Crawl Rate
Crawl rate är hastigheten med vilken sökmotorer genomsöker din webbplats. Lär dig hur det påverkar indexering, SEO-prestanda och hur du optimerar det för bättre...
9 min läsning
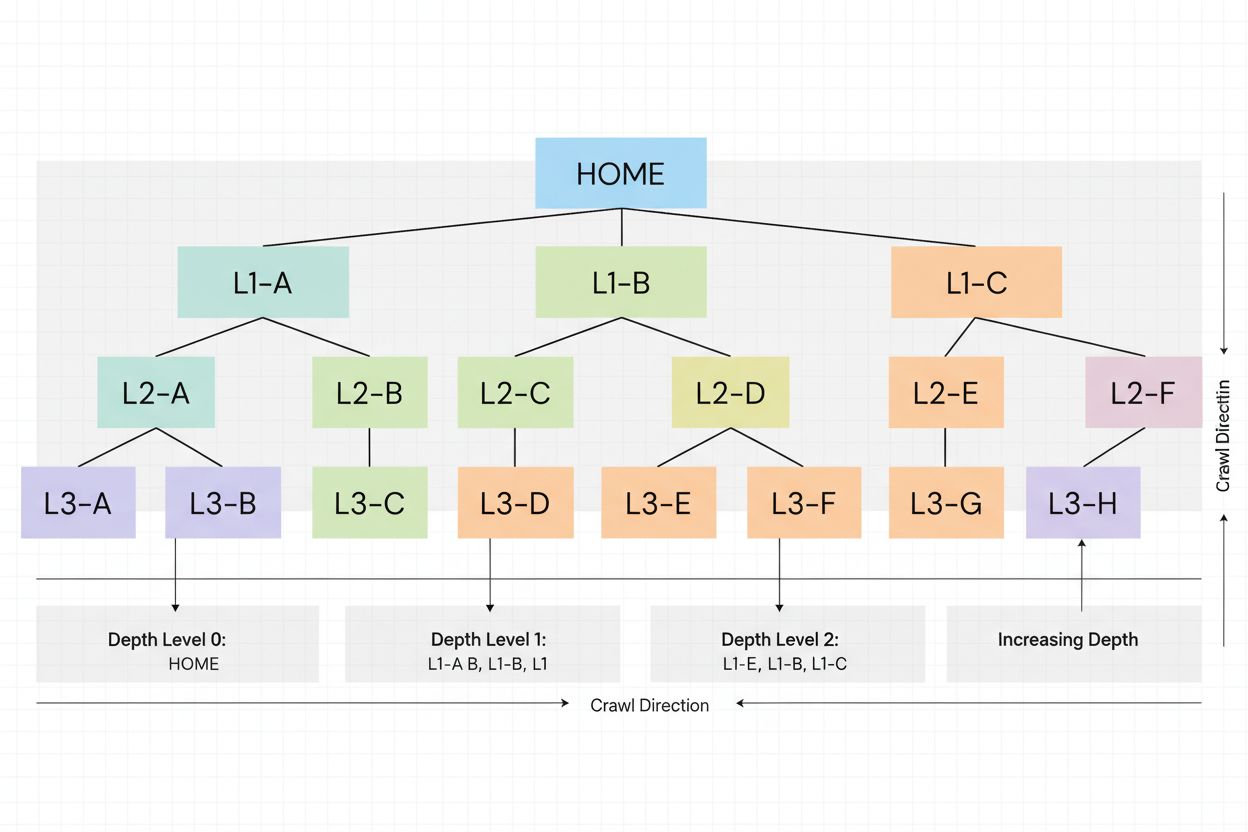
Crawl-djup avser hur långt ner i en webbplats hierarkiska struktur sökmotorernas spindlar kan nå under en enskild genomsökningssession. Det mäter antalet klick eller steg som krävs från startsidan för att nå en viss sida, vilket direkt påverkar vilka sidor som indexeras och hur ofta de genomsöks inom webbplatsens tilldelade crawl-budget.
Crawl-djup avser hur långt ner i en webbplats hierarkiska struktur sökmotorernas spindlar kan nå under en enskild genomsökningssession. Det mäter antalet klick eller steg som krävs från startsidan för att nå en viss sida, vilket direkt påverkar vilka sidor som indexeras och hur ofta de genomsöks inom webbplatsens tilldelade crawl-budget.
