
Kanonisk strategi för AI-sök: Optimera ditt innehåll för AI-motorer
Lär dig hur kanoniska taggar hjälper ditt innehåll att ranka i AI-sökmotorer. Upptäck bästa praxis för kanonisk strategi för ChatGPT, Perplexity och Google AI O...
13 min läsning

En kanonisk URL är den föredragna versionen av en webbsida som sökmotorer ska genomsöka, indexera och ranka när flera URL:er innehåller identiskt eller liknande innehåll. Den specificeras med hjälp av HTML-taggen rel=“canonical” för att konsolidera rankningssignaler och förhindra problem med duplicerat innehåll.
En kanonisk URL är den föredragna versionen av en webbsida som sökmotorer ska genomsöka, indexera och ranka när flera URL:er innehåller identiskt eller liknande innehåll. Den specificeras med hjälp av HTML-taggen rel="canonical" för att konsolidera rankningssignaler och förhindra problem med duplicerat innehåll.
En kanonisk URL är den primära, föredragna eller auktoritativa versionen av en webbsida som du anger för att sökmotorer ska genomsöka, indexera och ranka när flera URL:er innehåller identiskt eller väsentligen liknande innehåll. Begreppet “kanonisk” härstammar från idén om att etablera en enda auktoritativ källa bland flera varianter. Inom sökmotoroptimering och webbaritektur fungerar en kanonisk URL som huvudkopian som konsoliderar rankningssignaler, länkstyrka och indexeringsauktoritet från alla dubblett- eller nästan dubblettversioner av samma innehåll. Denna åtskillnad är avgörande eftersom sökmotorer som Google, Bing och i allt högre grad AI-söksystem som ChatGPT, Perplexity och Claude behandlar varje unik URL som en separat sida, även när innehållet är identiskt. Genom att explicit ange en kanonisk URL via HTML-taggen rel="canonical" eller andra kanoniseringsmetoder kommunicerar webbansvariga sin preferens till sökmotorer, vilket säkerställer att rätt version får prioritet vid indexering och rankingfördelar.
Konceptet kanoniska URL:er uppstod i takt med att webteknologier utvecklades och webbplatser blev alltmer komplexa. I internets barndom hade de flesta webbplatser enkla URL-strukturer med minimalt med dubbletter. Men i och med att content management-system (CMS), e-handelsplattformar och dynamiska webbtillämpningar blev vanliga spred sig problemet med oavsiktligt duplicerat innehåll. Enligt forskning från de största SEO-plattformarna har över 30 % av webbplatserna betydande problem med duplicerat innehåll, ofta utan att webbansvariga är medvetna om det. Denna duplicering uppstår via olika mekanismer: URL-parametrar för spårning och filtrering, flera protokollversioner (HTTP kontra HTTPS), domänvarianter (www kontra icke-www), mobilspecifika URL:er, sessions-ID:n och pagineringsparametrar. Googles John Mueller har betonat att kanoniska taggar är avgörande för att kommunicera webbplatsens struktur till sökmotorer, särskilt när webbplatser genererar flera URL:er för samma innehåll. Specifikationen rel="canonical" introducerades formellt av Google, Yahoo och Microsoft 2009 som en standardiserad metod för webbansvariga att ange föredragna URL:er. Sedan dess har kanoniska URL:er blivit en grundläggande komponent i teknisk SEO, där över 78 % av företagswebbplatser implementerar kanoniska taggar som del av sin SEO-strategi. Betydelsen av kanoniska URL:er har bara ökat i och med AI-sökmotorers och generativa AI-systemens framväxt, vilka förlitar sig på korrekt kanonisering för att tillskriva innehåll korrekt och undvika att indexera dubblettversioner.
