
Hur skiljer sig Perplexity från Google? Komplett jämförelseguide
Upptäck de viktigaste skillnaderna mellan Perplexity och Google. Lär dig hur AI-drivna forskningsmotorer jämförs med traditionella sökmotorer när det gäller fun...
8 min läsning

Förstå hur Perplexitys livesökningsteknologi hämtar realtidsinformation från webben och genererar svar med källhänvisningar. Lär dig den tekniska processen bakom Perplexitys sökfunktioner.
Perplexitys livesök kombinerar realtidsindexering av webben med stora språkmodeller för att hämta aktuell information från internet och generera konversationssvar med källhänvisningar. När du skickar in en fråga bearbetar Perplexity din fråga, söker i sitt webbindex efter relevanta dokument, extraherar nyckelinformation och sammanställer detta till ett kortfattat svar med inbäddade hänvisningar till ursprungskällorna.
Perplexitys livesökning innebär ett grundläggande skifte i hur information hämtas och presenteras för användare. Till skillnad från traditionella sökmotorer som returnerar en länklista kombinerar Perplexity realtidswebbsökning med avancerade språkmodeller för att leverera direkta, konversationsbaserade svar med källhänvisningar. Detta hybrida tillvägagångssätt förenar sökmotorernas omedelbarhet med AI-chatbottars konversationsintelligens och skapar ett unikt informationshämtningssystem som prioriterar både noggrannhet och användarupplevelse.
Den grundläggande skillnaden mellan Perplexity och traditionella sökmotorer ligger i dess fokus på liveindexering av webben och realtidsinformation. Medan Google och Bing underhåller massiva index av genomsökta webbsidor, kartlägger Perplexity kontinuerligt webben för att säkerställa åtkomst till den mest aktuella informationen. Detta realtidssätt gör att du, när du ställer en fråga om till exempel senaste nyheter, marknadstrender eller nypublicerad forskning, får information publicerad inom timmar eller till och med minuter, inte veckor eller månader. Plattformens infrastruktur är särskilt utformad för att hantera denna ständiga ström av färska data och samtidigt bibehålla kvalitet och relevans i svaren.
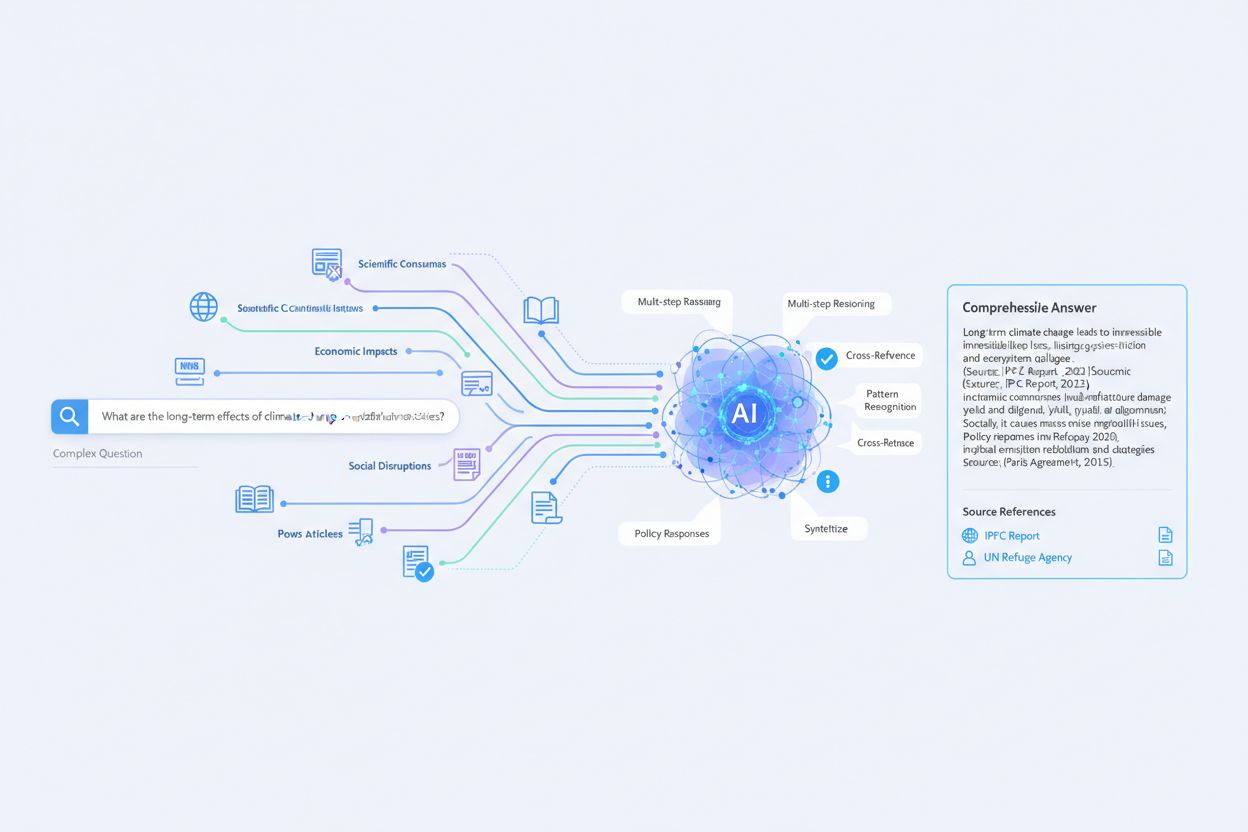
Perplexitys livesökning fungerar genom en sofistikerad fyrstegsprocess som förvandlar din naturliga språkfråga till ett väldokumenterat, konversationsbaserat svar. Om du förstår varje steg ser du hur plattformen kan leverera aktuell, korrekt information med transparenta källor.