Crawl-djup är ett grundläggande tekniskt SEO-begrepp som avser hur långt ner i en webbplats hierarkiska struktur sökmotorernas spindlar kan navigera under en enskild genomsökningssession. Mer specifikt mäter det antalet klick eller steg som krävs från startsidan för att nå en viss sida inom webbplatsens interna länkstruktur. En webbplats med högt crawl-djup innebär att sökmotorernas botar kan komma åt och indexera många sidor på hela webbplatsen, medan en webbplats med lågt crawl-djup indikerar att spindlar kanske inte når djupare sidor innan de har förbrukat sina tilldelade resurser. Detta är avgörande eftersom det direkt avgör vilka sidor som indexeras, hur ofta de genomsöks och slutligen deras synlighet i sökmotorernas resultatsidor (SERP:er).
Betydelsen av crawl-djup har blivit större de senaste åren på grund av den exponentiella ökningen av webbplatsinnehåll. Med Googles index som innehåller över 400 miljarder dokument och ökande mängder AI-genererat innehåll står sökmotorer inför oöverträffade begränsningar gällande crawl-resurser. Det innebär att webbplatser med dålig optimering av crawl-djup kan få sina viktiga sidor oindexerade eller genomsökta sällan, vilket kraftigt påverkar den organiska synligheten. Att förstå och optimera crawl-djup är därför avgörande för alla webbplatser som vill maximera sin synlighet i sökmotorer.
Begreppet crawl-djup härstammar från hur sökmotorernas spindlar (även kallade webspindlar eller botar) fungerar. När Googles Googlebot eller andra sökmotorbotar besöker en webbplats följer de en systematisk process: de börjar på startsidan och följer interna länkar för att upptäcka fler sidor. Spindeln tilldelar en begränsad mängd tid och resurser till varje webbplats, kallad crawl-budget. Denna budget bestäms av två faktorer: crawl-kapacitetsgräns (hur mycket spindeln kan hantera utan att överbelasta servern) och crawl-efterfrågan (hur viktig och ofta uppdaterad webbplatsen är). Ju djupare sidor är begravda i din webbplatsstruktur, desto mindre troligt är det att spindlarna når dem innan crawl-budgeten är förbrukad.
Historiskt sett var webbplatsstrukturer relativt enkla, där det mesta viktiga innehållet låg inom 2–3 klick från startsidan. Men i takt med att e-handelssajter, nyhetsportaler och innehållsrika webbplatser växte exponentiellt skapade många organisationer djupt nästlade strukturer med sidor på 5, 6 eller till och med 10+ nivåer djupa. Forskning från seoClarity och andra SEO-plattformar har visat att sidor på nivå 3 och djupare generellt presterar sämre i organiska sökresultat jämfört med sidor närmare startsidan. Denna prestandaskillnad beror på att spindlar prioriterar sidor närmare roten, och dessa sidor samlar även på sig mer länkstyrka (rankingkraft) genom intern länkning. Sambandet mellan crawl-djup och indexeringsgrad är särskilt tydligt på stora webbplatser med tusentals eller miljontals sidor, där crawl-budget blir en kritisk begränsande faktor.
Framväxten av AI-sökmotorer som Perplexity, ChatGPT och Google AI Overviews har lagt till ytterligare en dimension till optimering av crawl-djup. Dessa AI-system använder sina egna specialiserade spindlar (såsom PerplexityBot och GPTBot) som kan ha andra genomsökningsmönster och prioriteringar än traditionella sökmotorer. Den grundläggande principen är dock densamma: sidor som är lättillgängliga och väl integrerade i webbplatsens struktur har större chans att upptäckas, genomsökas och citeras som källor i AI-genererade svar. Det gör crawl-djup-optimering relevant inte bara för traditionell SEO, utan även för AI-synlighet och generative engine optimization (GEO).
