Algoritm för citeringsval
Lär dig hur AI-system väljer vilka källor som ska citeras jämfört med att parafrasera. Förstå citeringsvalsaloritmer, biasmönster och strategier för att förbätt...
6 min läsning

Lär dig hur AI-modeller som ChatGPT, Perplexity och Gemini väljer källor att citera. Förstå citeringsmekanismer, rankningsfaktorer och optimeringsstrategier för AI-synlighet.
AI-modeller bestämmer vad de ska citera genom Retrieval-Augmented Generation (RAG), där källor utvärderas baserat på domänauktoritet, innehållets aktualitet, semantisk relevans, informationsstruktur och faktadensitet. Beslutsprocessen sker på millisekunder med hjälp av vektorsimilaritetsmatchning och multifaktorsalgoritmer som bedömer trovärdighet, expertissignaler och innehållskvalitet.
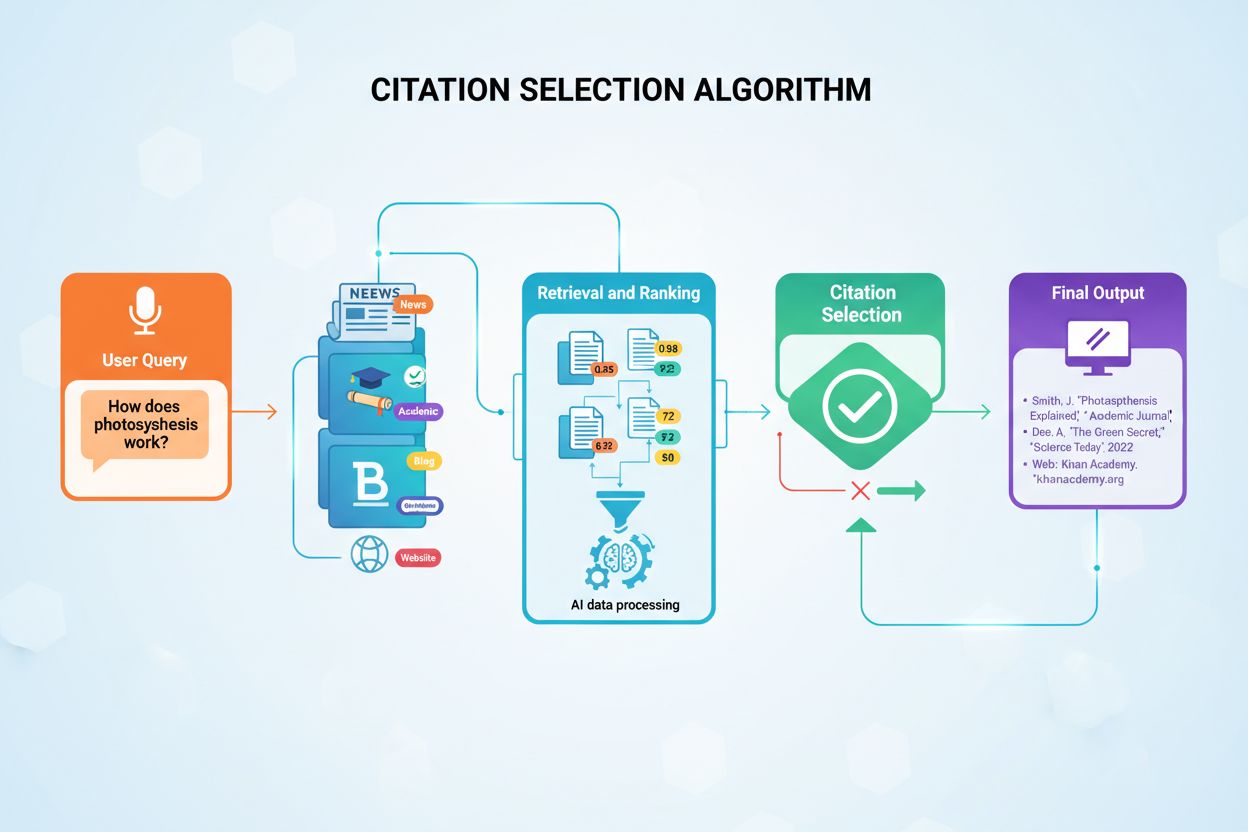
AI-modeller väljer inte källor slumpmässigt när de citerar i sina svar. Istället använder de sofistikerade algoritmer som utvärderar hundratals signaler på millisekunder för att avgöra vilka källor som förtjänar att bli citerade. Processen, kallad Retrieval-Augmented Generation (RAG), skiljer sig fundamentalt från hur traditionella sökmotorer rankar innehåll. Medan Googles algoritm fokuserar på att ranka sidor för synlighet i sökresultat, prioriterar AI-citeringsalgoritmer källor som ger den mest auktoritativa, relevanta och trovärdiga informationen för att besvara specifika användarfrågor. Denna skillnad innebär att synlighet i AI-genererade svar kräver förståelse för en helt annan uppsättning optimeringsprinciper än traditionell SEO.
