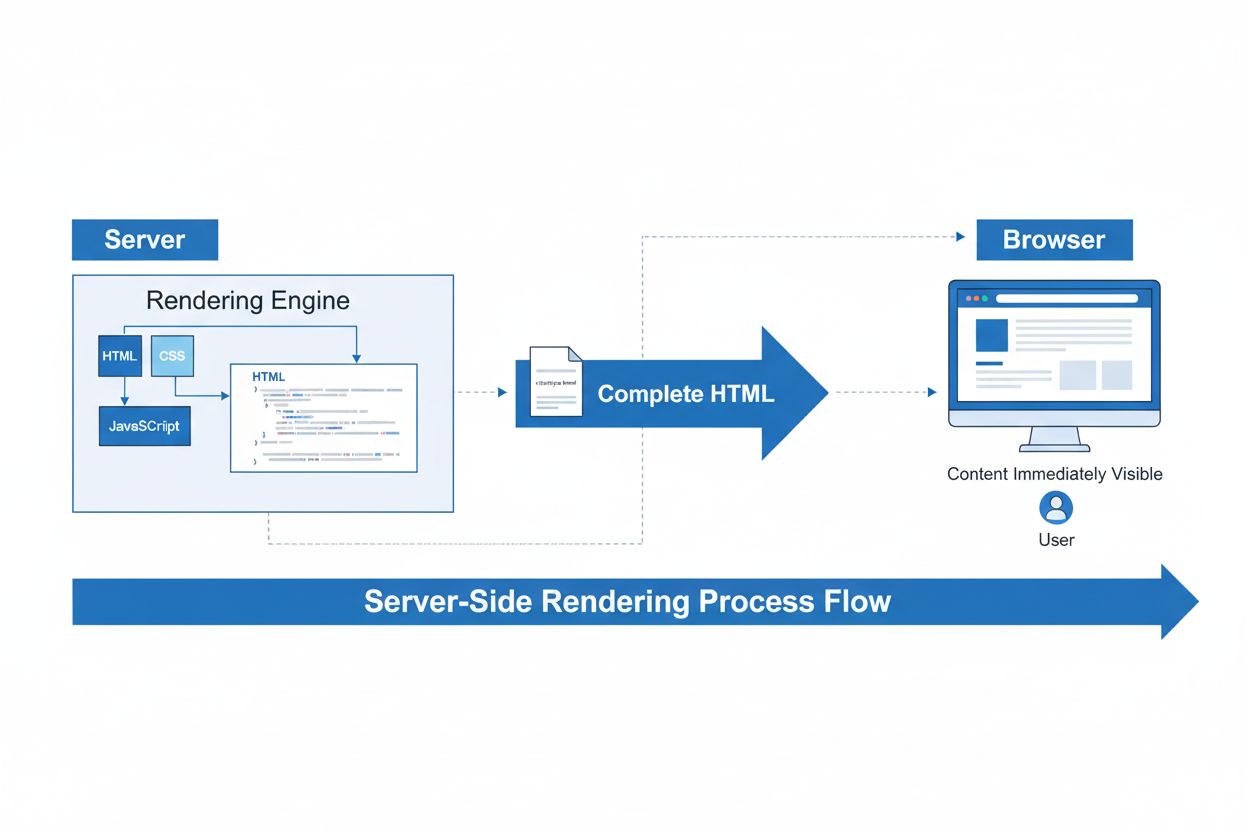
Server-Side Rendering (SSR)
Server-Side Rendering (SSR) är en webbteknik där servrar renderar kompletta HTML-sidor innan de skickas till webbläsare. Lär dig hur SSR förbättrar SEO, sidans ...
10 min läsning

Lär dig hur server-side rendering möjliggör effektiv AI-bearbetning, modellimplementering och realtidsinferenstjänster för AI-drivna applikationer och LLM-arbetsbelastningar.
Server-side rendering för AI är ett arkitektoniskt tillvägagångssätt där artificiella intelligensmodeller och inferensbearbetning sker på servern istället för på klientenheter. Detta möjliggör effektiv hantering av beräkningsintensiva AI-uppgifter, säkerställer konsekvent prestanda för alla användare och förenklar modellimplementering och uppdateringar.
Server-side rendering för AI syftar på ett arkitekturmönster där artificiella intelligensmodeller, inferensbearbetning och beräkningsuppgifter körs på backend-servrar istället för på klientenheter som webbläsare eller mobiltelefoner. Detta tillvägagångssätt skiljer sig fundamentalt från traditionell klientrendering, där JavaScript körs i användarens webbläsare för att generera innehåll. I AI-applikationer innebär server-side rendering att stora språkmodeller (LLM), maskininlärningsinferens och AI-genererat innehåll hanteras centralt på kraftfull serverinfrastruktur innan resultaten skickas till användarna. Detta arkitektoniska skifte har blivit allt viktigare i takt med att AI-förmågorna blivit mer beräkningskrävande och centrala för moderna webbapplikationer.
