
Promptforskning för AI-synlighet: Förstå användarfrågor
Lär dig att genomföra effektiv promptforskning för AI-synlighet. Upptäck metodiken för att förstå användarfrågor i LLM:er och spåra ditt varumärke över ChatGPT,...
10 min läsning
En uppmärksamhetsmekanism är en komponent i neurala nätverk som dynamiskt väger vikten av olika indataelement, vilket gör att modeller kan fokusera på de mest relevanta delarna av datan vid prediktioner. Den beräknar uppmärksamhetsvikter genom inlärda transformationer av queries, keys och values, vilket gör det möjligt för djupa nätverksmodeller att fånga långväga beroenden och kontextmedvetna relationer i sekventiell data.
En uppmärksamhetsmekanism är en komponent i neurala nätverk som dynamiskt väger vikten av olika indataelement, vilket gör att modeller kan fokusera på de mest relevanta delarna av datan vid prediktioner. Den beräknar uppmärksamhetsvikter genom inlärda transformationer av queries, keys och values, vilket gör det möjligt för djupa nätverksmodeller att fånga långväga beroenden och kontextmedvetna relationer i sekventiell data.
Uppmärksamhetsmekanism är en maskininlärningsteknik som styr djupa nätverksmodeller att prioritera (eller “uppmärksamma”) de mest relevanta delarna av indata när de gör prediktioner. Istället för att behandla alla indataelement lika, beräknar uppmärksamhetsmekanismer uppmärksamhetsvikter som återspeglar den relativa betydelsen av varje element för uppgiften i fråga, och tillämpar sedan dessa vikter för att dynamiskt betona eller tona ned specifika indata. Denna grundläggande innovation har blivit hörnstenen i moderna transformatorarkitekturer och stora språkmodeller (LLM:er) som ChatGPT, Claude och Perplexity, vilket gör det möjligt för dem att bearbeta sekventiell data med enastående effektivitet och noggrannhet. Mekanismen är inspirerad av mänsklig kognitiv uppmärksamhet—förmågan att selektivt fokusera på framträdande detaljer samtidigt som irrelevant information filtreras bort—och översätter denna biologiska princip till en matematiskt stringent och inlärningsbar komponent i neurala nätverk.
Konceptet med uppmärksamhetsmekanismer introducerades först av Bahdanau och kollegor 2014 för att åtgärda kritiska begränsningar i rekurrenta neurala nätverk (RNN:er) som användes för maskinöversättning. Innan attention introducerades, förlitade sig Seq2Seq-modeller på en enda kontextvektor för att koda hela källmeningar, vilket skapade en informationsflaskhals som allvarligt begränsade prestandan på längre sekvenser. Den ursprungliga uppmärksamhetsmekanismen gjorde det möjligt för dekodern att komma åt alla dolda tillstånd i kodaren istället för bara det sista, och kunde därmed dynamiskt välja vilka delar av indatan som var mest relevanta vid varje avkodningssteg. Detta genombrott förbättrade översättningskvaliteten drastiskt, särskilt för längre meningar. År 2015 introducerade Luong och kollegor dot-product attention, som ersatte den beräkningsintensiva additive attention med effektiv matris-multiplikation. Den avgörande vändningen kom 2017 med publiceringen av “Attention is All You Need”, som introducerade transformatorarkitekturen som helt övergav rekurrens till förmån för rena uppmärksamhetsmekanismer. Denna artikel revolutionerade djupinlärning och möjliggjorde utvecklingen av BERT, GPT-modeller och hela det moderna generativa AI-ekosystemet. Idag är uppmärksamhetsmekanismer allestädes närvarande inom naturlig språkbehandling, datorseende och multimodala AI-system, där över 85% av de mest avancerade modellerna inkluderar någon form av attention-baserad arkitektur.
