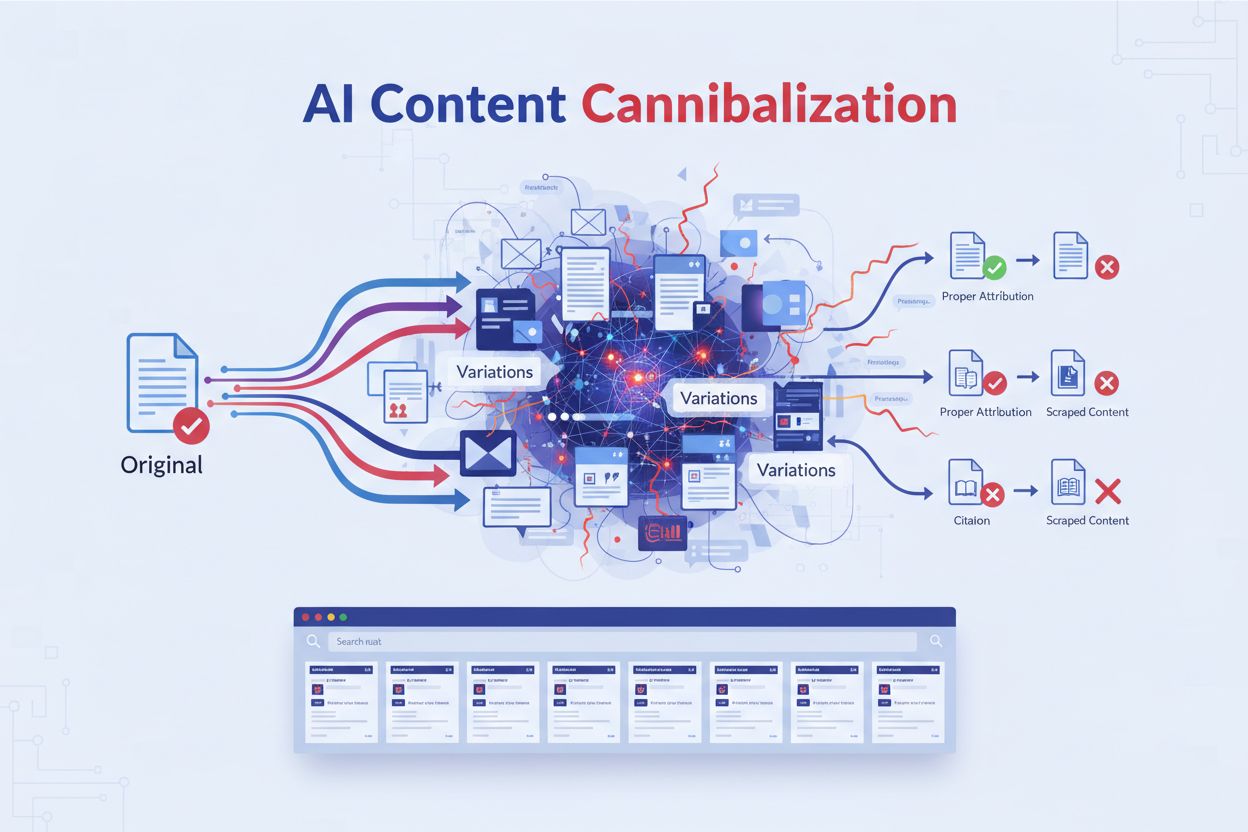
När flera innehållsbitar konkurrerar om samma AI-citat. AI-system skrapar och omskriver ditt ursprungliga innehåll till semantiskt liknande varianter som konkurrerar med dina ursprungliga sidor i sökresultat och AI-genererade svar, vilket urholkar din synlighet och auktoritet utan korrekt attribuering.
AI-innehållskannibalisering
När flera innehållsbitar konkurrerar om samma AI-citat. AI-system skrapar och omskriver ditt ursprungliga innehåll till semantiskt liknande varianter som konkurrerar med dina ursprungliga sidor i sökresultat och AI-genererade svar, vilket urholkar din synlighet och auktoritet utan korrekt attribuering.