Kanoniseringsprocessen fungerar genom ett systematiskt arbetsflöde som sökmotorer följer när de stöter på flera URL:er med identiskt eller liknande innehåll. När en sökmotorrobot besöker din webbplats identifierar den sidor som innehåller samma eller nästan samma innehåll över olika URL:er. Crawlern letar sedan efter kanoniseringssignaler för att avgöra vilken version som ska behandlas som huvudsidan. Dessa signaler inkluderar HTML-taggen rel="canonical" placerad i sidans <head>, HTTP-header med kanonisk information, 301-omdirigeringar, interna länkningsmönster, XML-sitemap-poster och HTTPS-prioritetssignaler. Den tydligaste och starkaste signalen är rel="canonical"-länkelementet, som i HTML-källkoden ser ut så här: <link rel="canonical" href="https://www.example.com/preferred-url" />. När sökmotorer stöter på denna tagg förstår de att URL:en i href-attributet är den kanoniska versionen. Crawlern konsoliderar sedan alla rankningssignaler – inklusive bakåtlänkar, interna länkar, användarengagemang och auktoritet – till den kanoniska URL:en. Denna konsolidering är avgörande för att förhindra att rankingkraften fördelas över flera dubblett-URL:er. Om till exempel din produktsida är tillgänglig via fem olika URL:er på grund av spårningsparametrar och domänvarianter, och varje URL får bakåtlänkar var för sig, skulle dessa länkar normalt konkurrera med varandra. Med korrekt kanonisering flödar all länkstyrka till den enda kanoniska URL:en, vilket avsevärt stärker dess rankingpotential. Forskning visar att korrekt kanonisering kan förbättra synligheten i sökresultat med 15–30 % för webbplatser med betydande problem med duplicerat innehåll.
| Aspekt | Kanonisk URL (rel=“canonical”) | 301-omdirigering | Sitemap-inkludering | Robots.txt-blockering |
|---|---|---|---|---|
| Syfte | Anger föredragen version med bibehållna dubbletter | Flyttar permanent en URL till en annan | Föreslår kanoniska URL:er för sökmotorer | Förhindrar genomsökning av dubblettsidor |
| Användarupplevelse | Användare kan nå både kanonisk och dubblett-URL | Användare omdirigeras automatiskt till ny URL | Ingen direkt påverkan | Användare kan inte nå blockerade URL:er |
| Styrka på sökmotorsignal | Stark signal; konsoliderar rankingkraft | Starkast signal; fullständig URL-konsolidering | Svag signal; Google avgör dubbletter | Rekommenderas ej för kanonisering |
| Implementeringskomplexitet | Måttlig; kräver HTML-ändring eller CMS-inställning | Måttlig; kräver serverkonfiguration | Enkel; lägg till URL:er i sitemap | Enkel; lägg till regler i robots.txt |
| Bästa användningsfall | Duplicerat innehåll som måste vara tillgängligt | Avveckling av gamla URL:er eller migreringar | Stora webbplatser med många kanoniska URL:er | Blockera test-/stagingmiljöer |
| Länkkraftkonsolidering | Ja; signaler går till kanonisk URL | Ja; all kraft överförs till ny URL | Delvis; beroende på Googles tolkning | Nej; blockerar genomsökning helt |
| Reversibilitet | Ja; kan ändras eller tas bort | Svår; kräver ny omdirigering | Ja; kan uppdateras i sitemap | Ja; kan tas bort i robots.txt |
| Påverkan på crawlbudget | Måttlig; minskar slösad crawl på dubbletter | Hög; eliminerar crawl av gamla URL:er | Låg; crawlar ändå alla URL:er i sitemap | Hög; förhindrar crawl av dubbletter |
Implementering av kanoniska URL:er kräver förståelse för de specifika metoder som finns tillgängliga och att välja det tillvägagångssätt som bäst passar din webbplats arkitektur och CMS. rel="canonical"-länkelementet är den vanligaste metoden och placeras direkt i HTML-
