AI-missinformationskorrigering
Lär dig identifiera och korrigera felaktig varumärkesinformation i AI-system som ChatGPT, Gemini och Perplexity. Upptäck övervakningsverktyg, korrigeringsstrate...
8 min läsning

Lär dig hur du kan begära rättelser från AI-plattformar som ChatGPT, Perplexity och Claude. Förstå korrigeringsmekanismer, feedbackprocesser och strategier för att påverka AI-genererade svar om ditt varumärke.
Även om du inte kan ta bort information direkt från AI:s träningsdata kan du begära rättelser genom feedbackmekanismer, åtgärda felaktigheter vid källan och påverka framtida AI-svar genom att skapa auktoritativt positivt innehåll och samarbeta med plattformarnas supportteam.
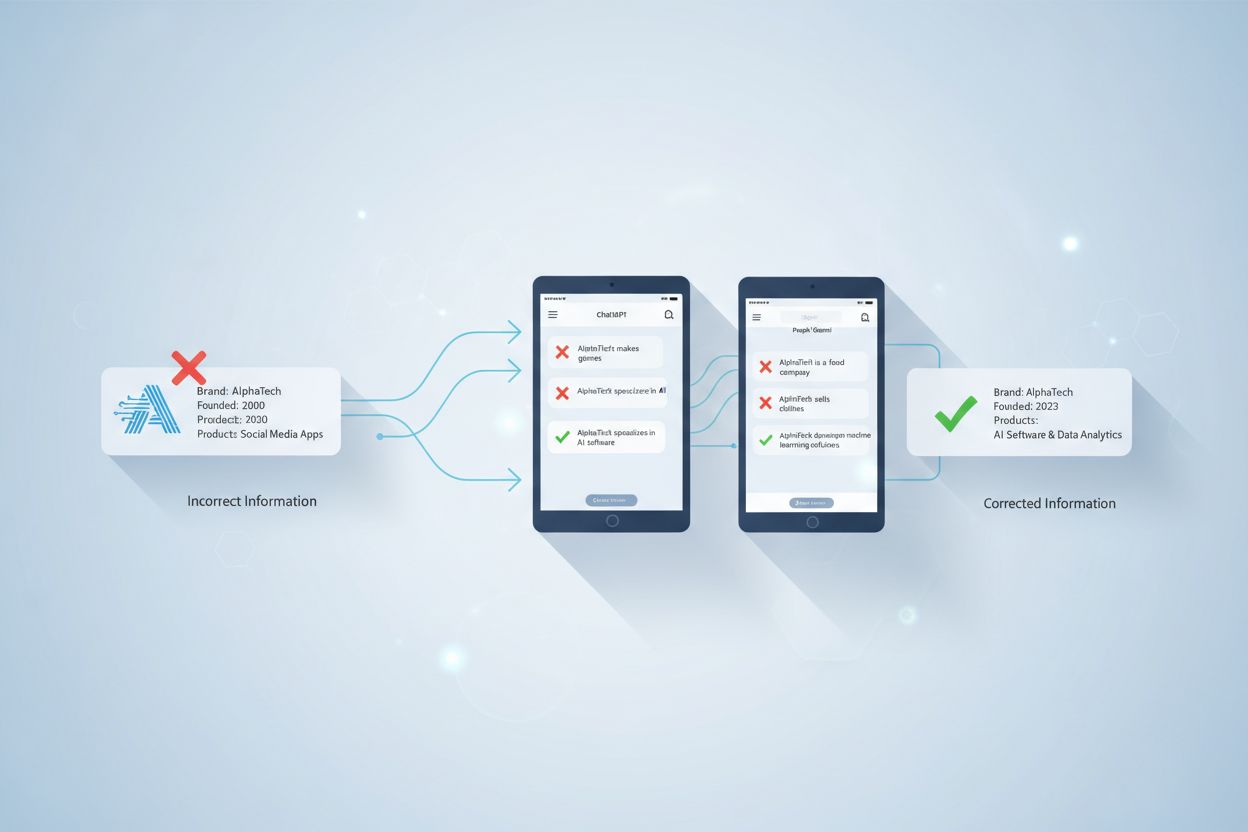
Att begära rättelser från AI-plattformar kräver förståelse för hur dessa system fungerar i grunden. Till skillnad från traditionella sökmotorer, där du kan kontakta en webbplatsägare för att ta bort eller uppdatera innehåll, lär sig AI-språkmodeller från träningsdata under specifika träningsfaser och inkluderar miljarder webbsidor, nyhetsartiklar och textkällor. När negativ eller felaktig information väl har blivit en del av träningsdatan kan du inte direkt radera eller redigera den som du kanske skulle begära från en webbplatsägare. AI:n har redan lärt sig mönster och samband från flera källor under sin träningscykel.
