AI-synlighetscenter för spetskompetens
Lär dig vad ett AI-synlighetscenter för spetskompetens är, dess nyckelansvar, övervakningsfunktioner och hur det möjliggör för organisationer att upprätthålla t...
7 min läsning

Cohere är ett AI-företag med fokus på företag som utvecklar Command-familjen av stora språkmodeller och driver en webbcrawler för att samla in träningsdata. Plattformen erbjuder säkra, anpassningsbara AI-lösningar för företag, inklusive textgenerering, semantisk sökning och retrieval-augmented generation. Cohere’s teknik driver AI-agenter, arbetsflödesautomation och innehållsskapande i stor skala över flera branscher.
Cohere är ett AI-företag med fokus på företag som utvecklar Command-familjen av stora språkmodeller och driver en webbcrawler för att samla in träningsdata. Plattformen erbjuder säkra, anpassningsbara AI-lösningar för företag, inklusive textgenerering, semantisk sökning och retrieval-augmented generation. Cohere's teknik driver AI-agenter, arbetsflödesautomation och innehållsskapande i stor skala över flera branscher.
Cohere är ett AI-företag med företagsfokus som specialiserar sig på att utveckla kraftfulla språkmodeller och AI-lösningar utformade specifikt för affärsapplikationer. Företaget grundades med målet att göra avancerad AI tillgänglig och säker för företag och har positionerat sig som ledande inom leverans av anpassningsbar, produktionsklar AI-teknik med särskild prioritet på datasäkerhet och kontroll för organisationer. Cohere’s kärnerbjudande är Command-familjen av språkmodeller, som är konstruerade för att hantera komplexa affärsarbetsflöden såsom innehållsgenerering, retrieval-augmented generation (RAG), verktygsanvändning och agentbaserade AI-applikationer. Till skillnad från konsumentinriktade AI-plattformar betonar Cohere säkerhet på företagsnivå, privata driftsalternativ och möjligheten att anpassa modeller med företagets egna data. Företaget betjänar en mängd olika branscher, inklusive finansiella tjänster, sjukvård, teknik, tillverkning och offentlig sektor, med välkända kunder såsom Oracle, Fujitsu, Notion, Dell Technologies, RBC, SAP och Salesforce.
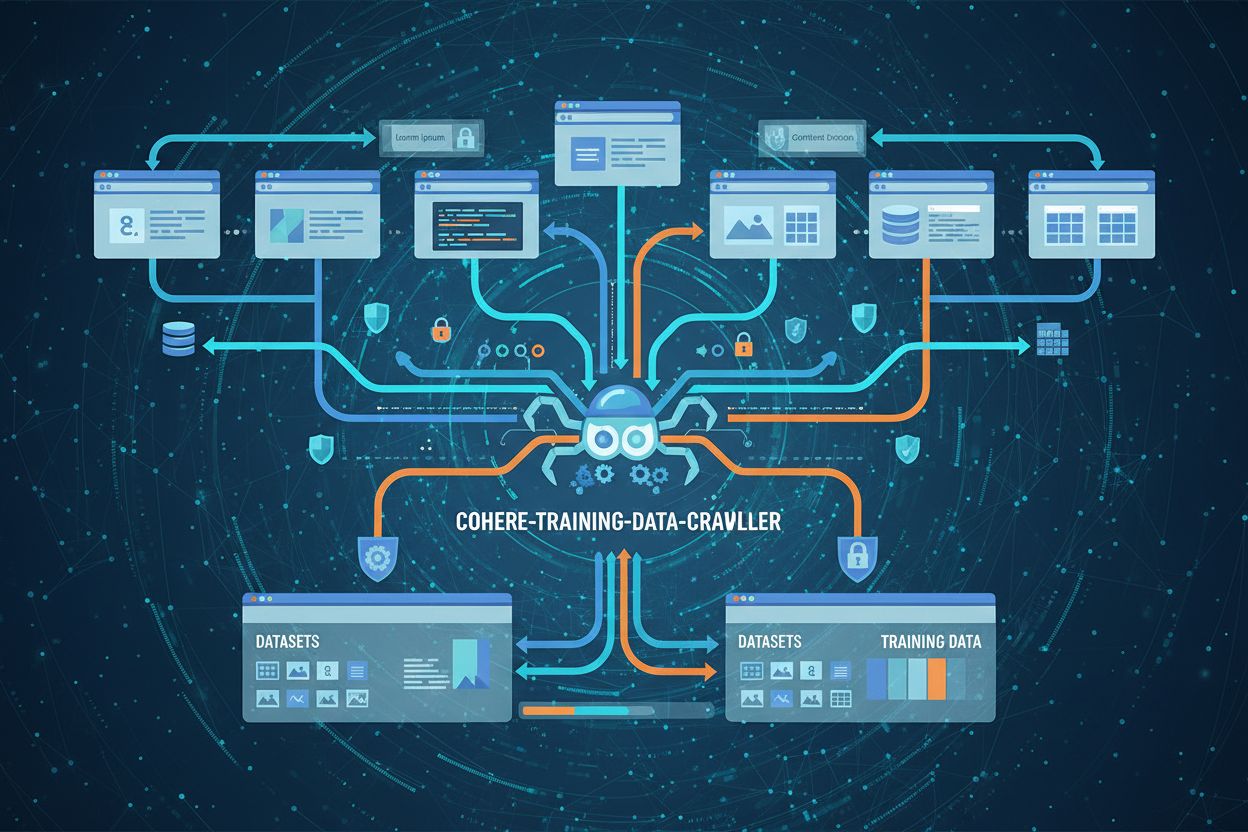