| Begrepp | Definition | Perspektiv | Mätning | Påverkan på SEO |
|---|---|---|---|---|
| Crawl-djup | Hur långt ner i webbplatsens hierarki spindlar navigerar baserat på interna länkar och URL-struktur | Sökmotorbotens vy | Antal klick/steg från startsidan | Påverkar indexeringsfrekvens och täckning |
| Klickdjup | Antal användarklick som krävs för att nå en sida från startsidan via kortaste vägen | Användarens perspektiv | Faktiska klick som krävs | Påverkar användarupplevelse och navigation |
| Siddjup | Sidans position i webbplatsens hierarkiska struktur | Strukturell vy | URL-nivå | Påverkar fördelning av länkstyrka |
| Crawl-budget | Totala resurser (tid/bandbredd) tilldelade för att genomsöka en webbplats | Resursallokering | Sidor genomsökta per dag | Avgör hur många sidor som indexeras |
| Crawl-effektivitet | Hur effektivt spindlar navigerar och indexerar webbplatsens innehåll | Optimeringsvy | Sidor indexerade kontra använd crawl-budget | Maximerar indexering inom budgetgränser |
Att förstå hur crawl-djup fungerar kräver att man undersöker mekanismerna bakom hur sökmotorernas spindlar navigerar på webbplatser. När Googlebot eller en annan spindel besöker din webbplats börjar den på startsidan (djup 0) och följer interna länkar för att upptäcka fler sidor. Varje sida som är länkad från startsidan är på djup 1, sidor som länkas från dessa är på djup 2, och så vidare. Spindeln följer inte nödvändigtvis en linjär väg; istället upptäcker den flera sidor på varje nivå innan den går djupare. Spindelns resa begränsas dock av crawl-budgeten, som avgör hur många sidor den kan besöka under en viss tidsperiod.
Den tekniska relationen mellan crawl-djup och indexering styrs av flera faktorer. För det första spelar crawl-prioritering en avgörande roll — sökmotorer genomsöker inte alla sidor lika ofta. De prioriterar sidor baserat på upplevd vikt, aktualitet och relevans. Sidor med fler interna länkar, högre auktoritet och nyliga uppdateringar genomsöks oftare. För det andra påverkar URL-strukturen själv crawl-djupet. En sida på /kategori/underkategori/produkt/ har ett högre crawl-djup än en sida på /produkt/, även om båda är länkade från startsidan. För det tredje utgör omdirigeringskedjor och brutna länkar hinder som slösar crawl-budget. En omdirigeringskedja tvingar spindeln att följa flera omdirigeringar innan den når slutmålet, vilket förbrukar resurser som annars kunde ha använts för att genomsöka annat innehåll.
Den tekniska implementeringen av crawl-djup-optimering omfattar flera nyckelstrategier. Intern länkstruktur är avgörande — genom att strategiskt länka viktiga sidor från startsidan och sidor med hög auktoritet minskar du deras effektiva crawl-djup och ökar sannolikheten att de genomsöks ofta. XML-sitemaps ger spindlar en direkt karta över webbplatsens struktur, vilket gör att de kan upptäcka sidor effektivare utan att enbart förlita sig på länkföljning. Webbplatshastighet är också en kritisk faktor; snabbare sidor laddas snabbare, vilket gör att spindlar kan komma åt fler sidor inom sin tilldelade budget. Slutligen gör robots.txt och noindex-taggar att du kan styra vilka sidor spindlar ska prioritera, så att de inte slösar budget på lågkvalitativa sidor som dubbletter eller adminsidor.
De praktiska konsekvenserna av crawl-djup sträcker sig långt utanför tekniska SEO-mått — de påverkar direkt affärsresultat. För e-handelswebbplatser innebär dålig crawl-djup-optimering att produktsidor som är djupt begravda i kategorihierarkier kanske inte indexeras eller indexeras sällan. Det leder till minskad organisk synlighet, färre produktvisningar i sökresultaten och i slutändan förlorad försäljning. En studie från seoClarity visade att sidor med högre crawl-djup hade betydligt lägre indexeringsgrad, där sidor på nivå 4+ genomsöktes upp till 50 % mindre ofta än sidor på nivå 1–2. För stora återförsäljare med tusentals artiklar kan detta innebära förlorade intäkter på miljontals kronor.
För innehållstunga webbplatser som nyhetssidor, bloggar och kunskapsbanker påverkar crawl-djup-optimering direkt innehållets upptäckbarhet. Artiklar som publiceras djupt i kategoristrukturer kanske aldrig når Googles index, vilket innebär att de inte genererar någon organisk trafik oavsett kvalitet eller relevans. Detta är särskilt problematiskt för nyhetssajter där aktualitet är kritiskt — om nya artiklar inte genomsöks och indexeras snabbt missar de möjligheten att ranka för trendande ämnen. Publicister som optimerar crawl-djup genom att platta ut strukturen och förbättra intern länkning ser dramatiska ökningar i indexerade sidor och organisk trafik.