Korrigeringsprocessen skiljer sig avsevärt mellan statiska och realtidsbaserade AI-system. Statiska modeller som GPT-4 är tränade på data upp till ett specifikt stoppdatum (t.ex. december 2023 för GPT-4-turbo), och när de väl är tränade behåller de den kunskapen tills nästa träningscykel. Realtidsbaserade AI-system som Perplexity och Claude.ai hämtar innehåll direkt från webben, vilket innebär att rättelser vid källan kan få omedelbara effekter på deras svar. Att förstå vilken typ av AI-plattform du har att göra med är avgörande för att avgöra den mest effektiva korrigeringsstrategin.
De flesta större AI-plattformar erbjuder inbyggda feedbackmekanismer som låter användare rapportera felaktigheter. ChatGPT har till exempel tummar upp och tummar ner-knappar på svar, vilket gör det möjligt för användare att flagga problematiska svar. När du ger negativ feedback på ett felaktigt svar samlas denna information in och analyseras av plattformens team. Dessa feedback-loopar hjälper AI-systemen att finjustera sin prestanda genom att lära sig av utfall – både lyckade och misslyckade. Den feedback du skickar in blir en del av de data som utvecklarna använder för att identifiera mönster i fel och förbättra modellens noggrannhet.
Perplexity och Claude erbjuder liknande feedbackalternativ i sina gränssnitt. Du kan vanligtvis rapportera när ett svar är felaktigt, vilseledande eller innehåller föråldrad information. Vissa plattformar låter dig ange specifika rättelser eller förtydliganden. Effektiviteten av denna feedback beror på hur många användare som rapporterar samma problem och hur betydande felaktigheten är. Plattformar prioriterar rättelser för utbredda problem som påverkar många användare, så om flera personer rapporterar samma felaktighet om ditt varumärke är det mer troligt att plattformen utreder och åtgärdar det.
Den mest effektiva långsiktiga strategin för att rätta AI-genererad felinformation är att åtgärda den ursprungliga källan till felaktig information. Eftersom AI-system lär sig från webb-innehåll, nyhetsartiklar, Wikipedia-poster och annat publicerat material, påverkar rättelser vid dessa källor hur AI-plattformar kommer att presentera information i framtida träningscykler. Begär rättelser eller uppdateringar från de ursprungliga utgivarna där felaktig information förekommer. Om ett nyhetsmedium publicerat felaktig information om ditt varumärke, kontakta deras redaktion med bevis på felaktigheten och begär en rättelse eller ett förtydligande.
Wikipedia utgör en särskilt viktig källa för AI:s träningsdata. Om felaktig information om ditt varumärke eller din domän förekommer på Wikipedia, arbeta inom plattformens korrekta redaktionella kanaler för att åtgärda det. Wikipedia har specifika processer för att bestrida information och begära rättelser, men du måste följa deras riktlinjer för neutralitet och verifierbarhet. Höga auktoritets-källor som Wikipedia, större nyhetsorganisationer, utbildningsinstitutioner och myndighetssidor väger tungt i AI:s träningsdatan. Rättelser som görs i dessa källor har större sannolikhet att integreras i framtida AI-modelluppdateringar.
För föråldrad eller felaktig information på din egen webbplats eller kontrollerade egendomar, se till att du uppdaterar eller tar bort den omgående. Dokumentera alla ändringar du gör, eftersom dessa uppdateringar kan inkluderas i framtida omträningscykler. När du rättar information på din egen domän förser du AI-systemen med mer korrekt källmaterial att lära av i framtiden.
