Krav på mångfald av AI-källor avser hur AI-system balanserar att citera flera olika källor jämfört med att fokusera på auktoritativa sådana. Dessa algoritmer avgör om AI-plattformar prioriterar bredden av källor eller graden av auktoritet när de genererar svar, vilket påverkar vilka varumärken och innehåll som får synlighet i AI-genererade svar. Olika AI-plattformar använder olika strategier – från ChatGPT:s auktoritetsfokus till Perplexitys gemenskapsdrivna modell – vilket kräver att varumärken optimerar för plattformsspecifika citeringsmönster.
Krav på mångfald av AI-källor
Krav på mångfald av AI-källor avser hur AI-system balanserar att citera flera olika källor jämfört med att fokusera på auktoritativa sådana. Dessa algoritmer avgör om AI-plattformar prioriterar bredden av källor eller graden av auktoritet när de genererar svar, vilket påverkar vilka varumärken och innehåll som får synlighet i AI-genererade svar. Olika AI-plattformar använder olika strategier – från ChatGPT:s auktoritetsfokus till Perplexitys gemenskapsdrivna modell – vilket kräver att varumärken optimerar för plattformsspecifika citeringsmönster.
Vad är krav på mångfald av AI-källor?
Krav på mångfald av AI-källor syftar på de algoritmiska mekanismer och strategiska överväganden som avgör hur AI-system väljer och prioriterar flera källor när de genererar svar och citeringar. Istället för att förlita sig på en enda auktoritativ källa balanserar moderna AI-plattformar källauktoritet med källmångfald för att ge användarna omfattande svar ur flera perspektiv. Denna balans är avgörande eftersom den påverkar vilka varumärken, publikationer och innehållsskapare som får synlighet i AI-genererade svar – vilket gör det viktigt för organisationer att förstå hur olika AI-system väger auktoritet mot