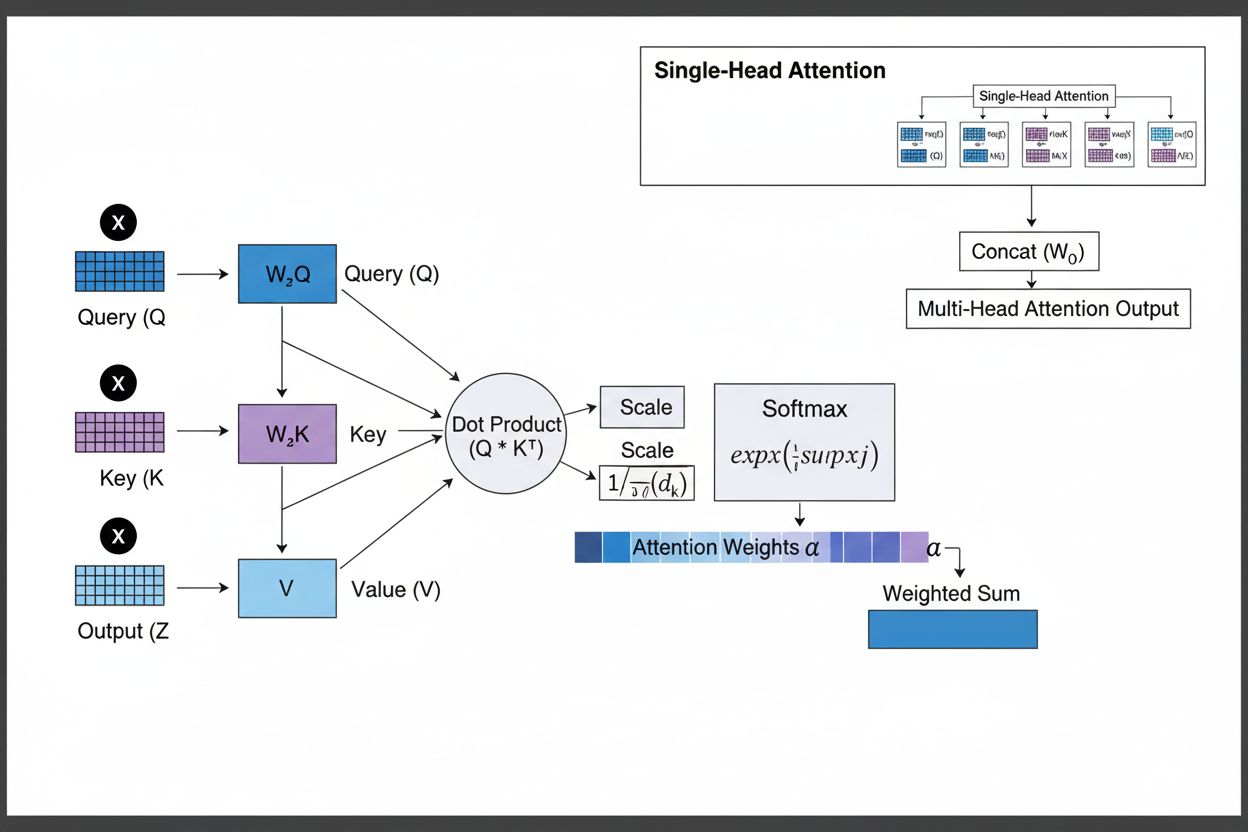
Uppmärksamhetsmekanismen fungerar genom ett sofistikerat samspel mellan tre centrala matematiska komponenter: queries (Q), keys (K) och values (V). Varje indataelement transformeras till dessa tre representationer genom inlärda linjära projektioner, vilket skapar en databasliknande struktur där keys fungerar som identifierare och values innehåller den faktiska informationen. Mekanismen beräknar alignmentscore genom att mäta likheten mellan en query och alla keys, vanligtvis med scaled dot-product attention där scoren beräknas som QK^T/√d_k. Dessa råa score normaliseras sedan med softmax-funktionen, vilket omvandlar dem till en sannolikhetsfördelning där alla vikter summerar till 1, vilket säkerställer att varje element får en vikt mellan 0 och 1. Slutsteget innebär att beräkna en viktad summa av value-vektorerna med dessa uppmärksamhetsvikter, vilket ger en kontextvektor som representerar den mest relevanta informationen från hela indata-sekvensen. Kontextvektorn kombineras sedan med ursprungsindatan genom residualkopplingar och skickas genom feedforward-lager, vilket möjliggör att modellen iterativt kan förfina sin förståelse av indatan. Den matematiska elegansen i denna design—som kombinerar inlärningsbara transformationer, likhetsberäkningar och sannolikhetsviktning—gör att uppmärksamhetsmekanismer kan fånga komplexa beroenden samtidigt som de är fullt differentierbara för gradientbaserad optimering.
