
Vad är Crawl Budget för AI? Förstå AI-botars Resursallokering
Lär dig vad crawl budget för AI innebär, hur det skiljer sig från traditionella sökmotorers crawl budget och varför det är viktigt för ditt varumärkes synlighet...
11 min läsning

Tekniker för att säkerställa att AI-crawlers effektivt får tillgång till och indexerar det viktigaste innehållet på en webbplats inom deras crawlgränser. Crawl budget-optimering hanterar balansen mellan crawlkapacitet (serverresurser) och crawlefterfrågan (bot-förfrågningar) för att maximera synlighet i AI-genererade svar samtidigt som driftskostnader och serverbelastning kontrolleras.
Tekniker för att säkerställa att AI-crawlers effektivt får tillgång till och indexerar det viktigaste innehållet på en webbplats inom deras crawlgränser. Crawl budget-optimering hanterar balansen mellan crawlkapacitet (serverresurser) och crawlefterfrågan (bot-förfrågningar) för att maximera synlighet i AI-genererade svar samtidigt som driftskostnader och serverbelastning kontrolleras.
Crawl budget avser mängden resurser—mätt i förfrågningar och bandbredd—som sökmotorer och AI-botar tilldelar för att crawla din webbplats. Traditionellt gällde detta koncept främst Googles crawlingbeteende, men framväxten av AI-drivna botar har fundamentalt förändrat hur organisationer måste tänka kring hanteringen av crawl budget. Crawl budget-ekvationen består av två kritiska variabler: crawlkapacitet (det maximala antalet sidor en bot kan crawla) och crawlefterfrågan (det faktiska antalet sidor boten vill crawla). I AI-eran har denna dynamik blivit exponentiellt mer komplex, eftersom botar som GPTBot (OpenAI), Perplexity Bot och ClaudeBot (Anthropic) nu konkurrerar om serverresurser tillsammans med traditionella sökmotorcrawlers. Dessa AI-botar arbetar med andra prioriteringar och mönster än Googlebot, ofta med avsevärt högre bandbreddsförbrukning och annorlunda indexeringsmål, vilket gör crawl budget-optimering oumbärligt för att behålla webbplatsens prestanda och kontrollera driftskostnader.
AI-crawlers skiljer sig fundamentalt från traditionella sökmotorbots i sina crawlingmönster, frekvens och resursförbrukning. Medan Googlebot respekterar crawl budget-gränser och tillämpar avancerade begränsningsmekanismer, uppvisar AI-botar ofta mer aggressiva crawlingbeteenden, ibland med upprepade förfrågningar om samma innehåll och mindre hänsyn till serverbelastningssignaler. Forskning visar att OpenAI:s GPTBot kan förbruka 12–15 gånger mer bandbredd än Googles crawler på vissa webbplatser, särskilt de med stora innehållsbibliotek eller ofta uppdaterade sidor. Detta aggressiva tillvägagångssätt beror på AI-träningskrav—dessa botar behöver kontinuerligt läsa in färskt innehåll för att förbättra modellernas prestanda, vilket ger en fundamentalt annorlunda crawlingfilosofi än sökmotorer som fokuserar på indexering för återvinning. Serverpåverkan är betydande: organisationer rapporterar markanta ökningar i bandbreddskostnader, CPU-användning och serverbelastning direkt orsakad av AI-bot-trafik. Dessutom kan den samlade effekten av flera AI-botar som crawlar samtidigt försämra användarupplevelsen, sakta ner sidladdningstider och öka hostingkostnader, vilket gör skillnaden mellan traditionella och AI-crawlers till en viktig affärsfråga snarare än en teknisk kuriositet.