<link rel="canonical" href="https://www.example.com/products/blue-shoes" /> på alla dubblettversioner. Den kanoniska URL:en ska vara en ren, tillgänglig URL utan spårningsparametrar, sessions-ID eller onödiga query-strängar. Självrefererande kanoniska taggar – där en sidas kanoniska tagg pekar på dess egen URL – rekommenderas alltmer som bästa praxis. Detta förstärker för sökmotorer vilken URL som är kanonisk, även för unika sidor, och förhindrar oavsiktliga kanoniseringsproblem. För icke-HTML-innehåll som PDF:er, Word-dokument eller andra filtyper är rel="canonical"-HTTP-header mer lämplig. Detta innebär att du konfigurerar din server att skicka en Link-header i HTTP-svaret: Link: <https://www.example.com/document.pdf>; rel="canonical". Denna metod är särskilt användbar för webbplatser som publicerar innehåll i flera format på olika URL:er. Dessutom fungerar 301-omdirigeringar som en stark kanoniseringssignal, särskilt när du vill konsolidera URL:er helt och ta bort den gamla versionen från sökresultaten. När Sida A omdirigeras med statuskod 301 till Sida B förstår sökmotorer att Sida B är den kanoniska versionen och överför alla rankningssignaler därefter. XML-sitemaps ger en svagare men ändå värdefull kanoniseringssignal genom att endast lista de kanoniska URL:er du vill ska indexeras. Slutligen är HTTPS-prioritet en automatisk signal där Google föredrar HTTPS-versioner över HTTP-ekvivalenter, så se till att dina kanoniska URL:er använder HTTPS för korrekt kanonisering.Duplicerat innehåll är en av de största utmaningarna inom modern webbförvaltning och påverkar ungefär 29 % av alla indexerade webbsidor enligt branschforskning. Duplicerat innehåll uppstår från många källor: e-handelssajter med produktfilter och sorteringsalternativ som genererar unika URL:er för samma produkt, bloggar med taggarkiv och kategorisidor som visar samma artiklar, syndikering av innehåll mellan olika domäner, mobilspecifika URL:er vid sidan av desktopversioner, samt oavsiktliga dubbletter från staging- eller testsidor. Utan korrekt kanonisering måste sökmotorer själva avgöra vilken version som ska indexeras, vilket ofta inte överensstämmer med dina affärsmål. Detta kan leda till nyckelords kannibalisering, där flera versioner av samma innehåll konkurrerar om samma söktermer, vilket försvagar rankingkraften och minskar synligheten. Kanoniska URL:er löser detta problem genom att tydligt kommunicera din preferens till sökmotorerna. När du anger en kanonisk URL förstår sökmotorerna att alla duplicerade versioner ska behandlas som varianter av ett och samma innehåll, med rankingkraften konsoliderad till den kanoniska versionen. Denna konsolidering är särskilt viktig för länkstyrkefördelning. Om din webbplats får bakåtlänkar till olika URL-varianter av samma innehåll skulle dessa länkar normalt räknas separat och splittra rankingkraften. Med kanoniska taggar flödar all länkstyrka till den kanoniska URL:en och skapar en starkare ranking. Om din startsida till exempel är tillgänglig via https://www.example.com, https://example.com, http://www.example.com och http://example.com och varje version får bakåtlänkar, säkerställer kanoniska taggar att all länkstyrka konsolideras till din föredragna version. Denna konsolidering kan resultera i 15–30 % förbättring av sökrankningar för sidor med betydande problem med duplicerat innehåll.
