
Första stegen i AI-sökmotoroptimering för ditt varumärke
Lär dig de viktigaste första stegen för att optimera ditt innehåll för AI-sökmotorer som ChatGPT, Perplexity och Google AI Overviews. Upptäck hur du strukturera...
7 min läsning

Lär dig hur AI-sökmotorer som ChatGPT, Perplexity och Google AI Overviews fungerar. Upptäck LLM:er, RAG, semantisk sökning och realtidsmekanismer för informationshämtning.
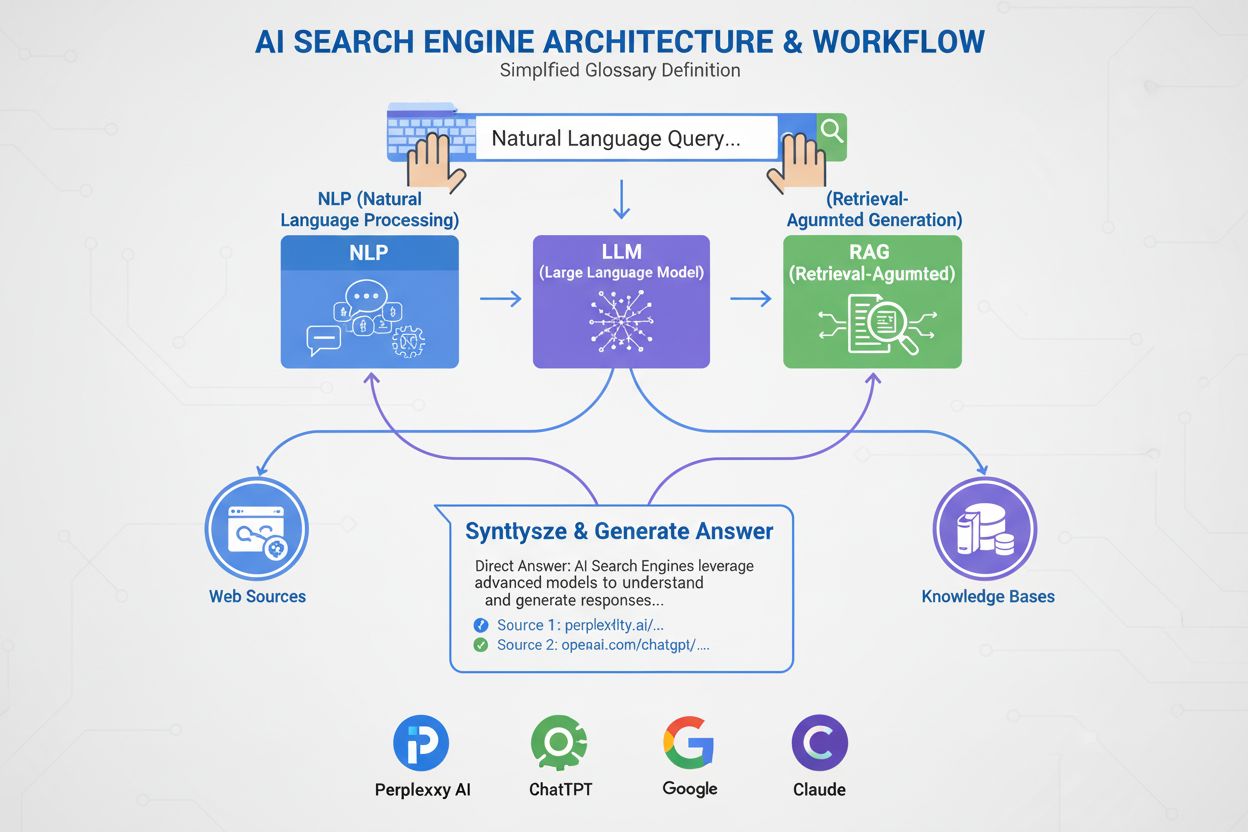
AI-sökmotorer använder stora språkmodeller (LLM:er) i kombination med retrieval-augmented generation (RAG) för att förstå användarens avsikt och hämta relevant information från webben i realtid. De bearbetar frågor genom semantisk förståelse, vektorinbäddningar och kunskapsgrafer för att leverera konversationssvar med källhänvisningar, till skillnad från traditionella sökmotorer som returnerar rankade listor med webbplatser.