| Egenskap | Traditionella crawlers (Googlebot) | AI-crawlers (GPTBot, ClaudeBot) |
|---|---|---|
| Crawlfrekvens | Anpassningsbar, respekterar crawl budget | Aggressiv, kontinuerlig |
| Bandbreddsförbrukning | Måttlig, optimerad | Hög, resurskrävande |
| Respekt för Robots.txt | Strikt efterlevnad | Varierande efterlevnad |
| Cachingbeteende | Avancerad caching | Frekventa omförfrågningar |
| User-Agent-identifikation | Tydlig, konsekvent | Ibland fördold |
| Affärsmål | Sökindexering | Modellträning/datainsamling |
| Kostnadspåverkan | Minimal | Betydande (12–15x högre) |
Att förstå crawl budget kräver att du behärskar dess två grundläggande komponenter: crawlkapacitet och crawlefterfrågan. Crawlkapacitet representerar det maximala antalet URL:er din server kan hantera att bli crawlad inom en given tidsram, bestämt av flera relaterade faktorer. Denna kapacitet påverkas av:
Crawlefterfrågan å andra sidan representerar hur många sidor botar faktiskt vill crawla, drivet av innehållskaraktäristika och botprioriteringar. Faktorer som påverkar crawlefterfrågan:
Optimeringsutmaningen uppstår när crawlefterfrågan överstiger crawlkapaciteten—botar måste välja vilka sidor som ska crawlas och kan missa viktiga uppdateringar. Omvänt, när crawlkapaciteten vida överstiger efterfrågan slösar du serverresurser. Målet är att uppnå crawl-effektivitet: maximera crawling av viktiga sidor och minimera slöseri på lågkvalitativt innehåll. Denna balans blir alltmer komplex i AI-eran, där flera bottar med olika prioriteringar konkurrerar om samma serverresurser, vilket kräver sofistikerade strategier för att fördela crawl budget effektivt mellan alla intressenter.
Mätning av crawl budget-prestanda inleds med Google Search Console, som tillhandahåller crawlstatistik under avsnittet “Inställningar”, där du ser dagliga crawl-förfrågningar, nedladdade byte och svarstider. För att räkna ut din crawl-effektivitetskvot, dela antalet lyckade crawls (HTTP 200-svar) med totala crawl-förfrågningar; sunda webbplatser landar oftast på 85–95 % effektivitet. En formel för grundläggande crawl-effektivitet är: (Lyckade crawls ÷ Totala crawl-förfrågningar) × 100 = Crawl-effektivitet %. Utöver Googles data krävs praktisk övervakning, bland annat:
För specifik övervakning av AI-crawlers erbjuder verktyg som AmICited.com specialiserad spårning av GPTBot, ClaudeBot och Perplexity Bot, med insikter om vilka sidor dessa botar prioriterar och hur ofta de återkommer. Att implementera egna varningar för ovanliga crawl-toppar—särskilt från AI-botar—möjliggör snabb respons vid oväntad resursförbrukning. Nyckelmåttet att följa är crawl-kostnad per sida: dela totala serverresurser använda för crawls med antalet unika crawlade sidor för att se om du använder crawl budget effektivt eller slösar på lågkvalitativa sidor.
Optimering av crawl budget för AI-botar kräver en flernivåstrategi som kombinerar teknisk implementering och strategiskt beslutsfattande. De viktigaste optimeringstaktikerna inkluderar:
Vilken taktik som används beror på din affärsmodell och innehållsstrategi. E-handelssajter kan blockera AI-botar från produktsidor för att förhindra att konkurrenter tränar på deras data, medan innehållspublicister kan tillåta crawling för att synas i AI-genererade svar. För webbplatser som upplever verklig serverbelastning från AI-bot-trafik är user-agent-specifik blockering i robots.txt den mest direkta lösningen: User-agent: GPTBot följt av Disallow: / stoppar OpenAIs crawler helt från åtkomst till din webbplats. Detta innebär dock att du förlorar potentiell synlighet i ChatGPT:s svar och andra AI-tjänster. En mer nyanserad strategi är selektiv blockering: tillåt AI-botar åtkomst till publikt innehåll men blockera dem från känsliga områden, arkiv eller duplicerat innehåll som slösar crawl budget utan värde för dig eller boten.