variation. Begreppet är särskilt relevant i Retrieval-Augmented Generation (RAG)-system, där AI-modeller hämtar relevanta dokument från en kunskapsbas innan de genererar svar, vilket kräver noggrann kalibrering av vilka källor som hämtas och rankas. För varumärken och innehållsskapare innebär förståelsen av dessa krav att optimera innehållet för att synas på flera AI-plattformar istället för att förlita sig på en enda citeringskälla. Insatserna är höga: ett varumärke som syns i AI-svar får trovärdighet och trafik, medan de som utesluts får minskad synlighet i ett alltmer AI-medierat informationslandskap.
Hur olika AI-plattformar närmar sig källmångfald
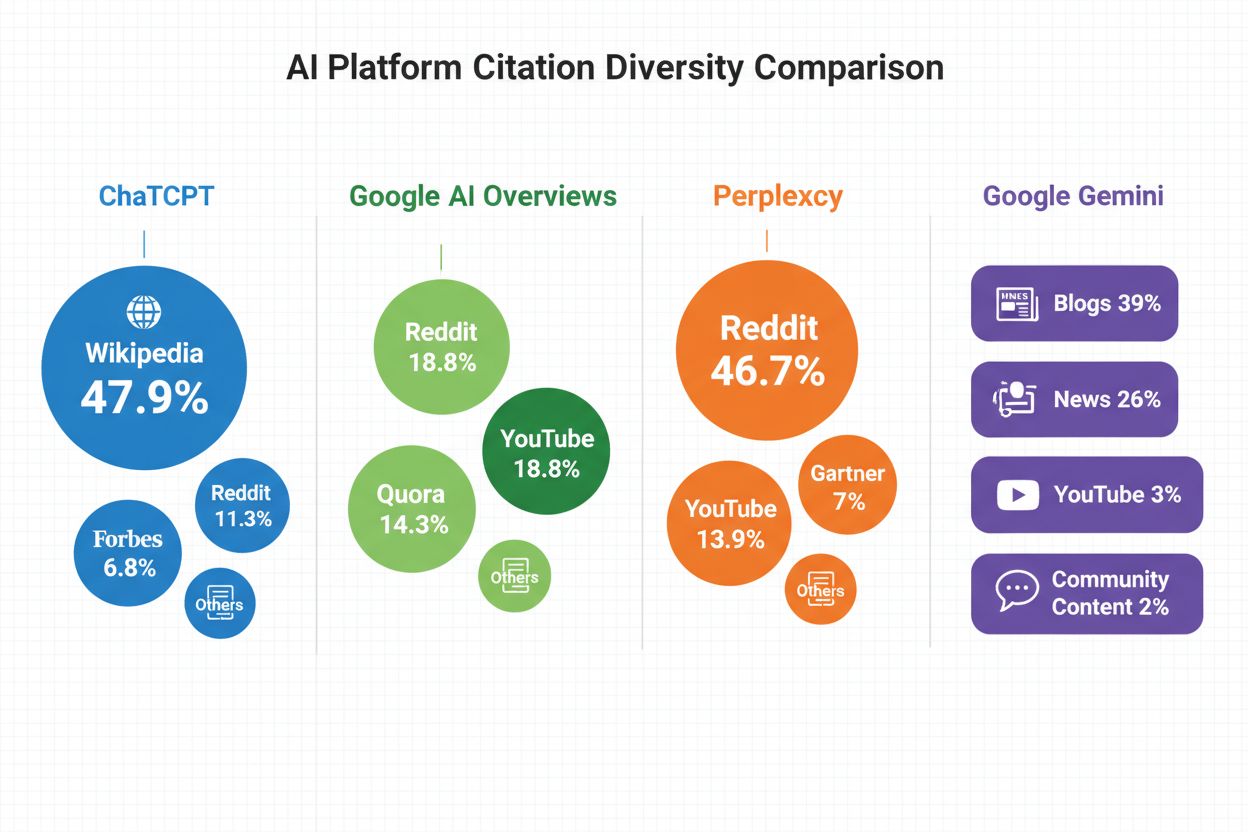
Varje större AI-plattform har ett tydligt unikt sätt att närma sig källmångfald, vilket återspeglar deras underliggande arkitektur och designfilosofi. ChatGPT uppvisar en stark auktoritetsbias, där Wikipedia dominerar 47,9 % av dess topp 10-citeringar, vilket indikerar en förkärlek för etablerade, verifierbara källor med hög domänauktoritet. Google AI Overviews, däremot, använder en balanserad distributionsstrategi, där källor som Reddit (21 %), YouTube (18,8 %), Quora (14,3 %) och LinkedIn (13 %) tyder på en algoritm utformad för att lyfta fram olika innehållstyper och användarperspektiv. Perplexity lutar starkt åt gemenskapsdrivna källor, med Reddit som står för 46,7 % av citeringarna tillsammans med YouTube (13,9 %), och positionerar sig som en plattform som värderar verkliga användarupplevelser och diskussioner. Google Gemini har en blandad strategi, där bloggar (39 %) och nyhetskällor (26 %) prioriteras och därmed balanserar professionellt innehåll med olika perspektiv. Dessa skillnader är inte slumpmässiga – de återspeglar varje plattforms målgrupp och innehållsfilosofi.