| Typ av attention | Beräkningsmetod | Beräkningskomplexitet | Bästa användningsområde | Viktigaste fördel |
|---|---|---|---|---|
| Additive Attention | Feed-forward-nätverk + tanh-aktivering | O(n·d) per query | Kortare sekvenser, variabla dimensioner | Hanterar olika query/key-dimensioner |
| Dot-Product Attention | Enkel matris-multiplikation | O(n·d) per query | Standardsekvenser | Beräkningsmässigt effektiv |
| Scaled Dot-Product | QK^T/√d_k + softmax | O(n·d) per query | Moderna transformatorer | Förhindrar att gradienten försvinner |
| Multi-Head Attention | Flera parallella attention-huvuden | O(h·n·d) där h=huvuden | Komplexa relationer | Fångar olika semantiska aspekter |
| Self-Attention | Queries, keys, values från samma sekvens | O(n²·d) | Intra-sekvensrelationer | Möjliggör parallell bearbetning |
| Cross-Attention | Queries från en sekvens, keys/values från en annan | O(n·m·d) | Encoder-decoder, multimodal | Justerar olika modaliteter |
| Grouped Query Attention | Delar keys/values mellan query-huvuden | O(n·d) | Effektiv inferens | Minskar minne och beräkning |
| Sparse Attention | Begränsad attention till lokala/stridna positioner | O(n·√n·d) | Mycket långa sekvenser | Hanterar extrema sekvenslängder |
Uppmärksamhetsmekanismen verkar genom en noggrant orkestrerad sekvens av matematiska transformationer som gör det möjligt för neurala nätverk att dynamiskt fokusera på relevant information. Vid bearbetning av en indata-sekvens bäddas varje element först in i ett högdimensionellt vektorrum, som fångar semantisk och syntaktisk information. Dessa inbäddningar projiceras sedan till tre separata rum genom inlärda viktmatriser: query-rum (vad som söks), key-rum (vad varje element innehåller för information), och value-rum (den faktiska informationen som ska aggregeras). För varje query-position beräknar mekanismen en likhetspoäng med varje key genom att ta deras dot-produkt, vilket ger en vektor av råa alignmentscore. Dessa score skalas genom division med kvadratroten av key-dimensionen (√d_k), ett avgörande steg som förhindrar att dot-produkterna blir för stora vid höga dimensioner, vilket annars skulle göra att gradienterna försvinner under backpropagation. De skalade score skickas därefter genom en softmax-funktion, som exponentierar varje score och normaliserar dem så att de summerar till 1, vilket skapar en sannolikhetsfördelning över alla indata-positioner. Slutligen används dessa uppmärksamhetsvikter för att beräkna ett viktat medelvärde av value-vektorerna, där positioner med högre attention-vikt bidrar starkare till den slutliga kontextvektorn. Denna kontextvektor kombineras sedan med ursprungsindatan genom residualkopplingar och bearbetas i feedforward-lager, vilket gör att modellen iterativt kan förfina sina representationer. Hela processen är differentierbar, vilket gör att modellen kan lära sig optimala attention-mönster via gradientnedstigning under träning.