AI-sökmotorer representerar ett grundläggande skifte från traditionell sökning baserad på nyckelord till konversationell, avsiktsdriven informationshämtning. Till skillnad från Googles traditionella sökmotor, som genomsöker, indexerar och rankar webbplatser för att returnera en lista med länkar, genererar AI-sökmotorer som ChatGPT, Perplexity, Google AI Overviews och Claude egna svar genom att kombinera flera teknologier. Dessa plattformar förstår vad användare faktiskt letar efter, hämtar relevant information från auktoritativa källor och syntetiserar den informationen till sammanhängande, citerade svar. Tekniken bakom dessa system förändrar hur människor upptäcker information online, med ChatGPT som hanterar 2 miljarder frågor dagligen och AI Overviews som visas i 18% av globala Google-sökningar. Att förstå hur dessa system fungerar är avgörande för innehållsskapare, marknadsförare och företag som vill synas i detta nya söklandskap.
AI-sökmotorer fungerar genom tre sammankopplade system som samverkar för att leverera korrekta, källbaserade svar. Den första komponenten är Large Language Model (LLM), som tränas på enorma mängder textdata för att förstå språkets mönster, struktur och nyanser. Modeller som OpenAI:s GPT-4, Googles Gemini och Anthropics Claude tränas med osuperviserad inlärning på miljarder dokument, vilket gör att de kan förutsäga vilka ord som bör följa baserat på statistiska mönster som lärts in under träningen. Den andra komponenten är inbäddningsmodellen, som omvandlar ord och fraser till numeriska representationer kallade vektorer. Dessa vektorer fångar semantisk innebörd och relationer mellan begrepp, vilket gör att systemet kan förstå att “gaming-laptop” och “högpresterande dator” är semantiskt relaterade även om de inte delar exakta nyckelord. Den tredje viktiga komponenten är Retrieval-Augmented Generation (RAG), som kompletterar LLM:ens träningsdata genom att hämta aktuell information från externa kunskapsbaser i realtid. Detta är avgörande eftersom LLM:er har ett träningsstoppdatum och inte kan komma åt aktuell information utan RAG. Tillsammans möjliggör dessa tre komponenter för AI-sökmotorer att leverera aktuella, korrekta och citerade svar istället för hallucinerad eller föråldrad information.
Retrieval-Augmented Generation är processen som gör att AI-sökmotorer kan grunda sina svar i auktoritativa källor istället för att enbart förlita sig på träningsdata. När du skickar in en fråga till en AI-sökmotor omvandlas din fråga först till en vektorrepresentation med hjälp av inbäddningsmodellen. Denna vektor jämförs sedan mot en databas med indexerat webbmaterial, även det omvandlat till vektorer, med tekniker som cosine similarity för att identifiera de mest relevanta dokumenten. RAG-systemet hämtar dessa dokument och skickar dem till LLM:en tillsammans med din ursprungliga fråga. LLM:en använder därefter både den hämtade informationen och sin träningsdata för att generera ett svar som direkt refererar till de källor den konsulterat. Detta tillvägagångssätt löser flera kritiska problem: det säkerställer att svaren är aktuella och faktabaserade, det gör det möjligt för användare att verifiera information genom att kontrollera källhänvisningar, och det ger innehållsskapare möjlighet att bli citerade i AI-genererade svar. Azure AI Search och AWS Bedrock är företagsimplementeringar av RAG som visar hur organisationer kan bygga egna AI-söksystem. Kvaliteten på RAG beror till stor del på hur väl hämtningstekniken identifierar relevanta dokument, vilket är varför semantisk ranking och hybrid-sökning (kombinera nyckelords- och vektorsökning) har blivit viktiga tekniker för att förbättra noggrannheten.
Semantisk sökning är teknologin som gör att AI-sökmotorer kan förstå innebörd istället för att bara matcha nyckelord. Traditionella sökmotorer letar efter exakta nyckelords-matcher, men semantisk sökning analyserar avsikten och det kontextuella innehållet bakom en fråga. När du söker efter “prisvärda smartphones med bra kamera” förstår en semantisk sökmotor att du vill ha budgetmobiler med utmärkta kamerafunktioner, även om resultaten inte innehåller exakt de orden. Detta uppnås med vektorinbäddningar, som representerar text som högdimensionella numeriska arrayer. Avancerade modeller som BERT (Bidirectional Encoder Representations from Transformers) och OpenAI:s text-embedding-3-small omvandlar ord, fraser och hela dokument till vektorer där semantiskt liknande innehåll placeras nära varandra i vektorrummet. Systemet beräknar sedan vektorsimilaritet med matematiska tekniker som cosine similarity för att hitta de dokument som bäst matchar frågans avsikt. Detta tillvägagångssätt är mycket mer effektivt än nyckelords-matchning eftersom det fångar relationer mellan begrepp. Till exempel förstår systemet att “gaming-laptop” och “högpresterande dator med GPU” är relaterade även om de inte har några gemensamma nyckelord. Kunskapsgrafer lägger till ytterligare ett lager genom att skapa strukturerade nätverk av semantiska relationer, där begrepp som “laptop” länkas till “processor”, “RAM” och “GPU” för att förbättra förståelsen. Detta flerskiktade tillvägagångssätt för semantisk förståelse gör att AI-sökmotorer kan leverera relevanta resultat för komplexa, konversationella frågor som traditionella sökmotorer har svårt med.