Plattform
Wikipedia
Reddit
YouTube
Nyheter
Bloggar
Annat
ChatGPT
47,9%
8–12%
5–8%
10–15%
8–12%
10–15%
Google AI Overviews
15–20%
21%
18,8%
18–22%
12–15%
10–15%
Perplexity
12–18%
46,7%
13,9%
8–12%
10–15%
5–10%
Google Gemini
18–22%
10–15%
12–16%
26%
39%
5–10%
Den praktiska innebörden är att ett varumärkes citeringsstrategi måste vara plattformsspecifik. Ett företag som enbart optimerar för ChatGPT-citeringar bör fokusera på Wikipedia-omnämnanden och högauktoritativa domäner, medan samma företag, om det riktar sig till Perplexity, bör investera i engagemang i gemenskaper och närvaro på Reddit. Att förstå dessa plattformsspecifika preferenser är där verktyg som AmICited.com, en övervakningsplattform för AI-svar som spårar citeringar i ChatGPT, Perplexity och Google AI Overviews, blir ovärderliga för att mäta faktisk citeringsprestanda och justera strategier därefter.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Spänningen mellan auktoritet och mångfald står i centrum för moderna AI-citeringsalgoritmer, vilket kräver sofistikerade tekniska lösningar för att balansera motstridiga mål. Auktoritetssignaler inkluderar domänrykte (mätt med mått som Domain Authority och Trust Flow), bakåtlänksportföljer, närvaro i kunskapsgrafer som Googles Knowledge Panel och historisk citeringsfrekvens på webben. Mångfaldsmekanismer fungerar genom flera tekniker: dedupliceringsalgoritmer förhindrar att samma information visas flera gånger, ämnesklustring säkerställer täckning av olika vinklar på en fråga och Maximal Marginal Relevance (MMR)-algoritmer väljer källor som både är relevanta och skiljer sig från tidigare valda källor. I RAG-system uppnås denna balans under hämtfasen, där systemet måste avgöra om det ska hämta det mest relevanta dokumentet eller en mångfald av måttligt relevanta dokument. Hämtstrategin påverkar svarskvaliteten direkt – för mycket auktoritetsbias ger smala, potentiellt vinklade svar, medan överdriven mångfald kan introducera motsägelsefull eller lågkvalitativ information. Moderna AI-system använder allt oftare ensemblemetoder som kombinerar flera hämtnings- och rankningsstrategier, vilket gör att de kan optimera för både relevans och mångfald samtidigt.
Källtypspreferenser efter frågetyp
AI-plattformar tillämpar inte samma krav på källmångfald på alla frågor; istället anpassar de sina citeringsstrategier utifrån frågeintention och innehållstyp. Att förstå dessa mönster är avgörande för innehållsskapare som vill synas i AI-svar:
B2C-frågor (konsumentinriktade): YouTube dominerar för produktdemonstrationer och recensioner, Reddit för autentiska användarupplevelser och felsökning samt e-handelssajter för köpinformation. Dessa frågor prioriterar praktiskt, användargenererat innehåll före institutionell auktoritet.
B2B-frågor (företagsinriktade): Branschpublikationer, leverantörsbloggar, analytikerrapporter (Gartner, Forrester) och LinkedIn-artiklar får högre vikt. Dessa frågor premierar specialiserad expertis och professionell trovärdighet före innehåll för bred publik.
Informationsfrågor (utbildande): Wikipedia, akademiska källor, nyhetsmedier och utbildningsinstitutioner dominerar. Dessa frågor betonar auktoritativt, välunderbyggt innehåll med tydliga källor.
Kommersiella frågor (köpintention): Produkttestningssajter, jämförelseplattformar, leverantörshemsidor och YouTube-unboxings får förtur. Dessa frågor balanserar användarrecensioner med officiell produktinformation.
Lokala frågor (platsbaserade): Google Business Profiler, lokala nyheter, gemenskapsforum och platsbaserade kataloger väger tungt. Dessa frågor kräver geografiska relevanssignaler.
