Kunskapsgraf
Lär dig vad en kunskapsgraf är, hur sökmotorer använder dem för att förstå entitetsrelationer och varför de är viktiga för AI-synlighet och varumärkesövervaknin...
14 min läsning

Upptäck vad kunskapsgrafer är, hur de fungerar och varför de är avgörande för modern datalagring, AI-tillämpningar och affärsanalys.
En kunskapsgraf är ett strukturerat nätverk som kopplar samman dataentiteter genom definierade relationer, vilket gör det möjligt för både maskiner och människor att förstå komplexa informationsmönster. Den är viktig eftersom den omvandlar rådata till handlingsbara insikter, driver AI-tillämpningar, förbättrar söknoggrannhet och gör det möjligt för organisationer att bryta ned datasilos för bättre beslutsfattande.
En kunskapsgraf är en strukturerad, sammankopplad representation av dataentiteter och deras relationer, organiserad som ett nätverk av noder och kanter. Till skillnad från traditionella relationsdatabaser som bygger på stela, fördefinierade strukturer, modellerar kunskapsgrafer information som ett semantiskt nät där varje punkt (nod) representerar en entitet—till exempel en person, plats, produkt eller ett begrepp—och varje koppling (kant) illustrerar hur dessa entiteter förhåller sig till varandra. Denna grundläggande skillnad gör det möjligt för både människor och maskiner att tolka, fråga och resonera kring data på sätt som tidigare var omöjliga med konventionella databassystem.
Begreppet fick stor spridning när Google introducerade sin Knowledge Graph 2012, vilket revolutionerade sökresultat genom att ge direkta svar och visa kopplingar mellan begrepp snarare än att bara lista relevanta länkar. Kunskapsgrafer har dock utvecklats långt bortom konsumentsökapplikationer. Idag använder organisationer inom alla branscher kunskapsgrafer för att organisera komplex information, driva artificiell intelligens och hitta dolda mönster i sina dataekosystem. Styrkan i en kunskapsgraf ligger i dess förmåga att fånga kontext, ursprung och betydelse över hela datalandskapet, vilket gör den till ett oumbärligt verktyg för moderna företag som vill skapa konkurrensfördelar genom intelligent datastyrning.
Varje kunskapsgraf består av fyra grundläggande komponenter som tillsammans skapar ett heltäckande, sökbart informationssystem:
| Komponent | Definition | Exempel |
|---|---|---|
| Entiteter (Noder) | Objekt eller begrepp som beskrivs med unika identifierare | “Albert Einstein”, “Apple Inc.”, “New York City” |
| Relationer (Kanter) | Kopplingar mellan noder som visar hur entiteter interagerar | “Albert Einstein uppfann relativitetsteorin” |
| Attribut (Egenskaper) | Egenskaper som beskriver noder och ger kontext | Födelsedatum: 14 mars 1879; Plats: Berlin, Tyskland |
| Ontologier & Scheman | Formella definitioner och regler som styr entitetstyper och relationer | RDF Schema (RDFS), Web Ontology Language (OWL), Schema.org |
Entiteter utgör grunden i varje kunskapsgraf och representerar verkliga objekt på ett strukturerat och organiserat sätt. Varje entitet har en unik identifierare och kan ha flera egenskaper och relationer till andra entiteter. Relationer, även kallade kanter, är de kopplingar som binder samman entiteter och uttrycker hur de samverkar och relaterar till varandra. Dessa relationer kan vara riktade (från en entitet till en annan, som “John arbetar på Google”) eller oriktade (ömsesidiga kopplingar, som “John och Mary är vänner”). Utöver enkla kopplingar kan relationer representera hierarkiska strukturer, orsakssamband, sekventiella beroenden eller nätverksbaserade interaktioner.
Attribut eller egenskaper ger ytterligare beskrivande information om entiteter, vilket hjälper till att särskilja dem från liknande entiteter i nätverket. Dessa kan variera från enkla kännetecken som ålder eller plats till komplexa, domänspecifika egenskaper som medicinska tillstånd, finansiella mått eller tekniska specifikationer. Slutligen fastställer ontologier och scheman den formella ramen som styr hur entiteter, relationer och attribut definieras och används. Vanliga ontologier är bland annat RDF Schema (RDFS) för grundläggande hierarkier, Web Ontology Language (OWL) för avancerad logik och Schema.org för standardiserad webbdata. Dessa komponenter samverkar för att skapa ett flexibelt och utbyggbart system som kan representera kunskap inom praktiskt taget vilket område som helst.
