nyckelord någon skriver in. När du söker efter “bästa projektledningsverktyg” kan du vara ute efter en snabb jämförelse, prisinformation eller integrationsmöjligheter—och stora språkmodeller (LLM:er) som ChatGPT, Perplexity och Googles Gemini arbetar för att förstå vilket av dessa mål du faktiskt eftersträvar. Till skillnad från traditionella sökmotorer som matchar nyckelord mot sidor, tolkar LLM:er den semantiska betydelsen av din fråga genom att analysera kontext, formulering och relaterade signaler för att förutsäga vad du verkligen vill uppnå. Denna övergång från nyckelords-matchning till intentionsförståelse är grundläggande för hur moderna AI-söksystem fungerar, och det avgör direkt vilka källor som citeras i AI-genererade svar. Att förstå användarintention har blivit avgörande för varumärken som vill synas i AI-sökresultat, eftersom verktyg som AmICited nu övervakar hur AI-system refererar till ditt innehåll utifrån intentionsöverensstämmelse.
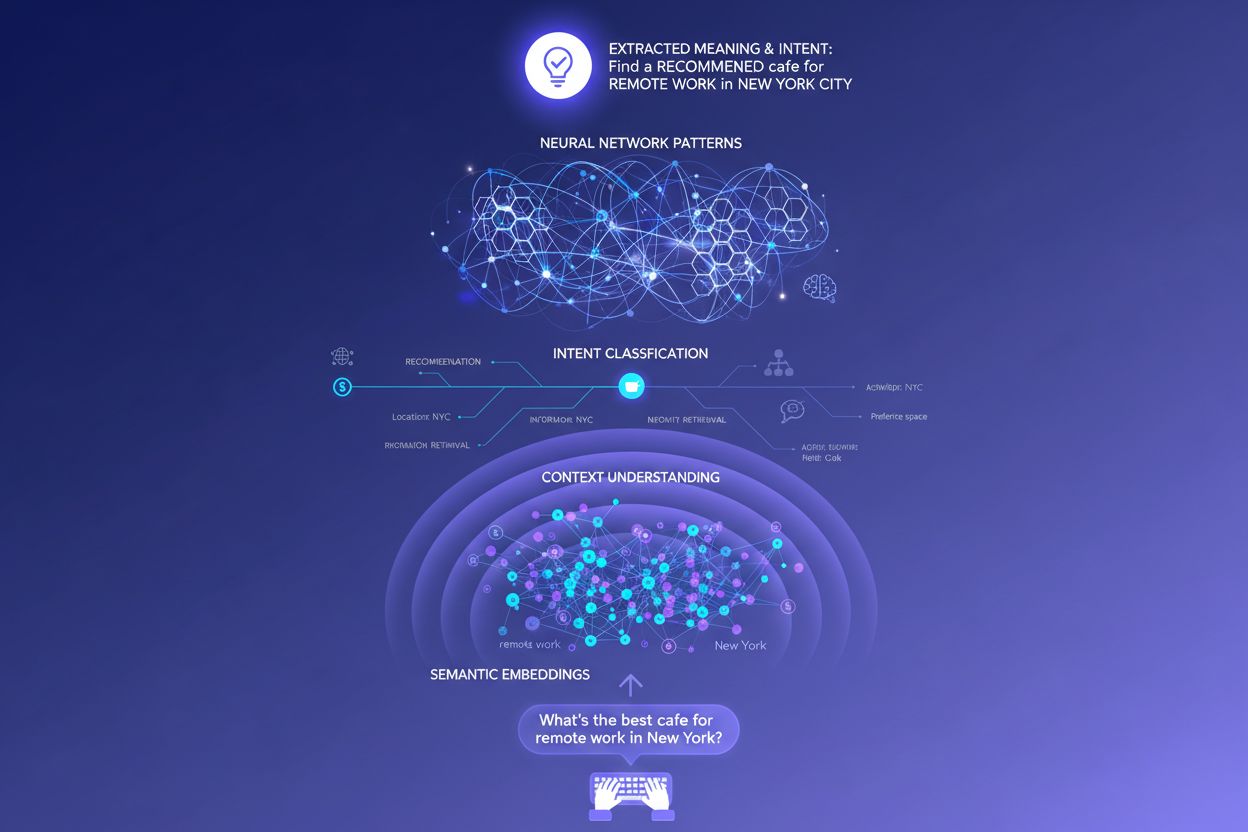
När du skriver in en enda fråga i ett AI-söksystem händer något anmärkningsvärt bakom kulisserna: modellen svarar inte bara direkt på din fråga. Istället expanderar den din fråga till dussintals relaterade mikrosaker, en process som forskare kallar “query fan-out”. Till exempel kan en enkel sökning som “Notion vs Trello” trigga underfrågor som “Vilket är bäst för teamsamarbete?”, “Vad är skillnaden i pris?”, “Vilket integrerar bäst med Slack?” och “Vad är enklast för nybörjare?” Denna expansion gör att LLM:er kan utforska olika vinklar av din intention och samla in mer heltäckande information innan svaret genereras. Systemet utvärderar avsnitt från olika källor på en detaljerad nivå, istället för att ranka hela sidor, vilket innebär att ett enda stycke från ditt innehåll kan väljas ut medan resten av din sida ignoreras. Denna analys på avsnittsnivå är anledningen till att tydlighet och specifikhet i varje sektion är viktigare än någonsin—ett välstrukturerat svar på en specifik underintention kan vara anledningen till att ditt innehåll hamnar i ett AI-genererat svar.
