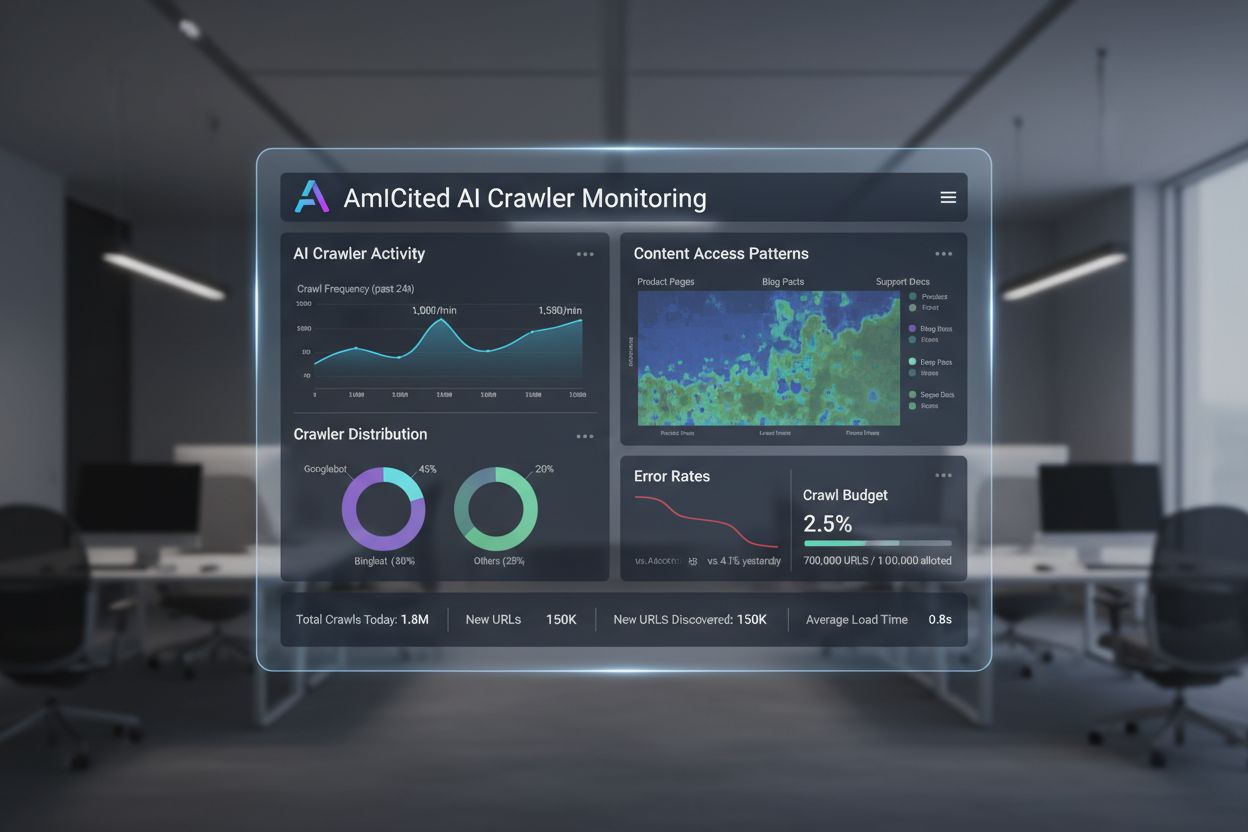
AI Crawl Analytics
Lär dig vad AI crawl analytics är och hur serverloggsanalys spårar AI-crawlers beteende, mönster för innehållsåtkomst och synlighet i AI-drivna sökplattformar s...