Slutsatsen för varumärken är att en enskild innehållsdel inte kan optimeras lika bra för alla frågetyper. En produktrecension kommer prestera annorlunda i B2C-frågor än vad en teknisk vitbok gör i B2B-frågor, vilket kräver diversifierade innehållsstrategier i flera format och plattformar.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Domänauktoritet och kunskapsgrafers inverkan
Domänauktoritet fungerar som en tillförlitlighetsindikator i AI-citeringsalgoritmer, där domäner med högre auktoritet får förtur vid källval. Domäner med starka bakåtlänksprofiler, lång driftshistorik och konsekvent ämnesfokus har högre sannolikhet att bli citerade, särskilt på plattformar som ChatGPT där auktoritet står i fokus. Närvaro i kunskapsgrafer – särskilt Googles Knowledge Panel och Wikipedia – ökar dramatiskt sannolikheten för att bli citerad, eftersom dessa källor algoritmiskt är förvaliderade som auktoritativa. Bakåtlänksportföljen är viktig, inte bara i antal utan även i kvalitet; länkar från andra högauktoritativa domäner väger tyngre än länkar från lågauktoritativa sajter, vilket ger en snöbollseffekt där etablerade varumärken ackumulerar citeringsfördelar. Authorschema och expertattribution har blivit allt viktigare, där AI-system känner igen bylines, författaruppgifter och expertissignaler för att validera källors trovärdighet. Organisationer utan etablerad domänauktoritet har en strukturell nackdel i AI-citeringsalgoritmer, även om detta delvis kan motverkas genom strategisk innehållsspridning, gemenskapsengagemang och byggande av bakåtlänkar från erkända auktoriteter. Den långsiktiga effekten är att synlighet i AI-citeringar alltmer korrelerar med traditionella SEO-auktoritetsmått, vilket gör historiska domäninvesteringar till en konkurrensfördel.
Innehållsegenskaper som driver mångfaldiga citeringar
Utöver domänauktoritet påverkar specifika innehållsegenskaper om AI-system väljer en källa för citering. Samsvar med samtalsfrågor är avgörande – innehåll som är skrivet i en stil som matchar hur användare formulerar frågor får högre poäng i RAG-system. Innehåll som innehåller interna källhänvisningar och attributering signalerar kvalitet och djup, vilket uppmuntrar AI-system att citera det som en tillförlitlig sammanfattningspunkt. Konsekvens över plattformar är också viktigt; när samma information återfinns på flera kanaler (blogg, LinkedIn, YouTube, Reddit) ser AI-system det som validerad kunskap värd att citera. Implementering av strukturerad data – med schema markup för artiklar, FAQ och produktinformation – hjälper AI-system att förstå och extrahera information mer tillförlitligt, vilket ökar sannolikheten för citering. Aktualitet och färskhetssignaler påverkar citeringsvalet, särskilt för tidskritiska frågor; innehåll som uppdateras regelbundet väger tyngre än statiskt, föråldrat material. Till exempel får ett företag som publicerar kvartalsvisa branschrapporter fler citeringar för trendrelaterade frågor än ett som publicerar årsrapporter, eftersom AI-system känner igen fördelen med aktualitet. Praktiskt innebär det att investera i innehåll som direkt besvarar specifika användarfrågor, syns på flera plattformar och har konsekvent budskap med korrekt markup.
Mäta och optimera för källmångfald
Effektiv optimering för källmångfald i AI kräver systematisk testmetodik över plattformar, eftersom varje AI-system reagerar olika på innehålls- och spridningsstrategier. Organisationer bör spåra citeringsfrekvens i ChatGPT, Google AI Overviews, Perplexity och Google Gemini separat, med insikt om att en källa som presterar bra på en plattform kan prestera sämre på en annan. Plattformsspecifika optimeringsstrategier inkluderar: för ChatGPT, fokus på domänauktoritet och Wikipedia-omnämnanden; för Google AI Overviews, bredda över innehållstyper och plattformar; för Perplexity, investera i gemenskapsengagemang och Reddit-närvaro; för Google Gemini, balansera blogginnehåll med nyhetsbevakning. Innehållsspridning över flera kanaler är avgörande – samma kärninnehåll bör finnas som blogginlägg, sociala medier, YouTube-videor och deltagande i gemenskapsforum för att öka sannolikheten för citering i olika AI-system. Övervakningsverktyg som AmICited.com gör det möjligt för organisationer att spåra vilka källor som faktiskt citeras och justera strategier utifrån faktiska resultatdata istället för antaganden. Anpassningskraven är kontinuerliga, eftersom AI-algoritmer utvecklas och nya modeller introduceras; det som fungerar idag kan kräva justering imorgon, och kontinuerlig övervakning och experimentering är nödvändigt. Organisationer som ser AI-citeringsoptimering som en pågående process istället för ett engångsprojekt kommer att behålla konkurrensfördelar när landskapet förändras.