E-handelswebbplatser står inför särskilt komplexa kanoniseringsutmaningar på grund av produktsidor och filtreringssystem. En enda produkt kan vara tillgänglig via flera URL:er: den direkta produkt-URL:en, URL:er med filter för färg eller storlek, URL:er med sorteringsparametrar, URL:er med spårningskoder för marknadsföringskampanjer och mobilspecifika URL:er. Utan korrekt kanonisering kan sökmotorer indexera dussintals varianter av samma produktsida, vilket slösar crawlbudget och försvagar rankingkraften. E-handelssajter som implementerar korrekt kanonisering rapporterar 20–40 % förbättring i organisk trafik tack vare konsoliderade ranking-signaler. Den kanoniska URL:en för en produkt bör vanligtvis vara den rena produkt-URL:en utan några parametrar: https://www.example.com/products/blue-running-shoes. Alla filtrerade, sorterade eller spårade varianter ska innehålla en kanonisk tagg som pekar på denna rena URL. CMS-system som Magento, Shopify och WooCommerce har ofta inbyggda funktioner för kanonisering som automatiskt genererar lämpliga kanoniska taggar. Dessa system kräver dock ibland konfiguration för att säkerställa att de fungerar korrekt. För Shopify-butiker läggs kanoniska taggar automatiskt till på produkt- och kategorisidor, men anpassade implementationer kan kräva manuell konfiguration. Magento har inställningar för att aktivera kanoniska taggar för produkter och kategorier, men kategorikanonisering kräver noggrannhet för att undvika oavsiktlig konsolidering. WordPress-webbplatser med SEO-plugins som Yoast SEO eller Rank Math kan automatiskt skapa kanoniska taggar, med möjlighet att anpassa dem per sida. Den viktigaste principen för kanonisering av e-handel är att alla produktvarianter – oavsett om de skapats via filter, sortering eller spårningsparametrar – pekar på en enda kanonisk produkt-URL, så att sökmotorer korrekt kan indexera och ranka produkten med alla ranking-signaler konsoliderade.
Framväxten av AI-sökmotorer och generativa AI-system har gett kanoniska URL:er en ny dimension av betydelse. Plattformar som ChatGPT, Perplexity, Claude och Google AI Overviews förlitar sig på webbcrawling och indexering för att samla information till sina svar. När dessa AI-system stöter på flera URL:er med identiskt innehåll hjälper korrekt kanonisering dem att identifiera den auktoritativa källan att citera i sina svar. Över 60 % av företag oroar sig nu för hur deras innehåll visas i AI-genererade svar, vilket gör hanteringen av kanoniska URL:er allt viktigare för varumärkessynlighet och attribution. När ett AI-system genomsöker din webbplats och hittar flera URL:er med samma innehåll måste det avgöra vilken version som ska citeras som källa. Utan kanoniska taggar kan AI-systemet citera en icke-kanonisk version, vilket potentiellt leder användare till en mindre optimal sida eller misslyckas att korrekt attribuera ditt varumärke. Med korrekt kanonisering säkerställer du att AI-system citerar din föredragna URL, förbättrar användarupplevelsen och upprätthåller konsekvent varumärkesattributering. Detta är särskilt viktigt för AI-citeringsspårning och övervakning, där plattformar som AmICited hjälper organisationer att följa hur deras innehåll visas i AI-genererade svar. Genom att implementera kanoniska taggar korrekt ökar du sannolikheten att din föredragna URL visas i AI-citeringar, vilket förbättrar synligheten i det AI-drivna söklandskapet. Dessutom hjälper kanoniska URL:er AI-system att förstå din webbplats struktur och innehållshierarki, vilket möjliggör mer exakta och relevanta citeringar. I takt med att AI-sök växer – Perplexity rapporterar över 500 miljoner aktiva användare per månad och ChatGPT:s sökfunktion expanderar – blir korrekt kanonisering avgörande för att upprätthålla synlighet och attribution i AI-genererat innehåll.