9 min läsning
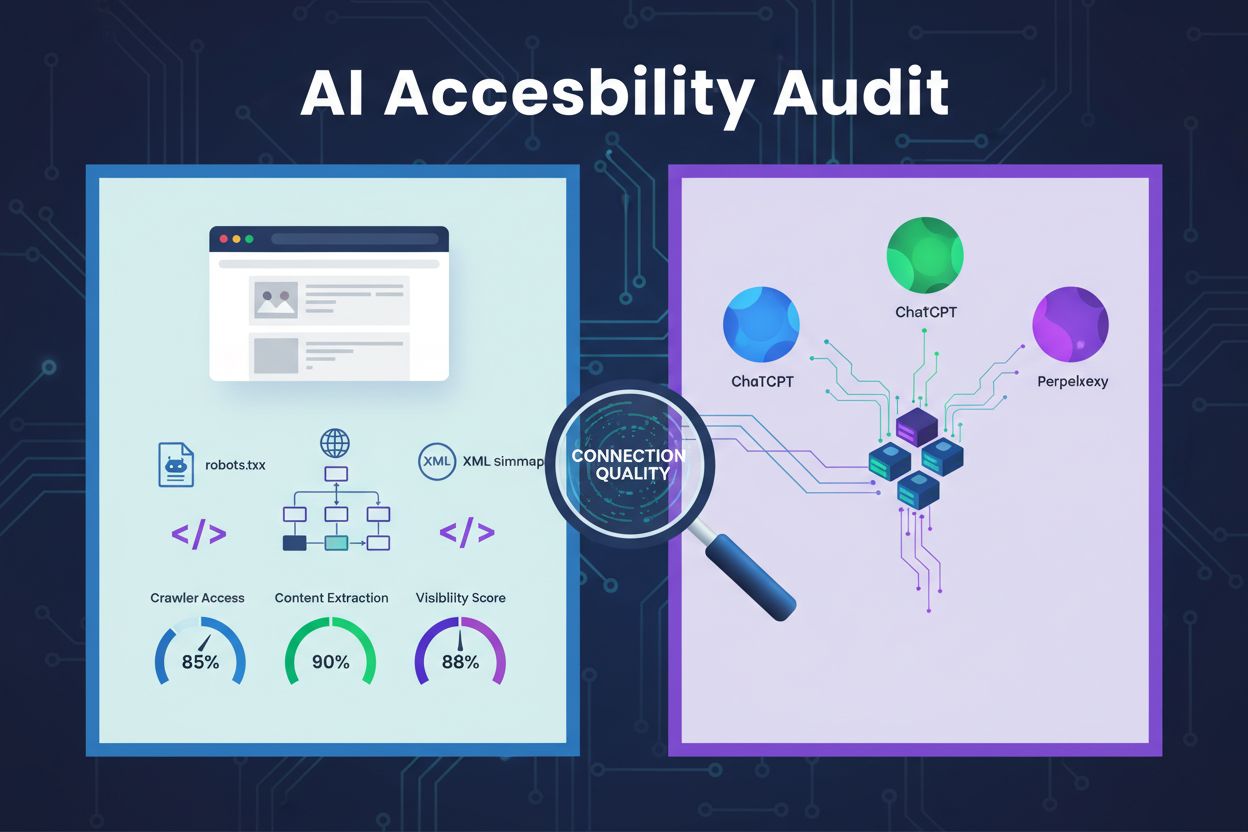
En teknisk granskning av webbplatsens arkitektur, konfiguration och innehållsstruktur för att avgöra om AI-crawlers effektivt kan komma åt, förstå och extrahera innehåll. Utvärderar robots.txt-konfiguration, XML-sitemaps, webbplatsens genomsökningsbarhet, JavaScript-rendering och förmåga till innehållsextraktion för att säkerställa synlighet på AI-drivna sökplattformar som ChatGPT, Claude och Perplexity.
En teknisk granskning av webbplatsens arkitektur, konfiguration och innehållsstruktur för att avgöra om AI-crawlers effektivt kan komma åt, förstå och extrahera innehåll. Utvärderar robots.txt-konfiguration, XML-sitemaps, webbplatsens genomsökningsbarhet, JavaScript-rendering och förmåga till innehållsextraktion för att säkerställa synlighet på AI-drivna sökplattformar som ChatGPT, Claude och Perplexity.