| Ursprunglig fråga | Underintention 1 | Underintention 2 | Underintention 3 | Underintention 4 |
|---|---|---|---|---|
| “Bästa projektledningsverktyg” | “Vilket är bäst för distansteam?” | “Vad kostar det?” | “Vilket integreras med Slack?” | “Vad är enklast för nybörjare?” |
| “Hur förbättra produktiviteten” | “Vilka verktyg hjälper med tidshantering?” | “Vilka är beprövade produktivitetsmetoder?” | “Hur minska distraktioner?” | “Vilka vanor ökar fokus?” |
| “AI-sökmotorer förklarade” | “Hur skiljer de sig från Google?” | “Vilken AI-sök är mest exakt?” | “Hur hanterar de integritet?” | “Vad är framtiden för AI-sök?” |
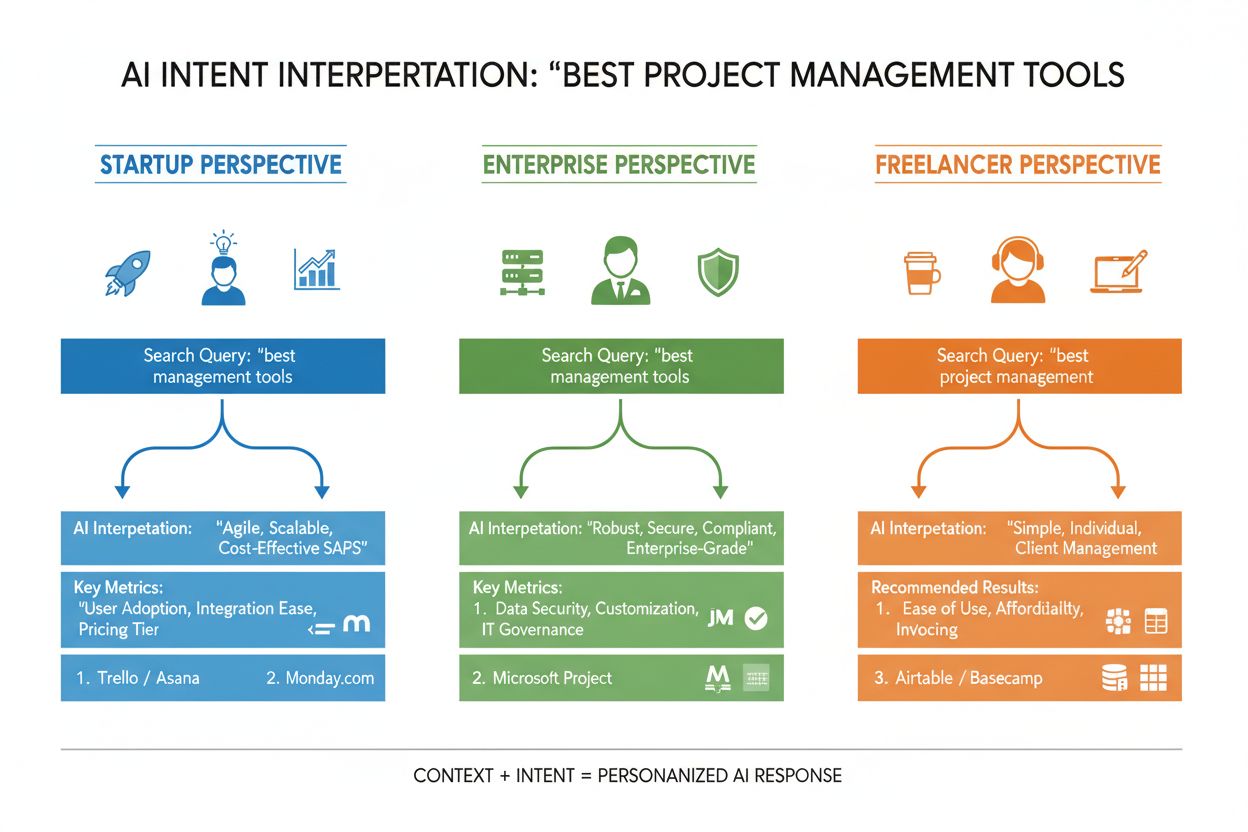
LLM:er utvärderar inte din fråga isolerat—de bygger det forskare kallar en “användarinbäddning,” en vektorbaserad profil som fångar din föränderliga intention baserat på sökhistorik, plats, enhetstyp, tid på dygnet och till och med tidigare konversationer. Denna kontextuella förståelse gör att systemet kan personanpassa resultat dramatiskt: två användare som söker efter “bästa CRM-verktyg” kan få helt olika rekommendationer om den ena är startupgrundare och den andra företagschef. Omdirankning i realtid förfinar ytterligare resultaten baserat på hur du interagerar med dem—om du klickar på vissa resultat, läser specifika avsnitt eller ställer följdfrågor, justerar systemet sin förståelse av din intention och uppdaterar framtida rekommendationer därefter. Denna beteendeloop innebär att AI-system ständigt lär sig vad användare faktiskt vill, inte bara vad de initialt skrev. För innehållsskapare och marknadsförare understryker detta vikten av att skapa innehåll som tillfredsställer intentionen över flera användarkontexter och beslutsstadier.