Effektiv implementering av kanoniska URL:er kräver att man följer etablerad bästa praxis så att sökmotorer och AI-system korrekt känner igen och respekterar dina kanoniseringssignaler. Använd absoluta URL:er istället för relativa URL:er i dina kanoniska taggar, och inkludera alltid hela protokollet och domänen: <link rel="canonical" href="https://www.example.com/page" /> istället för <link rel="canonical" href="/page" />. Relativa URL:er kan orsaka problem, särskilt om din testmiljö av misstag blir genomsökt eller om URL-strukturer ändras. Säkerställ konsekvens mellan alla kanoniseringssignaler – dina kanoniska taggar, interna länkar, XML-sitemap-poster och 301-omdirigeringar ska alla peka på samma URL. Motstridiga signaler förvirrar sökmotorer och minskar effekten av kanoniseringen. Undvik kedjor av kanoniska taggar, där Sida A pekar på Sida B och Sida B pekar på Sida C. Sökmotorer kanske inte följer dessa kedjor korrekt, vilket leder till felaktig kanonisering. Peka aldrig kanoniska taggar mot omdirigerade URL:er eller mot sidor som blockeras av robots.txt eller är märkta med noindex. Detta skapar motstridiga signaler som sökmotorer har svårt att tolka. Implementera självrefererande kanoniska taggar på alla sidor, även på de sidor som är kanoniska i sig själva. Detta förstärker för sökmotorer vilken URL som är kanonisk och förhindrar oavsiktliga kanoniseringsproblem. Använd HTTPS i dina kanoniska URL:er om din webbplats stödjer HTTPS, eftersom sökmotorer föredrar HTTPS-versioner. Upprätthåll konsekvent URL-format avseende snedstreck, www-prefix och versalisering. Bestäm till exempel om dina kanoniska URL:er ska ha snedstreck (https://example.com/page/) eller inte (https://example.com/page) och tillämpa detta konsekvent på hela webbplatsen. Granska regelbundet dina kanoniska taggar med verktyg som Google Search Console, Moz Pro Site Crawl eller Semrush Site Audit för att identifiera saknade, felaktiga eller motstridiga kanoniska taggar. Testa din implementering med hjälp av webbläsarens utvecklarverktyg eller SEO-verktyg för att kontrollera att de kanoniska taggarna är korrekt placerade i HTML-head-sektionen och pekar på rätt URL:er.
Trots vikten av kanoniska URL:er implementeras de ofta felaktigt på många webbplatser, vilket underminerar deras effektivitet och kan skada SEO-prestandan. Ett av de vanligaste misstagen är att peka kanoniska taggar mot obefintliga eller trasiga URL:er. Detta skapar en situation där sökmotorer får motstridiga signaler – den kanoniska taggen föreslår en URL som ska indexeras, men den URL:en returnerar ett 404-fel eller är blockerad från indexering. Kontrollera alltid att dina kanoniska URL:er är tillgängliga, returnerar statuskod 200 och inte är blockerade av robots.txt eller märkta med noindex. Ett annat vanligt fel är att använda kanoniska taggar för icke-duplicerat innehåll. Kanoniska taggar ska endast användas för duplicerat eller nästan identiskt innehåll. Vissa SEO-specialister försöker felaktigt använda kanoniska taggar för att konsolidera ranking från olika sidor, till exempel genom att styra auktoritet från slutsålda produktsidor till kategorisidor. Google avråder uttryckligen från detta och kommer sannolikt att ignorera sådana kanoniska taggar. Kedjor av kanoniska taggar är också ett betydande problem, där Sida A pekar på Sida B, Sida B på Sida C, och så vidare. Sökmotorer kanske inte följer dessa kedjor korrekt, vilket leder till felaktig kanonisering. Se alltid till att kanoniska taggar pekar direkt på den slutliga kanoniska URL:en. Motstridiga kanoniseringssignaler uppstår när olika metoder pekar på olika URL:er. Om till exempel din kanoniska tagg pekar på en URL men din 301-omdirigering på en annan får sökmotorer motstridiga data och kan ignorera båda signalerna. Se till att alla kanoniseringsmetoder – kanoniska taggar, omdirigeringar, sitemaps och interna länkar – pekar på samma URL. Placera inte kanoniska taggar utanför HTML-head-sektionen eftersom sökmotorer då inte hittar dem. Kanoniska taggar måste ligga i <head>-sektionen i din HTML. Om de placeras i body- eller footerdelen kanske sökmotorer inte känner igen dem. Att använda relativa URL:er istället för absoluta URL:er kan orsaka problem, särskilt om din webbplatsstruktur ändras eller om testmiljöer av misstag genomsöks. Använd alltid kompletta URL:er inklusive protokoll och domän. Att glömma självrefererande kanoniska taggar på de sidor som är kanoniska i sig själva kan leda till oavsiktliga kanoniseringsproblem. Varje sida, även kanoniska sidor, ska ha en kanonisk tagg som pekar på sin egen URL. Felhantering av kanoniska taggar ihop med hreflang-taggar på flerspråkiga webbplatser kan också skapa problem. Varje språkversion ska ha en egen kanonisk tagg som pekar på sig själv, med hreflang-taggar som anger alla tillgängliga språkversioner.