Uppmärksamhetsmekanismer utgör den grundläggande byggstenen i transformatorarkitekturer, som blivit det dominerande paradigmet inom djupinlärning. Till skillnad från RNN:er som bearbetar sekvenser sekventiellt och CNN:er som arbetar på fasta lokala fönster, använder transformatorer self-attention för att göra det möjligt för varje position att direkt uppmärksamma alla andra positioner samtidigt, vilket möjliggör massiv parallellisering över GPU:er och TPU:er. Transformatorarkitekturen består av alternerande lager av multi-head self-attention och feedforward-nätverk, där varje attention-lager gör att modellen kan förfina sin förståelse av indatan genom selektivt fokus på olika aspekter. Multi-head attention kör flera attentionmekanismer parallellt, där varje huvud lär sig fokusera på olika typer av relationer—ett huvud kan specialisera sig på grammatiska beroenden, ett annat på semantiska relationer och ett tredje på långväga kärnreferenser. Utgångarna från alla huvuden konkateneras och projiceras, vilket gör att modellen kan hålla medvetenhet om flera språkliga fenomen samtidigt. Denna arkitektur har visat sig vara mycket effektiv för stora språkmodeller som GPT-4, Claude 3 och Gemini, vilka använder endast dekoder-transformatorarkitekturer där varje token bara kan uppmärksamma tidigare tokens (kausal maskning) för att bibehålla den autoregressiva genereringsegenskapen. Attention-mekanismens förmåga att fånga långväga beroenden utan de försvinnande gradientproblem som plågade RNN:er har varit avgörande för att möjliggöra dessa modellers hantering av kontextfönster på över 100 000 tokens, med bibehållen koherens och konsekvens över enorma textmängder. Forskning visar att cirka 92% av de mest avancerade NLP-modellerna nu bygger på transformerarkitekturer som drivs av attentionmekanismer, vilket understryker deras fundamentala betydelse för moderna AI-system.
Inom ramen för AI-sökplattformar som ChatGPT, Perplexity, Claude och Google AI Overviews spelar uppmärksamhetsmekanismer en avgörande roll för att avgöra vilka delar av hämtade dokument och kunskapsbaser som är mest relevanta för användarens fråga. När dessa system genererar svar, viktar deras uppmärksamhetsmekanismer dynamiskt olika källor och avsnitt baserat på relevans, vilket gör att de kan syntetisera sammanhängande svar från flera källor med bibehållen faktamässig korrekthet. De attention-vikter som beräknas under genereringen kan analyseras för att förstå vilken information modellen prioriterade, vilket ger insikt i hur AI-system tolkar och besvarar frågor. För varumärkesövervakning och GEO (Generative Engine Optimization) är förståelsen av uppmärksamhetsmekanismer avgörande eftersom de avgör vilket innehåll och vilka källor som får betoning i AI-genererade svar. Innehåll som är strukturerat för att passa hur attention-mekanismer viktar information—genom tydliga entitetsdefinitioner, auktoritativa källor och kontextuell relevans—har större sannolikhet att citeras och synas framträdande i AI-svar. AmICited använder insikter om uppmärksamhetsmekanismer för att spåra hur varumärken och domäner syns över AI-plattformar, med insikten att attention-viktade citeringar representerar de mest inflytelserika omnämnandena i AI-genererat innehåll. I takt med att företag i allt högre grad övervakar sin närvaro i AI-svar blir förståelsen att attention-mekanismer styr citeringsmönster avgörande för att optimera innehållsstrategin och säkerställa varumärkets synlighet i den generativa AI-eran.