Konceptet växte fram ur insikten om en avgörande skillnad mellan vad moderna AI-applikationer kräver och vad klientenheter realistiskt kan leverera. Traditionella webbframeworks som React, Angular och Vue.js populariserade klientrendering under 2010-talet, men detta tillvägagångssätt skapar stora utmaningar när det gäller AI-tunga arbetsbelastningar. Server-side rendering för AI adresserar dessa utmaningar genom att utnyttja specialiserad hårdvara, centraliserad modellhantering och optimerad infrastruktur som klientenheter helt enkelt inte kan matcha. Detta representerar ett fundamentalt paradigmskifte i hur utvecklare bygger AI-drivna applikationer.
De beräkningsmässiga kraven hos moderna AI-system gör server-side rendering inte bara fördelaktigt utan ofta nödvändigt. Klientenheter, särskilt smartphones och enklare laptops, saknar processorkraft för att effektivt hantera realtidsinferens för AI. När AI-modeller körs på klientenheter upplever användarna märkbara fördröjningar, ökad batteriförbrukning och varierande prestanda beroende på deras hårdvarukapacitet. Server-side rendering eliminerar dessa problem genom att centralisera AI-bearbetningen på infrastruktur utrustad med GPU:er, TPU:er och specialiserade AI-acceleratorer som erbjuder betydligt bättre prestanda än konsumentenheter.
Utöver rå prestanda erbjuder server-side rendering för AI avgörande fördelar inom modellhantering, säkerhet och konsistens. När AI-modeller körs på servrar kan utvecklare uppdatera, finjustera och distribuera nya versioner omedelbart utan att användarna behöver ladda ner uppdateringar eller hantera olika modellversioner lokalt. Detta är särskilt viktigt för stora språkmodeller och maskininlärningssystem som utvecklas snabbt med täta förbättringar och säkerhetspatchar. Dessutom förhindras otillåten åtkomst, modellextraktion och stöld av immateriella rättigheter när modellerna hålls på servrarna istället för att distribueras till klientenheter.
| Aspekt | Klientbaserad AI | Serverbaserad AI |
|---|---|---|
| Bearbetningsplats | Användarens webbläsare eller enhet | Backend-servrar |
| Hårdvarukrav | Begränsat till enhetens kapacitet | Specialiserade GPU:er, TPU:er, AI-acceleratorer |
| Prestanda | Varierande, enhetsberoende | Konsekvent, optimerad |
| Modelluppdateringar | Kräver nedladdning av användaren | Omedelbar distribution |
| Säkerhet | Modeller exponerade för extraktion | Modeller skyddade på servrar |
| Latens | Beroende av enhetens kraft | Optimerad infrastruktur |
| Skalbarhet | Begränsad per enhet | Mycket skalbar mellan användare |
| Utvecklingskomplexitet | Hög (enhetsfragmentering) | Låg (centraliserad hantering) |
Nätverksöverhead och latens utgör betydande utmaningar i AI-applikationer. Moderna AI-system kräver konstant kommunikation med servrar för modelluppdateringar, hämtning av träningsdata och hybrida bearbetningsscenarion. Klientrendering ökar ironiskt nog nätverksförfrågningarna jämfört med traditionella applikationer, vilket minskar de prestandavinster som klientbaserad bearbetning var tänkt att ge. Server-side rendering samlar dessa kommunikationer, minskar rundresans fördröjning och möjliggör realtids-AI-funktioner som översättning, innehållsgenerering och datorsynsbearbetning att fungera smidigt utan latensproblemen från klientbaserad inferens.
Synkroniseringskomplexitet uppstår när AI-applikationer behöver upprätthålla tillståndskonsistens över flera AI-tjänster samtidigt. Moderna applikationer använder ofta embeddingstjänster, kompletteringsmodeller, finjusterade modeller och specialiserade inferensmotorer som måste samordnas. Att hantera detta distribuerade tillstånd på klientenheter introducerar betydande komplexitet och risk för datainkonsistens, särskilt i realtidssamarbetande AI-funktioner. Server-side rendering centraliserar denna tillståndshantering, säkerställer att alla användare ser konsekventa resultat och eliminerar det tekniska överhänget av komplex klientbaserad synkronisering.
Enhetsfragmentering skapar omfattande utvecklingsutmaningar för klientbaserad AI. Olika enheter har varierande AI-funktioner såsom Neurala processorenheter, GPU-acceleration, WebGL-stöd och minnesbegränsningar. Att skapa konsekventa AI-upplevelser över denna fragmenterade miljö kräver mycket utvecklingsarbete, strategier för graciös nedgradering och flera kodvägar för olika enhetskapaciteter. Server-side rendering eliminerar denna fragmentering helt genom att säkerställa att alla användare får tillgång till samma optimerade AI-bearbetningsinfrastruktur, oavsett deras enhetsspecifikationer.