Crawlbudget – antalet sidor som sökmotorer genomsöker på din webbplats inom en given tidsperiod – är en begränsad resurs, särskilt för stora webbplatser. Webbplatser med mycket duplicerat innehåll kan slösa bort 20–40 % av sin crawlbudget på sidor som inte behöver indexeras. Kanoniska URL:er hjälper till att optimera crawlbudgeten genom att signalera för sökmotorer vilka sidor som är värda att genomsöka och indexera. När du implementerar kanoniska taggar korrekt förstår sökmotorer att dubblettsidor inte behöver genomsökas lika noggrant, vilket gör att de kan lägga mer crawlbudget på unikt, värdefullt innehåll. Detta är särskilt viktigt för stora e-handelssajter med tusentals produktvarianter, nyhetssajter med flera artikeltyper och innehållsplattformar med omfattande tagg- och kategorisidor. Genom att konsolidera dubblett-URL:er via kanonisering säkerställer du att sökmotorer lägger crawlbudgeten på de sidor som är viktigast för din verksamhet. Detta kan leda till snabbare indexering av nytt innehåll, oftare genomsökning av viktiga sidor och förbättrad total synlighet i sökresultat. Dessutom minskar korrekt kanonisering antalet URL:er som visas i Google Search Console, vilket gör det lättare att övervaka och hantera webbplatsens sökprestanda. För webbplatser med begränsad crawlbudget – särskilt mindre webbplatser eller de i konkurrensutsatta nischer – kan optimering av crawlbudgeten genom kanonisering ha en mätbar effekt på ranking och synlighet.
I takt med att söklandskapet utvecklas med AI-drivna sökmotorer och generativa AI-system blir kanoniska URL:ers roll allt viktigare. Marknaden för AI-sök förväntas växa från 5,2 miljarder dollar 2024 till över 15 miljarder dollar 2030, där plattformar som Perplexity, ChatGPT och Claude tar betydande marknadsandelar. Dessa AI-system förlitar sig på webbscrawling och innehållsindexering på samma sätt som traditionella sökmotorer, vilket gör kanoniska URL:er avgörande för korrekt tillskrivning och synlighet. I framtiden kommer kanoniska URL:er troligen att integreras mer med AI-citeringsspårnings- och övervakningssystem. Plattformar som AmICited är pionjärer inom spårning av hur innehåll visas i AI-genererade svar, och kanoniska URL:er kommer att spela en central roll för korrekt attribution. När AI-system blir mer sofistikerade kan de utveckla bättre metoder för att identifiera kanoniska URL:er och konsolidera information från flera källor. Dessutom gör framväxten av federerade sökningar och AI-system med multipla källor som kombinerar resultat från flera sökmotorer och datakällor kanoniska URL:er ännu viktigare för att säkerställa konsekvent innehållsrepresentation över plattformar. Organisationer som redan nu implementerar kanoniska URL:er korrekt kommer att stå bättre rustade för att behålla synlighet och attribution i takt med att AI-sök utvecklas. I takt med att regleringar kring integritet och tillskrivning av innehåll skärps kan kanoniska URL:er dessutom bli ett standardkrav för licensiering och syndikering av innehåll. Integrationen av kanoniska URL:er med strukturerad datamarkup och semantiska webbteknologier kan också möjliggöra mer avancerad konsolidering och attribution av innehåll. I slutändan utgör kanoniska URL:er ett grundläggande element i webbaritekturen som kommer att förbli relevant och viktigt oavsett hur sökteknologin utvecklas.