När du skriver in en fråga i Perplexity behandlar systemet den inte bara som en samling sökord. Istället använder det avancerad språkteknologi (NLP) för att förstå den verkliga avsikten bakom din fråga. Systemet tokeniserar din input—delar upp den i ord och fraser—och tillämpar semantiska regler för att identifiera entiteter, platser, begrepp och potentiella oklarheter. Om du till exempel frågar “Vad är de senaste framstegen inom kvantdatorer?” förstår Perplexity att du söker efter aktuell information om ett specifikt teknikområde, inte historik eller allmänna definitioner.
I detta steg kan Perplexity omformulera din ursprungliga fråga till en mer effektiv sökfras som ändå matchar din avsikt. Omformuleringen kan lägga till synonymer, booleska operatorer och kontextuella förfiningar för att säkerställa att nästa steg söker exakt det du behöver. Om din ursprungliga fråga innehåller vaga termer eller kan tolkas på flera sätt identifierar systemet dessa oklarheter och justerar sökparametrarna därefter. Denna intelligenta förbehandling förbättrar betydligt relevansen på de resultat som hämtas i nästa steg.
När Perplexity har förstått din fråga börjar dess informationshämtningssystem söka i ett stort, kontinuerligt uppdaterat webbindex. Detta index fungerar ungefär som Googles databas över genomsökta sidor men med en viktig skillnad: Perplexity prioriterar färskhet och realtidsuppdateringar. Systemet använder semantiska sökmetoder som går bortom enkel sökordsjämförelse och hittar relevanta dokument även om de inte innehåller exakt samma termer som din fråga. Det gör att Perplexity förstår att ett dokument om “artificiella neurala nätverk” är relevant för en fråga om “djupinlärning”, även om exakt de fraserna inte matchar.
Vid hämtning utvärderar systemet flera faktorer när det väljer källor: relevans för din fråga, innehållskvalitet, källans trovärdighet, publiceringsdatum och domänauktoritet. Perplexity prioriterar etablerade, pålitliga källor som akademiska institutioner, myndigheter, välkända nyhetsorganisationer och branschexperter. Denna prioritering är avgörande för att hålla hög noggrannhet och motverka spridning av felinformation. Systemet väljer normalt de främsta källorna som bäst besvarar din fråga, istället för att returnera hundratals resultat som traditionella sökmotorer.
| Hämtningsfaktor | Beskrivning | Påverkan på resultat |
|---|---|---|
| Relevans | Hur nära innehållet matchar din frågeavsikt | Avgör val av primära källor |
| Innehållskvalitet | Djup, noggrannhet och omfattning i informationen | Sorterar bort ytliga eller opålitliga källor |
| Källans trovärdighet | Publicerande domäns rykte och auktoritet | Prioriterar etablerade institutioner |
| Publiceringsdatum | Hur nyligen innehållet publicerades | Säkerställer aktuell information |
| Domänauktoritet | Källans totala trovärdighet och expertis | Ger större vikt åt etablerade publikationer |
Efter att relevanta dokument har hämtats skickar Perplexity denna information till sin stora språkmodell (LLM) för att generera ett naturligt, konversationsbaserat svar. Det är här magin med livesökning blir tydlig. LLM:en kopierar inte bara text från källor, utan sammanställer information från flera dokument till ett sammanhängande, konverserande svar som direkt adresserar din fråga. Modellen extraherar centrala fakta, åsikter, argument och belägg från de hämtade källorna, organiserar dem logiskt och presenterar dem i tydligt, lättillgängligt språk.
Avgörande är att modellen, när den genererar varje påstående i svaret, noggrant spårar källhänvisningen. Varje faktapåstående, statistik eller citat innehåller en inbäddad källhänvisning som länkar tillbaka till ursprungskällan. Denna transparens är grundläggande för Perplexitys synsätt och särskiljer den från traditionella chatbottar som kan generera trovärdiga men okällhänvisade svar. Hänvisningssystemet låter dig omedelbart verifiera påståenden genom att granska originalkällorna, vilket bygger förtroende för informationen.