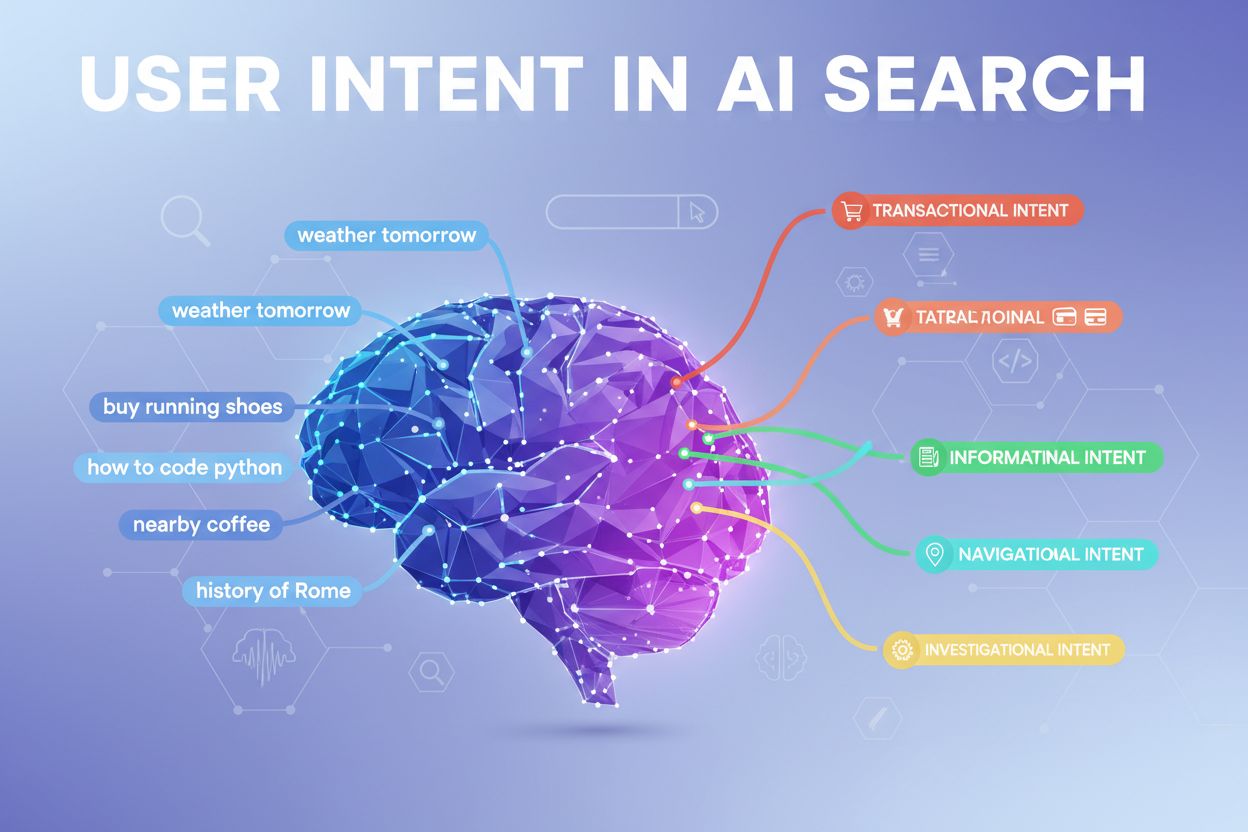
Moderna AI-system klassificerar användarintention i flera distinkta kategorier, som alla kräver olika typer av innehåll och svar:
LLM:er klassificerar automatiskt dessa intentioner genom att analysera frågestruktur, nyckelord och kontextuella signaler, och väljer sedan det innehåll som bäst matchar den upptäckta intentionskategorin. Att förstå dessa kategorier hjälper innehållsskapare att strukturera sina sidor för att möta den specifika intentionen användarna har med sina sökningar.
Traditionella sökmotorer baserade på nyckelord fungerar genom enkel strängmatchning—om din sida innehåller exakt de ord någon söker på, kan den rankas. Detta misslyckas totalt med synonymer, omformuleringar och kontext. Om någon söker “prisvärd projektledningsprogramvara” och din sida använder frasen “budgetvänlig plattform för uppgiftshantering”, kan traditionell sök missa kopplingen helt. Semantiska inbäddningar löser detta genom att konvertera ord och fraser till matematiska vektorer som fångar betydelse snarare än bara text. Dessa vektorer existerar i ett högdimensionellt rum där semantiskt liknande begrepp klustrar ihop sig, vilket gör att LLM:er kan känna igen att “prisvärd”, “budgetvänlig”, “billig” och “lågkostnad” alla uttrycker samma intention. Detta semantiska tillvägagångssätt hanterar även långa och konversationella frågor mycket bättre än nyckelords-matchning—en fråga som “Jag är frilansare och behöver något