En kanonisk URL använder taggen rel="canonical" för att ange en föredragen version samtidigt som båda URL:erna är tillgängliga för användare. En 301-omdirigering flyttar permanent en URL till en annan och skickar automatiskt både användare och sökmotorer till den nya platsen. Använd kanoniska taggar när du behöver att duplicerat innehåll ska vara tillgängligt och 301-omdirigeringar när du vill helt konsolidera URL:er och ta bort den gamla versionen från sökresultaten.
Ja, kanoniska taggar över domäner stöds av Google och andra sökmotorer. Detta är användbart när du syndikerar innehåll över flera webbplatser eller hanterar relaterade domäner. Använd dock cross-domain-kanoniska taggar strategiskt, eftersom de koncentrerar all rankningskraft till en enda domän, vilket potentiellt kan begränsa synligheten på andra egendomar. Säkerställ att din affärsstrategi är i linje med detta tillvägagångssätt innan du implementerar kanonisering över domäner.
Utan kanoniska taggar kan sökmotorer få svårt att identifiera vilken version av duplicerat innehåll som ska indexeras och rankas. Det kan resultera i splittrade rankningssignaler över flera URL:er, bortkastad crawlbudget på dubblettsidor och potentiellt lägre synlighet i sökresultaten. Google försöker automatiskt avgöra vilken version som är kanonisk, men det är inte säkert att den väljer den URL du föredrar, vilket kan leda till suboptimal SEO-prestanda och inkonsekventa resultat.
Även om det inte är strikt nödvändigt anses det vara bästa praxis att implementera självrefererande kanoniska taggar på alla sidor. Detta förstärker för sökmotorerna vilken URL som är kanonisk, även för unika sidor. Självrefererande kanoniska taggar är särskilt viktiga för startsidor och ofta besökta sidor som kan nås via flera URL-varianter (med/utan www, snedstreck, HTTP kontra HTTPS).
Kanoniska URL:er hjälper AI-sökmotorer att förstå vilken innehållsversion du föredrar, på samma sätt som traditionella sökmotorer. När AI-system genomsöker och indexerar ditt innehåll för citering i svar, signalerar kanoniska taggar vilken URL som ska anges som den auktoritativa källan. Detta är allt viktigare för AI-citeringsspårning och för att säkerställa att din domän får korrekt attributering i AI-genererade svar på plattformar som ChatGPT, Perplexity, Claude och Google AI Overviews.
Ja, rel="canonical" HTTP-headern stöds av sökmotorer för icke-HTML-innehåll som PDF:er och dokument. Denna metod är användbar när du inte kan ändra HTML-head-sektionen direkt. Dock föredras generellt HTML-kanoniska taggar för webbsidor eftersom de är mer tillförlitliga och enklare att implementera. För icke-HTML-filer utgör HTTP-headern ett effektivt alternativ för att ange kanoniska URL:er.
En självrefererande kanonisk tagg är när en sidas kanoniska tagg pekar på dess egen URL. Till exempel skulle en sida på https://example.com/blog/article ha en kanonisk tagg som pekar på https://example.com/blog/article. Denna praxis förstärker för sökmotorer att sidan är sin egen kanoniska version och hjälper till att förebygga oavsiktliga kanoniseringsproblem, särskilt på webbplatser med komplexa URL-strukturer eller dynamiskt innehåll.
Du kan granska kanoniska taggar på flera sätt: visa sidans källkod och sök efter "canonical" i HTML-head-sektionen, använd SEO-verktyg som Moz Pro Site Crawl eller Semrush Site Audit för att skanna hela webbplatsen efter kanoniska problem, kontrollera Google Search Consoles URL-inspektionsverktyg för att se vilken kanonisk URL Google känner igen, eller använd webbläsartillägg som MozBar för att snabbt se kanonisk information. Regelbundna granskningar hjälper dig att identifiera saknade, felaktiga eller motstridiga kanoniska taggar.
Börja spåra hur AI-chatbotar nämner ditt varumärke på ChatGPT, Perplexity och andra plattformar. Få handlingsbara insikter för att förbättra din AI-närvaro.