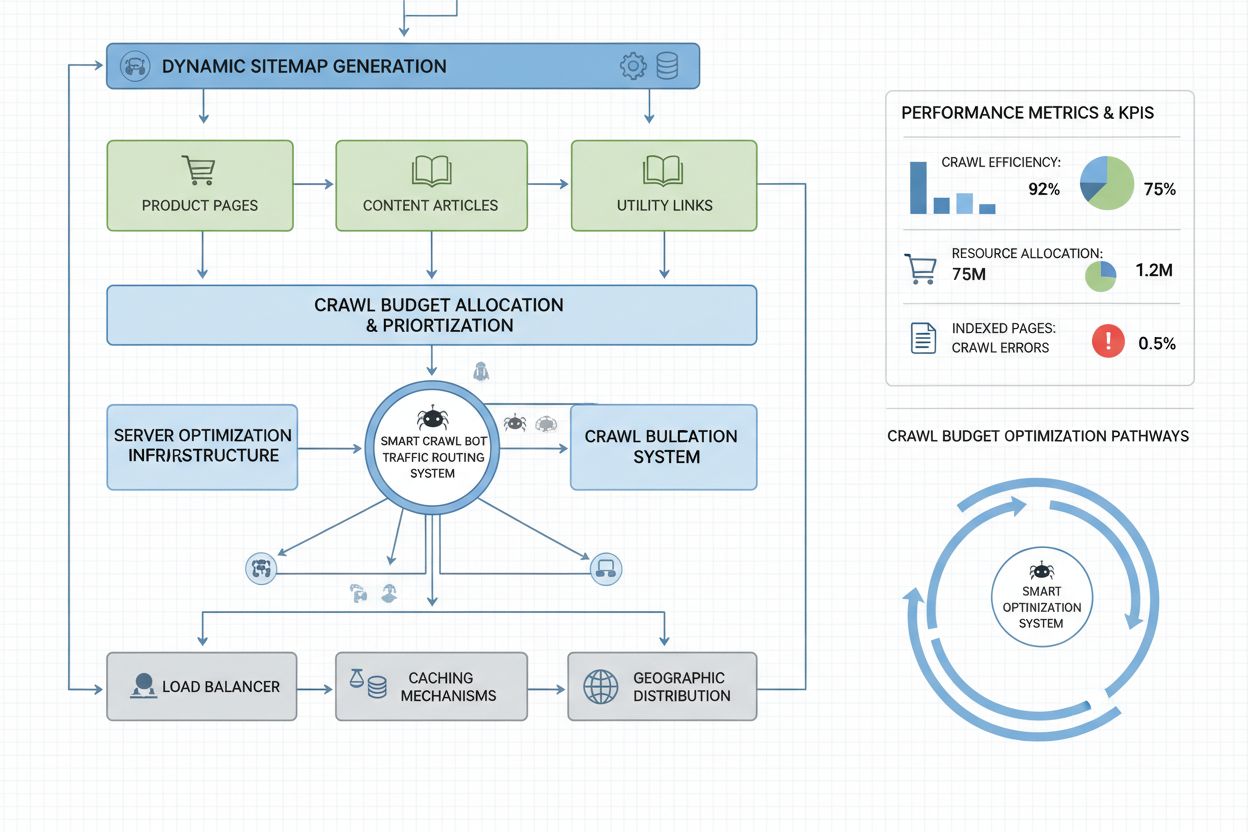
Storskaliga webbplatser med miljontals sidor kräver avancerade strategier för crawl budget-optimering utöver grundläggande robots.txt-konfiguration. Dynamiska sitemaps är en avgörande förbättring, där sitemaps genereras i realtid utifrån innehållets aktualitet, viktpoäng och crawlhistorik. Istället för statiska XML-sitemaps som listar alla sidor, prioriterar dynamiska sitemaps nyligen uppdaterade sidor, sidor med hög trafik och sidor med konverteringspotential—så att botarna fokuserar crawl budget på det innehåll som är viktigast. URL-segmentering delar upp webbplatsen i logiska crawl-zoner, var och en med skräddarsydda optimeringsstrategier—nyhetsavdelningar kan använda aggressiva sitemap-uppdateringar för att säkerställa omedelbar crawling av dagligt innehåll, medan evergreen-innehåll uppdateras mer sällan.
Serveroptimering inkluderar crawlkänslig caching som serverar cacheat innehåll till botar men färskt till användare, vilket minskar serverbelastning från upprepade bot-förfrågningar. Content delivery networks (CDN) med botspecifik routing kan isolera bottrafik från användartrafik och förhindra att crawlers tar bandbredd från riktiga besökare. Rate limiting per user-agent gör det möjligt att strypa AI-bot-förfrågningar men bibehålla normal hastighet för Googlebot och användare. För verkligt storskaliga lösningar möjliggör distribuerad crawl budget-hantering över flera serverregioner att ingen enskild punkt blir överbelastad och gör det möjligt att lastbalansera bottrafik geografiskt. Maskininlärningsbaserad crawl-prognos analyserar historiska crawlingmönster för att förutsäga vilka sidor botar kommer att begära härnäst, så att du proaktivt kan optimera prestanda och caching för dessa sidor. Dessa strategier på företagsnivå gör crawl budget till en kontrollerad resurs, vilket gör att stora organisationer kan servera miljarder sidor och samtidigt upprätthålla optimal prestanda för både botar och riktiga användare.