cohere-training-data-crawler är en webbcrawler som drivs av Cohere för att systematiskt ladda ner och samla in publikt tillgängligt innehåll från webbplatser för att träna dess stora språkmodeller. Till skillnad från traditionella sökmotorers crawlers, som indexerar innehåll för att hjälpa användare att hitta information via sökresultat, riktar Cohere’s crawler särskilt in sig på innehåll för maskininlärningsändamål, och laddar ner hela sidor och dokument för att bygga träningsdatamängder. Denna skillnad är avgörande: sökmotorers crawlers (som Googlebot) skapar index för återhämtning, medan AI-datainsamlare som cohere-training-data-crawler samlar in rådata för att förbättra modellernas förmågor. Crawlern arbetar med mindre transparens än sökmotorer när det gäller urvalskriterier, crawlingfrekvens och prioriteringar för datanvändning. Webbplatsägare kan blockera crawlern via robots.txt-konfiguration genom att lägga till regeln “User-agent: cohere-training-data-crawler” följt av “Disallow: /”, även om effektiviteten varierar beroende på implementation.
Viktiga egenskaper för cohere-training-data-crawler:
Command-familjen representerar Cohere’s flaggskeppsserie av generativa språkmodeller, var och en optimerad för specifika företagsanvändningsområden och prestandakrav. Dessa modeller är instruktionsföljande konversationsmodeller som är mycket skickliga på att förstå komplexa affärsuppgifter och generera text av hög kvalitet. Familjen innehåller flera varianter utformade för att balansera prestanda, hastighet och kostnadseffektivitet, vilket gör det möjligt för organisationer att välja den modell som bäst passar deras behov. Command-modellerna stödjer avancerade funktioner inklusive verktygsanvändning (som gör det möjligt för AI-agenter att interagera med externa system), retrieval-augmented generation (RAG) för att grunda svar i företagets egna data, flerspråkig bearbetning på 23 språk och agentbaserad AI för autonom arbetsflödesautomation. Den senaste varianten, Command A, är Cohere’s mest kraftfulla modell hittills, med 256K kontextlängd, kräver endast två GPU:er för drift och levererar 150% högre genomströmning jämfört med tidigare versioner.