Lär dig hur kanoniska taggar hjälper ditt innehåll att ranka i AI-sökmotorer. Upptäck bästa praxis för kanonisk strategi för ChatGPT, Perplexity och Google AI O...
Diskussion i communityn om hur kanoniska taggar påverkar AI-synlighet. Strategier för att förhindra citeringskannibalisering i ChatGPT, Perplexity och Google AI...
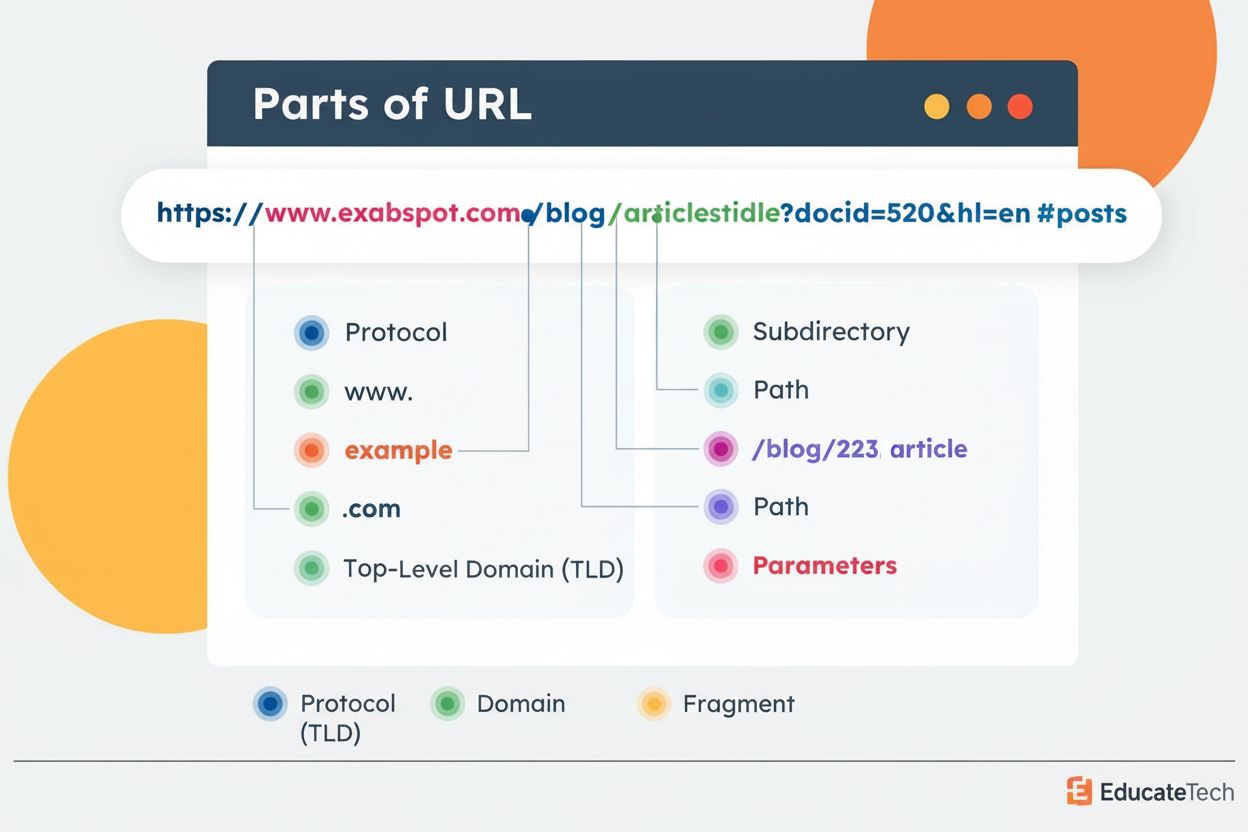
URL-struktur är formatet och organiseringen av webbsidornas adresser inklusive protokoll, domän, sökväg och parametrar. Lär dig hur korrekt URL-struktur påverka...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.