Beslutet att blockera eller tillåta AI-crawlers är ett fundamentalt affärsstrategiskt val med stor påverkan på synlighet, konkurrenspositionering och driftskostnader. Att tillåta AI-crawlers ger betydande fördelar: ditt innehåll kan inkluderas i AI-genererade svar, vilket potentiellt driver trafik från ChatGPT, Claude, Perplexity och andra AI-appar; ditt varumärke får synlighet i en ny kanal; och du drar nytta av SEO-signaler från att bli citerad av AI-system. Men dessa fördelar innebär kostnader: ökad serverbelastning och bandbreddsförbrukning, risk att konkurrenternas AI-modeller tränas på ditt innehåll och minskad kontroll över hur din information presenteras och tillskrivs i AI-svar.
Att blockera AI-botar eliminerar dessa kostnader men offrar också synlighetsfördelar och kan innebära att du förlorar marknadsandelar till konkurrenter som tillåter crawling. Den optimala strategin avgörs av din affärsmodell: innehållspublicister och nyhetsorganisationer gynnas ofta av att tillåta crawling för att spridas genom AI-sammanfattningar; SaaS-företag och e-handelssajter kan blockera botar för att förhindra att konkurrenter tränar modeller på deras produktinformation; utbildningsinstitutioner och forskningsorganisationer tillåter oftast crawling för maximal spridning av kunskap. En hybridstrategi erbjuder en medelväg: tillåt crawling av publikt innehåll men blockera åtkomst till känsliga områden, användargenererat innehåll eller proprietär information. Detta maximerar synlighetsfördelarna och skyddar samtidigt värdefulla tillgångar. Genom att övervaka AmICited.com och liknande verktyg kan du dessutom se om ditt innehåll verkligen citeras av AI-system—om din webbplats inte dyker upp i AI-svar trots att du tillåter crawling, blir blockering mer attraktivt eftersom du bär crawl-kostnaden utan att få synlighet.
Effektiv crawl budget-hantering kräver specialiserade verktyg som ger insyn i botbeteende och möjliggör databaserade optimeringsbeslut. Conductor och Sitebulb erbjuder crawl-analys på företagsnivå, simulerar hur sökmotorer crawlar din webbplats och identifierar ineffektiv crawling, slöseri på felaktiga sidor och möjligheter att förbättra crawl budget-fördelning. Cloudflare erbjuder bot-hantering på nätverksnivå, så att du kan styra exakt vilka botar som får åtkomst och införa rate limiting för AI-crawlers. För övervakning av AI-botar är AmICited.com det mest heltäckande verktyget, med detaljerad analys av GPTBot, ClaudeBot, Perplexity Bot och andra AI-crawlers—du ser vilka sidor de besöker, hur ofta de återkommer och om ditt innehåll syns i AI-genererade svar.
Serverlogganalys är fortfarande grundläggande för crawl budget-optimering—verktyg som Splunk, Datadog eller öppen källkod som ELK Stack gör att du kan analysera råa accessloggar och segmentera trafik per user-agent, identifiera vilka botar som förbrukar mest resurser och vilka sidor som får mest crawl-uppmärksamhet. Skräddarsydda dashboards som spårar crawlingtrender över tid visar om optimeringsinsatser fungerar och om nya typer av botar dyker upp. Google Search Console fortsätter ge grundläggande data om Googles crawlingbeteende, medan Bing Webmaster Tools ger liknande insikter för Microsofts crawler. De mest avancerade organisationerna implementerar multiverktygsstrategier där Google Search Console används för traditionell crawl-data, AmICited.com för AI-botövervakning, serverlogganalys för full bot-synlighet och specialverktyg som Conductor för simulation och effektivitetsanalys. Detta lager-på-lager-angreppssätt ger komplett insyn i hur alla bottyper interagerar med din webbplats och möjliggör optimeringsbeslut baserade på data, inte gissningar. Regelbunden övervakning—helst veckovisa granskningar av crawl-mått—gör att du snabbt kan identifiera problem som oväntade crawl-toppar, ökade felfrekvenser eller nya aggressiva botar, så att du kan agera innan crawl budget-problem påverkar prestanda eller kostnader.