| Sökteknik | Hur den fungerar | Styrkor | Begränsningar |
|---|---|---|---|
| Nyckelordssökning | Matchar exakta ord eller fraser i frågan med indexerat innehåll | Snabb, enkel, förutsägbar | Fungerar dåligt med synonymer, stavfel och komplex avsikt |
| Semantisk sökning | Förstår innebörd och avsikt med NLP och inbäddningar | Hanterar synonymer, kontext och komplexa frågor | Kräver mer datorkraft |
| Vektorsökning | Omvandlar text till numeriska vektorer och beräknar likhet | Precisa likhetsmatchningar, skalbar | Fokuserar på matematisk närhet, ej kontext |
| Hybridsökning | Kombinerar nyckelords- och vektorsökningsmetoder | Bästa av båda världar för precision och återhämtning | Mer komplext att implementera och justera |
| Kunskapsgrafsökning | Använder strukturerade relationer mellan begrepp | Lägger till resonemang och kontext i svaren | Kräver manuell kurering och underhåll |
En av de största fördelarna med AI-sökmotorer jämfört med traditionella LLM:er är deras förmåga att komma åt information i realtid från webben. När du frågar ChatGPT om aktuella händelser använder den en bot som heter ChatGPT-User för att skanna webbplatser i realtid och hämta aktuell information. Perplexity söker på liknande sätt på internet i realtid för att samla insikter från förstklassiga källor, vilket gör att den kan besvara frågor om händelser som inträffat efter dess träningsdatastopp. Google AI Overviews utnyttjar Googles befintliga webbindex och skanningsinfrastruktur för att hämta aktuell information. Denna förmåga till realtidsinhämtning är avgörande för att upprätthålla noggrannhet och relevans. Hämtningen sker i flera steg: först bryter systemet ner din fråga i flera relaterade underfrågor genom en process som kallas query fan-out, vilket hjälper till att få mer heltäckande information. Sedan söker systemet indexerat webbinnehåll med både nyckelords- och semantisk matchning för att identifiera relevanta sidor. De hämtade dokumenten rankas efter relevans med semantiska rankningsalgoritmer som poängsätter resultat baserat på innebörd snarare än bara nyckelordsfrekvens. Slutligen extraherar systemet de mest relevanta passagerna från dessa dokument och skickar dem till LLM:en för svarsgenerering. Denna process sker på några sekunder, vilket är anledningen till att användare förväntar sig AI-svar inom 3–5 sekunder. Hastigheten och noggrannheten i denna hämtning påverkar direkt kvaliteten på det slutliga svaret, vilket gör effektiv informationshämtning till en avgörande komponent i AI-sökmotorers arkitektur.
När RAG-systemet har hämtat relevant information använder Large Language Model denna information för att generera ett svar. LLM:er “förstår” inte språk på mänskligt vis; de använder istället statistiska modeller för att förutsäga vilka ord som bör följa baserat på mönster som lärts in under träningen. När du matar in en fråga omvandlar LLM:en den till en vektorrepresentation och bearbetar den genom ett neuralt nätverk med miljontals sammankopplade noder. Dessa noder har inlärda kopplingsstyrkor, kallade vikter, från träningen, vilka avgör hur mycket inflytande varje koppling har över andra. LLM:en returnerar inte bara en enda förutsägelse för nästa ord; den returnerar en rankad lista av sannolikheter. Till exempel kan den förutsäga 4,5% chans att nästa ord bör vara “lära” och 3,5% chans att det bör vara “förutsäga”. Systemet väljer inte alltid det ord med högst sannolikhet; ibland väljer det ord längre ner på listan för att göra svaren mer naturliga och kreativa. Denna slumpmässighet styrs av temperature-parametern, som går från 0 (deterministisk) till 1 (mycket kreativ). Efter att det första ordet genererats upprepas processen för nästa ord, och nästa, tills ett komplett svar är genererat. Denna token-för-token-generering gör att AI-svar ibland känns konversationella och naturliga—modellen förutspår i princip den mest sannolika fortsättningen på en konversation. Kvaliteten på det genererade svaret beror både på kvaliteten på den hämtade informationen och på LLM:ens träningssofistikation.