Sambandet mellan crawl-djup och fördelning av länkstyrka har stor affärsmässig betydelse. Länkstyrka (även kallat PageRank eller rankingkraft) flödar genom interna länkar från startsidan och utåt. Sidor närmare startsidan samlar mer länkstyrka, vilket gör dem mer benägna att ranka för konkurrensutsatta sökord. Genom att optimera crawl-djup och säkerställa att viktiga sidor finns inom 2–3 klick från startsidan kan företag koncentrera länkstyrka på sina mest värdefulla sidor — vanligtvis produktsidor, tjänstesidor eller kärninnehåll. Denna strategiska fördelning av länkstyrka kan dramatiskt förbättra rankingar för högt värderade sökord.
Dessutom påverkar crawl-djup-optimering crawl-budget-effektiviteten, vilket blir allt viktigare i takt med att webbplatser växer. Stora webbplatser med miljontals sidor har ofta svåra crawl-budget-begränsningar. Genom att optimera crawl-djup, ta bort dubblettinnehåll, laga brutna länkar och eliminera omdirigeringskedjor kan webbplatser se till att spindlar lägger sin budget på värdefullt, unikt innehåll istället för att slösa resurser på lågprioriterade sidor. Detta är särskilt avgörande för företagswebbplatser och stora e-handelsplattformar där hantering av crawl-budget kan innebära skillnaden mellan att få 80 % av sidorna indexerade jämfört med 40 %.
Framväxten av AI-sökmotorer och generativa AI-system har lagt till nya dimensioner till crawl-djup-optimering. ChatGPT, som drivs av OpenAI, använder GPTBot-spindeln för att upptäcka och indexera webbinnehåll. Perplexity, en ledande AI-sökmotor, använder PerplexityBot för att crawla webben efter källor. Google AI Overviews (tidigare SGE) använder Googles egna spindlar för att samla in information till AI-genererade sammanfattningar. Claude, Anthropic’s AI-assistent, crawlar också webbinnehåll för träning och hämtning. Var och en av dessa system har olika genomsökningsmönster, prioriteringar och resursbegränsningar jämfört med traditionella sökmotorer.
Den viktigaste insikten är att crawl-djup-principer gäller även för AI-sökmotorer. Sidor som är lättillgängliga, väl länkade och strukturellt framträdande har större chans att upptäckas av AI-spindlar och citeras som källor i AI-genererade svar. Forskning från AmICited och andra AI-övervakningsplattformar visar att webbplatser med optimerat crawl-djup får fler citeringar i AI-sökresultat. Detta beror på att AI-system prioriterar källor som är auktoritativa, tillgängliga och ofta uppdaterade — alla egenskaper som hänger samman med grunt crawl-djup och bra intern länkstruktur.
Det finns dock vissa skillnader i hur AI-spindlar beter sig jämfört med Googlebot. AI-spindlar kan vara mer aggressiva i sina genomsökningsmönster och potentiellt förbruka mer bandbredd. De kan också ha andra preferenser för innehållstyper och aktualitet. Vissa AI-system prioriterar nyligen uppdaterat innehåll mer än traditionella sökmotorer, vilket gör crawl-djup-optimering ännu viktigare för att förbli synlig i AI-sökresultat. Dessutom kanske AI-spindlar inte respekterar vissa direktiv som robots.txt eller noindex-taggar på samma sätt som traditionella sökmotorer gör, även om detta utvecklas i takt med att AI-företag arbetar för att anpassa sig till SEO-bästa praxis.
För företag som fokuserar på AI-synlighet och generative engine optimization (GEO) tjänar optimering av crawl-djup ett dubbelt syfte: det förbättrar traditionell SEO samtidigt som det ökar sannolikheten att AI-system upptäcker, crawlar och citerar ditt innehåll. Detta gör crawl-djup-optimering till en grundläggande strategi för alla organisationer som vill synas på både traditionella och AI-drivna sökplattformar.