Vad är AI-innehållskannibalisering?
AI-innehållskannibalisering uppstår när artificiella intelligenssystem skrapar och omskriver ditt ursprungliga innehåll till semantiskt liknande varianter som konkurrerar med dina ursprungliga sidor i sökresultat och AI-genererade svar. Till skillnad från traditionellt duplicerat innehåll som kopierar text ord för ord, använder AI-genererade versioner annan formulering men behåller samma innebörd, vilket gör att de kan kringgå plagiatkontroller. Detta skapar ett särskilt lömskt problem i ett AI-först-sökslandskap: ditt innehåll föder AI-modeller som sedan genererar konkurrerande svar utan korrekt attribuering. När Google AI Overviews och andra AI-söksystem syntetiserar information, kan de citera dessa AI-genererade kloner oftare än ditt ursprungliga arbete, vilket urholkar din synlighet och auktoritet. Den grundläggande frågan är att semantisk likhet betyder mer än exakt duplicering i AI-system – vilket innebär att dina unika insikter och forskning återvinns i otaliga varianter som alla konkurrerar om samma citat och trafik.
Hur AI-innehållskannibalisering skiljer sig från traditionellt duplicerat innehåll
Faktor
Klassiskt duplicerat innehåll
AI-innehållskannibalisering
Källa
Kopierat ord för ord från din sida
Omskrivet eller parafraserat av AI-verktyg till nya varianter
Upptäckt
Lätt att upptäcka med plagiatfilter eller manuella kontroller
Mycket svårare att upptäcka eftersom formuleringen är unik men semantiskt lik
Utseende
Ser ut som en direkt kopia eller spegelsida
Verkar “originell” för sökmotorer och användare trots att den bygger på ditt arbete
SEO-påverkan
Vanligtvis undertryckt i SERP när den flaggats som duplicerad
Urholkar ämnesauktoritet, förvirrar sökmotorer och kan ranka högre än din ursprungliga sida
Åtgärd
Skicka DMCA-takedown eller begär borttagning
Mycket svårare att agera på; kräver ofta att du stärker ditt eget innehåll istället för borttagning
Traditionellt duplicerat innehåll har varit ett känt SEO-problem i åratal – det är synligt, spårbart och relativt enkelt att lösa via borttagningar eller kanonisering. AI-innehållskannibalisering är fundamentalt annorlunda och mer lömsk. De omskrivna versionerna ser inte ut som direkta kopior, så plagiatkontroller flaggar dem sällan. För sökmotorer kan den AI-genererade sidan verka lika relevant som din originalversion, vilket splittrar rankningssignaler och urholkar din auktoritet. I praktiken innebär detta att din webbplats tyst kan tappa trafik och rankingar utan en uppenbar orsak. Om du inte aktivt övervakar sökresultat och analyserar semantisk likhet, förblir AI-kannibalisering ofta osynlig tills betydande skada redan har uppstått.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
AI-innehållskannibalisering skadar din söksynlighet på flera sätt:
SERP-förorening: Sökresultaten fylls av sidor som upprepar din idé med nya ord. Detta gör att ditt original syns sämre och tvingar användare att välja mellan flera liknande resultat, där inget tydligt framstår som auktoritativ källa. När Google visar flera varianter av samma koncept tappar ditt original sin framträdande plats.
Ämnesförvirring: Google kan inte enkelt avgöra vem som har verklig auktoritet inom ett ämne. Den semantiska vikten fördelas över flera kopior, vilket gör det svårare för sökmotorerna att identifiera vilken sida som förtjänar topprankning. Denna förvirring försvagar alla konkurrerande sidor, inklusive din originalversion.
Klickläckage: Omskrivna sidor fångar trafik som borde ha gått till ditt original. De ser nya ut för användarna och besvarar sökningen, men källan är inte du. En användare som söker efter “bästa SEO-verktygen” kan klicka på en AI-omskriven version istället för din ursprungliga jämförelse, vilket kostar dig trafik och engagemangsstatistik.