En AI-tillgänglighetsgranskning är en teknisk genomgång av din webbplats arkitektur, konfiguration och innehållsstruktur för att avgöra om AI-crawlers effektivt kan komma åt, förstå och extrahera ditt innehåll. Till skillnad från traditionella SEO-granskningar som fokuserar på nyckelordsrankningar och bakåtlänkar, undersöker AI-tillgänglighetsgranskningar de tekniska grunderna som gör att AI-system som ChatGPT, Claude och Perplexity kan upptäcka och citera ditt innehåll. Granskningen utvärderar avgörande komponenter såsom robots.txt-konfiguration, XML-sitemaps, webbplatsens genomsökningsbarhet, JavaScript-rendering och innehållsextraktion för att säkerställa att din webbplats är fullt synlig i det AI-drivna sökekosystemet.
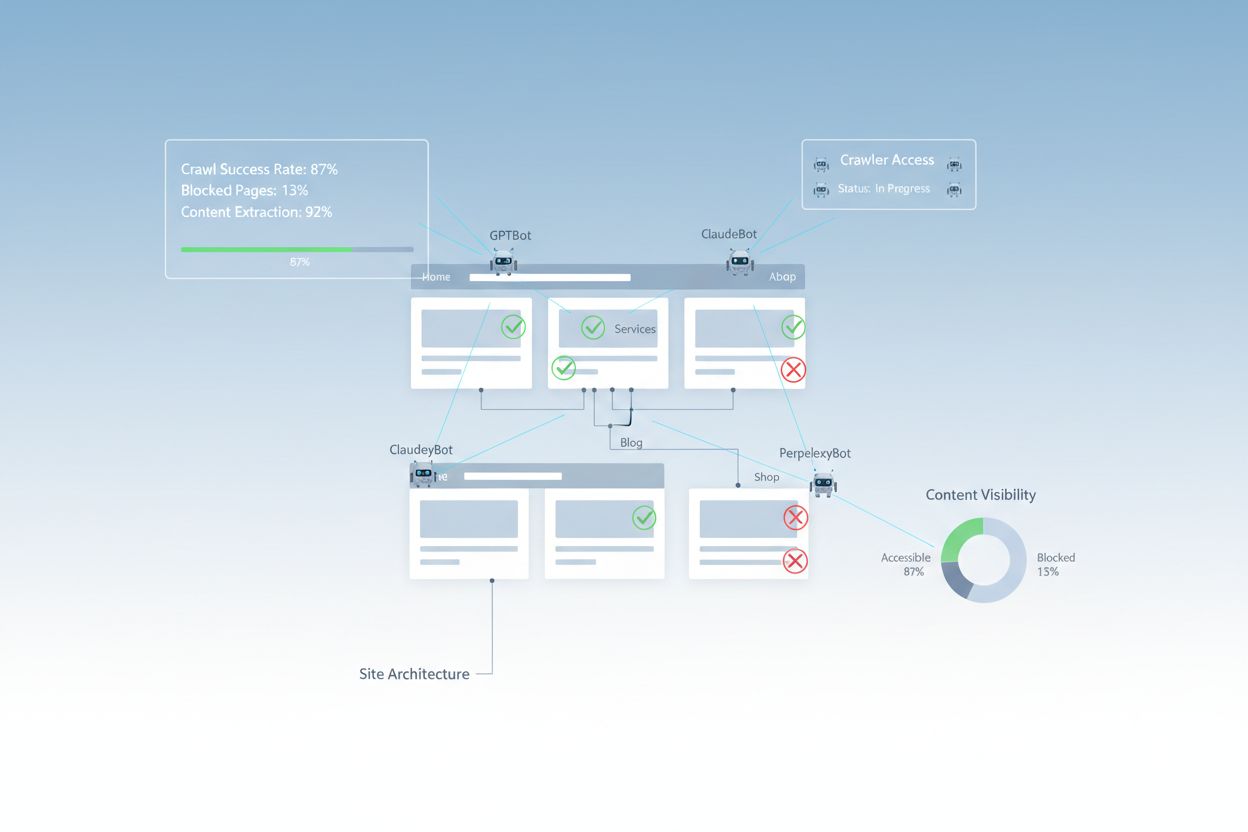
Trots framsteg inom webbteknik stöter AI-crawlers på betydande hinder när de försöker komma åt moderna webbplatser. Den största utmaningen är att många nutida webbplatser är starkt beroende av JavaScript-rendering för att visa innehåll dynamiskt, men de flesta AI-crawlers kan inte köra JavaScript-kod. Detta innebär att cirka 60–90 % av modernt webbplatsinnehåll förblir osynligt för AI-system, även om det visas perfekt i användares webbläsare. Dessutom blockerar säkerhetsverktyg som Cloudflare AI-crawlers som standard och behandlar dem som potentiella hot snarare än legitima indexeringsrobotar. Forskning visar att 35 % av företagswebbplatser oavsiktligt blockerar AI-crawlers, vilket förhindrar att värdefullt innehåll upptäcks och citeras av AI-system.