Server-side rendering möjliggör enklare och mer underhållbara AI-applikationsarkitekturer genom att centralisera kritisk funktionalitet. Istället för att distribuera AI-modeller och inferenslogik över tusentals klientenheter underhåller utvecklare en enda, optimerad implementation på servrarna. Denna centralisering ger omedelbara fördelar såsom snabbare distributionscykler, enklare felsökning och mer rättfram prestandaoptimering. När en AI-modell behöver förbättras eller ett fel hittas, åtgärdas det en gång på servern istället för att försöka driva ut uppdateringar till miljontals klientenheter med varierande uppdateringstakt.
Resurseffektiviteten förbättras dramatiskt med server-side rendering. Serverinfrastruktur möjliggör effektiv resursdelning mellan alla användare, med anslutningspoolning, cache-strategier och lastbalansering som optimerar hårdvaruanvändningen. En enda GPU på en server kan bearbeta inferensförfrågningar från tusentals användare sekventiellt, medan samma kapacitet på klientenheter hade krävt miljontals GPU:er. Denna effektivitet leder till lägre driftkostnader, minskad miljöpåverkan och bättre skalbarhet när applikationer växer.
Säkerhet och skydd av immateriella rättigheter blir betydligt enklare med server-side rendering. AI-modeller representerar stora investeringar i forskning, träningsdata och beräkningsresurser. Att behålla modeller på servrar förhindrar angrepp för modellextraktion, obehörig åtkomst och stöld av immateriella rättigheter som annars är möjligt när modeller distribueras till klientenheter. Dessutom möjliggör serverbaserad bearbetning detaljerad åtkomstkontroll, loggning av åtgärder och regelefterlevnadsövervakning som vore omöjliga att upprätthålla på distribuerade klientenheter.
Moderna ramverk har utvecklats för att effektivt stödja server-side rendering för AI-arbetsbelastningar. Next.js leder denna utveckling med Server Actions som möjliggör sömlös AI-bearbetning direkt från serverkomponenter. Utvecklare kan anropa AI-API:er, bearbeta stora språkmodeller och strömma svar tillbaka till klienten med minimal uppstartskod. Ramverket hanterar komplexiteten kring server-klient-kommunikation så att utvecklare kan fokusera på AI-logik istället för infrastrukturfrågor.
SvelteKit erbjuder ett prestandafokuserat tillvägagångssätt för serverbaserad AI-rendering med sina load-funktioner som körs på servern före rendering. Detta möjliggör förbearbetning av AI-data, generering av rekommendationer och förberedelse av AI-förstärkt innehåll innan HTML skickas till klienten. Resultatet blir applikationer med minimalt JavaScript-innehåll men full AI-kapacitet, vilket ger extremt snabba användarupplevelser.
Specialiserade verktyg som Vercel AI SDK abstraherar bort komplexiteten i att strömma AI-svar, hantera tokenräkning och olika AI-leverantörers API:er. Dessa verktyg gör det möjligt för utvecklare att bygga sofistikerade AI-applikationer utan djup infrastrukturkunskap. Infrastrukturval som Vercel Edge Functions, Cloudflare Workers och AWS Lambda erbjuder globalt distribuerad serverbaserad AI-bearbetning, vilket minskar latensen genom att behandla förfrågningar närmare användarna samtidigt som centraliserad modellhantering bibehålls.
Effektiv serverbaserad AI-rendering kräver sofistikerade cache-strategier för att hantera beräkningskostnader och latens. Redis-cache lagrar ofta förfrågade AI-svar och användarsessioner, vilket eliminerar onödig bearbetning för liknande frågor. CDN-cache distribuerar statiskt AI-genererat innehåll globalt, så att användare får svar från geografiskt närliggande servrar. Edge-cachningsstrategier distribuerar AI-bearbetat innehåll över edge-nätverk, vilket ger ultralåg latens samtidigt som centraliserad modellhantering bevaras.
Dessa cache-approacher samverkar för att skapa effektiva AI-system som kan skalas till miljontals användare utan motsvarande ökning av beräkningskostnader. Genom att cache:a AI-svar på flera nivåer kan applikationer leverera majoriteten av förfrågningarna från cache och endast beräkna nya svar för verkligt nya frågor. Detta minskar dramatiskt infrastrukturkostnaderna och förbättrar användarupplevelsen genom snabbare svarstider.