| Modellnamn | Lansering | Nyckelfunktioner | Kontextlängd | Bäst för |
|---|---|---|---|---|
| Command A | 2025 | Verktygsanvändning, agenter, RAG, flerspråk, resonemang | 256K | Komplexa företagsarbetsflöden, agentbaserad AI |
| Command R7B | 2024 | RAG, verktygsanvändning, agenter, resonemang | 128K | Snabba, effektiva företagsapplikationer |
| Command R+ | 2024 | Avancerad RAG, flerstegsverktygsanvändning | 128K | Avancerad sökning och resonemangsuppgifter |
| Command R | 2024 | Konversationsbaserad, språk, kodning | 128K | Allmänna företagsapplikationer |
| Aya Expanse | 2024 | Flerspråkig (23 språk) | 128K | Globala företag, icke-engelskt innehåll |

Cohere’s Command-modeller driver olika företagsapplikationer över flera branscher och gör det möjligt för organisationer att automatisera komplexa arbetsflöden och öka produktiviteten i stor skala. Inom finansiella tjänster används Command-modeller av institutioner för automatiserad rapportgenerering, finansiell analys, kundkommunikation och regelefterlevnad, där bland annat RBC och andra storbanker använder teknologin för att skapa innehåll i stora volymer. Hälso- och sjukvårdsorganisationer använder Cohere’s modeller för medicinsk dokumenthantering, frågesystem för patienter, generering av kliniska anteckningar och analys av forskningsartiklar, där förmågan att hantera specialiserad terminologi och bibehålla noggrannhet är avgörande. Teknikföretag använder Command för kodgenerering, dokumentationsskapande, API-integration och utvecklingsverktyg, där Notion har integrerat Cohere’s funktioner i sin plattform. Tillverknings- och logistiksektorn drar nytta av arbetsflödesautomation, optimering av leveranskedjor och generering av operativ dokumentation. Fujitsu, en stor teknikjätte, samarbetade med Cohere för att erbjuda säkra företags-LLM:er till företag globalt, med fokus på säkerhet och anpassning inom AI för företag. North-plattformen, som drivs av Command-modeller, representerar Cohere’s integrerade lösning för arbetsplatsproduktivitet och kombinerar AI-agenter, intelligent sökning och generativa funktioner i ett och samma system anpassat för företag.
Driften av cohere-training-data-crawler väcker viktiga frågor för webbplatsägare, innehållsskapare och organisationer som är oroade över dataanvändning och attribution. Även om crawlern riktar in sig på publikt tillgängligt innehåll, skiljer sig insamlingen av dessa data för träning av AI-modeller fundamentalt från traditionell webbindexering, eftersom innehållet blir en del av proprietära träningsdatamängder med begränsad insyn i hur det kommer att användas eller krediteras. Innehållsskapare kan ha legitima farhågor om att deras arbete används för att träna kommersiella AI-system utan uttryckligt tillstånd eller ersättning, särskilt för kreativt, journalistiskt eller specialiserat professionellt innehåll. De etiska konsekvenserna sträcker sig bortom enskilda webbplatser till bredare frågor om insamling av träningsdata för AI, attribution och innehållsskaparnas rättigheter i en AI-driven ekonomi.
Praktiska överväganden för hantering av cohere-training-data-crawler:
Cohere särskiljer sig från stora AI-konkurrenter som OpenAI, Google och Anthropic genom sitt tydliga fokus på företagens behov, säkerhet och anpassningsbarhet. Medan OpenAI’s ChatGPT och Google’s Gemini riktar sig till konsument- och allmänmarknaden har Cohere strategiskt positionerat sig som plattformen för företags-AI och erbjuder funktioner som stora organisationer kräver: privata implementationer i dedikerade virtuella privata moln (VPC), on-premises-installation för luftgapade miljöer och möjligheten att finjustera modeller på egna data utan att exponera känslig information för tredje part. Cohere’s flerspråkiga kapacitet via Aya-familjen av modeller, med stöd för 23 språk, ger betydande fördelar för globala företag som verkar över flera regioner och språk. Företagets fokus på verktygsanvändning och agentbaserad AI möjliggör avancerad arbetsflödesautomation som går långt utöver enkel textgenerering, och låter AI-system interagera med affärsapplikationer, databaser och externa API:er. Implementeringsflexibilitet över flera plattformar – inklusive Amazon Bedrock, Azure AI Foundry, Oracle GenAI Service och SageMaker – säkerställer att företag kan integrera Cohere-modeller i sina befintliga tekniska miljöer utan inlåsning till en leverantör. Kombinationen av säkerhetsfokuserad arkitektur, anpassningsmöjligheter, flerspråkigt stöd och tillförlitlighet på företagsnivå gör Cohere till det föredragna valet för organisationer som prioriterar dataskydd, regelefterlevnad och operativ kontroll framför konsumentinriktade AI-funktioner.