AI Overviews-urholkning: Google AI Overviews använder stora språkmodeller tränade på återvunnet innehåll. Din unika formulering tappar attribuering när AI-system oftare citerar semantiskt liknande kloner än ditt originalverk. Det innebär att ditt innehåll föder AI-systemen utan att du får korrekt erkännande eller trafik.
Exempel: Om din ursprungliga artikel säger “Semrush är stark för granskningar. Ahrefs är stark för backlinks,” kan ett AI-system omskriva detta till “Ahrefs utmärker sig vid länkanalys. Semrush presterar bättre för tekniska granskningar.” Innebörden är identisk, båda indexeras, och den omskrivna versionen kan till och med ranka högre än din originaltext tack vare starkare domänauktoritet på kopieringssidan.
Hur du upptäcker AI-innehållskannibalisering
Identifiering av AI-innehållskannibalisering kräver en flernivåstrategi:
Använd verktyg för semantisk likhet: Inbäddningsmodeller och klustringsalgoritmer kan upptäcka omskrivna dubletter som plagiatkontroller missar. Dessa verktyg analyserar semantisk innebörd snarare än exakt textmatchning, och avslöjar innehåll som förmedlar samma information med andra ord. Verktyg som Semrush och Similarweb erbjuder semantiska analysfunktioner särskilt för detta.
Spåra dina toppsidor i Google Search Console: Övervaka dina högpresterande sidor för plötsliga trafikfall utan motsvarande länkförlust. Om en sida som konsekvent drivit trafik plötsligt får en markant nedgång, kan det tyda på att AI-genererade varianter kannibaliserar dess synlighet. Använd fliken Prestanda för att filtrera på specifika sidor och håll koll på oförklarliga förändringar.
Läs AI Overview-resultat för dina sökord: Sök på dina målsökord i Google AI Overviews och Perplexity. Om du ser formuleringar som liknar dina utan korrekt citation eller attribuering, är det ett tecken på att ditt innehåll skrapas och omskrivs. Notera om ditt varumärke nämns eller om AI-systemet istället citerar konkurrenter.
Sätt upp varningar för skrapade RSS-flöden: Många AI-system tränar på skrapade syndikeringsflöden. Övervaka användningen av ditt RSS-flöde och sätt upp varningar för obehörig skrapning. Verktyg som Google Alerts och specialiserade flödesövervakningstjänster kan hjälpa dig att spåra var ditt innehåll distribueras och eventuellt återanvänds utan tillstånd.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Strategier för att skydda mot AI-innehållskannibalisering
Försvar av ditt innehåll kräver en proaktiv och mångsidig strategi:
Publicera tillgångar som AI inte kan spinna: Skapa innehåll som AI-system inte enkelt kan replikera – originaldatatabeller, enkätresultat, egen forskning, interaktiva kalkylatorer och specialbyggda verktyg. Medan AI är skickligt på att generera generisk text kan det inte hitta på färsk data eller unika interaktiva upplevelser. Dessa försvarbara tillgångar blir din vallgrav mot kannibalisering och ger användare en anledning att besöka din ursprungliga källa.
Mynt originaltermer och använd dem konsekvent: Om du introducerar en distinkt fras såsom “AI-innehållskannibalisering” och använder den konsekvent i hela ditt innehållsekosystem, kommer kopior att ekonera den. Detta kopplar auktoritet tillbaka till dig som upphovsman. När AI-system citerar denna term förstärker de ditt varumärke som källa. Skapa unikt språk för dina nyckelbegrepp och äg det språkutrymmet.
Lägg till schema markup: Implementera FAQ-, HowTo- och Artikelschema på dina sidor. Strukturerad data guidar Google kring källauktoritet och hjälper AI-system att förstå ditt innehålls syfte och trovärdighet. Det gör det lättare för sökmotorer att tillskriva innehållet korrekt och prioritera ditt original framför kopior.