Utvecklingen mot server-side rendering representerar en mognad av webbutvecklingsmetoder i takt med AI-kraven. I takt med att AI blir centralt för webbapplikationer kräver de beräkningsmässiga realiteterna servercentrisk arkitektur. Framtiden innebär avancerade hybrida tillvägagångssätt som automatiskt avgör var rendering ska ske baserat på innehållstyp, enhetskapacitet, nätverksförhållanden och AI-bearbetningskrav. Ramverk kommer successivt att förbättra applikationer med AI-förmågor och säkerställa att kärnfunktionaliteten fungerar universellt samtidigt som upplevelsen förbättras där det är möjligt.
Detta paradigmskifte bygger vidare på lärdomar från Single Page Application-eran samtidigt som det adresserar AI-inhemska applikationsutmaningar. Verktygen och ramverken är redo för utvecklare att dra nytta av server-side rendering i AI-eran och möjliggör nästa generation av intelligenta, responsiva och effektiva webbapplikationer.
Följ hur din domän och ditt varumärke syns i AI-genererade svar i ChatGPT, Perplexity och andra AI-sökmotorer. Få insikter i realtid om din AI-synlighet.
Server-Side Rendering (SSR) är en webbteknik där servrar renderar kompletta HTML-sidor innan de skickas till webbläsare. Lär dig hur SSR förbättrar SEO, sidans ...
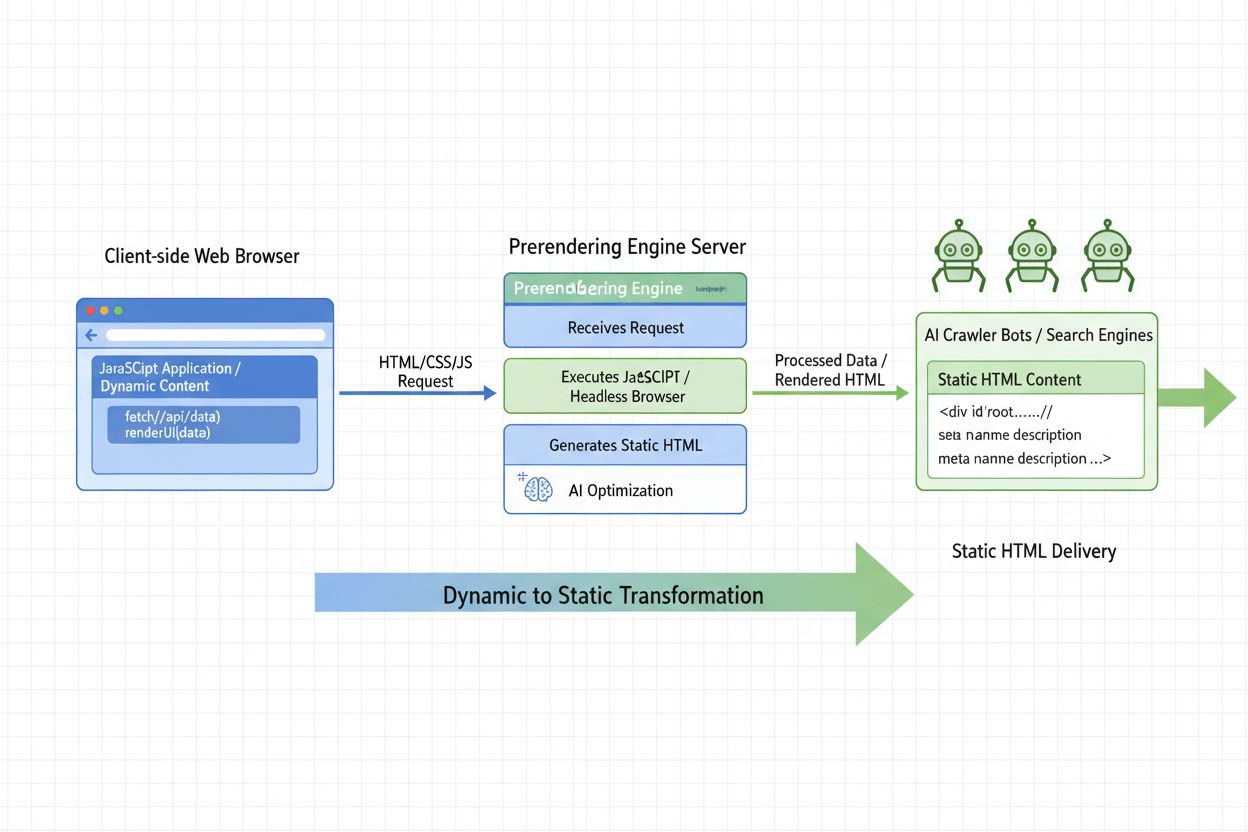
Lär dig vad AI-förgenerering är och hur server-side-renderingsstrategier optimerar din webbplats för AI-crawlers synlighet. Upptäck implementeringsstrategier fö...

Lär dig hur för-rendering hjälper din webbplats att synas i AI-sökresultat från ChatGPT, Perplexity och Claude. Förstå den tekniska implementeringen och fördela...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.