Citeringsbeslutet sker genom en flerstegsprocess som startar så snart en användare skickar in en fråga. AI-systemet omvandlar användarens fråga till numeriska vektorer kallade embeddingar, som representerar den semantiska betydelsen av frågan. Dessa embeddingar söker sedan igenom indexerade innehållsdatabaser med miljontals dokument för att hitta semantiskt liknande innehållsbitar. Systemet hämtar inte bara det mest liknande innehållet; istället tillämpar det flera utvärderingskriterier samtidigt för att ranka potentiella källor utifrån deras lämplighet för citering. Denna parallella utvärderingsprocess säkerställer att de mest trovärdiga, relevanta och välstrukturerade källorna hamnar högst upp i rankingen.
Retrieval-Augmented Generation (RAG) är den grundläggande arkitekturen som möjliggör att AI-modeller överhuvudtaget kan citera externa källor. Till skillnad från traditionella stora språkmodeller som enbart bygger på träningsdata, söker RAG-system aktivt igenom indexerade dokument vid frågetillfället för att hämta relevant information innan svar genereras. Denna arkitektoniska skillnad förklarar varför vissa plattformar som Perplexity och Google AI Overviews konsekvent tillhandahåller källhänvisningar, medan andra som bas-ChatGPT ofta genererar svar utan explicit källangivelse. Att förstå RAG förklarar varför visst innehåll blir citerat medan lika högkvalitativt innehåll förblir osynligt för AI-system.
RAG-processen sker genom fyra distinkta faser som avgör vilka källor som till slut får citeras. Först delas dokumenten upp i hanterbara bitar om 200-500 ord, så att AI-systemen kan extrahera specifik, relevant information utan att behöva bearbeta hela artiklar. För det andra omvandlas dessa bitar till numeriska vektorer (embeddingar) med hjälp av maskininlärningsmodeller tränade för att förstå semantisk betydelse. För det tredje, när en användare ställer en fråga, söker systemet efter semantiskt liknande vektorer genom vektorsimilaritetsmatchning, och hittar innehåll som adresserar frågans kärnkoncept. För det fjärde genererar AI ett svar med det hämtade innehållet som kontext, och de källor som bidragit mest till svaret får citeringar. Denna arkitektur förklarar varför innehållsstruktur, tydlighet och semantisk överensstämmelse med vanliga frågor direkt påverkar sannolikheten att bli citerad.
AI-citeringsalgoritmer utvärderar källor utifrån fem kärndimensioner som tillsammans avgör citeringsvärde. Dessa faktorer samverkar för att skapa en heltäckande bedömning av källkvalitet, där varje dimension bidrar till det totala citeringsbetyget.