Uppdatera ditt innehåll ofta: Sökmotorer belönar aktualitet och AI-kopior tenderar att frysa efter sin första publicering. Genom att regelbundet uppdatera ditt innehåll med ny data, färska exempel och aktuella insikter signalerar du att din sida är den levande, auktoritativa källan. Denna aktualitetssignal hjälper till att skilja ditt original från statiska AI-genererade kopior.
Vattenmärk visuella medier och data: Lägg till subtila vattenmärken på diagram, infografik och egna datavisualiseringar. Även om det inte är idiotsäkert, bevisar vattenmärken upphovsrätt vid tvister och gör det svårare för andra att hävda att ditt arbete är deras eget. Inkludera copyright-notiser och attribueringskrav i dina datapresentationer.
AI-citatspårningens roll
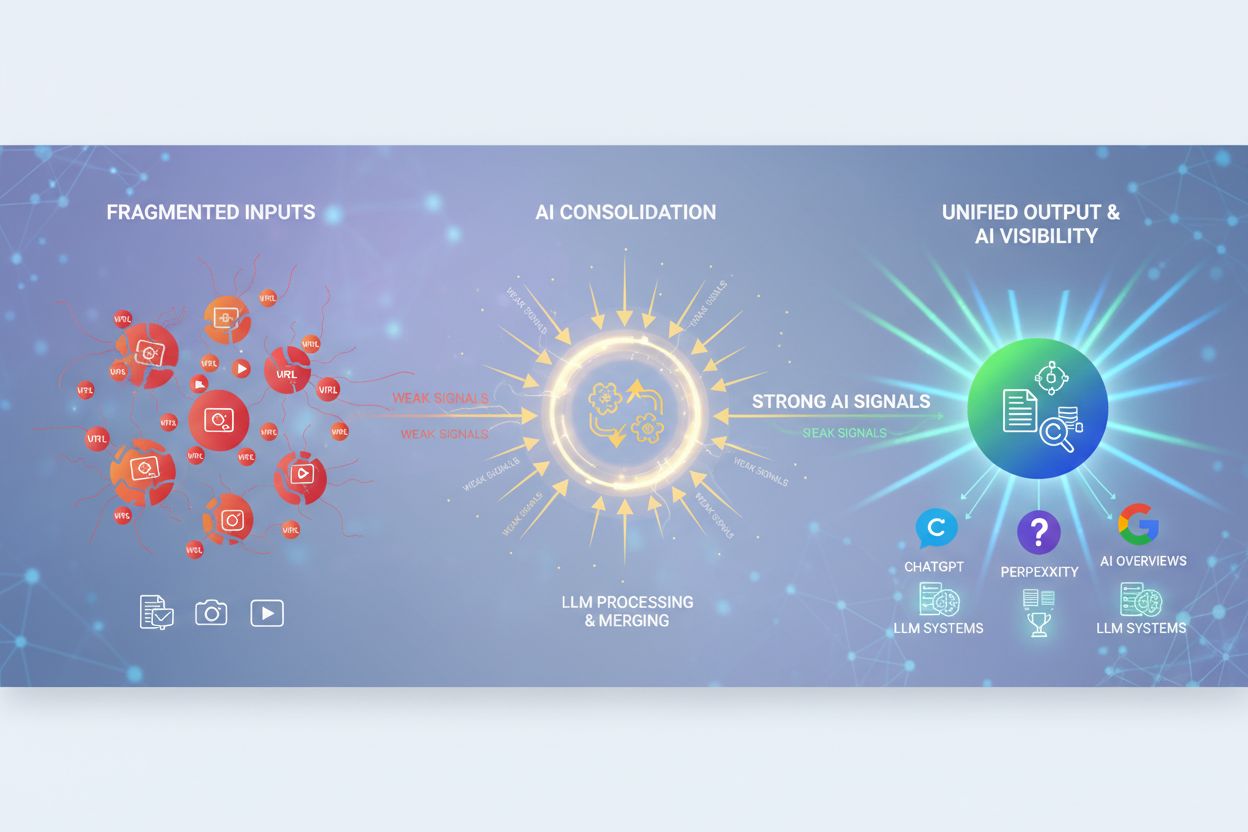
AI-citatspårning är praxis att övervaka var, hur och varför ditt varumärkes innehåll nämns som källa i AI-genererade svar över verktyg som ChatGPT, Perplexity, Google AI Overviews och andra AI-sökplattformar. Detta representerar ett fundamentalt skifte från traditionell SEO, där du spårade sökordsranking och bakåtlänkar. I AI-först-sök konkurrerar du nu om att bli citerad, syntetiserad och lyft av språkmodeller istället för att tävla om fasta positioner på en sökresultatsida.