Vanliga hinder som förhindrar AI-crawleråtkomst inkluderar:
En omfattande AI-tillgänglighetsgranskning undersöker flera tekniska och strukturella element som påverkar hur AI-system interagerar med din webbplats. Varje komponent spelar en egen roll i om ditt innehåll blir synligt på AI-drivna sökplattformar. Granskningsprocessen innebär testning av genomsökningsbarhet, verifiering av konfigurationsfiler, bedömning av innehållsstruktur och övervakning av faktiskt crawlerbeteende. Genom att systematiskt utvärdera dessa komponenter kan du identifiera specifika hinder och implementera riktade lösningar för att förbättra din AI-synlighet.
| Komponent | Syfte | Påverkan på AI-synlighet |
|---|---|---|
| Robots.txt-konfiguration | Styr vilka crawlers som får tillgång till specifika webbplatsdelar | Avgörande – Felkonfiguration blockerar AI-crawlers helt |
| XML-sitemaps | Guider crawlers till viktiga sidor och innehållsstruktur | Hög – Hjälper AI-system att prioritera och upptäcka innehåll |
| Webbplatsens genomsökningsbarhet | Säkerställer att sidor är åtkomliga utan autentisering eller komplex navigering | Avgörande – Blockerade sidor är osynliga för AI-system |
| JavaScript-rendering | Avgör om dynamiskt innehåll är synligt för crawlers | Avgörande – 60–90 % av innehållet kan missas utan förrendering |
| Innehållsextraktion | Bedömer hur lätt AI-system kan tolka och förstå innehåll | Hög – Dålig struktur minskar citeringsmöjligheter |
| Konfiguration av säkerhetsverktyg | Hanterar brandvägg och skyddsregler som påverkar crawleråtkomst | Avgörande – För restriktiva regler blockerar legitima AI-botar |
| Implementering av schema markup | Ger maskinläsbar kontext om innehållet | Medel – Förbättrar AI-förståelse och citeringsmöjlighet |
| Intern länkstruktur | Skapar semantiska relationer mellan sidor | Medel – Hjälper AI att förstå ämnesauktoritet och relevans |
Din robots.txt-fil är den primära mekanismen för att styra vilka crawlers som får tillgång till din webbplats. Filen ligger i roten av din domän och innehåller direktiv som talar om för crawlers om de får komma åt specifika delar av din webbplats. För AI-tillgänglighet är korrekt robots.txt-konfiguration avgörande eftersom felaktiga regler helt kan blockera stora AI-crawlers som GPTBot (OpenAI), ClaudeBot (Anthropic) och PerplexityBot (Perplexity). Nyckeln är att uttryckligen tillåta dessa crawlers samtidigt som du skyddar känsliga områden och blockerar skadliga botar.
Exempel på robots.txt-konfiguration för AI-crawlers:
# Tillåt alla AI-crawlers
User-agent: GPTBot
User-agent: ChatGPT-User
User-agent: ClaudeBot
User-agent: Claude-Web
User-agent: PerplexityBot
User-agent: Google-Extended
Allow: /
# Blockera känsliga områden
Disallow: /admin/
Disallow: /private/
Disallow: /api/
# Sitemaps
Sitemap: https://yoursite.com/sitemap.xml
Sitemap: https://yoursite.com/ai-sitemap.xml
Denna konfiguration tillåter uttryckligen större AI-crawlers att komma åt ditt offentliga innehåll och skyddar samtidigt administrativa och privata delar. Sitemap-direktiven hjälper crawlers att effektivt hitta dina viktigaste sidor.