Istället för att enbart fokusera på att ta bort negativ eller felaktig information, utveckla starka motnarrativ med auktoritativt positivt innehåll. AI-modeller väger information delvis utifrån frekvens- och auktoritetsmönster i sitt träningsdata. Om du skapar väsentligt mer positivt, korrekt och auktoritativt innehåll än det finns felaktig information, kommer AI-system att stöta på mycket mer positiv information när de formar svar om ditt varumärke.
| Innehållstyp | Auktoritetsnivå | Påverkan på AI | Tidsram |
|---|---|---|---|
| Professionella biografisidor | Hög | Omedelbar påverkan på svar | Veckor till månader |
| Branschpublikationer & thought leadership | Mycket hög | Stark viktning i AI-svar | Månader |
| Pressmeddelanden via stora nyhetsbyråer | Hög | Betydande påverkan på narrativ | Veckor till månader |
| Fallstudier och framgångshistorier | Medelhög | Kontextuellt stöd för positiva påståenden | Månader |
| Akademiska eller forskningspublikationer | Mycket hög | Långvarig påverkan i träningsdata | Månader till år |
| Wikipedia-poster | Mycket hög | Kritisk för framtida AI-träningscykler | Månader till år |
Utveckla omfattande innehåll på flera trovärdiga plattformar för att säkerställa att AI-system stöter på auktoritativ positiv information. Denna satureringsstrategi är särskilt effektiv eftersom den angriper grundorsaken till AI-felinformation – otillräckligt positiv information för att balansera felaktiga påståenden. När AI-system har tillgång till mer positiv, välkällbelagd information från auktoritativa källor genererar de naturligt mer fördelaktiga svar om ditt varumärke.
Olika AI-plattformar har olika arkitekturer och uppdateringscykler, vilket kräver anpassade korrigeringsmetoder. ChatGPT och andra GPT-baserade system fokuserar på plattformar som ingår före träningsstopp: stora nyhetssajter, Wikipedia, professionella kataloger och allmänt citerat webbinnehåll. Eftersom dessa modeller inte uppdateras i realtid, kommer rättelser som görs idag att påverka framtida träningscykler, vanligtvis 12–18 månader framåt. Perplexity och realtidsbaserade AI-sökmotorer integrerar live webbinnehåll, så stark SEO och löpande pressnärvaro ger omedelbar effekt. När du tar bort eller rättar innehåll från webben slutar Perplexity vanligtvis att referera till det inom dagar eller veckor.
Claude och Anthropic-system prioriterar faktabaserad, välunderbyggd information. Anthropic betonar faktamässig tillförlitlighet, så se till att positivt innehåll om ditt varumärke är verifierbart och länkat till trovärdiga källor. När du begär rättelser från Claude, fokusera på att tillhandahålla evidensbaserade förtydliganden och peka på auktoritativa källor som stöder korrekt information. Nyckeln är att förstå att varje plattform har olika datakällor, uppdateringsfrekvens och kvalitetskrav. Anpassa din korrigeringsstrategi därefter.
Att regelbundet testa hur AI-system beskriver ditt namn eller varumärke är avgörande för att spåra effektiviteten av rättelser. Kör frågor i ChatGPT, Claude, Perplexity och andra plattformar med både positiv och negativ formulering (t.ex. “Är [varumärke] pålitligt?” kontra “[varumärke] prestationer”). Dokumentera resultaten över tid och följ utvecklingen för att identifiera felaktigheter och mäta om dina rättelseinsatser förändrar narrativet. Denna övervakning låter dig upptäcka när nya felaktigheter dyker upp och agera snabbt. Om du märker att en AI-plattform fortfarande hänvisar till föråldrad eller felaktig information veckor efter att du rättat källan kan du eskalera ärendet via plattformens supportkanaler.
Dokumentera alla rättelser du begär och de svar du får. Denna dokumentation tjänar flera syften: den ger bevis om du behöver eskalera frågor, hjälper dig identifiera mönster i hur olika plattformar hanterar rättelser och visar på dina goda avsikter att upprätthålla korrekt information. För logg över när du skickade in feedback, vilken felaktighet du rapporterade och eventuella svar från plattformen.