Olika AI-sökmotorplattformar implementerar dessa grundteknologier med olika tillvägagångssätt och optimeringar. ChatGPT, utvecklad av OpenAI, har tagit 81% av marknadsandelen för AI-chattbotar och hanterar 2 miljarder frågor dagligen. ChatGPT använder OpenAI:s GPT-modeller i kombination med realtidswebbåtkomst via ChatGPT-User för att hämta aktuell information. Den är särskilt stark på att hantera komplexa, flerstegiga frågor och bibehålla konversationens kontext. Perplexity särskiljer sig genom transparenta källhänvisningar, där användarna ser exakt vilka webbplatser som informerat varje del av svaret. Perplexitys främsta citeringskällor inkluderar Reddit (6,6%), YouTube (2%) och Gartner (1%), vilket speglar dess fokus på att hitta auktoritativa och mångsidiga källor. Google AI Overviews integreras direkt i Googles sökresultat och visas högst upp på sidan för många frågor. Dessa översikter visas i 18% av globala Google-sökningar och drivs av Googles Gemini-modell. Google AI Overviews är särskilt effektiva för informationssökande frågor, med 88% av frågorna som utlöser dem är informationssökande till sin natur. Googles AI Mode, en separat sökupplevelse lanserad i maj 2024, omstrukturerar hela sökresultatsidan kring AI-genererade svar och har nått 100 miljoner aktiva användare per månad i USA och Indien. Claude, utvecklad av Anthropic, betonar säkerhet och noggrannhet, med användare som rapporterar hög tillfredsställelse med dess förmåga att leverera nyanserade, välmotiverade svar. Varje plattform gör olika avvägningar mellan hastighet, noggrannhet, källtransparens och användarupplevelse, men alla bygger på den grundläggande arkitekturen med LLM:er, inbäddningar och RAG.
När du skickar in en fråga till en AI-sökmotor genomgår den en sofistikerad, flerstegs processpipeline. Första steget är frågeanalys, där systemet bryter ner din fråga i grundläggande komponenter såsom nyckelord, entiteter och fraser. Naturlig språkbehandling som tokenisering, ordklassmärkning och namngiven entityigenkänning identifierar vad du frågar om. Till exempel identifierar systemet i frågan “bästa laptops för gaming” “laptops” som huvudentitet och “gaming” som avsiktsdrivare, och drar slutsatsen att du behöver hög minneskapacitet, processorkraft och GPU-funktionalitet. Andra steget är frågeexpansion och fan-out, där systemet genererar flera relaterade frågor för att hämta mer heltäckande information. Istället för att bara söka efter “bästa gaming-laptops” kan systemet också söka efter “specifikationer gaming-laptop”, “högpresterande laptops” och “laptop GPU-krav”. Dessa parallella sökningar sker samtidigt, vilket dramatiskt förbättrar omfattningen av den hämtade informationen. Tredje steget är hämtning och ranking, där systemet söker i indexerat innehåll med både nyckelords- och semantisk matchning och sedan rankar resultaten efter relevans. Fjärde steget är passagextraktion, där systemet identifierar de mest relevanta styckena från hämtade dokument istället för att skicka hela dokument till LLM:en. Detta är avgörande eftersom LLM:er har tokenbegränsningar—GPT-4 accepterar cirka 128 000 tokens, men du kan ha 10 000 sidor dokumentation. Genom att bara extrahera de mest relevanta passagerna maximerar systemet kvaliteten på informationen som skickas till LLM:en och håller sig inom tokenbegränsningar. Sista steget är svarsgenerering och källhänvisning, där LLM:en genererar ett svar och inkluderar hänvisningar till de källor den konsulterat. Hela denna pipeline måste slutföras på några sekunder för att möta användarnas förväntningar på svarstid.