Under denna fas utför Perplexity även flera kvalitetskontroller. Systemet löser motsägelser mellan källor genom att utvärdera beviskvalitet och trovärdighet, upprätthåller en neutral ton för att undvika partiskhet och säkerställer faktakontroll genom att jämföra uppgifter mellan flera källor. Om källor är oense om ett faktum kan Perplexity presentera flera perspektiv med lämplig hänvisning, så att du förstår nyanser och debatter kring ett ämne.
Innan svaret presenteras för dig gör Perplexity en sista förfining, inklusive faktakontroll, sammanhangsbedömning och fullständighetskontroll. Systemet verifierar att det genererade svaret korrekt återspeglar informationen i källdokumenten och att alla påståenden är ordentligt belagda. Det utvärderar om svaret verkligen adresserar din ursprungliga fråga eller om viktiga aspekter saknas. Dessutom genererar Perplexity förslag på uppföljningsfrågor som guidar till vidare utforskning av ämnet, så att du kan upptäcka relaterad information du kanske inte tänkt på.
Denna förfining säkerställer att svaret du får inte bara är korrekt och väldokumenterat, utan även optimerat för tydlighet och användbarhet. Uppföljningsfrågorna fungerar som en forskningsguide, så att du kan fördjupa din förståelse av ett ämne stegvis genom naturlig konversation, istället för att hela tiden börja om med nya sökningar.
Perplexitys livesökning blir ännu kraftfullare tack vare sitt kontextuella minnessystem, som håller koll på din konversationshistorik under en session. När du ställer en uppföljningsfråga behandlar Perplexity den inte som en isolerad fråga, utan kodar in relevanta delar av dina tidigare utbyten i kontexten för den nya frågan. Detta gör att systemet förstår referenser, pronomen och underförstådd kontext utan att du behöver upprepa information.
Om du till exempel först frågar “Vad är de senaste framstegen inom kvantdatorer?” och sedan följer upp med “Hur jämförs detta med klassisk databehandling?”, förstår Perplexity att “detta” syftar på de tidigare diskuterade framstegen inom kvantdatorer. Systemet använder uppmärksamhetsmekanismer för att väga betydelsen av olika delar ur din konversationshistorik och avgöra vilka tidigare påståenden som är mest relevanta för din nya fråga. Denna kontextmedvetenhet möjliggör mer naturliga och flytande samtal där du kan förfina dina frågor och utforska ämnen successivt.
Det är dock viktigt att notera att Perplexitys minne endast är sessionsbaserat. När du stänger en konversation sparas inte historiken till framtida sessioner. Detta är ett medvetet val för att prioritera integritet och undvika lagring av känslig information, men innebär också att du inte kan förlita dig på personlig anpassning mellan olika samtal.
En av de största utmaningarna för språkmodeller är informationshallucination—att generera trovärdig men falsk information. Perplexity hanterar denna utmaning genom flera inbyggda mekanismer i sin livesökningsarkitektur. Den viktigaste skyddsåtgärden är kravet på källhänvisning. Eftersom varje påstående måste kopplas till ett verkligt källdokument kan modellen inte generera påståenden utan stöd utan att bryta hänvisningskedjan. Denna arkitektoniska begränsning minskar hallucinationer avsevärt jämfört med traditionella chatbottar.
Utöver källhänvisningar använder Perplexity realtidshämtning för att få aktuell information istället för att bara förlita sig på träningsdata som kan vara inaktuell eller ofullständig. Systemet bekräftar normalt påståenden över flera källor och kräver att viktiga fakta stöds av mer än ett dokument innan de inkluderas i svaret. Detta valideringssätt fångar fel och inkonsekvenser som kan finnas i enskilda källor. Dessutom har Perplexity faktakontrollprocesser som jämför genererad information med andra pålitliga data, vilket ytterligare höjer noggrannheten.
Plattformen prioriterar även välkända och pålitliga källor som akademiska institutioner, myndigheter och etablerade nyhetsorganisationer, vilket minskar risken för felinformation. När användare rapporterar felaktigheter eller hallucinationer används denna feedback för att förbättra kvaliteten på svaren över tid. Det är dock viktigt att komma ihåg att Perplexity inte har en formell faktagranskningsprocess motsvarande journalistiska standarder, så kritisk granskning av källor är fortsatt avgörande för viktiga beslut.