Citatspårning skiljer sig från traditionell SEO-synlighet på avgörande sätt. Medan traditionell SEO mäter din rankingposition för specifika sökord, mäter citatspårning hur AI-system väljer att referera till ditt innehåll när de genererar svar. En citering i ett AI-svar kanske inte ger omedelbar trafik, men signalerar ditt innehålls inflytande och auktoritet inom ett ämnesområde. Publicister använder allt oftare citatspårning för att identifiera synlighetsluckor, se vilket innehåll som citeras oftast och mäta sitt inflytande i AI-genererade svar. Verktyg som Semrush, Similarweb och specialiserade AI-övervakningsplattformar erbjuder nu citatspårningsfunktioner, så att du kan se vilka av dina sidor som förekommer i AI-svar och hur ofta de citeras jämfört med konkurrenter. Denna data hjälper dig att förstå vilket innehåll som resonerar med AI-system och informerar din innehållsstrategi för AI-eran.
Framtidsutsikter och semantisk deduplicering
Google utvecklar gradvis semantiska dedupliceringssystem som är utformade för att känna igen när innehåll är meningsfullt detsamma, även om det har skrivits om. Dessa system syftar till att identifiera semantiskt likvärdigt innehåll och konsolidera rankingar kring ursprungskällan. Den avgörande utmaningen är dock hastigheten: AI-genererat innehåll ökar mycket snabbare än Googles filter utvecklas. När semantiska dedupliceringssystem har mognat kommer tusentals nya AI-genererade varianter redan ha skapats och indexerats.
Vinnarna i detta landskap blir de publicister som äger sin nisch genom egen data och forskning, distinkta format och ramverk, och unika förstahandsinsikter som AI inte enkelt kan syntetisera. Dessa publicister skapar försvarbara vallgravar som AI-system inte kan replikera. De myntar originaltermer, publicerar exklusiv data och bygger genuin expertis som blir omöjlig att kopiera. Förlorarna blir de som förlitar sig på generiskt, textbaserat innehåll utan försvarbar fördel. När AI accelererar innehållsproduktionen blir originalitet, expertis och varumärkesauktoritet de avgörande faktorerna som avgör vilka sajter som växer och vilka som försvinner. Framtiden tillhör de publicister som förstår att i en AI-först-värld är unikt värde och äkta expertis de enda hållbara konkurrensfördelarna. Innehåll som enkelt kan omskrivas och återanvändas kommer att bli en handelsvara, medan innehåll som stöds av egen forskning, egen data och genuin auktoritet kommer att få högsta synlighet i både traditionell sökning och AI-genererade svar.
Vanliga frågor
Vad är egentligen AI-innehållskannibalisering?
AI-innehållskannibalisering uppstår när artificiella intelligenssystem skrapar och omskriver ditt ursprungliga innehåll till semantiskt liknande varianter som konkurrerar med dina ursprungliga sidor i sökresultat och AI-genererade svar. Till skillnad från traditionellt duplicerat innehåll som kopierar text ord för ord, använder AI-genererade versioner annan formulering men behåller samma innebörd, vilket gör att de kan kringgå plagiatkontroller.
Hur skiljer sig AI-innehållskannibalisering från duplicerat innehåll?