Fältet uppmärksamhetsmekanismer utvecklas snabbt, där forskare utvecklar allt mer sofistikerade varianter för att åtgärda beräkningsbegränsningar och förbättra prestanda. Sparsamma attention-mönster begränsar attention till lokala områden eller stridna positioner, vilket minskar komplexiteten från O(n²) till O(n·√n) samtidigt som prestandan bibehålls för mycket långa sekvenser. Effektiva attention-mekanismer som FlashAttention optimerar minnesåtkomsten vid attention-beräkning, med 2–4 gånger snabbare körning genom bättre GPU-utnyttjande. Grouped query attention och multi-query attention minskar antalet key-value-huvuden med bibehållen prestanda, vilket avsevärt minskar minnesbehovet vid inferens—en avgörande faktor för att driftsätta stora modeller i produktion. Mixture of Experts-arkitekturer kombinerar attention med sparsam routing, vilket gör det möjligt att skala modeller till biljoner parametrar med bibehållen beräkningsmässig effektivitet. Nya forskningsrön utforskar inlärda attention-mönster som dynamiskt anpassas baserat på indatans egenskaper och hierarkisk attention som verkar på flera abstraktionsnivåer. Integrationen av attention-mekanismer med retrieval-augmented generation (RAG) gör det möjligt för modeller att dynamiskt uppmärksamma relevant extern kunskap, vilket förbättrar faktakvalitet och minskar hallucinationer. I takt med att AI-system används i allt mer kritiska applikationer, förbättras attentionmekanismer med förklaringsfunktioner som ger tydligare insikt i modellens beslutsfattande. Framtiden innebär sannolikt hybridarkitekturer som kombinerar attention med alternativa mekanismer som state-space models (exempelvis Mamba), vilka erbjuder linjär komplexitet med bibehållen konkurrenskraftig prestanda. Att förstå dessa utvecklande uppmärksamhetsmekanismer är avgörande för praktiker som bygger nästa generations AI-system och för organisationer som övervakar sin närvaro i AI-genererat innehåll, då mekanismerna som avgör citeringsmönster och innehållsdominans fortsätter att utvecklas.
För organisationer som använder AmICited för att övervaka varumärkets synlighet i AI-svar ger förståelsen av uppmärksamhetsmekanismer avgörande kontext för att tolka citeringsmönster. När ChatGPT, Claude eller Perplexity citerar din domän i sina svar, avgjorde de attention-vikter som beräknades under genereringen att ditt innehåll var mest relevant för användarens fråga. Högkvalitativt, välstrukturerat innehåll som tydligt definierar entiteter och tillhandahåller auktoritativ information får naturligt högre attention-vikter, vilket gör det mer sannolikt att väljas för citering. Attention-visualiseringar i vissa AI-plattformar visar vilka källor som fick störst fokus vid genereringen av svaret, och visar därmed vilka citeringar som var mest inflytelserika. Denna insikt gör att organisationer kan optimera sin innehållsstrategi genom att förstå att attention-mekanismer belönar tydlighet, relevans och auktoritativa källor. I takt med att AI-sök växer—med över 60% av företagen som nu investerar i generativa AI-initiativ—blir förmågan att förstå och optimera för uppmärksamhetsmekanismer alltmer värdefull för att bibehålla varumärkets synlighet och säkerställa korrekt representation i AI-genererat innehåll. Mötet mellan uppmärksamhetsmekanismer och varumärkesövervakning är en grens inom GEO, där förståelsen av de matematiska grunderna för hur AI-system viktar och citerar information direkt översätts till ökad synlighet och inflytande i det generativa AI-ekosystemet.
Traditionella RNN:er bearbetar sekvenser seriellt, vilket gör det svårt att fånga långväga beroenden, medan CNN:er har fasta lokala mottagningsfält som begränsar deras förmåga att modellera avlägsna relationer. Uppmärksamhetsmekanismer övervinner dessa begränsningar genom att beräkna relationer mellan alla indata-positioner samtidigt, vilket möjliggör parallell bearbetning och fångar beroenden oavsett avstånd. Denna flexibilitet över både tid och rum gör uppmärksamhetsmekanismer mycket mer effektiva och ändamålsenliga för komplex sekventiell och spatial data.