| Citeringsfaktor | Påverkansnivå | Nyckelindikatorer |
|---|---|---|
| Domänauktoritet | Mycket hög (25-30%) | Backlänkprofil, domänålder, närvaro i kunskapsgrafer, Wikipedia-omnämnanden |
| Innehållets aktualitet | Hög (20-25%) | Publiceringsdatum, uppdateringsfrekvens, färska statistik/data |
| Semantisk relevans | Hög (20-25%) | Överensstämmelse mellan fråga och innehåll, ämnesspecificitet, direkt svar |
| Informationsstruktur | Medelhög (15-20%) | Rubrikhierarki, skanningsbar formatering, implementation av schemamarkup |
| Faktadensitet | Medel (10-15%) | Specifika datapunkter, statistik, expertcitat, citeringskedjor |
Auktoritet är den mest tungt vägda faktorn i AI:s citeringsbeslut. Forskning som analyserat 150 000 AI-citat visar att Reddit och Wikipedia står för 40,1% respektive 26,3% av alla LLM-citeringar, vilket visar hur etablerad auktoritet dramatiskt påverkar urvalet. AI-system bedömer auktoritet via flera förtroendesignaler, inklusive domänålder, kvalitet på backlänkprofil, förekomst i kunskapsgrafer och tredjepartsvalidering. Webbplatser med domänauktoritet över 60 får konsekvent fler citeringar över ChatGPT, Perplexity och Gemini. Auktoritet handlar dock inte bara om domännivå; även författarnivåns trovärdighet spelar roll, där innehåll signerade av namngivna experter med verifierbara meriter får förtur framför anonyma bidrag.
Aktualitet fungerar som ett avgörande tidsfilter som avgör om innehåll fortfarande är citeringsbart. Innehåll som publicerats eller uppdaterats inom 48-72 timmar får förtur i rankingen, medan innehåll snabbt tappar synlighet redan inom 2-3 dagar utan uppdatering. Denna aktualitetsbias speglar AI-plattformarnas åtagande att ge aktuell information, särskilt inom snabbt föränderliga områden där föråldrad information kan vilseleda användare. Dock kan tidlöst innehåll med nyliga uppdateringar prestera bättre än nytt men ytligt innehåll, vilket antyder att kombinationen av grundläggande kvalitet och färskhet är viktigare än någon av faktorerna var för sig. Organisationer som uppdaterar innehåll kvartals- eller årsvis har högre citeringsfrekvens än de som publicerar en gång och sedan lämnar innehållet.
Relevans mäter semantisk överensstämmelse mellan användarfrågor och dokumentinnehåll. Källor som besvarar huvudfrågan direkt med minimalt sidospår får högre poäng än omfattande men ofokuserade resurser. AI-system utvärderar relevans genom embedding-similaritet, där den numeriska representationen av frågan jämförs med dokumentets embeddingar. Det innebär att innehåll skrivet i konversationston och som matchar naturliga sökfrågor presterar bättre än innehåll optimerat för traditionell SEO. FAQ-liknande innehåll och fråga-svar-par stämmer naturligt med hur AI-system behandlar frågor, vilket gör denna innehållsform särskilt citeringsvärd.
Struktur omfattar både informationsarkitektur och teknisk implementation. Tydlig hierarkisk organisation med beskrivande rubriker, logiskt flöde och skanningsbar formatering hjälper AI-system att förstå innehållsgränser och extrahera relevant information. Strukturerad datamarkering med schemaformat som FAQ-schema, artikelschema och organisationsschema kan öka citeringssannolikheten med upp till 10%. Innehåll organiserat som koncisa sammanfattningar, punktlistor, jämförelsetabeller och fråga-svar-par prioriteras framför täta stycken där insikter är begravda. Denna strukturella preferens speglar hur AI-system tränas att känna igen välorganiserad information som ger kompletta, kontextuella svar.
Faktadensitet syftar på koncentrationen av specifik, verifierbar information i innehållet. Källor med tydliga datapunkter, statistik, datum och konkreta exempel överträffar rent konceptuellt innehåll. Ännu viktigare är att källor som citerar auktoritativa referenser skapar förtroendekedjor där AI-system ärver förtroende från de citerade källorna. Innehåll med stödjande bevis och länkar till primärkällor får högre citeringsfrekvens än påståenden utan stöd. Detta krav på faktadensitet innebär att varje viktigt påstående bör inkludera hänvisning till auktoritativa källor med publiceringsdatum och expertmeriter.