AI-kannibalisering innebär omskrivet innehåll som klarar plagiatkontroller men ändå urholkar auktoritet, medan duplicerat innehåll är exakta kopior som är lättare att upptäcka och undertrycka. AI-genererade sidor uppfattas som 'originella' för sökmotorerna även om de bygger på ditt arbete, vilket gör dem mycket svårare att identifiera och åtgärda än traditionella dubletter.
Varför skadar AI-innehållskannibalisering mina rankingar?
Det orsakar SERP-förorening (flera liknande resultat konkurrerar), ämnesförvirring (sökmotorer kan inte avgöra auktoritet), klickläckage (trafik går till AI-genererade kopior) och minskar din synlighet i AI Overviews. Ditt innehåll föder AI-modeller som sedan genererar konkurrerande svar utan korrekt attribuering, vilket splittrar rankningssignaler och urholkar din auktoritet.
Hur kan jag upptäcka om mitt innehåll blir kannibaliserat av AI?
Använd verktyg för semantisk likhet och inbäddningsmodeller för att upptäcka omskrivna dubletter, övervaka Google Search Console för oförklarliga trafikfall, kontrollera AI Overview-resultat för oattribuerad formulering liknande din, och sätt upp varningar för skrapade RSS-flöden. Verktyg som Semrush och Similarweb erbjuder semantiska analysfunktioner speciellt framtagna för detta ändamål.
Vad är det bästa sättet att skydda mitt innehåll från AI-kannibalisering?
Publicera egen data och originalinsikter som AI inte enkelt kan replikera, mynt unika termer och använd dem konsekvent, lägg till schema markup (FAQ, HowTo, Artikel), uppdatera innehåll ofta för att signalera aktualitet, och vattenmärk visuella medier och data. Dessa försvarbara tillgångar skapar en vallgrav mot kannibalisering och ger användare en anledning att besöka din ursprungliga källa.
Vilken roll spelar AI-citatspårning i innehållskannibalisering?
Citatspårning hjälper dig att övervaka var ditt innehåll dyker upp i AI-genererade svar, förstå din synlighet i AI-system, och identifiera när AI-system citerar konkurrenter istället för dig. Denna data hjälper dig att förstå vilket innehåll som resonerar med AI-system och informerar din strategi för AI-eran.
Kommer Google att lösa problemet med AI-innehållskannibalisering?
Google utvecklar semantiska dedupliceringssystem för att känna igen när innehåll är meningsfullt detsamma, även om det är omskrivet. Dock ökar AI-innehållsgenereringen snabbare än filtren utvecklas. Det bästa försvaret är att skapa försvarsbart, originellt innehåll som AI-system inte enkelt kan replikera.
Hur relaterar AI-innehållskannibalisering till strategi för innehållsdistribution?
Det belyser vikten av strategisk innehållsdistribution över flera kanaler och att säkerställa att ditt ursprungliga innehåll blir citerat och attribuerat i AI-system. Publicister måste nu konkurrera om att bli citerade av AI-system snarare än bara ranka i traditionell sökning, vilket gör innehållskvalitet och originalitet viktigare än någonsin.
Övervaka dina AI-citat med AmICited
Skydda ditt varumärkes synlighet i AI-drivna sökningar. Spåra hur AI-system citerar ditt innehåll över Google AI Overviews, ChatGPT, Perplexity och mer. Förstå var ditt innehåll visas i AI-genererade svar och säkerställ korrekt attribuering.
Vad är innehållskannibalisering i AI-sök och hur påverkar det rankningar
Lär dig vad innehållskannibalisering i AI-sök innebär, hur det påverkar ditt varumärkes synlighet i AI-svar och varför det är viktigt att övervaka överlappninga...
Hur åtgärdar du nyckelords-kannibalisering för AI-sökmotorer
Lär dig identifiera och åtgärda problem med nyckelords-kannibalisering som påverkar din synlighet i AI-sökmotorer som ChatGPT, Perplexity och Gemini. Upptäck st...
Lär dig vad AI-innehållskonsolidering är och hur sammanslagning av liknande innehåll stärker synlighetssignaler för ChatGPT, Perplexity och Google AI Overviews....
10 min läsning
Cookie-samtycke Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.