enkelt men kraftfullt” kan matchas mot relevant innehåll även om den inte innehåller några traditionella nyckelord. Det praktiska resultatet är att AI-system kan visa relevanta svar på vaga, komplexa eller ovanliga frågor, vilket gör dem mycket mer användbara än sina nyckelordsbaserade föregångare.
I den tekniska kärnan av intentionsinterpretation ligger transformatorarkitekturen, en neuronnätsdesign som bearbetar språk genom att analysera relationer mellan ord via en mekanism som kallas “attention”. Istället för att läsa text sekventiellt som en människa, utvärderar transformatorer hur varje ord relaterar till alla andra ord i en fråga, vilket gör att de kan fånga nyanserad mening och kontext. Semantiska inbäddningar är de numeriska representationer som uppstår från denna process—varje ord, fras eller begrepp omvandlas till en vektor av siffror som kodar dess betydelse. Modeller som BERT (Bidirectional Encoder Representations from Transformers) och RankBrain använder dessa inbäddningar för att förstå att “bästa CRM för startups” och “topp kundrelationsplattform för nya företag” uttrycker liknande intention, även om de använder helt olika ord. Attention-mekanismen är särskilt kraftfull eftersom den gör att modellen kan fokusera på de mest relevanta delarna av en fråga—i “bästa projektledningsverktyg för distansteam med begränsad budget”, lär sig systemet att väga in “distansteam” och “begränsad budget” som avgörande intentionssignaler. Denna tekniska sofistikering är anledningen till att modern AI-sök känns så mycket smartare än traditionella nyckelordsbaserade system.