Framtiden för mångfald av AI-källor
Utvecklingen av citeringsalgoritmer kommer sannolikt gå mot ökad sofistikering i balansen mellan auktoritet och mångfald, där framtida AI-system potentiellt implementerar mer nyanserade källa-utvärderingsmekanismer som beaktar faktorer som författarens expertis, publikationens meritlista och realtidsfaktakontroll. Framväxande trender tyder på ökat fokus på multimodala källor – kombination av text, video, bilder och interaktivt innehåll – i takt med att AI-system blir bättre på att bearbeta olika innehållstyper. Nya AI-modeller som lanseras kommer att ha egna citeringsfilosofier, vilket kan fragmentera landskapet ytterligare och kräva att varumärken optimerar för ännu större plattformsbredd. Vikten av närvaro på flera kanaler kommer bara att öka, eftersom organisationer som upprätthåller konsekvent, högkvalitativt innehåll på bloggar, sociala medier, videoplattformar och gemenskapsforum naturligt kommer att samla fler citeringar i olika AI-system. Långsiktiga strategiska implikationer pekar på att traditionell SEO och innehållsmarknadsföring alltmer kommer att smälta samman med AI-optimering, vilket kräver att organisationer tänker holistiskt kring synlighet i sökmotorer, AI-svar och nya AI-plattformar. Konkurrensfördelen kommer tillfalla de organisationer som ser källmångfald i AI inte som ett separat initiativ utan som en integrerad del av den övergripande digitala strategin, så att deras innehåll når publiken oavsett vilken AI-plattform de använder för att hitta information.
Vanliga frågor
Vad är skillnaden mellan källmångfald och källauktoritet i AI?
Källmångfald syftar på bredden av olika källor som citeras i ett AI-svar, medan källauktoritet syftar på trovärdigheten och pålitligheten hos enskilda källor. AI-system måste balansera dessa motstående mål – att citera flera perspektiv (mångfald) samtidigt som de säkerställer att dessa källor är tillförlitliga (auktoritet). ChatGPT prioriterar auktoritet, Perplexity betonar mångfald och Google AI Overviews försöker balansera båda.
Varför citerar ChatGPT Wikipedia så mycket mer än andra plattformar?
ChatGPT:s träningsdata och återhämtningsalgoritmer viktar Wikipedia mycket tungt eftersom det utgör en förvaliderad, encyklopedisk källa med hög domänauktoritet. Wikipedias strukturerade format, redaktionella kontroll och omfattande täckning gör det idealiskt för faktabaserade, auktoritativa svar. Detta återspeglar ChatGPT:s designfilosofi att prioritera tillförlitlighet framför mångfald, vilket gör plattformen mest lik traditionella uppslagsverk.
Hur kan mitt varumärke bli citerat av AI-system?
För att öka AI-citat, fokusera på: att bygga domänauktoritet genom bakåtlänkar och konsekvent ämnesfokus, skapa innehåll som direkt besvarar specifika användarfrågor, upprätthålla närvaro på flera plattformar (bloggar, sociala medier, YouTube, forum), implementera strukturerad data-markup och hålla innehållet färskt och uppdaterat. Olika plattformar kräver olika strategier – Wikipedia och högauktoritativa domäner för ChatGPT, gemenskapsengagemang för Perplexity och varierade innehållstyper för Google AI Overviews.
Hjälper det att synas på Reddit för AI-citeringar?