En XML-sitemap fungerar som en karta för crawlers och listar de URL:er du vill få indexerade samt metadata om varje sida. För AI-system är sitemaps särskilt värdefulla eftersom de hjälper crawlers att förstå webbplatsens struktur, prioritera viktigt innehåll och hitta sidor som annars kan missas vid vanlig crawling. Till skillnad från traditionella sökmotorer som kan dra slutsatser om webbplatsstruktur via länkar, drar AI-crawlers stor nytta av tydlig vägledning om vilka sidor som är viktigast. En välstrukturerad sitemap med korrekt metadata ökar sannolikheten att ditt innehåll upptäcks, förstås och citeras av AI-system.
Exempel på XML-sitemapstruktur för AI-optimering:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<!-- Högprioriterat innehåll för AI-crawlers -->
<url>
<loc>https://yoursite.com/about</loc>
<lastmod>2025-01-03</lastmod>
<priority>1.0</priority>
</url>
<url>
<loc>https://yoursite.com/products</loc>
<lastmod>2025-01-03</lastmod>
<priority>0.9</priority>
</url>
<url>
<loc>https://yoursite.com/blog/ai-guide</loc>
<lastmod>2025-01-02</lastmod>
<priority>0.8</priority>
</url>
<url>
<loc>https://yoursite.com/faq</loc>
<lastmod>2025-01-01</lastmod>
<priority>0.7</priority>
</url>
</urlset>
Attributet priority signalerar för AI-crawlers vilka sidor som är viktigast, medan lastmod visar innehållets aktualitet. Detta hjälper AI-system att disponera crawl-resurser effektivt och förstå din innehållshierarki.
Utöver konfigurationsfiler kan flera tekniska hinder förhindra att AI-crawlers effektivt når ditt innehåll. JavaScript-rendering är fortsatt det största problemet, eftersom moderna webbramverk som React, Vue och Angular renderar innehåll dynamiskt i webbläsaren, vilket lämnar AI-crawlers med tom HTML. Cloudflare och liknande säkerhetsverktyg blockerar ofta AI-crawlers som standard och ser deras många förfrågningar som potentiella attacker. Rate limiting kan förhindra omfattande indexering, medan komplex webbplatsarkitektur och dynamisk innehållsladdning ytterligare försvårar crawleråtkomst. Lyckligtvis finns flera lösningar för att övervinna dessa hinder.
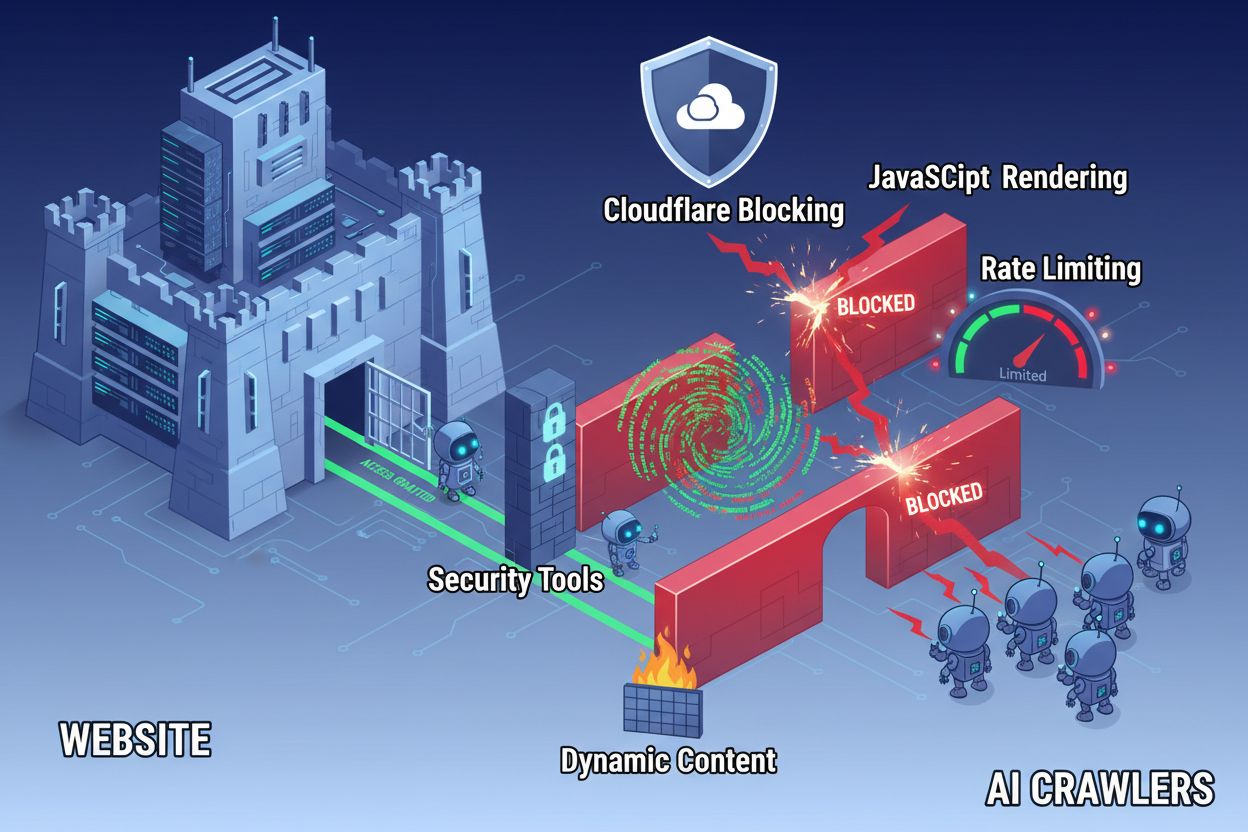
Lösningar för att förbättra AI-crawleråtkomst:
AI-system behöver inte bara komma åt ditt innehåll—de måste även förstå det. Innehållsextraktion handlar om hur effektivt AI-crawlers kan tolka, förstå och extrahera meningsfull information från dina sidor. Denna process beror starkt på semantisk HTML-struktur, som använder korrekta rubrikhierarkier, beskrivande texter och logisk organisering för att förmedla betydelse. När ditt innehåll är välstrukturerat med tydliga rubriker (H1, H2, H3), beskrivande stycken och logisk flöde kan AI-system lättare identifiera nyckelinformation och förstå sammanhang. Dessutom ger schema markup maskinläsbar metadata som tydligt talar om för AI-system vad ditt innehåll handlar om, vilket dramatiskt förbättrar förståelse och citeringsmöjligheter.
Korrekt semantisk struktur inkluderar också användning av semantiska HTML-element som <article>, <section>, <nav> och <aside> istället för generiska <div>-taggar. Detta hjälper AI-system att förstå syftet och vikten av olika innehållsdelar. Kombinerat med strukturerad data som FAQ-schema, produkt-schema eller organisationsschema blir ditt innehåll avsevärt mer tillgängligt för AI-system, vilket ökar chansen att bli presenterad i AI-genererade svar och rekommendationer.
Efter att ha implementerat förbättringar behöver du verifiera att AI-crawlers faktiskt kan komma åt ditt innehåll och övervaka den löpande prestandan. Serverloggar ger direkt bevis på crawleraktivitet och visar vilka botar som besökt din webbplats, vilka sidor de hämtat och om de stött på fel. Google Search Console ger insikter om hur Googles crawlers interagerar med din webbplats, medan specialiserade AI-synlighetsverktyg spårar hur ditt innehåll visas på olika AI-plattformar. AmICited.com övervakar specifikt hur AI-system refererar till ditt varumärke över ChatGPT, Perplexity och Google AI Översikter, och ger insyn i vilka av dina sidor som citeras och hur ofta.
Verktyg och metoder för övervakning av AI-crawleråtkomst:
Att optimera din webbplats för AI-crawleråtkomst kräver ett strategiskt, kontinuerligt angreppssätt. Istället för att se AI-tillgänglighet som ett engångsprojekt, implementerar framgångsrika organisationer kontinuerliga övervaknings- och förbättringsprocesser. Den mest effektiva strategin kombinerar korrekt teknisk konfiguration med innehållsoptimering, så att både din infrastruktur och ditt innehåll är AI-redo.