AI-botar som GPTBot och ClaudeBot har andra prioriteringar än Googlebot. Medan Googlebot respekterar crawl budget-gränser och tillämpar avancerad begränsning, uppvisar AI-botar ofta mer aggressiva crawlingmönster och förbrukar 12–15 gånger mer bandbredd. AI-botar prioriterar kontinuerlig innehållsinläsning för modellträning snarare än sökindexering, vilket gör deras crawlbeteende fundamentalt annorlunda och kräver särskilda optimeringsstrategier.
Forskning visar att OpenAIs GPTBot kan förbruka 12–15 gånger mer bandbredd än Googles crawler på vissa webbplatser, särskilt de med stora innehållsbibliotek. Den exakta förbrukningen beror på din webbplats storlek, hur ofta innehåll uppdateras och hur många AI-botar som crawlar samtidigt. Flera AI-botar som crawlar på en gång kan kraftigt öka serverbelastning och hostingkostnader.
Ja, du kan blockera specifika AI-crawlers med robots.txt utan att påverka traditionell SEO. Att blockera AI-crawlers innebär dock att du avstår från synlighet i AI-genererade svar från ChatGPT, Claude, Perplexity och andra AI-applikationer. Beslutet beror på din affärsmodell—innehållspublicister gynnas ofta av att tillåta crawling, medan e-handelsplatser kan blockera för att förhindra träning av konkurrenter.
Dålig crawl budget-hantering kan leda till att viktiga sidor inte crawlas eller indexeras, långsammare indexering av nytt innehåll, ökad serverbelastning och bandbreddskostnader, försämrad användarupplevelse från bot-trafik samt missade möjligheter till synlighet i både traditionell sökning och AI-genererade svar. Stora sajter med miljontals sidor är mest utsatta för dessa effekter.
För optimala resultat, övervaka crawl budget-mått varje vecka och dagligen under större innehållslanseringar eller vid oväntade trafiktoppar. Använd Google Search Console för traditionell crawl-data, AmICited.com för övervakning av AI-crawlers och serverloggar för fullständig bot-synlighet. Regelbunden övervakning gör att du snabbt kan identifiera problem innan de påverkar webbplatsens prestanda.
Robots.txt har varierande effektivitet med AI-botar. Googlebot respekterar robots.txt-direktiv strikt, men AI-botar har inkonsekvent efterlevnad—vissa följer reglerna medan andra ignorerar dem. För mer tillförlitlig kontroll, implementera blockering per user-agent, begränsa begäranden på servernivå eller använd CDN-baserade bot-hanteringsverktyg som Cloudflare för mer detaljerad kontroll.
Crawl budget påverkar direkt AI-synlighet eftersom AI-botar inte kan citera eller referera till innehåll de inte har crawlat. Om dina viktiga sidor inte crawlas på grund av budgetbegränsningar kommer de inte att synas i AI-genererade svar. Optimering av crawl budget säkerställer att ditt bästa innehåll upptäcks av AI-botar och ökar chansen att bli citerad i svar från ChatGPT, Claude och Perplexity.
Prioritera sidor med dynamiska sitemaps som lyfter fram nyligen uppdaterat innehåll, sidor med hög trafik och sidor med konverteringspotential. Använd robots.txt för att blockera lågkvalitativa sidor som arkiv och dubbletter. Implementera rena URL-strukturer och strategisk internlänkning för att styra botar mot viktigt innehåll. Övervaka vilka sidor AI-botar faktiskt crawlar med verktyg som AmICited.com för att justera din strategi.
Spåra hur AI-botar crawlar din webbplats och optimera din synlighet i AI-genererade svar med AmICited.coms heltäckande plattform för övervakning av AI-crawlers.
Lär dig vad crawl budget för AI innebär, hur det skiljer sig från traditionella sökmotorers crawl budget och varför det är viktigt för ditt varumärkes synlighet...
Crawl budget är antalet sidor som sökmotorer genomsöker på din webbplats inom en tidsram. Lär dig hur du optimerar crawl budget för bättre indexering och SEO-pr...

Crawlbarhet är sökmotorers förmåga att komma åt och navigera på webbsidor. Lär dig hur crawlers fungerar, vad som blockerar dem och hur du optimerar din webbpla...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.