Olika AI-plattformar implementerar skilda citeringsstrategier som speglar deras arkitektoniska skillnader och designfilosofier. Att förstå dessa plattformsspecifika preferenser hjälper innehållsskapare att optimera för flera AI-system samtidigt.
ChatGPT:s citeringsmönster visar en stark preferens för encyklopediska och auktoritativa källor. Wikipedia förekommer i cirka 35% av ChatGPT:s citeringar, vilket visar modellens tillit till etablerad, gemenskapsgranskad information. Plattformen undviker användargenererat forum-innehåll om inte frågan specifikt efterfrågar sådana åsikter, och föredrar källor med tydliga hänvisningskedjor och verifierbara fakta framför åsiktsbaserat innehåll. Detta konservativa tillvägagångssätt speglar ChatGPT:s träning på högkvalitativa källor och dess designfilosofi att prioritera noggrannhet framför omfattning. Organisationer som vill få ChatGPT-citat gynnas av att finnas i kunskapsgrafer, bygga Wikipedia-artiklar och skapa innehåll som efterliknar encyklopedisk djup och neutralitet.
Google AI-system som Gemini och AI Overviews inkluderar mer varierade källtyper, vilket speglar Googles bredare indexeringsfilosofi. Reddit-inlägg står för cirka 5% av AI Overviews-citeringarna, och plattformen föredrar innehåll som redan syns högt i organiska sökresultat, vilket skapar synergi mellan traditionell SEO och AI-citeringsfrekvens. Googles AI-system är mer benägna att citera nyare källor och användargenererat innehåll jämfört med ChatGPT, så länge dessa källor visar relevans och auktoritet. Denna plattformspreferens innebär att stark traditionell SEO-kapacitet korrelerar med AI-citeringsframgång på Googles plattformar, även om korrelationen inte är perfekt.
Perplexity AI:s preferenser betonar transparens och direkt källhänvisning. Plattformen tillhandahåller typiskt 3-5 källor per svar med direkta länkar, och föredrar branschspecifika recensionssajter, expertpublikationer och datadrivet innehåll. Domänauktoritet väger tungt, där etablerade publikationer får förtur, medan gemenskapsinnehåll utgör cirka 1% av citeringarna, främst för produktrekommendationer. Perplexitys designfilosofi prioriterar att hjälpa användare att verifiera information genom tydlig källhänvisning, vilket gör den särskilt värdefull för spårning av varumärkessynlighet. Organisationer som vill optimera för Perplexity bör skapa datarikt innehåll, branschspecifika resurser och expertförfattade texter som tydligt visar auktoritet.
Domänauktoritet fungerar som en tillförlitlighetsindikator i AI-algoritmer, vilket signalerar att en källa visat trovärdighet över tid. Systemen bedömer auktoritet via flera förtroendesignaler värda cirka 5% av den totala citeringssannolikheten, även om denna andel ökar markant för YMYL-ämnen (Your Money, Your Life) som påverkar hälsa, ekonomi eller säkerhet. Viktiga auktoritetsindikatorer är domänålder, SSL-certifikat, integritetspolicyer och efterlevnad som SOC 2 eller GDPR-certifiering. Dessa tekniska signaler får större effekt i kombination med kvalitetsmått på innehållet, så att tekniskt välskötta sajter med utmärkt innehåll överträffar tekniskt svaga sajter oavsett innehållskvalitet.
Backlänkprofiler påverkar AI-algoritmers källuppfattning avsevärt. AI-modeller bedömer auktoriteten hos länkande domäner, relevansen i länkens kontext och mångfalden i backlänkportföljen. Forskning visar att tio länkar från stora publikationer är mer värda än 100 länkar från lågauktoritativa sajter, vilket visar att länkens kvalitet är viktigare än kvantitet. Expertattribution höjer chansen att bli citerad rejält, där innehåll signerat av namngivna författare med verifierbara meriter presterar mycket bättre än anonymt innehåll. Författarschema-märkning och utförliga biografier hjälper AI-system att validera expertis, medan tredjepartsvalidering via omnämnanden i branschpublikationer stärker trovärdigheten. Organisationer som bygger auktoritet bör fokusera på länkar från högauktoritativa källor, bygga upp författarmeriter och säkra omnämnanden i branschpublikationer.