Den grundläggande skillnaden mellan AI-sökmotorer och traditionella sökmotorer som Google ligger i deras huvudsakliga syften och metoder. Traditionella sökmotorer är utformade för att hjälpa användare hitta befintlig information genom att genomsöka webben, indexera sidor och ranka dem baserat på relevanssignaler som länkar, nyckelord och användarengagemang. Googles process innefattar tre huvudsteg: skanning (upptäcka sidor), indexering (analysera och lagra sidinformation) och ranking (avgöra vilka sidor som är mest relevanta för en fråga). Målet är att returnera en lista med webbplatser, inte att generera nytt innehåll. AI-sökmotorer, däremot, är utformade för att generera egna, syntetiserade svar baserat på mönster lärda från träningsdata och aktuell information hämtad från webben. Medan traditionella sökmotorer använder AI-algoritmer som RankBrain och BERT för att förbättra ranking, försöker de inte skapa nytt innehåll. AI-sökmotorer genererar i grunden ny text genom att förutsäga ordföljder. Denna skillnad har stora konsekvenser för synlighet. Med traditionell sökning måste du ranka bland de 10 översta för att få klick. Med AI-sökning citeras 40% av källorna i AI Overviews trots att de rankar lägre än topp 10 i traditionell Google-sökning, och endast 14% av URL:erna som citeras av Googles AI Mode rankar i Googles traditionella topp 10 för samma frågor. Det betyder att ditt innehåll kan citeras i AI-svar även om det inte rankar högt i traditionell sökning. Dessutom har varumärkesomnämnanden på webben en korrelation på 0,664 med förekomst i Google AI Overviews, vilket är mycket högre än bakåtlänkar (0,218), vilket tyder på att varumärkesexponering och rykte är viktigare i AI-sök än traditionella SEO-mått.
AI-sökområdet utvecklas snabbt, med stora konsekvenser för hur människor upptäcker information och hur företag bibehåller synlighet. AI-söktrafik förväntas överträffa traditionell söktrafik senast 2028, och nuvarande data visar att AI-plattformar genererade 1,13 miljarder hänvisningsbesök i juni 2025, vilket är en ökning med 357% från juni 2024. Viktigt är att AI-söktrafik konverterar i 14,2% jämfört med Googles 2,8%, vilket gör denna trafik dramatiskt mer värdefull trots att den idag bara utgör 1% av den globala trafiken. Marknaden koncentreras kring några få dominerande plattformar: ChatGPT har 81% av marknadsandelen för AI-chattbotar, Googles Gemini har 400 miljoner aktiva användare per månad och Perplexity har över 22 miljoner aktiva användare per månad. Nya funktioner expanderar AI-sökningens möjligheter—ChatGPT:s Agent Mode gör det möjligt för användare att delegera komplexa uppgifter som att boka flyg direkt i plattformen, medan Instant Checkout möjliggör produktköp direkt från chatten. ChatGPT Atlas, lanserad i oktober 2025, tar ChatGPT ut på hela webben för omedelbara svar och förslag. Dessa utvecklingar visar att AI-sökning håller på att bli inte bara ett alternativ till traditionell sökning, utan en komplett plattform för informationsupptäckt, beslutsfattande och handel. För innehållsskapare och marknadsförare kräver detta skifte en grundläggande förändring i strategi. Istället för att optimera för nyckelordsranking krävs framgång i AI-sök genom att etablera relevanta mönster i träningsmaterial, bygga varumärkesauktoritet via omnämnanden och källhänvisningar samt säkerställa att innehållet är aktuellt, heltäckande och välstrukturerat. Verktyg som AmICited gör det möjligt för företag att övervaka var deras innehåll syns på AI-plattformar, följa citeringsmönster och mäta AI-synlighet—viktiga funktioner för att navigera i detta nya landskap.
Spåra var ditt innehåll visas i ChatGPT, Perplexity, Google AI Overviews och Claude. Få realtidsaviseringar när din domän citeras i AI-genererade svar.
Lär dig de viktigaste första stegen för att optimera ditt innehåll för AI-sökmotorer som ChatGPT, Perplexity och Google AI Overviews. Upptäck hur du strukturera...
Lär dig vad AI-sökmotorer är, hur de skiljer sig från traditionell sökning och deras inverkan på varumärkets synlighet. Utforska plattformar som Perplexity, Cha...
Lär dig hur AI-sökindex fungerar, skillnaderna mellan ChatGPT:s, Perplexitys och SearchGPT:s indexeringsmetoder och hur du optimerar ditt innehåll för AI-synlig...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.