Att förstå hur LLM:er tolkar intention förändrar innehållsstrategin i grunden. Istället för att skriva en omfattande guide som försöker ranka för ett enda nyckelord, adresserar framgångsrikt innehåll nu flera underintentioner i modulära sektioner som kan stå på egna ben. Om du skriver om projektledningsverktyg, skapa istället distinkta avsnitt som besvarar “Vilket är bäst för distansteam?”, “Vilket är det mest prisvärda alternativet?” och “Vilket integreras med Slack?"—varje avsnitt blir ett potentiellt svarskort som LLM:er kan extrahera och citera. Citeringsklar formatering är mycket viktigt: använd fakta istället för vaga påståenden, inkludera specifika siffror och datum och strukturera informationen så att det är enkelt för AI-system att citera eller sammanfatta. Punktlistor, tydliga rubriker och korta stycken hjälper LLM:er att tolka ditt innehåll mer effektivt än tät text. Verktyg som AmICited gör det nu möjligt för marknadsförare att övervaka hur AI-system refererar till deras innehåll i ChatGPT, Perplexity och Google AI, och visar vilka intentionsöverensstämmelser som fungerar och var det finns innehållsluckor. Detta datadrivna angreppssätt på innehållsstrategi—att optimera för hur AI-system faktiskt tolkar och citerar ditt arbete—representerar ett grundläggande skifte från traditionell SEO.
Tänk på ett e-handelsexempel: när någon söker “vattentät jacka under 2000 kr” uttrycker de flera intentioner samtidigt—de vill ha information om hållbarhet, prisbekräftelse och produktrekommendationer. Ett AI-system kan expandera detta till underfrågor om vattentätningsteknik, prisjämförelser, varumärkesrecensioner och garantivillkor. Ett varumärke som täcker alla dessa vinklar i modulärt, välstrukturerat innehåll har mycket större chans att bli citerat i AI-genererade svar än en konkurrent med en generisk produktsida. Inom SaaS kan samma fråga “Hur bjuder jag in mitt team till detta arbetsutrymme?” dyka upp hundratals gånger i supportloggar, vilket signalerar ett viktigt innehållsgap. En AI-assistent tränad på din dokumentation kan ha svårt att svara tydligt på denna fråga, vilket leder till sämre användarupplevelse och minskad synlighet i AI-genererade supportsvar. Inom nyheter och information kommer en fråga som “Vad händer med AI-reglering?” tolkas olika beroende på användarkontext—en beslutsfattare kan behöva lagstiftningsdetaljer, en företagsledare konkurrensmässiga implikationer och en tekniker tekniska standarder. Framgångsrikt innehåll adresserar dessa olika intentionskontexter uttryckligen.
Trots sin sofistikation möter LLM:er verkliga utmaningar i intentionsinterpretation. Tvetydiga frågor som “Java” kan syfta på programmeringsspråket, ön eller kaffe—även med kontext kan systemet felaktigt klassificera intentionen. Blandade eller lager av intentioner komplicerar ytterligare: “Är detta CRM bättre än Salesforce och var kan jag testa det gratis?” kombinerar jämförelse, utvärdering och transaktionsintention i en fråga. Begränsningar i kontextfönstret innebär att LLM:er bara kan ta hänsyn till en viss mängd samtalshistorik, så i långa samtal kan tidigare intentionssignaler glömmas. Hallucinationer och faktamissar är fortfarande ett bekymmer, särskilt i områden som kräver hög noggrannhet som sjukvård, ekonomi eller juridisk rådgivning. Integritetshänsyn är också viktigt—när systemen samlar in mer beteendedata för att förbättra personalisering måste de balansera intentionsnoggrannhet mot användarens integritet. Att förstå dessa begränsningar hjälper innehållsskapare och marknadsförare att ha realistiska förväntningar på AI-synlighet i sök och inse att inte varje fråga kommer att tolkas perfekt.