Wikipedia- och kunskapsgrafförekomst förbättrar citeringsfrekvensen dramatiskt oavsett andra faktorer. Källor som refereras i Wikipedia har stora fördelar eftersom kunskapsgrafer fungerar som auktoritativa källor som AI-modeller återkommer till över vitt skilda frågor. Google Knowledge Panel-information matas direkt in i hur AI-modeller förstår entitetsrelationer och auktoritet. Organisationer utan närvaro på Wikipedia har svårt att få konsekventa citat även med högkvalitativt innehåll, vilket antyder att utveckling av kunskapsgrafer bör vara en prioritet för seriösa AI-synlighetsstrategier. Detta skapar ett grundläggande förtroendelager som språkmodeller använder vid hämtning, så att kunskapsgrafer fungerar som auktoritativa källor som modeller rådfrågar upprepade gånger.
Anpassning till konversationsfrågor innebär ett grundläggande skifte från traditionell SEO-optimering. Innehåll strukturerat som fråga-svar-par fungerar bättre i hämtalgoritmer än keyword-optimerat material. FAQ-sidor och innehåll som efterliknar naturliga språkfrågor prioriteras eftersom AI-system är tränade på konversationsdata och förstår naturliga språk bättre än nyckelordskedjor. Det innebär att innehåll skrivet som om man svarar en väns fråga överträffar innehåll skrivet för sökmotoralgoritmer. Organisationer bör granska sitt innehåll för konversationston, direkta svar på vanliga frågor och naturlig språkanpassning till hur användare faktiskt frågar.
Citeringskvalitet i innehållet skapar förtroendekedjor som sträcker sig bortom individuella källor. AI-system utvärderar om påståenden stöds av data och bevis. Innehåll som citerar auktoritativa referenser ärver förtroende från dessa källor, vilket ger multiplicerande trovärdighet. Källor som inkluderar bevis och länkar till primärkällor har högre citeringsfrekvens än påståenden utan stöd. Det innebär att varje viktigt påstående bör inkludera hänvisning till auktoritativa källor med publiceringsdatum och expertmeriter. Organisationer som skapar citeringsvärdigt innehåll bör forska och citera minst 5-8 auktoritativa källor, inkludera 2-3 expertcitat med fulla meriter och lägga till 3-5 nya statistikuppgifter med publiceringsdatum.
Konsistens över plattformar påverkar hur AI-system bedömer källors trovärdighet. När AI hittar konsekvent information i flera källor ökar förtroendet för att citera någon av dessa. Källor som motsäger konsensus prioriteras lägre om de inte har tungt vägande motbevis. Denna konsistensbias innebär att sammanhängande budskap över egna, förtjänade och delade kanaler stärker enskilda källors citerbarhet. Organisationer som utvecklar AI-rykteshanteringsstrategier måste säkerställa konsekventa budskap på alla digitala plattformar, så att informationen på företagets webbplats, sociala medier, branschpublikationer och tredjepartsplattformar går i linje och stärker kärnbudskapen.
Uppdateringsfrekvensstrategi är viktigare i AI-eran än för traditionell SEO. Publiceringsfrekvensen påverkar citeringsgraden direkt, då AI-plattformar tydligt föredrar nyligen uppdaterat innehåll. Organisationer bör uppdatera befintligt innehåll var 48-72 timme för att upprätthålla aktualitetssignaler, även om det inte kräver fullständiga omskrivningar. Att lägga till nya datapunkter, uppdatera statistik eller utöka med senaste utvecklingen bibehåller citeringskvalificeringen. Innehållshanteringssystem som spårar uppdateringsfrekvens och innehållets färskhet hjälper till att bibehålla konkurrenskraftiga citeringsnivåer när AI-plattformar alltmer viktar aktualitet. Detta kontinuerliga arbetssätt skiljer sig fundamentalt från traditionell SEO där innehåll kunde rankas i åratal utan ändring.