Cohere är ett AI-företag med fokus på företag som utvecklar stora språkmodeller och AI-lösningar för verksamheter. Företaget erbjuder Command-familjen av språkmodeller, som driver applikationer som AI-agenter, innehållsgenerering och retrieval-augmented generation (RAG). Cohere driver också en webbcrawler vid namn cohere-training-data-crawler som samlar in publikt tillgängligt innehåll för att träna dess AI-modeller.
Till skillnad från sökmotorers crawlers som indexerar innehåll för att kunna visas i sökresultat, laddar cohere-training-data-crawler ner innehåll specifikt för träning av maskininlärningsmodeller. Sökmotorers crawlers hjälper användare att hitta information, medan Cohere's crawler samlar in data för att förbättra AI-modellers kapacitet. Crawlern arbetar med mindre transparens kring val av webbplatser och frekvens jämfört med traditionella sökmotorer.
Command-familjen inkluderar flera språkmodeller som Command A, Command R och Command R+, var och en optimerad för olika användningsområden. Dessa modeller är särskilt bra på verktygsanvändning, agenter, retrieval-augmented generation (RAG) och flerspråkiga uppgifter. Command A är Cohere's senaste och mest kraftfulla modell, med stöd för 256K kontextlängd och kan hantera komplex problemlösning, kodgenerering och företagsarbetsflöden.
Du kan blockera cohere-training-data-crawler genom att lägga till en robots.txt-regel: User-agent: cohere-training-data-crawler följt av Disallow: /. De flesta seriösa företag följer dessa direktiv, men du kan behöva servernivå-begränsningar för total blockering. Verktyg som Dark Visitors erbjuder Agent Analytics för att övervaka crawlerbesök och verifiera om dina robots.txt-regler följs.
Cohere används inom flera branscher inklusive finansiella tjänster (dataanalys och rapportering), sjukvård (dokumenthantering och frågor/svar), teknik (kodgenerering och automation), tillverkning (arbetsflödesautomation) och offentlig sektor (informationssökning). Kunder som Oracle, Fujitsu, Notion och Salesforce använder Cohere för innehållsgenerering, sökning, automatiserad kundservice och företagsinriktade AI-applikationer.
Cohere särskiljer sig genom sitt företagsfokus och erbjuder privata implementationer, anpassningsmöjligheter och starka säkerhetsfunktioner. Medan OpenAI och Google fokuserar på konsumentinriktad AI, specialiserar sig Cohere på företagslösningar med flexibla implementeringsalternativ. Cohere stödjer 23 språk med Aya Expanse och lägger vikt vid verktygsanvändning och agentkapacitet, vilket gör det särskilt starkt för företagsautomation och flerspråkiga applikationer.
Crawlern samlar in publikt tillgängligt innehåll för att träna AI-modeller, vilket väcker frågor om attribution och hur ditt innehåll kan användas i AI-genererade resultat. Även om innehållet är publikt, kan du vilja blockera crawlern om du är oroad över ersättning, attribution eller hur ditt kreativa arbete visas i AI-system. Cohere's transparens kring crawlerns syfte hjälper webbplatsägare att fatta informerade beslut om blockering.
Ja, Cohere erbjuder API-åtkomst till sina modeller via olika plattformar, inklusive deras egna dashboard, Amazon Bedrock, Amazon SageMaker, Microsoft Azure och Oracle GenAI Service. Företag kan integrera Command-modeller för textgenerering, Embed-modeller för semantisk sökning, och Rerank-modeller för förbättring av resultat. Cohere erbjuder även privata implementationer och anpassningsmöjligheter för företagskunder med särskilda krav på säkerhet eller prestanda.
Följ omnämnanden av ditt varumärke på AI-plattformar som ChatGPT, Perplexity och Google AI Overviews. Få insikter om hur AI-system citerar och hänvisar till ditt innehåll.
Lär dig vad ett AI-synlighetscenter för spetskompetens är, dess nyckelansvar, övervakningsfunktioner och hur det möjliggör för organisationer att upprätthålla t...

Strategi för företags-AI-sökning: integration, styrning, ROI-mått. Lär dig hur stora organisationer implementerar AI-sökningsplattformar för ChatGPT, Perplexity...
Lär dig vad AI-infödda varumärken är, hur de skiljer sig från traditionella företag och varför AI-synlighetsövervakning är avgörande för deras framgång i en tid...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.