Fullständig borttagning av felaktig information från AI-sökningar är sällan möjlig, men utspädning och kontextbyggande är uppnåeliga mål. De flesta AI-företag uppdaterar träningsdata periodvis, vanligtvis var 12–18 månad för större språkmodeller. Åtgärder du vidtar idag kommer att påverka framtida iterationer, men du bör räkna med en betydande fördröjning mellan det att du begär en rättelse och att den syns i AI-genererade svar. Framgång kräver tålamod och uthållighet. Genom att fokusera på auktoritativt innehåll, åtgärda felaktigheter vid källan och bygga trovärdighet kan du påverka hur AI-plattformar beskriver ditt varumärke över tid.
Realtidsbaserade AI-sökmotorer som Perplexity kan visa resultat inom veckor eller månader, medan statiska modeller som ChatGPT kan ta 12–18 månader innan rättelser återspeglas i basmodellen. Dock kan du även i statiska modeller se förbättringar snabbare om plattformen släpper uppdaterade versioner eller finjusterar specifika delar av modellen. Tidsramen beror också på hur utbredd felaktigheten är och hur många användare som rapporterar den. Utbredda felaktigheter som påverkar många användare får snabbare uppmärksamhet än problem som bara rör några få personer.
I vissa jurisdiktioner har du juridiska möjligheter vid felaktig eller ärekränkande information. Om en AI-plattform genererar falsk, ärekränkande eller skadlig information om ditt varumärke kan du ha grund för rättsliga åtgärder. Rätten att bli glömd i tillämpliga jurisdiktioner, särskilt enligt GDPR i Europa, ger ytterligare alternativ. Dessa lagar låter dig begära borttagning av viss personlig information från sökresultat och i vissa fall från AI:s träningsdata.
Kontakta AI-plattformens juridiska team om du anser att informationen bryter mot deras användarvillkor eller gällande lagstiftning. De flesta plattformar har processer för att hantera juridiska klagomål och borttagningsförfrågningar. Ge tydliga bevis på felaktigheten och förklara varför den bryter mot tillämplig lag eller plattformens policy. Dokumentera all kommunikation med plattformen, eftersom detta utgör en dokumentation av dina goda avsikter att lösa problemet.
Det mest hållbara sättet att hantera ditt rykte i AI-sökningar är att överträffa negativ information med konsekvent, auktoritativ positivitet. Publicera löpande expertinnehåll, håll dina professionella profiler aktiva, skaffa stadig mediebevakning, bygg nätverk som förstärker prestationer och lyft fram samhällsengagemang. Detta långsiktiga tillvägagångssätt säkerställer att eventuell negativ eller felaktig bevakning späs ut till en fotnot i den bredare berättelsen om ditt varumärke.
Implementera strategisk SEO för framtida AI-träning genom att säkerställa att auktoritativt innehåll rankas högt i sökmotorer. Använd strukturerad datamarkering och schema för att klargöra kontext, upprätthåll konsekventa NAP-uppgifter (namn, adress, telefon) och bygg högkvalitativa backlinks till trovärdigt, positivt innehåll. Dessa insatser ökar chansen att positiv information blir det dominerande narrativet i framtida AI-omträningscykler. I takt med att AI-systemen blir allt mer sofistikerade och integrerade i vardagen, kommer vikten av att underhålla korrekt, auktoritativ information på webben bara att öka. Investera i din digitala närvaro nu för att säkerställa att AI-plattformar har tillgång till korrekt information om ditt varumärke under många år framöver.
Spåra hur ditt varumärke, din domän och dina URL:er visas i ChatGPT, Perplexity och andra AI-sökmotorer. Få aviseringar när rättelser behövs och mät effekten av dina insatser.
Lär dig identifiera och korrigera felaktig varumärkesinformation i AI-system som ChatGPT, Gemini och Perplexity. Upptäck övervakningsverktyg, korrigeringsstrate...

Komplett guide för att avanmäla dig från AI-träning och datainsamling på ChatGPT, Perplexity, LinkedIn och andra plattformar. Lär dig steg-för-steg hur du skydd...
Diskussion i communityn om skillnaden mellan AI-träningsdata och live-sök (RAG). Praktiska strategier för att optimera innehåll för både statiska träningsdata o...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.