Perplexity erbjuder två olika söklägen som är optimerade för olika typer av frågor, och som båda utnyttjar livesökningsinfrastrukturen på olika sätt. Snabbsökning är utformad för enkla faktabaserade frågor som kräver direkta svar. När du väljer Snabbsökning gör Perplexity en fokuserad hämtning för att hitta de mest relevanta källorna och generera ett kortfattat svar. Detta läge prioriterar snabbhet och ger resultat på några sekunder, vilket är perfekt för enkla fakta, definitioner eller allmänna kunskapsfrågor.
Pro-sökning, som finns i Perplexity Pro och Enterprise-abonnemang, har ett mer sofistikerat tillvägagångssätt för komplexa frågor. Istället för att göra en enkel sökning delar Pro-sökning upp din fråga i flera delfrågor och gör iterativa sökningar för att bygga en helhetsbild. Systemet kan ställa följdfrågor för att bättre förstå din avsikt och förfina sökningen utifrån dina svar. Detta stegvisa arbetssätt är särskilt värdefullt för nyanserade frågor, forskningsintensiva ämnen eller situationer där du behöver djupgående utforskning. Pro-sökning tar oftast längre tid än Snabbsökning, men ger mer utförliga och välgrundade svar.
Perplexitys livesökning sträcker sig bortom grundläggande frågor och svar genom avancerade funktioner som Focus Mode och Copilot. Med Focus Mode kan du begränsa sökningen till specifika domäner eller innehållstyper, till exempel enbart vetenskapliga artiklar, Reddit-diskussioner, nyhetsartiklar eller utvalda webbplatser. Detta är särskilt användbart om du vill ha information från en viss typ av källa eller perspektiv. Om du till exempel forskar på ett vetenskapligt ämne kan du använda Focus Mode för att bara söka bland akademiska källor, vilket säkerställer att svaret baseras på granskad forskning.
Copilot, som finns på Pro och Enterprise-abonnemang, möjliggör djupare utforskning av nyanserade frågor genom vägledd konversation. Istället för att bara besvara din fråga engagerar sig Copilot i en dialog för att förstå kontext, begränsningar och specifika aspekter som är viktiga för dig. Detta interaktiva sätt är särskilt värdefullt vid komplexa forskningsprojekt, konkurrensanalys eller strategisk planering där den första frågan kanske inte helt fångar vad du behöver veta. Copilot hjälper dig att förfina ditt tänkande samtidigt som livesökningar genomförs för att stödja samtalet.
Livesökningsfunktionerna gör Perplexity särskilt värdefullt för marknadsundersökningar och konkurrensanalys. Istället för att manuellt bläddra bland rapporter och webbplatser kan du fråga Perplexity om aktuella trender i din bransch, konkurrenternas aktiviteter eller nya marknadsmöjligheter. Systemet hämtar den senaste informationen från trovärdiga källor och sammanfattar detta till handlingsbara insikter, alltid med källhänvisning som du kan verifiera. Marknadsföringsteam rapporterar att detta tillvägagångssätt avsevärt minskar researchtiden och höjer kvaliteten på insikterna.
Innehållsskapande och sociala medier-strategi gynnas av Perplexitys förmåga att lyfta fram trender och datadrivna idéer. Genom att fråga om aktuella diskussioner, populära innehållsformat eller nya samtal i din nisch kan du identifiera innehållsmöjligheter medan de fortfarande växer. De medföljande hänvisningarna gör att du kan referera till källor i ditt innehåll, vilket stärker trovärdigheten och gynnar SEO-arbetet. Kundinsikter och analys av feedback blir mer effektivt när du kan ladda upp kundrecensioner, enkätsvar eller sociala medier-kommentarer och be Perplexity identifiera nyckelteman, sentiment och förbättringsmöjligheter.
För SEO och innehållsoptimering hjälper Perplexity dig att identifiera strukturer hos topprankat innehåll, mönster i nyckelordsanvändning och luckor i din bransch. Genom att förstå hur framgångsrikt innehåll är uppbyggt och vilka frågor målgruppen ställer kan du skapa innehåll som rankar bättre och ger mer värde. Livesökningsfunktionen innebär att du baserar optimeringsbeslut på aktuella söktrender och konkurrenters strategier—inte på föråldrad information.
Spåra hur ditt varumärke, din domän och dina webbadresser visas i AI-genererade svar över Perplexity, ChatGPT och andra AI-sökmotorer. Få realtidsinsikter om din AI-synlighet.
Upptäck de viktigaste skillnaderna mellan Perplexity och Google. Lär dig hur AI-drivna forskningsmotorer jämförs med traditionella sökmotorer när det gäller fun...
Perplexity AI är en AI-svarsmotor som kombinerar realtidswebbsökning med LLM:er för att leverera källhänvisade, korrekta svar. Lär dig hur det fungerar och dess...
Lär dig mer om Perplexity Pro Search, ett avancerat AI-sökläge som utför flerstegsresonemang och analyserar 20–25+ källor för heltäckande forskning. Upptäck hur...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.