Att göra för AI-tillgänglighet:
Att undvika för AI-tillgänglighet:
Den mest framgångsrika AI-tillgänglighetsstrategin ser crawlers som partners i innehållsspridning snarare än hot som ska blockeras. Genom att säkerställa att din webbplats är tekniskt stabil, korrekt konfigurerad och semantiskt tydlig maximerar du sannolikheten att AI-system upptäcker, förstår och citerar ditt innehåll i sina svar till användare.
AI-tillgänglighetsgranskningar fokuserar på semantisk struktur, maskinläsbart innehåll och citerbarhet för AI-system, medan traditionella SEO-granskningar betonar nyckelord, bakåtlänkar och sökrankningar. AI-granskningar undersöker om crawlers kan komma åt och förstå ditt innehåll, medan SEO-granskningar fokuserar på rankingfaktorer för Googles sökresultat.
Kontrollera dina serverloggar efter AI-crawler user agents som GPTBot, ClaudeBot och PerplexityBot. Använd Google Search Console för att övervaka crawl-aktivitet, testa din robots.txt-fil med valideringsverktyg och använd specialiserade plattformar som AmICited för att spåra hur AI-system refererar till ditt innehåll på olika plattformar.
De vanligaste hindren inkluderar begränsningar i JavaScript-rendering (AI-crawlers kan inte köra JavaScript), Cloudflare och säkerhetsverktyg som blockerar (35 % av företagswebbplatser blockerar AI-crawlers), rate limiting som förhindrar omfattande indexering, komplex webbplatsarkitektur och dynamisk innehållsladdning. Varje hinder kräver olika lösningar.
De flesta företag gynnas av att tillåta AI-crawlers eftersom de ökar varumärkets synlighet i AI-drivna sökresultat och konversationsgränssnitt. Beslutet beror dock på din innehållsstrategi, konkurrenspositionering och affärsmål. Du kan använda robots.txt för att selektivt tillåta vissa crawlers samtidigt som du blockerar andra utifrån dina specifika behov.
Gör en omfattande granskning varje kvartal eller när du gör större ändringar i din webbplatsarkitektur, innehållsstrategi eller säkerhetskonfiguration. Övervaka crawleraktivitet kontinuerligt med serverloggar och specialverktyg. Uppdatera din robots.txt och sitemaps varje gång du lanserar nya innehållssektioner eller ändrar URL-strukturer.
Robots.txt är din primära mekanism för att kontrollera AI-crawleråtkomst. Rätt konfiguration tillåter uttryckligen större AI-crawlers (GPTBot, ClaudeBot, PerplexityBot) samtidigt som den skyddar känsliga områden. Felkonfigurerad robots.txt kan helt blockera AI-crawlers, vilket gör ditt innehåll osynligt för AI-system oavsett dess kvalitet.
Även om teknisk optimering är viktig kan du också förbättra AI-synligheten genom innehållsoptimering—använda semantisk HTML-struktur, implementera schema markup, förbättra intern länkning och säkerställa innehållskompletthet. Tekniska hinder som JavaScript-rendering och säkerhetsblockering kräver dock vanligtvis tekniska lösningar för full AI-tillgänglighet.
Använd serverlogganalys för att spåra crawleraktivitet, Google Search Console för crawlstatistik, robots.txt-validatiorer för att verifiera konfigurationen, schema markup-validatiorer för strukturerad data och specialiserade plattformar som AmICited för att övervaka AI-citat. Många SEO-verktyg som Screaming Frog erbjuder även crawler-simuleringsmöjligheter för att testa AI-tillgänglighet.
Spåra hur ChatGPT, Perplexity, Google AI Översikter och andra AI-system refererar till ditt varumärke med AmICited. Få insikter i realtid om din AI-synlighet och optimera din innehållsstrategi.
Lär dig vad AI crawl analytics är och hur serverloggsanalys spårar AI-crawlers beteende, mönster för innehållsåtkomst och synlighet i AI-drivna sökplattformar s...

Lär dig vad en AI-innehållsgranskning är, hur den skiljer sig från traditionella innehållsgranskningar och varför det är avgörande för din digitala strategi att...

Lär dig vad AI index-täckning är och varför det är viktigt för ditt varumärkes synlighet i ChatGPT, Google AI Overviews och Perplexity. Upptäck tekniska faktore...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.