Ja, betydligt. Reddit är den mest citerade källan för både Perplexity (46,7 % av topp 10-citeringarna) och Google AI Overviews (21 %), vilket gör det avgörande för AI-synlighet. Effekten varierar dock beroende på frågetyp – Reddit fungerar bättre för B2C- och konsumentfokuserade frågor än för B2B-yrkesrelaterade frågor. Aktivt deltagande i relevanta Reddit-gemenskaper kan avsevärt öka hur ofta ditt varumärke citeras på flera AI-plattformar.
Vilken roll spelar domänauktoritet för AI-citeringar?
Domänauktoritet fungerar som en tillförlitlighetsindikator i AI-algoritmer, där domäner med högre auktoritet får förtur vid källval. Faktorer är bland annat kvalitet och antal bakåtlänkar, domänålder, ämnesmässig konsekvens och förekomst i kunskapsgrafer som Wikipedia eller Google Knowledge Panel. Även om domänauktoritet är viktigt är det inte den enda faktorn – innehållskvalitet, aktualitet och plattformsspecifika preferenser påverkar också sannolikheten för att bli citerad väsentligt.
Hur ofta bör jag uppdatera innehåll för att behålla AI-citeringssynlighet?
Innehållet bör uppdateras var 48–72 timme för att bibehålla starka färskhetssignaler, även om det inte krävs fullständiga omskrivningar. Att lägga till nya datapunkter, uppdatera statistik, utöka avsnitt med senaste utvecklingen eller förnya exempel upprätthåller citeringsbarheten. Föråldrat innehåll försvinner från AI:s överväganden inom några dagar oavsett historisk auktoritet, vilket gör regelbundna uppdateringar avgörande för att behålla synligheten i AI-genererade svar.
Kan mindre varumärken konkurrera med etablerade om AI-citeringar?
Ja, men med andra strategier. Medan etablerade varumärken har fördelar i domänauktoritet kan mindre varumärken konkurrera genom att: rikta in sig på nischämnen där de har expertis, bygga närvaro på gemenskapsplattformar som Reddit och Quora, skapa mycket specifikt innehåll som direkt besvarar användarfrågor och utnyttja plattformar som Perplexity som värderar mångfald över ren auktoritet. Nischpositionering ger ofta bättre citeringsmöjligheter än att direkt konkurrera med etablerade varumärken om breda ämnen.
Vad är sambandet mellan SEO-rankningar och AI-citeringar?
Det finns ett samband men ingen perfekt överensstämmelse. Google AI Overviews-citeringar korrelerar med traditionella sökrankningar då båda använder liknande auktoritetssignaler, men ChatGPT och Perplexity har andra citeringsmönster. En sida som rankar #1 i Google Search kanske inte citeras av ChatGPT om den saknar Wikipedia-nivå av auktoritet. Framgångsrik AI-synlighet kräver förståelse för plattformsspecifika preferenser snarare än att anta att traditionella SEO-strategier automatiskt genererar AI-citeringar.
Övervaka ditt varumärkes AI-citat
Följ hur ditt varumärke citeras i ChatGPT, Perplexity, Google AI Overviews och andra AI-plattformar. Få insikter i realtid om din AI-synlighet och optimera din innehållsstrategi med AmICited.
Hur du lägger till variation i innehåll för AI – Strategier för bättre AI-synlighet
Lär dig hur du lägger till variation i innehåll för AI-system. Upptäck strategier för olika datakällor, semantisk rikedom, innehållsstruktur och optimeringstekn...
Lär dig det optimala innehållsdjupet, struktur- och detaljkraven för att bli citerad av ChatGPT, Perplexity och Google AI. Upptäck vad som gör innehåll citerbar...
Varför ger AI ibland olika svar från olika källor? Förstå hur den väljer mellan motstridig information
Diskussion i communityn om hur AI-modeller hanterar motstridig information från olika källor. Riktiga erfarenheter från innehållsskapare som analyserar AI:s kon...
6 min läsning
Discussion
AI Search
+1
Cookie-samtycke Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.