Att optimera crawl-djup kräver ett systematiskt angreppssätt som omfattar både strukturella och tekniska aspekter av webbplatsen. Följande bästa praxis har visat sig effektiva på tusentals webbplatser:
För stora företagswebbplatser med tusentals eller miljontals sidor blir crawl-djup-optimering alltmer komplex och kritisk. Företagssajter har ofta hårda crawl-budget-begränsningar, vilket gör det nödvändigt att tillämpa avancerade strategier. En metod är crawl-budget-allokering, där du strategiskt avgör vilka sidor som förtjänar crawl-resurser baserat på affärsvärde. Högvärdessidor (produktsidor, tjänstesidor, kärninnehåll) bör hållas på ytliga nivåer och länkas ofta, medan lågprioriterade sidor (arkivinnehåll, dubbletter, tunt innehåll) bör ha noindex eller nedprioriteras.
En annan avancerad strategi är dynamisk intern länkning, där du använder datadrivna insikter för att identifiera vilka sidor som behöver fler interna länkar för att förbättra sitt crawl-djup. Verktyg som seoClarity’s Internal Link Analysis kan identifiera sidor på överdrivet djupa nivåer med få interna länkar och därmed avslöja möjligheter att förbättra crawl-effektiviteten. Dessutom möjliggör loggfilanalys att du kan se exakt hur spindlar navigerar på din webbplats, vilket avslöjar flaskhalsar och ineffektiviteter i crawl-djup-strukturen. Genom att analysera spindelbeteende kan du identifiera sidor som genomsöks ineffektivt och optimera deras tillgänglighet.
För flerspråkiga webbplatser och internationella sajter blir crawl-djup-optimering ännu viktigare. Hreflang-taggar och korrekt URL-struktur för olika språkversioner kan påverka crawl-effektiviteten. Genom att säkerställa att varje språkversion har en optimerad crawl-djup-struktur maximerar du indexeringen i alla marknader. På liknande sätt innebär mobile-first-indexering att crawl-djup-optimering måste ta hänsyn till både desktop- och mobilversioner av webbplatsen, så att viktigt innehåll är tillgängligt på båda plattformarna.
Betydelsen av crawl-djup utvecklas i takt med att sökteknologin går framåt. Med framväxten av AI-sökmotorer och generativa AI-system blir crawl-djup-optimering relevant för en bredare publik än bara traditionella SEO-specialister. När AI-system blir mer sofistikerade kan de utveckla andra genomsökningsmönster och prioriteringar, vilket potentiellt gör crawl-djup-optimering ännu viktigare. Dessutom sätter den ökande mängden AI-genererat innehåll press på Googles index, vilket gör hantering av crawl-budget viktigare än någonsin.
Framöver kan vi förvänta oss flera trender som formar crawl-djup-optimering. För det första kommer AI-drivna crawl-optimeringsverktyg att bli mer avancerade och använda maskininlärning för att identifiera optimala crawl-djup-strukturer för olika webbplatstyper. För det andra blir realtidsövervakning av crawl standard, vilket gör att webbplatsägare kan se exakt hur spindlar navigerar och göra omedelbara justeringar. För det tredje blir crawl-djup-mått mer integrerade i SEO-plattformar och analystjänster, vilket gör det enklare för icke-tekniska marknadsförare att förstå och optimera denna viktiga faktor.
Sambandet mellan crawl-djup och AI-synlighet kommer sannolikt att bli ett viktigt fokusområde för SEO-specialister. När fler användare förlitar sig på AI-sökmotorer för information behöver företag optimera inte bara för traditionell sökning, utan även för att bli upptäckta av AI. Det innebär att crawl-djup-optimering blir en del av en bredare generative engine optimization (GEO)-strategi som omfattar både traditionell SEO och AI-synlighet. Organisationer som bemästrar crawl-djup-optimering tidigt får ett konkurrensförsprång i det AI-drivna söklandskapet.
Slutligen kan begreppet crawl-djup komma att utvecklas i takt med att sökteknologin blir mer sofistikerad. Framtida sökmotorer kan använda andra metoder för att upptäcka och indexera innehåll, vilket potentiellt minskar betydelsen av traditionellt crawl-djup. Den grundläggande principen — att lättillgängligt, välstrukturerat innehåll har större chans att upptäckas och rankas — kommer dock troligen att förbli relevant oavsett hur sökteknologin utvecklas. Därför är investering i crawl-djup-optimering idag en solid långsiktig strategi för bibehållen synlighet på nuvarande och framtida sökplattformar.