Kunskapsgrafer fungerar genom att skapa ett semantiskt lager över organisationens dataekosystem och omvandlar olika datakällor till ett enhetligt, sammankopplat kunskapsnätverk. När data matas in i en kunskapsgraf använder maskininlärningsalgoritmer med naturlig språkbehandling (NLP) en process som kallas semantisk berikning. Denna process identifierar individuella objekt i datan och förstår automatiskt relationerna mellan olika objekt, även när de kommer från källor med olika struktur. Det semantiska lagret är särskilt kraftfullt eftersom det kan särskilja ord med flera betydelser—till exempel att förstå att “Apple” i ett sammanhang avser teknikföretaget medan det i ett annat syftar på frukten.
När kunskapsgrafen är uppbyggd gör den det möjligt för avancerade frågesystem och sökfunktioner att leverera heltäckande svar på komplexa frågor. Istället för att kräva exakta nyckelordsmatchningar kan semantiska söksystem förstå användarens avsikt och leverera relaterad information även om specifika termer inte uttryckligen används. Denna kontextuella förståelse uppnås tack vare grafens förmåga att explicit modellera relationer och beroenden. Dataintegrationsarbetet kring kunskapsgrafer genererar också ny kunskap genom att skapa kopplingar mellan tidigare orelaterade datapunkter, vilket avslöjar insikter som inte hade varit synliga i isolerade datamängder. För organisationer innebär detta att kunskapsgrafer kan eliminera manuellt datainsamlings- och integrationsarbete, påskynda affärsbeslut och möjliggöra självbetjäning där verksamhetsanvändare kan fråga grafen direkt utan IT-stöd.
Kunskapsgrafer har blivit allt viktigare för moderna organisationer av flera övertygande skäl. Snabbare beslutsfattande är en av de mest påtagliga fördelarna—kunskapsgrafer ger en 360-graders vy av dataentiteter och deras relationer, vilket gör att analytiker snabbt kan identifiera mönster, samband och insikter som skulle ta betydligt längre tid att upptäcka med traditionella analysmetoder. Detta helhetsgrepp gör det möjligt för organisationer att fatta välgrundade beslut baserade på komplett information istället för fragmenterade datavyer.
Förbättrad kundupplevelse är en annan avgörande fördel. Genom att koppla samman kunddata från olika kontaktpunkter—inklusive köphistorik, supportärenden, surfbeteende och demografisk information—kan organisationer skapa detaljerade kundprofiler som möjliggör personliga och relevanta upplevelser. Denna samlade bild stödjer riktad marknadsföring, produktrekommendationer och proaktiv kundservice. Effektiv datastyrning uppnås tack vare kunskapsgrafens förmåga att länka och harmonisera data från olika källor, vilket bryter ned organisatoriska silos som annars försvårar effektiv datadelning och samarbete. Genom att tillämpa bästa praxis för databereddning och utnyttja kunskapsgrafens semantiska styrka får organisationer en betydande konkurrensfördel.
Att ge verksamhetsanvändare ökad självservice demokratiserar dataåtkomst i hela organisationen. Istället för att förlita sig på IT-avdelningen för att besvara varje databasfråga kan verksamhetsanvändare själva interagera med och fråga kunskapsgrafer med hjälp av intuitiva visualiseringsverktyg, vilket påskyndar insiktsgenerering och minskar flaskhalsar. Accelererad AI och maskininlärning gynnas enormt av kunskapsgrafens strukturerade, semantiska natur. Den sammankopplade datan utgör idealiskt träningsmaterial för AI-system, vilket gör det möjligt att upptäcka komplexa mönster, trender och utfall samtidigt som tid och kostnad för modellutveckling minskar. Kunskapsgrafer stödjer också avancerade tillämpningar som Retrieval-Augmented Generation (RAG), där AI-system kan utnyttja komplexa relationer i stora datamängder för att resonera mer som människor och leverera mer korrekta och kontextuellt relevanta svar.