Intentionbaserad sök utvecklas snabbt mot mer sofistikerad förståelse och interaktion. Konversationell AI kommer att bli alltmer naturlig, med system som bevarar kontext över längre, mer komplexa dialoger där intention kan skifta och utvecklas. Multimodal intentionsförståelse kommer att kombinera text, bilder, röst och till och med video för att tolka användarmål mer holistiskt—föreställ dig att be en AI-assistent “hitta något liknande detta” samtidigt som du visar ett foto. Sök utan fråga representerar en kommande gräns där AI-system förutser användarbehov innan de uttrycks, genom att använda beteendesignaler och kontext för att proaktivt visa relevant information. Förbättrad personalisering kommer göra resultaten allt mer anpassade efter individuella användarprofiler, beslutsstadier och kontextuella situationer. Integration med rekommendationssystem kommer sudda ut gränsen mellan sök och upptäckt, med AI-system som föreslår relevant innehåll användaren inte visste att de behövde söka efter. När dessa förmågor mognar kommer konkurrensfördelen alltmer att tillfalla varumärken och skapare som förstår intention på djupet och strukturerar sitt innehåll för att tillfredsställa den heltäckande över flera kontexter och användartyper.
Användarintention avser det underliggande målet eller syftet bakom en fråga, inte bara de skrivna nyckelorden. LLM:er tolkar semantisk mening genom att analysera kontext, formulering och relaterade signaler för att förutsäga vad användare verkligen vill uppnå. Därför kan samma fråga ge olika resultat beroende på användarens kontext och beslutsstadium.
LLM:er använder en process som kallas 'query fan-out' för att bryta ner en fråga i dussintals relaterade mikrosaker. Till exempel kan 'Notion vs Trello' expandera till underfrågor om samarbete, prissättning, integrationer och användarvänlighet. Detta gör att AI-system kan utforska olika vinklar av intentionen och samla in omfattande information.
Att förstå intention hjälper innehållsskapare att optimera för hur AI-system faktiskt tolkar och citerar deras arbete. Innehåll som adresserar flera underintentioner i modulära avsnitt väljs oftare av LLM:er. Detta påverkar direkt synligheten i AI-genererade svar i ChatGPT, Perplexity och Google AI.
Semantiska inbäddningar omvandlar ord och fraser till matematiska vektorer som fångar mening snarare än bara ytlig text. Detta gör att LLM:er kan känna igen att 'prisvärd', 'budgetvänlig' och 'billig' uttrycker samma intention, även om de använder olika ord. Detta semantiska tillvägagångssätt hanterar synonymer, omformuleringar och kontext mycket bättre än traditionell nyckelords-matchning.
Ja, LLM:er möter utmaningar med tvetydiga frågor, blandade intentioner och begränsningar i kontexten. Frågor som 'Java' kan syfta på programmeringsspråk, geografi eller kaffe. Långa konversationer kan överskrida kontextfönstret, vilket gör att tidigare intentionssignaler glöms bort. Att förstå dessa begränsningar hjälper till att sätta realistiska förväntningar på AI-synlighet i sök.
Varumärken bör skapa modulärt innehåll som adresserar flera underintentioner i separata avsnitt. Använd citeringsklar formatering med fakta, specifika siffror och tydlig struktur. Övervaka hur AI-system refererar till ditt innehåll med verktyg som AmICited för att identifiera luckor i intentionens överensstämmelse och optimera därefter.
Intention är uppgiftsfokuserad—vad användare vill uppnå just nu. Intresse är bredare allmän nyfikenhet. AI-system prioriterar intention eftersom det direkt avgör vilket innehåll som väljs ut till svar. En användare kan vara intresserad av produktivitetsverktyg generellt, men deras intention kan vara att hitta något specifikt för distansteamssamarbete.
AI-system citerar källor som bäst matchar den upptäckta intentionen. Om ditt innehåll tydligt adresserar en specifik underintention med välstrukturerad, faktabaserad information är det mer sannolikt att det väljs ut. Verktyg som AmICited spårar dessa citeringsmönster och visar vilka intentionsöverensstämmelser som driver synlighet i AI-genererade svar.
Förstå hur LLM:er refererar till ditt innehåll i ChatGPT, Perplexity och Google AI. Spåra intentionens överensstämmelse och optimera för AI-synlighet med AmICited.
Lär dig vad informationssökintention betyder för AI-system, hur AI känner igen dessa frågor och varför förståelse för denna intention är viktig för synlighet i ...
Lär dig identifiera och optimera för sökintention i AI-sökmotorer. Upptäck metoder för att klassificera användarfrågor, analysera AI-SERP:er och strukturera inn...
Lär dig identifiera och utnyttja AI-innehållsmöjligheter genom att övervaka varumärkesomnämnanden i ChatGPT, Perplexity och andra AI-plattformar. Upptäck strate...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.