Crawl-djup mäter hur långt sökmotorernas botar navigerar genom din webbplats hierarki baserat på interna länkar och URL-struktur, medan klickdjup mäter hur många användarklick som krävs för att nå en sida från startsidan. En sida kan ha ett klickdjup på 1 (länkad i sidfoten) men ett crawl-djup på 3 (nästlad i URL-strukturen). Crawl-djup är ur sökmotorns perspektiv, medan klickdjup är ur användarens perspektiv.
Crawl-djup påverkar inte direkt rankingar, men det har stor inverkan på om sidor överhuvudtaget indexeras. Sidor som är djupt begravna i din webbplatsstruktur är mindre benägna att genomsökas inom den tilldelade crawl-budgeten, vilket innebär att de kanske inte indexeras eller uppdateras ofta. Denna minskade indexering och färskhet kan indirekt skada rankingarna. Sidor närmare startsidan får vanligtvis mer uppmärksamhet av spindlar och mer länkstyrka, vilket ger dem bättre rankingpotential.
De flesta SEO-experter rekommenderar att viktiga sidor hålls inom 3 klick från startsidan. Detta säkerställer att de är lättupptäckta för både sökmotorer och användare. För större webbplatser med tusentals sidor är viss djup nödvändigt, men målet bör vara att hålla kritiska sidor så ytliga som möjligt. Sidor på nivå 3 och djupare presterar generellt sämre i sökresultaten på grund av minskad genomsökningsfrekvens och fördelning av länkstyrka.
Crawl-djup påverkar direkt hur effektivt du använder din crawl-budget. Google tilldelar en specifik crawl-budget till varje webbplats baserat på crawl-kapacitet och crawl-efterfrågan. Om din webbplats har överdrivet crawl-djup med många sidor långt ner, kan spindlarna förbruka sin budget innan de når alla viktiga sidor. Genom att optimera crawl-djup och minska onödiga sidolager säkerställer du att ditt mest värdefulla innehåll genomsöks och indexeras inom den tilldelade budgeten.
Ja, du kan förbättra crawl-effektiviteten utan att strukturera om hela webbplatsen. Strategisk intern länkning är det mest effektiva — länka viktiga djupa sidor från din startsida, kategorisidor eller innehåll med hög auktoritet. Att regelbundet uppdatera din XML-sitemap, laga brutna länkar och minska omdirigeringskedjor hjälper också spindlar att nå sidor effektivare. Dessa taktiker förbättrar crawl-djupet utan att kräva arkitektoniska förändringar.
AI-sökmotorer som Perplexity, ChatGPT och Google AI Overviews använder sina egna specialiserade spindlar (PerplexityBot, GPTBot, etc.) som kan ha andra genomsökningsmönster än Googlebot. Dessa AI-spindlar följer ändå crawl-djup-principer — sidor som är lättillgängliga och väl länkade har större chans att upptäckas och användas som källor. Optimering av crawl-djup gynnar både traditionella sökmotorer och AI-system, och förbättrar din synlighet på alla sökplattformar.
Verktyg som Google Search Console, Screaming Frog SEO Spider, seoClarity och Hike SEO erbjuder analys och visualisering av crawl-djup. Google Search Console visar crawl-statistik och frekvens, medan specialiserade SEO-spindlar visualiserar din webbplats hierarkiska struktur och identifierar sidor med överdrivet djup. Dessa verktyg hjälper dig att hitta optimeringsmöjligheter och följa förbättringar av crawl-effektivitet över tid.
Börja spåra hur AI-chatbotar nämner ditt varumärke på ChatGPT, Perplexity och andra plattformar. Få handlingsbara insikter för att förbättra din AI-närvaro.
Crawl rate är hastigheten med vilken sökmotorer genomsöker din webbplats. Lär dig hur det påverkar indexering, SEO-prestanda och hur du optimerar det för bättre...

Crawlbarhet är sökmotorers förmåga att komma åt och navigera på webbsidor. Lär dig hur crawlers fungerar, vad som blockerar dem och hur du optimerar din webbpla...

Crawlfrekvens är hur ofta sökmotorer och AI-crawlers besöker din sida. Lär dig vad som påverkar crawl-rater, varför det är viktigt för SEO och AI-synlighet, och...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.