Kunskapsgrafer har gått från teoretiska koncept till att leverera påtagligt värde i många sektorer. Inom hälso- och sjukvård samt life science använder medicinska forskningsnätverk och kliniska beslutsstöd kunskapsgrafer för att koppla samman symtom, behandlingar, utfall och medicinsk litteratur, vilket hjälper kliniker och forskare att hitta insikter som förbättrar patientvård och snabbar på läkemedelsutveckling. Finansiella tjänster använder kunskapsgrafer för kundkännedom (KYC) och bekämpning av penningtvätt, genom att kartlägga relationer mellan personer, konton och transaktioner för att upptäcka misstänkta aktiviteter och förebygga ekonomisk brottslighet. Detaljhandel och e-handel använder kunskapsgrafer för att driva rekommendationssystem och merförsäljningsstrategier, genom att analysera köpbeteende och demografiska trender för att föreslå produkter som kunderna sannolikt vill köpa.
Underhållningsplattformar som Netflix, Spotify och Amazon använder kunskapsgrafer för att bygga avancerade rekommendationsmotorer som analyserar användarengagemang och innehållsrelationer för att föreslå filmer, musik och produkter anpassade efter individuella preferenser. Optimering av leveranskedjor är ytterligare en kraftfull tillämpning, där kunskapsgrafer modellerar komplexa leverantörsrelationer, logistiknätverk och varuflöden, vilket möjliggör realtidsupptäckt av flaskhalsar och riskhantering. Regeluppfyllelse och styrning gynnas av kunskapsgrafers förmåga att automatiskt spåra dataursprung, matcha dataentiteter mot system och policys samt visa efterlevnad av regelverk som GDPR och HIPAA. En kunskapsgraf kan till exempel omedelbart visa alla platser där personuppgifter (PII) lagras, vilka applikationer som når dem och vilka integritetspolicys som gäller—avgörande funktioner för modern datastyrning.
Trots kunskapsgrafers stora fördelar måste organisationer noggrant hantera flera utmaningar för att lyckas med implementeringen. Datakvalitet och kurering är en ständigt aktuell fråga, eftersom kunskapsgrafens noggrannhet och fullständighet direkt påverkar kvaliteten på de insikter den genererar. Organisationer måste införa processer för att validera data, lösa inkonsekvenser och säkerställa att data hålls uppdaterad när ny information tillkommer. Skalbarhet och underhåll utgör tekniska utmaningar, särskilt när kunskapsgrafer växer till att omfatta miljontals eller miljarder entiteter och relationer. Det krävs noggrann arkitekturplanering och investeringar i infrastruktur för att säkerställa god sökprestanda och hantering av ökande datamängder.
Entitetsupplösning—att identifiera när olika datarepresentationer avser samma verkliga entitet—är ett komplext problem som kan ha stor inverkan på kunskapsgrafens kvalitet. Integritet och säkerhet blir allt viktigare när kunskapsgrafer innehåller känsliga eller personliga data, vilket kräver robusta åtkomstkontroller, kryptering och efterlevnadsmekanismer. Bias i kunskapsgrafer kan vidmakthålla eller förstärka befintliga snedvridningar i källdata, vilket kan leda till orättvisa eller diskriminerande resultat i AI-tillämpningar som använder grafen. Organisationer måste införa noggrann övervakning och styrning för att identifiera och motverka bias. Trots dessa utmaningar är kunskapsgrafers strategiska värde så stort att de är värda investeringen för organisationer som verkligen vill använda data som en konkurrenstillgång.
Kunskapsgrafer markerar ett grundläggande skifte i hur organisationer hanterar, styr och utvinner värde ur sin data. Genom att förvandla statiska datalager till levande, sammankopplade kunskapsnätverk möjliggör de smartare upptäckt, robust styrning och AI-förberedda dataekosystem. I takt med att artificiell intelligens fortsätter att utvecklas och organisationer samlar på sig allt större datamängder kommer kunskapsgrafens betydelse bara att öka. De utgör det kontextuella fundament som krävs för avancerad analys, maskininlärning och AI-förklarbarhet—och gör det möjligt att upptäcka dolda mönster, automatisera resonemang och stödja beslutsfattande i stor skala. För alla organisationer som vill förbättra sina AI-förmågor, stärka kundupplevelser eller skapa konkurrensfördelar genom bättre dataanvändning, bör kunskapsgraflösningar vara en strategisk prioritet i den digitala transformationsplanen.