Strategisk placering på aggregatorsajter skapar flera upptäcktsvägar för AI-system. Att synas i branschsammanställningar, expertlistor eller recensionssajter öppnar möjligheter utöver vad originalkällan kan åstadkomma ensam. Ett omnämnande i en ofta citerad publikation skapar flera upptäcktsvägar och möjliggör att AI-system stöter på ditt innehåll från flera håll. Medierelationer och innehållspartnerskap ökar i värde för AI-synlighet, liksom strategisk placering i branschsdatabaser och kataloger. Organisationer bör eftersträva omnämnanden i branschsammanställningar, expertlistor och recensionssajter som en del av sin AI-synlighetsstrategi.
Implementation av strukturerad data ökar citeringssannolikheten genom att göra innehållet maskinläsbart. Schemamarkup i AI-läsbara format hjälper AI-plattformar att förstå och extrahera specifika fakta utan att tolka ostrukturerad text. FAQ-schema, artikelschema med författarinformation och organisationsschema skapar maskinläsbara signaler som hämtalgoritmer prioriterar. JSON-LD-strukturerad data gör att AI kan extrahera fakta effektivt, vilket förbättrar både citeringssannolikhet och noggrannhet i citerad information. Organisationer som implementerar omfattande schemamarkup ser mätbara förbättringar i citeringsfrekvens över flera AI-plattformar.
Wikipedia- och kunskapsgrafsutveckling ger sammansatt avkastning trots att det kräver långsiktig insats. Att bygga närvaro på Wikipedia kräver neutrala, välkällbelagda bidrag som uppfyller Wikipedias redaktionella standarder. Samtidig optimering av profiler på Wikidata, Google Knowledge Panel och branschspecifika databaser skapar det grundläggande förtroendelagret som AI-system återvänder till. Dessa kunskapsgrafsinlägg fungerar som auktoritativa källor som modellerna rådfrågar över vitt skilda frågor, vilket gör kunskapsgrafsutveckling till en strategisk prioritet för organisationer som vill ha långvarig AI-synlighet.
Organisationer bör spåra citeringsfrekvens genom att manuellt testa relevanta frågor över ChatGPT, Google AI Overviews, Perplexity och andra plattformar. Regelbundna prompttester avslöjar vilket innehåll som får citeringar och vilka luckor som finns i AI-representationen. Denna testmetodik ger direkt insyn i citeringsprestanda och hjälper till att identifiera optimeringsmöjligheter. AI-citeringsalgoritmer förändras ständigt i takt med att träningsdata växer och hämtstrategier utvecklas, vilket kräver att innehållsstrategier anpassas efter prestandadata. När innehåll slutar få citeringar trots tidigare framgång, bör det förnyas med aktuell information eller omstruktureras för bättre semantisk överensstämmelse.
Flera källor kan bli citerade för en och samma fråga, vilket skapar kociteringsmöjligheter snarare än nollsummespel. Organisationer gynnas av att skapa heltäckande innehåll som kompletterar snarare än duplicerar redan ofta citerade källor. Konkurrensanalys avslöjar vilka varumärken som dominerar AI-synligheten i olika kategorier, vilket hjälper organisationer att identifiera luckor och möjligheter. Att följa citeringsprestanda över tid visar trender och vilka URL:er som driver framgång, vilket gör det möjligt för organisationer att upprepa vinnande strategier och skala upp framgångsrika koncept.
Spåra var ditt innehåll dyker upp i AI-genererade svar över ChatGPT, Perplexity, Google AI Overviews och andra AI-plattformar. Få insikter i realtid om din AI-synlighet och citeringsprestanda.
Lär dig hur AI-system väljer vilka källor som ska citeras jämfört med att parafrasera. Förstå citeringsvalsaloritmer, biasmönster och strategier för att förbätt...

Lär dig hur AI-genererat innehåll presterar i AI-sökmotorer som ChatGPT, Perplexity och Google AI Overviews. Upptäck rankningsfaktorer, optimeringsstrategier oc...
Lär dig vad citeringsoptimering för AI är och hur du optimerar ditt innehåll för att bli citerad av ChatGPT, Perplexity, Google Gemini och andra AI-sökmotorer....
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.