Queries representerar vilken information modellen för närvarande söker, keys representerar informationsinnehållet som varje indataelement innehåller, och values innehåller den faktiska datan som ska aggregeras. Modellen beräknar likhetspoäng mellan queries och keys för att avgöra vilka values som ska viktas högst. Denna databas-inspirerade terminologi, som populariserades av artikeln 'Attention is All You Need', ger ett intuitivt ramverk för att förstå hur uppmärksamhetsmekanismer selektivt hämtar och kombinerar relevant information från indata-sekvenser.
Self-attention beräknar relationer inom en och samma indata-sekvens, där queries, keys och values alla kommer från samma källa, vilket gör att modellen kan förstå hur olika element relaterar till varandra. Cross-attention, däremot, använder queries från en sekvens och keys/values från en annan, vilket gör att modellen kan anpassa och kombinera information från flera källor. Cross-attention är avgörande i encoder-decoder-arkitekturer som maskinöversättning och i multimodala modeller som Stable Diffusion som kombinerar text- och bildinformation.
Scaled dot-product attention använder multiplikation istället för addition för att beräkna alignmentscore, vilket gör det beräkningsmässigt mer effektivt genom matrisoperationer som utnyttjar GPU-parallellisering. Skalningsfaktorn 1/√dk förhindrar att dot-produkter blir för stora när key-dimensionen är hög, vilket annars skulle orsaka att gradienterna försvinner under backpropagation. Även om additive attention ibland presterar bättre än dot-product attention för mycket stora dimensioner, gör scaled dot-product attentions överlägsna datorkraft och praktiska prestanda den till standardvalet i moderna transformatorarkitekturer.
Multi-head attention kör flera uppmärksamhetsmekanismer parallellt, där varje huvud lär sig att fokusera på olika aspekter av indata så som grammatiska relationer, semantisk betydelse eller långväga beroenden. Varje huvud arbetar på olika linjära projektioner av indata, vilket gör att modellen samtidigt kan fånga olika typer av relationer. Utgångarna från alla huvuden konkateneras och projiceras, vilket gör att modellen kan ha omfattande medvetenhet om flera språkliga och kontextuella egenskaper samtidigt och därigenom förbättra representationskvalitet och prestanda för nedströmsuppgifter avsevärt.
Softmax normaliserar de råa alignmentscore som beräknas mellan queries och keys till en sannolikhetsfördelning där alla vikter summerar till 1. Denna normalisering säkerställer att uppmärksamhetsvikter kan tolkas som betydelsegrader, där högre värden indikerar större relevans. Softmax-funktionen är differentierbar, vilket möjliggör gradientbaserad inlärning av uppmärksamhetsmekanismen under träning, och dess exponentiella karaktär förstärker skillnader mellan score, vilket gör modellens fokus mer selektivt och tolkningsbart.
Uppmärksamhetsmekanismer gör det möjligt för dessa modeller att dynamiskt vikta olika delar av indataprompten baserat på relevans för det aktuella genereringssteget. Vid generering av ett svar använder modellen attention för att avgöra vilka tidigare tokens och indatadelar som mest ska påverka nästa token-prediktion. Denna kontextmedvetna viktning gör att modellerna kan bibehålla koherens, hålla reda på entiteter över långa dokument, lösa tvetydigheter och generera svar som på lämpligt sätt refererar till specifika delar av indatan, vilket gör deras utdata mer korrekta och kontextuellt passande.
Börja spåra hur AI-chatbotar nämner ditt varumärke på ChatGPT, Perplexity och andra plattformar. Få handlingsbara insikter för att förbättra din AI-närvaro.
Lär dig att genomföra effektiv promptforskning för AI-synlighet. Upptäck metodiken för att förstå användarfrågor i LLM:er och spåra ditt varumärke över ChatGPT,...

Upptäck hur branschutmärkelser påverkar AI-synlighet, varumärkesciteringar i AI-svar och konkurrenspositionering. Lär dig varför utmärkelser är viktiga för AI-p...
Lär dig vad prompt engineering är, hur det fungerar med AI-sökmotorer som ChatGPT och Perplexity, och upptäck viktiga tekniker för att optimera dina AI-sökresul...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.