Precis som kunskapsgrafer organiserar information intelligent, spårar vår AI-övervakningsplattform hur ditt varumärke syns över ChatGPT, Perplexity och andra AI-sökmotorer. Säkerställ din varumärkessynlighet i den AI-drivna framtiden.
Lär dig vad en kunskapsgraf är, hur sökmotorer använder dem för att förstå entitetsrelationer och varför de är viktiga för AI-synlighet och varumärkesövervaknin...

Diskussion i communityn som förklarar Knowledge Graphs och deras betydelse för synlighet i AI-sök. Experter delar med sig av hur entiteter och relationer påverk...
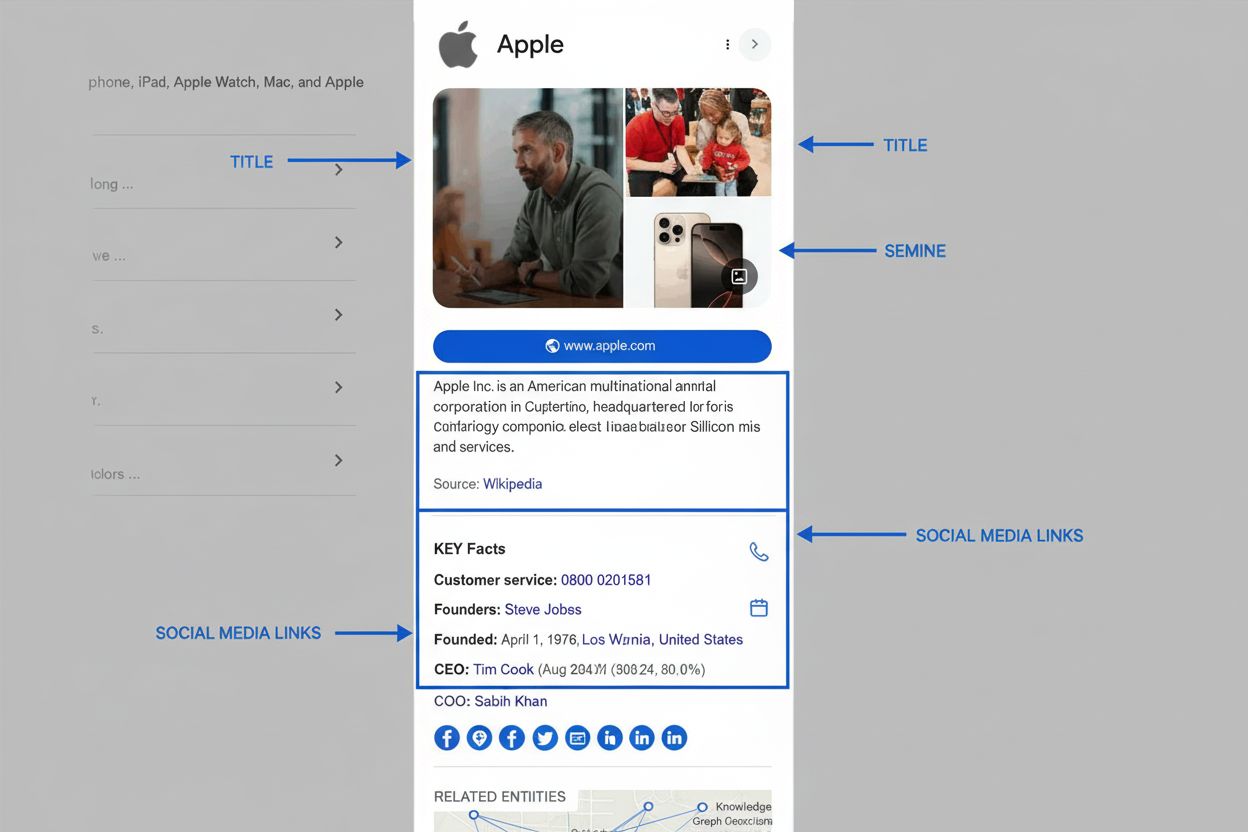
Lär dig vad en kunskapspanel är, hur den fungerar, varför den är viktig för SEO och AI-övervakning samt hur du kan göra anspråk på eller optimera en för ditt va...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.